
- 1MySQL 学习笔记(一)_费霄霄
- 2git从clone到pr的全流程_怎么git 去pr别的项目
- 3九大数据分析方法:矩阵分析法
- 4【人工智能】 使用线性回归预测波士顿房价 paddlepaddle 框架 飞桨
- 5【AI原理解析】— 字节豆包模型_豆包语言模型
- 6ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory解决方案
- 7TortoiseGit 使用说明_tortoisegit弹出no working directory found
- 8SD-WAN:成功部署的七个步骤_开源sdwan部署
- 9深度学习四大框架之争(Tensorflow、Pytorch、Keras和Paddle)_pytorch、tensorflow,padl
- 10软件测试52讲-笔记(持续更新中...)_软件测试52讲 百度云
Swin transformer详解
赞
踩

目录
3.7 Window Attention (W-MSA Module) ☆
摘要
本文介绍了一种称为 Swin Transformer 的新视觉 Transformer,它可以作为 CV 的通用主干。将 Transformer 从语言适应到视觉方面的挑战来自 两个域之间的差异,例如视觉实体的规模以及相比于文本单词的高分辨率图像像素的巨大差异。为解决这些差异,我们提出了一种 层次化 (hierarchical) Transformer,其表示是用 移位窗口 (Shifted Windows) 计算的。移位窗口方案通过 将自注意力计算限制在不重叠的局部窗口的同时,还允许跨窗口连接来提高效率。这种分层架构具有在各种尺度上建模的灵活性,并且 相对于图像大小具有线性计算复杂度。Swin Transformer 的这些特性使其与广泛的视觉任务兼容,包括图像分类(ImageNet-1K 的 87.3 top-1 Acc)和 密集预测任务,例如 目标检测(COCO test dev 的 58.7 box AP 和 51.1 mask AP)和语义分割(ADE20K val 的 53.5 mIoU)。它的性能在 COCO 上以 +2.7 box AP 和 +2.6 mask AP 以及在 ADE20K 上 +3.2 mIoU 的大幅度超越了 SOTA 技术,证明了基于 Transformer 的模型作为视觉主干的潜力。分层设计和移位窗口方法也证明了其对全 MLP 架构是有益的。
一、介绍
CV 建模一直由 CNN 主导。从 AlexNet 和它在图像分类挑战上的革命性性能开始,CNN 架构已通过更大规模的、更广泛的连接和更复杂的卷积形式变得越来越强大。随着 CNNs 作为各种视觉任务的主干网络,这些架构的进步促进了性能的提升,并广泛地带动了整个领域的发展。另一方面,在 NLP 中,网络架构的发展已采取了一条不同的道路,即时至今日流行的架构是 Transformer。为序列建模和转换任务而设计的 Transformer,因其注意力机制对数据中的长程依赖性进行建模而闻名。它在语言领域的巨大成功使研究人员研究了它对计算机视觉的适应性,最近它在某些任务上展示了良好的结果,特别是图像分类和联合视觉-语言建模。本文试图扩大 Transformer 的适用性,使它可以作为 CV 的通用主干,正如其在 NLP 和 CNNs 在 CV 中一样。我们注意到将其在语言领域的高性能迁移到视觉领域的显著挑战,而这可用 两种模态之间的差异 来解释。
