
- 1接收第三方系统的附件文件转为MultipartFile对象进行存储_接收第三方文件信息和附件
- 22024年目标检测数据集大合集所有下载地址汇总_仓鼠数据集下载
- 3相机系列——透视投影:针孔相机模型_透视投影模型
- 4在使用pro-cli来搭建初始化脚手架时出现:“git‘ 不是内部或外部命令,也不是可运行的程序或批处理文件。”_git' 不是内部或外部命令,也不是可运行的程序 或批处理文件。
- 5牛客网Java测试题解析_public class hasstatic { private static int x = 10
- 6算法数据结构——图的遍历之深度优先搜索算法(Depth First Search)_图的深度优先搜索 试用自己的语言理解图的深度遍历的过程。 并写成下列图的深度遍
- 7Unity3D人物移动篇之刚体跳跃重力下落慢的问题_unity中如何修改刚体下落加速度
- 8nginx的配置:TLSv1 TLSv1.1 被暴露不安全_nginx 放行tls1
- 9select * into 和insert into 备份与插入_select insert into
- 10女生当程序员到底行不行?数学149的女学霸,直言男生也没有比我好!_程序员张功
【论文笔记】Applications of Deep Reinforcement Learning in Communications and Networking: A Survey
赞
踩
摘要
本文综述了深度强化学习(DRL)在通信和网络中的应用。现代网络中的实体需要在网络环境不确定的情况下在本地进行决策,以使网络性能最大化。强化学习被有效地用于使网络实体在状态空间和行为空间较小的情况下获得动作的最优选择。然而,在复杂的大规模网络中,状态空间和动作空间往往很大,强化学习可能无法在合理的时间内找到最优策略。因此,强化学习与深度学习相结合的DRL可克服这一不足。在本次调查中,我们首先提供了从基本概念到高级模型的DRL知识。然后,我们回顾了为解决通信和网络中的新问题而提出的DRL方法。这些问题包括动态网络接入、速率控制、无线缓存、数据卸载、网络安全和连接留存,这些都是下一代通信网络要解决的重要问题。此外,我们呈现了DRL在流量路由、资源分享,数据收集方面的应用。最后,我们强调了应用DRL的重要挑战,待解决的问题和未来的研究方向。
因本paper内容过多,本博客仅对自己感兴趣的方面进行了记录,如有需要可以查看原文
介绍
在不确定且随机的环境下,大多数决策问题都可以用马尔可夫决策过程来建模(MDP)。采用动态规划或其他算法(比如数值迭代)或者RL来解决MDP。然而,现代网络规模庞大且复杂,计算复杂度变德难以控制。因此,DRL方法提供了以下优点:
- 可解决复杂问题。能让网络控制单元在无完整和准确的网络信息情况下,解决非凸和复杂的问题
- 使网络实体可以在不知道信道模型和移动模式的情况下学习最优策略
- 网络实体可以在本地进行观察并得到最优动作,减少通信开销,提高网络安全性和健壮性
- DRL的学习速度快

本文主要调查DRL如何解决通信和网络中的问题,如图2所示。主要讨论的问题包括:网络接入、数据速率控制、无线缓存、数据卸载、网络安全、连接预留、流量路由、数据收集。本文还调查了DRL相关的工作,如图1所示。从中可以看出DRL解决通信问题的研究主要集中在蜂窝网和无线缓存、卸载方面。

深度强化学习:概览
本节讲马尔可夫决策过程、强化学习、深度学习的基础知识,并回顾了DRL的最新模型及其扩展。
马尔可夫决策过程MDP
MDP是一个离散时间随机控制过程。MDP为决策问题的建模提供了一个数学框架,其中的结果是部分随机的并且受决策者(agent)的控制。MDPs有助于研究动态规划和强化学习技术所能解决的优化问题。通常,MDP由元组(S,a,p,r)定义,其中S是有限的状态集,a是有限动作集,p是从状态s到状态s'的转移概率,r为动作a执行后的即时奖励。我们把“策略”用![]() ,后者表示为
,后者表示为![]() 。
。
部分可观测MDP

