
- 1外包公司值不值得去?_现在外包值得做吗
- 2【已解决】ModuleNotFoundError: No module named ‘torch._six‘_modulenotfounderror: no module named 'torch
- 3大数据工程师简历_成为大数据工程师所需的技能
- 4半球展开图_棱锥的展开图.ppt
- 5ECMAScript 与 JavaScript的联系 以及为什么会有浏览器兼容的问题?_ecmascript 兼容性
- 6推荐项目:CLIP-ONNX - 加速CLIP推理速度的神器!
- 7MyBatis——MyBatis实现多表查询_mybatis多表查询
- 8老徐WEB:最简单详细的轮播图原理和制作过程(一)_最简单的网页轮播图
- 9LoRA中值得注意的微调细节_lora微调
- 10Python 实战之淘宝手机销售分析(数据清洗、可视化、数据建模、文本分析)_数据可视化手机价位图的代码
国产ETL etl-engine 流批一体数据交换引擎 轻量级 跨平台 支持动态解析GO语言脚本
赞
踩
流批一体数据交换引擎
产品概述
- 我们不仅仅是数据的搬运工,还是数据搬运过程中加工处理的工厂。
- 我们不仅仅适用关系型数据库中,还适配当下流行的时序数据库、消息中间件、Hadoop生态中,支持多种类型数据库之间的融合查询及流式计算。
- etl-engine的核心思想是为用户快速搭建ETL产品提供解决方案,让用户低代码乃至零代码将ETL产品集成到自己的项目或产品生态中。
- 该产品由etl-engine引擎和etl-designer云端设计器及etl-crontab调度组成。
- etl-engine引擎负责解析ETL配置文件并执行ETL任务;
- etl-designer云端设计器通过拖拉拽的方式生成etl-engine引擎可识别的ETL任务配置文件;
- etl-crontab调度设计器负责按时间周期执行指定的ETL任务,及查询ETL任务执行日志功能。

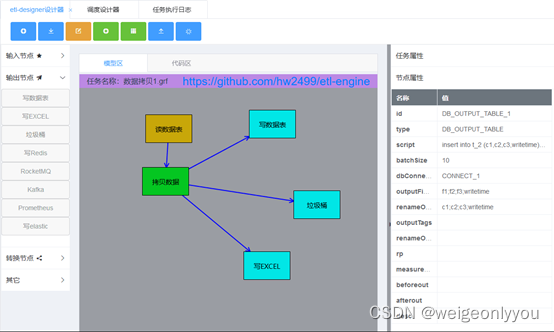
应用场景
异构系统数据交换
- 传统行业各业务系统数据相对独立,随着信息平台一体化、数据中台及大数据时代的推进,要求各业务系统数据相互融合,业务资源共享。
- etl-engine支持对关系型数据库、时序数据库等不同媒体进行数据交换。
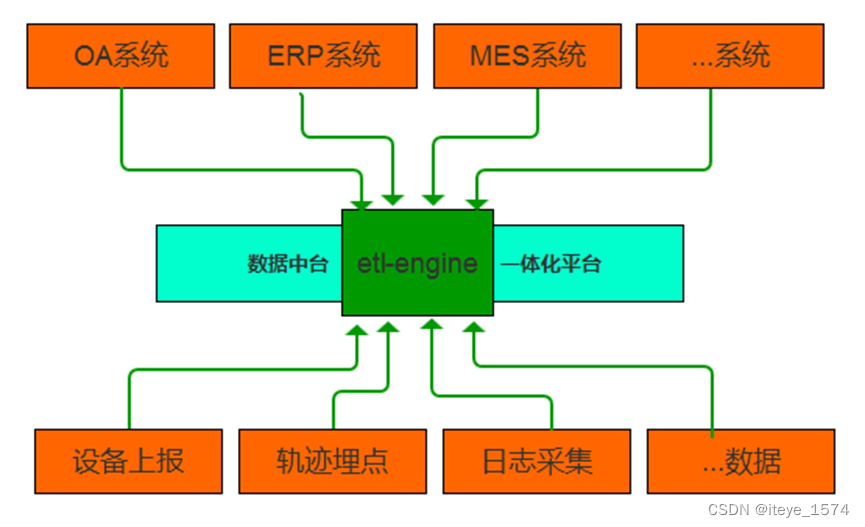