其中一种差异涉及尺度 (scale)。与在语言 Transformer 中作为处理的基本元素的 word token 不同,视觉元素在尺度 (scale) 上可以存在很大差异,这是一个在目标检测等任务中受到关注的问题。在现有的基于 Transformer 的模型中,token 的尺度 (scale) 都是固定的,这是一种不适合这些视觉应用的性质。另一个差异是,图像中的像素分辨率比文本段落中的文字要高得多。存在许多视觉任务 ,如语义分割,需在像素级别上进行密集预测,这对于高分辨率图像上的 Transformer 而言是难以处理的,因为其 自注意力的计算复杂度是关于图像大小的二次方。

图 1
为克服这些问题,Swin Transformer 构造了层次化特征图,且关于图像大小具有线性计算复杂度。如图 1 (a) 所示,Swin Transformer 通过 从小尺寸 patch (灰色轮廓) 开始,逐渐在更深的 Transformer 层中合并相邻 patch,从而构造出一个层次化表示 (hierarchical representation)。通过这些层次化特征图,Swin Transformer 模型可方便地利用先进技术进行密集预测,例如特征金字塔网络 (FPN) 或 U-Net。线性计算复杂度是通过在图像分区的非重叠窗口内,局部地计算自注意力来实现的 (红色轮廓) (而非在整张图像的所有 patch 上进行)。每个窗口中的 patch 数量是固定的,因此复杂度与图像大小成线性关系。这些优点使 Swin Transformer 适合作为各种视觉任务的通用主干,与之前基于 Transformer 的架构形成对比,后者产生单一分辨率的特征图并具有二次复杂度。
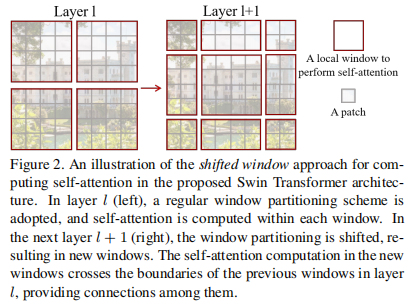
图 2
Swin Transformer 的一个关键设计元素是它 在连续自注意力层之间的窗口分区的移位 (shift),如图 2 所示。移位窗口桥接了前一层的窗口,提供二者之间的连接,显着增强建模能力 (见表 4)。这种策略对于现实世界的延迟也是有效的:一个局部窗口内的所有 query patch 共享相同的 key 集合,这有助于硬件中的内存访问。相比之下,早期的 基于滑动 (sliding) 窗口的自注意力方法 由于 不同 query 像素具有不同的 key 集合 而在通用硬件上受到低延迟的影响。我们的实验表明,所提出的移位窗口方法的延迟比滑动窗口方法低得多,而建模能力相似 (见表 5 / 6)。移位窗口方法也被证明对全 MLP 架构有益。
所提出的 Swin Transformer 在图像分类、目标检测和语义分割的识别任务上取得了强大的性能。它在三个任务上以相似的延迟显着优于 ViT / DeiT 和 ResNe(X)t 模型。 我们相信,跨 CV 和 NP 的统一架构可以使这两个领域受益,因为它将促进视觉和文本信号的联合建模,并且可以更深入地共享来自两个领域的建模知识。我们希望 Swin Transformer 在各种视觉问题上的强大表现能够在社区中更深入地推动这种信念,并鼓励视觉和语言信号的统一建模。
二、原理
2.1 整体架构
2.1.1 Architecture
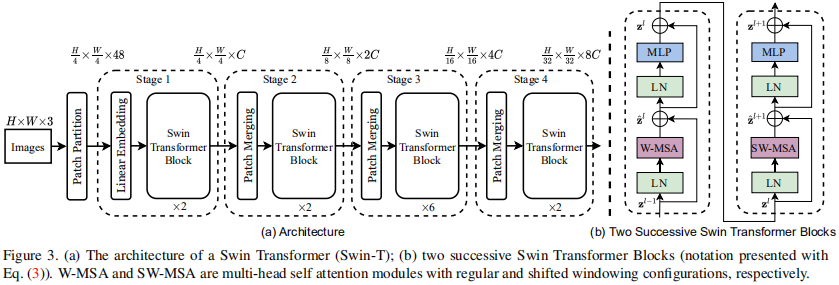
图 3
图 3 展示了 Swin Transformer 架构概览 (tiny 版 SwinT)。它首先通过 Patch 拆分模块 (Patch Partition) (同 ViT) 将输入的 H×W×3
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