普通的MDP中,我们假设系统状态是可以被agent完全可观测的。然而在很多情况下,agent只能观测到系统状态的一部分,因此部分可观测MDP(POMDPs)就可以用来解决这种顺序决策问题。一个典型的POMDP模型被一个六元组所定义
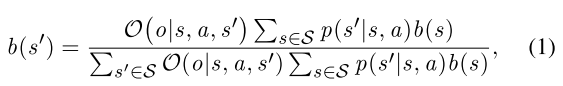
其中O是agent在状态s执行动作a到达新状态s’并观察到o的概率。
马尔可夫博弈 Markov Games(个人感觉和所谓的多主体RL一样)
一个随机博弈由多个players参与,并且是一个有转移概率的动态过程。这种的我们称之为Markov game。一个典型的马尔可夫博弈模型2可以被建模为,第一项是agent的集合;第二项是个向量,为agent的状态空间;第三项为agent i的动作空间;第四项p是转移概率;第五项r是agent的奖励。
在这样的Markov game中,agent对环境观察后,同时选择他们的动作。在这个博弈过程中,所有agent尝试去得到他们的最优policy以最大化他们各自的长期平均奖励的期望。当状态和agent个数均有限时,Markov Game通常可以在有限步后达到纳什均衡。
强化学习 RL

RL作为机器学习的重要分支,被广泛用于解决MDP问题。在强化学习方法中,agent作为动作主体与环境互动进而学习它的最优动作准则(policy)。具体来讲,agent首先观测当前状态,然后采取行动,并从环境中获得即时收益(reward)和一个新状态(s'),如图4(a)所示,观测值(包括reward和s')用来修正agent的policy,这个进程将会被重复直到agent的policy达到最优。在RL中,Q-learning是最有效的方法(甚至个人感觉没有RL是不用Q-learning的,Q-learning的方法已经和RL融合在一起),下面对其进行描述。
Q-Learning
在一个MDP中,我们的目标是求解最优policy ,它代表了在policy
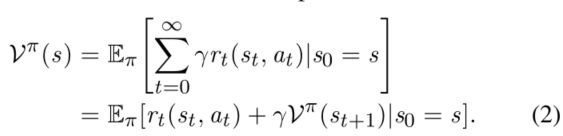
在每个状态的最优动作因此可以通过下式得到:
此外,我们定义![]() (称为最优Q函数),其用来评价状态-动作对 的好坏,其与V函数的关系为
(称为最优Q函数),其用来评价状态-动作对 的好坏,其与V函数的关系为![]() 。现在,问题被简化成了求解Q函数的最优值的问题,而这个问题也将通过迭代过程求解。具体来讲,Q函数可以根据如下规则被更新:
。现在,问题被简化成了求解Q函数的最优值的问题,而这个问题也将通过迭代过程求解。具体来讲,Q函数可以根据如下规则被更新:
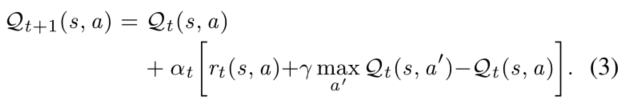