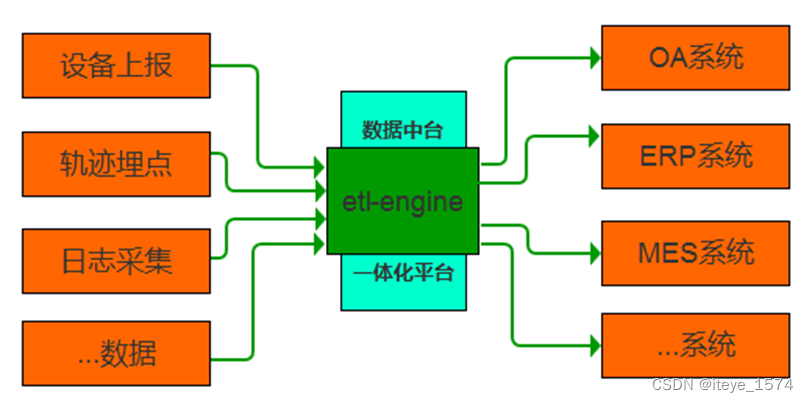
数据分发网关
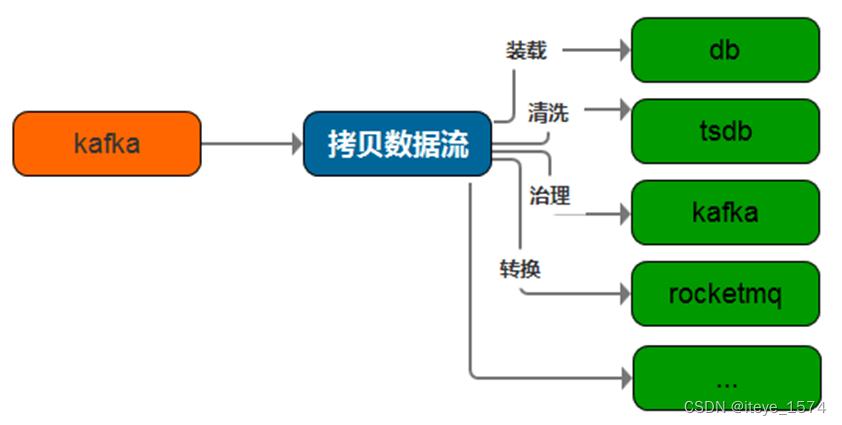
- 电商、物联网等领域在设备上报数据、日志采集、轨迹埋点等场景中从数据接收、再次加工、数据分发、数据格式化存储的要求尤为突出。
- etl-engine支持kafka、rocketmq、prometheus等多种数据源的接收;
支持在接收过程中对数据进行各种转换、清洗、治理; - 支持将同一数据源的数据经过再次加工后同时分发到多种目标中。
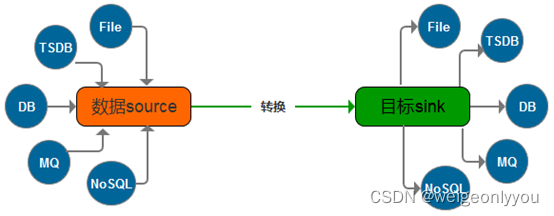
融合查询
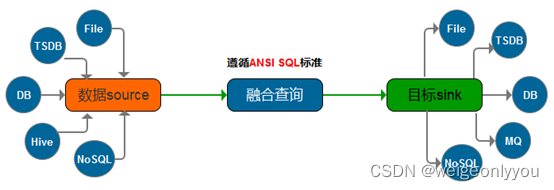
以往数据迁移过程是从一个A数据源到抽取、转换、再装载到另一个B数据源的过程,然后再做查询分析,即将多个业务系统产生的数据抽取到数据仓库中,然后再对数据仓库中事实表和维表进行统计查询及分析,相当于是两阶段操作。
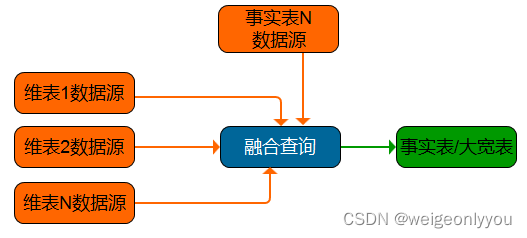
融合查询可同时从多个业务系统中读取数据,并在内存中对已读取的数据做数据关联查询,最终将关联后的结果输出到数据仓库,对比上述场景是一个轻量级的一阶段操作,常用在将多个维表数据转换成一个大宽表的场景。
 ### 流式计算
### 流式计算
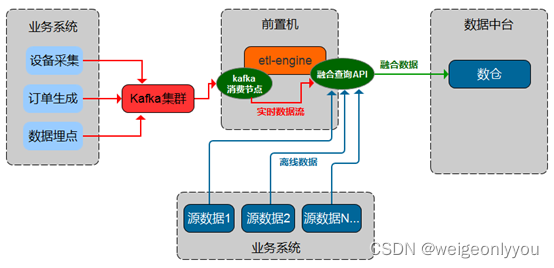
互联网诞生之初虽然数据量暴增,单日事实表条数达千万级别,但客户需求场景更多是“t+1”形式,只需对当日、当周、当月数据进行分析,这些诉求仅离线分析就可满足。
随着大数据领域不断发展,企业对于业务场景的诉求也从离线的满足转到高实时性的要求,数栈产品也在这一过程中进行着不断的迭代升级,随之数据栈诞生了kafka + flink组合实现对动态数据进行流式计算,同时kafka + etl-engine(融合计算的加持)组合也实现了轻量级的流式计算引擎。
产品优势
-
轻量级
该产品由Go语言开发,与生俱来的效率高,无需依赖各种动态库、静态库,部署方便,开箱即用,轻量级引擎。 -
流批一体融合查询
支持对多种类别数据库之间读取的数据进行融合查询。
支持消息流数据传输过程中动态产生的数据与多种类型数据库之间的流计算查询。
融合查询语法遵循ANSI SQL标准。 -
配置简单
