
- 1Windows server2016进行配置DHCP服务_虚拟机windows sever2016安装dhcp服务,结果画面截图
- 22021年保研推免面试经验_湖南大学计算机预推免
- 3王道考研 计算机网络12 点对点链路 广播式链路 介质访问控制MAC 动态分配信道 ALOHA协议 CSMA CSMA/CD CSMA/CA协议
- 42022中国智慧医疗领域最具商业合作价值企业盘点
- 5【论文笔记】Digital Twin in Industry: State-of-the-Art——Tao Fei
- 6GitHub的注册-登录-克隆仓库至本地-同步仓库-分享项目链接_克隆chatgpt存储库时,github网站的用户名和密码
- 7通用图形处理单元GPGPU计算管线(General Purpose computation on Graphics Processing Units)介绍
- 8Windows运行代码管理工具(gitee)指南_gitee windows工具
- 9matlab程序中ode45,关于matlab中ode45的问题
- 10轻松上手MYSQL:MYSQL事务隔离级别的奇幻之旅_mysql设置隔离级别
上交&阿里:掀开多模态大模型的头盖骨,解密黑盒模型推理过程_阿里 cot
赞
踩
多模态大模型的发展势头正猛,研究者们热衷于通过微调模型,打造出具有更高输入分辨率、更复杂功能、更强感知能力以及更精细粒度的模型。
但是,当我们深究这些模型时,不禁要问:这些多模态大模型的内部机制是如何运作的?它们是如何凭借系统token、图像token、用户Token这些复杂的输入,推导出准确的答案呢?
由于大模型固有的黑盒特性,再加上多模态的输入输出和复杂深层次的结构,理解MLLMs的内部机制变得异常困难。
知其然更要知其所以然,为了揭开这一谜团,上海交通大学与阿里巴巴的研究团队最近引入了一种信息流方法,来可视化图像和文本在复杂推理任务中的交互过程。这种方法利用注意力得分和Grad-CAM技术量化图像、用户和系统token对答案token的影响程度,展示了信息流的动态变化,并发现了一些非常有趣的现象。
下图展示了在多模态大模型不同层中token信息流的注意力得分。从左到右依次是系统token、图像token和用户token,他们的信息流向输出token汇聚。
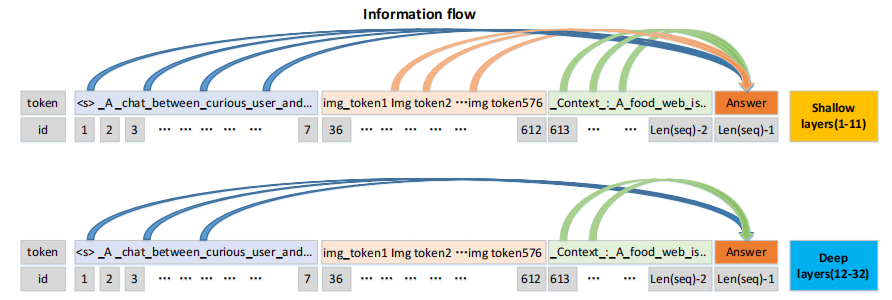
可以发现,在浅层与深层中不同token信息流汇聚情况有所区别。在深层(12-32),系统token和用户token的信息流汇聚更为明显。但令人惊讶的是,图像token的汇聚则相对较弱,甚至对输出token没有什么贡献。
这到底是怎么回事,让我们一起去一探究竟。
论文标题:
From Redundancy to Relevance: Enhancing Explainability in Multimodal Large Language Models
论文链接:
https://arxiv.org/pdf/2406.06579
多模态大模型推理过程可视化分析
为了观察信息流的动态变化,作者利用注意力得分和Grad-CAM有效地表示动态变化。注意力得分通过前向传播突出显示相关区域,而Grad-CAM通过反向传播捕捉梯度变化,揭示图像特征的显著性。这两种方法互补,既能评估输入的重要性,又能清晰展现其对模型预测的具体影响,提供了一种全面理解信息流动态的方式。
Grad-CAM可视化
计算Grad-CAM
大模型复杂推理本质上仍然是一个文本生成任务,生成的响应是由每个单词的分类结果组成的句子,即将所有单个单词的CLS logits加在一起,网络输出n个token的概率,记为,使用Grad-CAM将模型的输出答案可视化:

为了获取模型的整体输出的 logits,计算偏导数:
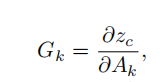
图像编码器或者LLM解码器的最后一层的所有注意力映射Ak求解,其中Ak表示第n通道的特征图在坐标点的特征,以及由此产生的导数特征映射G。Reshape操作将序列输入转换为一个H × W的二维形状。将α权重向量与特征图A的相应通道相乘,计算得到一个二维激活映射:

Grad-CAM可以可视化任何激活特征图,其最后一层的特征图蕴含丰富的高层语义信息和详细的空间信息。
图像编码器的信息流
基于以上的计算方法,本文利用Grad-CAM可视化来理解CLIP-ViT在图像编码器中的决策过程。
以下图为例,研究与答案Token(如(B)蘑菇)对应的图像Token,关注模型的最后一层(即最后层归一化后的特征)进行梯度反向传播,捕捉决策机制的精细动态,并可视化模型在预测答案选项(如A、B、C、D)时依赖的图像区域。

从上图可以看到,CLIP-ViT模型的浅层捕获了通用图像特征和广泛的兴趣区域,而深层则专注于提供预测答案的关键视觉线索。注意力集中在图像的特定区域,特征图尤其突出了有效回答问题的图像区域(如蘑菇的伞面和柄部),凸显了深层对于输出token的重要性,并且信息流主要在此处聚合。另外,由于图像编码器并不直接处理文本,因此其特征保持了丰富的信息,对答案的生成提供帮助。
LLM解码器的信息流
CLIP-ViT的丰富特征被传递给LLM解码器,由LLM解码器与文本交互。使用Grad-CAM来可视化后如下图所示:

可以看到:
-
浅层(1-11层)对于图像内容有显著的响应,与提示选项相关的图像区域高亮显示。这些层可以视为图像-文本语义交互层,模型在理解提示中的上下文、问题和选项后,能过滤并专注于与提示相关的图像内容。这种信息流的收敛模式与人类根据问题聚焦图像中相关信息以给出答案的方式非常相似。
-
深层(12-32层)的信息流表现较为分散,与文本关联的图像信息流的聚合变得不那么明显。这些深层可能依赖于浅层收集的信息,并结合LLM的知识,降低了对图像直接关注的依赖。
综上所述,CLIP-ViT模型在面临复杂推理时,浅层主要负责图像与文本的语义交互和信息流的收敛,而深层则侧重于知识推理,其信息流并不显著收敛。
注意力分数可视化LLM解码器中的信息流
通过注意力分数计算来衡量浅层显著特征,可以更好的理解模型的选择和加权机制,阐明它们在最终输出中的作用。将所有输出Tokens的注意力分数称为影响力率,用w表示,对不同类型的输入token进行聚合。
比如对于ScienceQA这样的复杂推理任务,其输出Tokens涵盖了代表系统、图像和用户Tokens的三个部分:

其中 表示系统Tokens的索引,Nsys表示系统Tokens的长度;
I表示图像Tokens的索引;
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