这部分不详细描述了,具体可见这篇博文(较简明)或者这篇博文(较详细)
SARSA(一种在线Q-Learning算法)
Q-Learning是一种离线的算法,具体来讲,算法1仅在Q值收敛后得到最优策略。因此,这一节呈现一种在线的学习算法:SARSA,其允许agent以一种在线的方式获取最优policy。
与Q-learning不同,SARSA允许agent在算法收敛之前在每个是不选择最优的动作。在Q-learning算法中,policy根据可用动作的最大奖励来更新,而不管用了哪种种策略。与之相反,SARSA与环境交互并直接从所采取的动作来更新policy。即SARSA时通过五元组Q(s, a, r, s', a')来更新Q值。
Q-Learning for Markov Games 马尔可夫博弈中的Q-Learning
为了将QL用于马尔可夫博弈,首先要定义i号agent的Q函数:
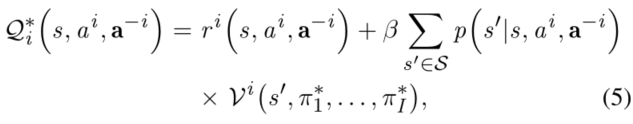
其中
[17]Hu J, Wellman M P. Nash Q-learning for general-sum stochastic games[J]. Journal of machine learning research, 2003, 4(Nov): 1039-1069.
在参考文献[17](是一篇03年的paper,目前引用了800+次)中,作者提出了一个用于马尔科夫博弈的多主体QL算法,该算法允许智能体给予对当前Q值得纳什均衡行为进行更新。具体来讲,i号agent将在博弈开始的时候通过构造随机的cancel来学习Q值。在每个时点t,i号agent观测当前状态并采取动作a^i,之后其收到即时收益r^i和他人采取的行动a^(-i),他人的即时奖励和新状态s'。最后,i号agent为状态博弈![]() 计算一个纳什均衡
计算一个纳什均衡![]() ,Q值由下式得到:
,Q值由下式得到:
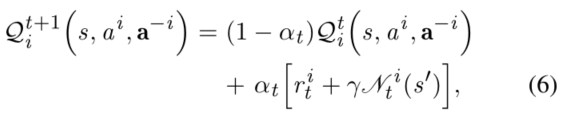
其中\alpha是学习速率,
为计算纳什均衡,i号agent需要直到其他agent得Q值,然而这对于其是不可知的。为此,代理i将在游戏开始时设置有关其他人的Q值得估计值,如![]() 。随着博弈进行,agent i观察其他agent得即使收益和之前做过的动作。这些信息可以用来修改agent关于其他agent的Q函数的猜想。之后,作者证明了在一些关于状态博弈的限制性假设下,所提出的多主体QL算法是收敛的。
。随着博弈进行,agent i观察其他agent得即使收益和之前做过的动作。这些信息可以用来修改agent关于其他agent的Q函数的猜想。之后,作者证明了在一些关于状态博弈的限制性假设下,所提出的多主体QL算法是收敛的。
深度QL
QL算法当动作/状态空间较小时可以迅速地得到一个最优策略。然而实际中系统模型非常复杂,状态空间和动作空间经常很大。因此DQL(深度Q-learning)被提出来克服这个困难。直观来讲,DQL通过DQN(深度Q网络)来实现,用以取代原先的Q表,来表征对于
[41]V . Mnih et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015.
如文献[41]所述,即便我们使用非线性函数逼近时,强化学习算法仍然的平均奖励仍可能不稳定并发散。这是因为Q值得微小变化可能会极大地对policy造成影响,因此,数据分布和Q值和目标值![]() 之间的相关性会发生变化,为解决这个问题,两个机制被提出,分别是目标Q网络和经验重播。
之间的相关性会发生变化,为解决这个问题,两个机制被提出,分别是目标Q网络和经验重播。
- 经验重播(Experience replay mechanism):算法首先初始化重播内存 D,其格式为
(st,at,rt,st+1) (称作experience),这些是随机生成的(比如使用-贪心算法)。之后算法从 D 中随即地选择样本(如:minibatches)来训练DNN。用训练后的DNN所获得的Q值用来获取新的experience并存储在D中。这个机制允许DNN以一种更加高效的方式学习旧的experience和新的experience。此外,通过使用experience replay,状态转移将更加独立且分布均因,以此消除观测值之间的相关性。
- Fixed target Q-network:在训练过程中,Q值可能会发生偏移,因此如果使用一组不断变化的值来更新Q网络那么值估计可能会脱离我们的控制。这导致算法的不稳定,为解决这个问题,目标Q网络用于频繁但缓慢地更新primary Q网络的值。通过这种方法,目标值和估计的Q值之间的相关性将被显著降低,从而使算法稳定。

