
热门标签
热门文章
- 1吴恩达机器学习2022-Jupyter-机器学习实例_吴恩达机器学习实验
- 2推荐两款ios端磁力下载工具_iso bt下载软件
- 3Linux安装Redis服务器以及本地Redis客户端连接远程Redis服务器_linuxredis无法通过redis-cli本地客户端进入
- 4YOLOv5改进 | 主干篇 | 低照度图像增强网络SCINet改进黑暗目标检测(全网独家首发)
- 5视频剪辑工资一般多少?Adobe视频设计专家,助你实现财务自由_视频剪辑这个行业月平均薪资多少
- 6插值法-python及matlab实现_hermite插值python代码
- 7Win11如何设置软件快捷方式?_戴尔w11怎么创建软件快捷方式
- 8大数据概论知识整理_大数据技术概论知识点总结
- 9ES 索引改名_es 索引支持改命吗
- 10React学习-UI框架-Ant-Design-of-React,干货满满_design for react
当前位置: article > 正文
详解半监督学习(Semi-Supervised Learning)(基础篇)_semisupervised model
作者:寸_铁 | 2024-07-09 14:09:35
赞
踩
semisupervised model
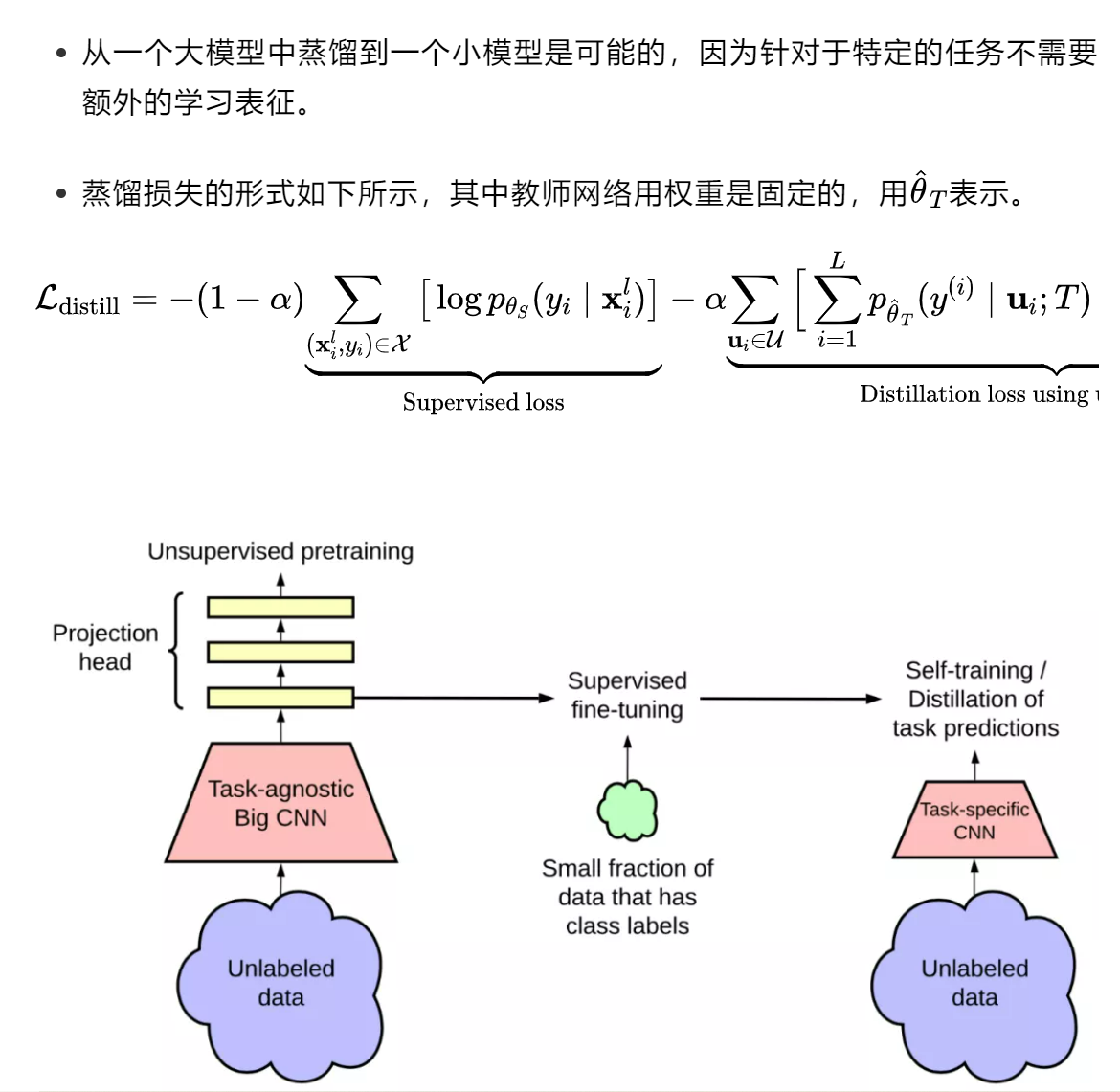
半监督学习(Semi-Supervised Learning)是一种机器学习方法,旨在利用标记和未标记数据一起进行训练,以提高模型的性能。在半监督学习中,我们使用少量标记数据和大量未标记数据来训练模型。该方法在可用标记数据有限,但未标记数据相对丰富时特别有用。
1. 半监督学习的底层原理:
半监督学习通常结合监督学习和无监督学习的方法。其中,无监督学习用于使用未标记数据进行聚类或生成模型,以学习数据的分布和结构。监督学习则使用标记数据进行预测模型的训练。常见的方法包括自训练(Self-Training)、伪标签(Pseudo-Labeling)、生成模型(Generative Models)等。
2. 应用场景:
半监督学习适用于以下情况:
- 数据标记成本高昂:标记大量数据需要大量时间和资源,而使用未标记数据进行训练可以降低标记成本。
- 数据集规模大:当前只有少量标记数据可用,而未标记数据比较丰富,可以利用未标记数据提供额外信息来改善模型性能。
- 数据分布中有类别不平衡:少数类别的样本数量很少,这导致监督学习中的模型偏向于多数类别,使用未标记数据可以提供辅助信息。
3. 优缺点:
-
优点:
- 可以利用大量未标记数据,增强模型的泛化能力。
- 在标记数据较少的情况下,能够提高模型的性能。
- 可以应对类别不平衡和数据分布不均匀的问题。
-
缺点:
- 未标记数据的质量对模型的影响不确定,可能引入噪声。
- 未标记数据的分布可能与标记数据不一致,导致模型不准确。
- 半监督学习的理论和算法相对较复杂,调参和优化困难。
4. Python代码示例:
下面是一个使用半监督学习方法自训练(Self-Training)进行文本分类的示例。
from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import LogisticRegression # 加载20个新闻组数据集(仅选择4个类别) categories = ['comp.graphics', 'rec.sport.baseball', 'sci.space', 'talk.politics.misc'] data = fetch_20newsgroups(categories=categories) # 文本特征提取(TF-IDF向量化) vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(data.data) y = data.target # 拆分标记和未标记数据 labeled_X = X[:100] # 标记数据 labeled_y = y[:100] unlabeled_X = X[100:] # 未标记数据 # 训练初始分类器 initial_classifier = LogisticRegression() initial_classifier.fit(labeled_X, labeled_y) # 利用初始分类器预测未标记数据的标签 pseudo_labels = initial_classifier.predict(unlabeled_X) # 使用标记和伪标签数据进行训练 combined_X = scipy.sparse.vstack([labeled_X, unlabeled_X]) combined_y = np.concatenate([labeled_y, pseudo_labels]) # 训练半监督学习模型 semisupervised_model = LogisticRegression() semisupervised_model.fit(combined_X, combined_y)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
以上代码使用scikit-learn库,以20个新闻组数据集为例进行文本分类。首先,使用TfidfVectorizer对文本进行向量化表示。然后,将部分数据作为标记数据,其余数据作为未标记数据。通过训练初始分类器,利用其预测结果作为未标记数据的伪标签。最后,将标记和伪标签数据合并,并用于训练半监督学习模型。
如果你想更深入地了解人工智能的其他方面,比如机器学习、深度学习、自然语言处理等等,也可以点击这个链接,我按照如下图所示的学习路线为大家整理了100多G的学习资源,基本涵盖了人工智能学习的所有内容,包括了目前人工智能领域最新顶会论文合集和丰富详细的项目实战资料,可以帮助你入门和进阶。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/寸_铁/article/detail/802614
推荐阅读
相关标签