通过云端etl-designer设计器,可视化拖拉拽方式就可以实现ETL任务的定制化配置工作及调度配置工作。 -
跨平台
直接编译成二进制文件,支持跨平台执行(windows、linux、mac),只需要一个可执行文件和一个配置文件就可以运行,无需其它依赖。 -
集成度高
etl-crontab调度集成了etl-designer云端设计器,只需运行一个执行文件即获得两个产品功能,支持HTTP/HTTPS协议访问,为方便用户产品集成,该功能可根据需要独立分发也可集成分发。 -
解析Go脚本
etl-engine中任意一个输出节点都可以嵌入go语言脚本并进行解析性运行,实现对输出数据流的格式转换功能。 -
动态配置
为满足业务场景需要,etl-engine支持ETL配置文件中使用外部传递的全局变量,实现动态更新ETL配置文件功能。 -
遵循pipeline模型
任意一个输入节点可以同任意一个输出节点进行组合;
任意一个输入节点都可以通过组合数据流拷贝节点,实现从一个输入同时分支到多个输出的场景;
任意一个输出节点都可以嵌入go语言脚本并进行解析,实现对输出数据流的格式转换功能。 -
支持二开
支持节点级二次开发,通过配置自定义节点,并在自定义节点中配置go语言脚本,可扩展实现各种功能操作。 -
日志查询
支持对etl-engine各节点执行情况的查询功能,方便监控执行轨迹。 -
执行情况报警
支持将任务执行失败情况通过HTTP/HTTPS、SMS方式上送报警功能。 -
安全性
暴露的服务接口支持HTTPS证书双向认证、Basic Auth认证、Token方式访问。 -
高可用
支持将N个etl-crontab服务端注册到consul服务中心,集成商可通过从consul服务中心发现etl-crontab服务端地址,以实现高可用。
支持部署模式
- 按原有产品功能前后端集成或前后端分离部署;
- 按用户个性化需求定制开发部署;
支持操作系统
Windows、Linux、Unix、Mac
支持数据源类型
- 文件类型
Excel、CSV - 数据库类型
MySQL、PostgreSQL、Oracle、Sqlite、Redis - 消息中间件
Kafka、Rocketmq - 时序数据库
Influxdb、Clickhouse、Prometheus - Hadoop生态
Hive
产品试用地址
github地址
https://github.com/hw2499/etl-engine
技术支持
vx : weigeonlyyou
- 1

