
- 1不知道如何测试?全网最全网络安全渗透测试流程给你答案!_网络安全测试
- 2我的技术博客地址_mjios cnblogs
- 35.gradle配置和project_gradle implementation project
- 4idea分支合并_idea 分支合并
- 5爬table数据_Python爬虫 福布斯排行榜 数据可视化
- 6Vue+ElmentUI在table表格中表头位置插入Dropdown下拉菜单实现过滤效果_table 表头下拉框
- 7基于混沌算法的图像加密解密系统_为什么图像加密要用混沌
- 8AI绘画Stable Diffusion 图生图必看教程:局部重绘和涂鸦重绘详解,超强操作流程奉上!_涂鸦重绘和局部重绘区别
- 9基于深度学习的聊天机器人项目
- 10Python绘制多分类ROC曲线_决策树多分类roc
kafka生产者消费者举例_kafka生产消费的例子
赞
踩
kafka介绍
Kafka 是一款分布式流处理平台,它被设计用于高吞吐量、持久性、分布式的数据流处理。
-
Kafka 简介:
- Kafka 是一个高吞吐、分布式、基于
发布订阅的消息系统。 - Kafka 具有高吞吐量、低延迟、可扩展性、持久性、可靠性、容错性、高并发等特性。
- Kafka 是一个高吞吐、分布式、基于
-
Kafka 应用场景:
- 日志收集:公司可以使用 Kafka 收集各种服务的日志,然后通过 Kafka 统一接口服务的方式将这些日志开放给各种消费者,例如 Hadoop、Hbase、Solr 等。
- 消息系统:Kafka 可以解耦生产者和消费者,缓存消息等。
- 用户活动跟踪:Kafka 经常用于记录 web 用户或 app 用户的各种活动,如浏览网页、搜索、点击等。这些活动信息被各个服务器发布到 Kafka 的 topic 中,然后订阅者通过订阅这些 topic 来实时监控分析,或者装载到 Hadoop、数据仓库中进行离线分析和挖掘。
- 运营指标:Kafka 也经常用来记录运营监控数据,包括收集各种分布式应用的数据、生产各种操作的集中反馈,比如报警和报告。
- 流式处理:例如 Spark Streaming 和 Storm。
Kafka 在大规模数据流处理和实时数据传输场景中发挥着重要作用,其发布订阅模型、分区和副本机制以及异步消息传递的特性使其成为分布式系统中的重要组件。
生产者消费者例子
当Docker部署Kafka集群时,需要确保安装了ZooKeeper,因为Kafka依赖于ZooKeeper来实现集群协调与管理。ZooKeeper是一个开源的分布式协调服务,用于维护集群的状态信息、进行领导者选举以及协调分布式应用程序的工作。Kafka利用ZooKeeper来管理集群中的节点、配置信息和分区分配等关键任务,确保集群的稳定运行和可靠性。
先引入依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.7.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
一、生产者
public class Producer { public static void main(String[] args) { // 设置Kafka生产者的配置 Properties props = new Properties(); // Kafka集群的地址 props.put("bootstrap.servers", "192.168.13.133:9092,192.168.13.133:9093,192.168.13.133:9094"); // 确认模式:全部副本确认 props.put("acks", "all"); props.put("retries", 2); // 键的序列化器 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 创建Kafka生产者实例 org.apache.kafka.clients.producer.Producer<String, String> producer = new KafkaProducer<>(props); // 发送10条消息到主题 for (int i = 0; i < 10; i++) { // send异步发送 ProducerRecord参数: 注意 key value【消息是键值对形式】 producer.send(new ProducerRecord<String, String>("hac", Integer.toString(i), Integer.toString(i))); } // 关闭生产者实例 producer.close(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
二、消费者
public class Consumer { public static void main(String[] args) { // 创建消费者配置 Properties props = new Properties(); props.setProperty("bootstrap.servers", "192.168.13.133:9092,192.168.13.133:9093,192.168.13.133:9094"); // 消费者主 props.setProperty("group.id", "groupId1"); // 消费者组ID // 是否开启自动提交偏移量 props.setProperty("enable.auto.commit", "true"); // 自动提交偏移量的间隔时间 props.setProperty("auto.commit.interval.ms", "1000"); props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); // 创建Kafka消费者实例 consumer.subscribe(Arrays.asList("hac"));// 订阅主题 可以订阅多个主题 while (true) { // 从服务器拉取消息记录 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); // 遍历接收到的消息记录 for (ConsumerRecord<String, String> record : records) { // 输出消息的偏移量、键和值 System.out.println("接受到的消息: " + record.key() + ":" + record.value()); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
三、效果
在启动Kafka消费者之前,需要确保消费者能够连接到可用的Kafka集群,并正确地订阅了所需的主题。一旦消费者启动并成功订阅了主题,它将持续监听并处理来自Kafka集群的消息。在此期间,消费者将与集群保持连接,并持续从指定的主题中拉取消息进行处理。当生产者向所订阅的主题发送新消息时,消费者将立即收到这些消息,并进行相应的处理。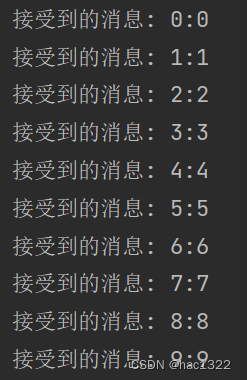
KafkaTemplate @KafkaListener
KafkaTemplate和@KafkaListener是Spring Kafka提供的两个核心组件,用于简化在Spring应用程序中与Apache Kafka集成的过程。
第一步:引入依赖
<!-- kafkfa -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
第二步:配置application.yml文件
spring:
application:
name: kafka-demo
kafka:
bootstrap-servers: 192.168.13.133:9092,192.168.13.133:9093,192.168.13.133:9094
producer:
retries: 3
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
acks: 1
consumer:
group-id: groupId1
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
第三步:使用
KafkaTemplate:KafkaTemplate是Spring Kafka提供的一个工具类,用于简化向Kafka发送消息的过程。通过KafkaTemplate,可以方便地将消息发送到指定的Kafka主题。它封装了Kafka的Producer API,提供了一系列发送消息的方法,包括同步发送、异步发送、带回调函数的发送等。使用KafkaTemplate,你可以在Spring应用程序中轻松地发送消息到Kafka集群中。
@KafkaListener:@KafkaListener注解用于标记一个方法,表示这个方法是一个Kafka消息监听器。通过在方法上使用@KafkaListener注解,可以让Spring容器自动创建Kafka消息监听器并订阅指定的主题,当有消息到达时,自动调用标记了@KafkaListener注解的方法进行消息处理。
生产者:
@RestController @RequestMapping(value = "/kafka") public class SendController { @Autowired private KafkaTemplate kafkaTemplate; @GetMapping(value = "/send") public String send() { String msg = "hello"; //这里写固定的测试一下 String topic = "hac"; kafkaTemplate.send(topic, msg); return "OK"; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
消费者:
@Component
public class KafkaListenerMessage {
/***
* 监听新消息
*/
@KafkaListener(topics = "hac", groupId = "groupId1")
public void listener(ConsumerRecord<String, String> record) {
String value = record.value();
int partition = record.partition();
long offset = record.offset();
System.out.println("value:" + value + ",partition:" + partition + ",offset:" + offset);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
效果:

❤觉得有用的可以留个关注❤