算法2中展示了经验重播和固定的目标Q网络的用法,表二总结了DQL方法与其他算法的不同。

先进的DQL模型
| 技术 | 论文 | 年份 | 关键特点 | 好处 | 劣处 | 应用 |
| Double Deep Q-Learning | Deep reinforcement learning with double Q-learning | 2016 | 使用两个Q函数同时选择和评估动作价值 | 易收敛易实现 | 没有考虑MDP特殊的特点 | 适用于大多数MDP |
| Prioritized Experience Replay | Prioritized experience replay | 2016 | 在replay memory中对experience排列优先级 | 更快地收敛 | 在replay memory时需要关于experience的优先级信息 | 当experience存在优先级差异是非常有效 |
| Dueling Deep Q-Learning | Dueling network architectures for deep reinforcement learning | 2016 | 使用2个DNN同时估计动作和状态价值函数 | 比以上两者快得多 | 当动作和状态空间小的时候复杂度高、效率低 | 状态空间和动作空间大的时候效率很高 |
| Asynchronous Multi-Step Deep Q-Learning | Asynchronous methods for drl | 2016 | 使用多个agent并行训练DNN | 通过多个agent进行训练,学习速度很快 | 对于硬件需求高、复杂度高 | 对于状态和动作空间非常大的MDP效率很高 |
| Distributional Deep Q-Learning | A distributional perspective on reinforcement learning | 2017 | 使用分布式函数来更新Q值函数 | 评估Q函数更加精确 | 需要知道不同状态和动作的奖励函数的分布 | 适合在MDP奖励函数的分布已知的场景中实现 |
| Deep Q-Learning With Noisy Nets | Noisy networks for exploration | 2018 | 训练时在DNN加入了一个高斯噪声层 | 对于环境的探索更加高效 | 增加高斯噪声层的效率有待商榷 | 对于状态和动作空间非常大的MDP,其效率很高 |
| Rainbow Deep Q-Learning | Rainbow: Combining improvements in deep rein- forcement learning | 2018 | 把之前用到的RL技术汇在一起 | 集成了所有RL算法的有限 | 极其高的复杂性和对于MDP非常多的要求 | 仅适合大状态/动作空间并且已知一些先验特征的MDP |
| Deep Deterministic Policy Gradient Q-Learning | Continuous control with deep reinforcement learning
Deterministic policy gradient algorithms(DPG) | 2016 2014 | 使用了DPG算法 | 可用于动作空间连续的情景 使用低维度的观测值学习竞争policy | 适用于学习高维度、连续的动作空间 | |
| Deep Recurrent Q-Learning for POMDPs | Deep recurrent Q-learning for partially observable MDPS | 2015 | 使用LSTM层来替换卷积DQ2N的第一个全连接层
| 对观测值质量的变化不敏感; LSTM能以任意长的历史记录估计当前状态 | 适用于环境仅可部分观测的问题 | |
| Deep SARSA Learning | Deep reinforcement learn- ing with experience replay based on SARSA | 2016 | 以在线的方法进行学习; 使用CNN获得Q | |||
| Deep Q-Learning for Markov Games | Towards cooperation in sequential prisoner’s dilemmas: A deep multiagent reinforcement learning approach | 2017 | 分成在线和离线两个阶段 | 多个动作主体的顺序决策 | ||
| Neural Fictitious Self-Play (NFSP) | Deep reinforcement learning from self-play in imperfect-information games | 2016 | 有两个网络,一个用DRL,一个用监督学习;
| 不完全信息下的决策 |
应用层技术
这里本来应该是按照图2的应用分类进行描述的,因本文过长(42页),因此仅对与个人课题相关的部分进行归纳和整理,本篇博客的来源是一篇不错的文章,如果有需要可以查看原文


| 论文 | 年份 | 模型 | 优化目标 | 特点 | 研究内容 | 状态 | 动作 |
| DECCO: Deep-learning enabled coverage and capac- ity optimization for massive MIMO systems | 2018 (felow写的) | policy network(from 148) | 分配资源块给BS和移动用户 | 平均频谱效率 | 调度的参数 | ||
| A deep reinforce- ment learning based framework for power-efficient resource allocation in cloud RANs | 2017 ICC | DQL | 最小化功率损耗 QoS要求 | 第一阶段决定哪些RRH工作; 第二阶段决定怎么分配资源 | 云端接入网的动态资源分配 | 用户需求 RRH的工作状态 | RRH的工作与否 分配给RRH的权重 |
| Deep reinforcement learning for distributed dynamic power allocation in wireless networks | 2018 | DQN+FNN | BS的传输速率 | 基站的功率控制 | 其他基站的干扰 | 选择发射功率 | |
| Reinforcement learning based QoS/QoEaware service function chaining in software-driven 5G slices | DQN+CNN | QoE gain | 网络拓扑、QoE/QoS状态、
| ||||
| Deep reinforcement learning for network slicing | 2018 | DQN+FNN | 频谱效率和QoE | 优化频谱资源块的分配 | |||
| A Deep-Learning-Based Radio Resource Assignment Technique for 5G Ultra Dense Networks | 2018 | DL+LSTM | 使BS预测流量负载; 调整上下行比例以防止拥塞 |

