
- 1Go语言开发利器:几种主流IDE的优势与应用_go语言开发工具
- 2计算机网络第四章:网络层_网络层分组传输的基本方式有哪些
- 3栈结构之链栈详解(C语言版)
- 4【ESP32大作业】基于onenet云平台的家居门禁系统_esp32门禁
- 5【专题】2024家·生活智能家居趋势报告合集PDF分享(附原数据表)
- 6RGMII简介及收发端口延时模式下时序图
- 7R语言glm函数构建二分类logistic回归模型、epiDisplay包logistic.display函数获取模型汇总统计信息(自变量初始和调整后的优势比及置信区间,回归系数的Wald检验的p值_glm系数 wald
- 8HuggingFace 机器学习总监、Grafana Labs 团队与你相约 KubeCon 2023!
- 9【华为OD机试真题】421、来自异国的客人 | 机试真题+思路参考+代码解析(CD卷)(C++、Java、Py)(本题100%)_来自异国的客人 od
- 10stable diffusion+LangChain+LLM自动生成图片_stable diffusion接入llm
超详细解读 Transformer 框架!建议收藏!_transformer架构
赞
踩
Transformer 是由谷歌大脑2017年在论文《Attention is All You Need》中提出的一种序列到序列(Seq2Seq)模型。自提出伊始,该模型便在NLP和CV界大杀四方,多次达到SOTA效果。NLP领域中,我们所熟知的BERT和GPT就是从Transformer中衍生出来的预训练语言模型。
本篇将对 Transformer 框架进行详细的解读,和大家一起深入理解Transformer的原理和机制。
1. 什么是Transformer?
首先我们先对Transformer来个直观的认识。Transformer出现以前,NLP领域应用基本都是以RNN或LSTM循环处理完成,一个token一个tokrn输入到模型中。模型本身是一种顺序结构,包含token在序列中的位置信息。但是存在了一些问题:
-
会出现梯度消失现象,无法支持长时间序列。
-
句子越靠后的token对结果的影响越大。
-
只能利用上文信息,无法获取下文信息。
-
循环网络逐个token输入,也就是句子有多长就要循环多少遍,计算的效率低。
而Transformer的出现得以解决了上述的一系列问题。
2. Transformer架构
2.1. 宏观层面
首先将Transformer可以看成是一个黑箱操作的序列到序列(seq2seq)模型,输入是单词/字母/图像特征序列,输出是另外一个序列。一个训练好的Transformer模型如下图所示:

在机器翻译中,就是输入一种语言(一连串单词),经Transformer输出另一种语言(一连串单词)。

拆开这个黑箱,可以看到模型本质就是一个Encoder-Decoder结构,由编码组件、解码组件和它们之间的连接组成。
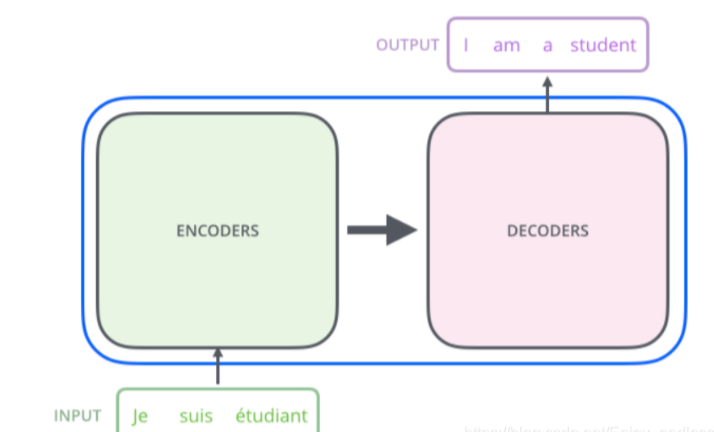
每个Encoders中分别由6层Encoder组成,而每个Decoders中同样也是由6层Decoder组成。
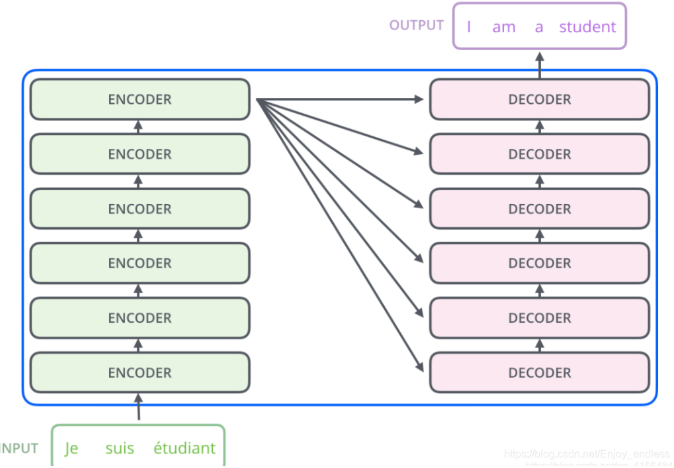
每一层Encoder的结构都是相同的,但是它们的权重参数不同。
每个Encoder里面又分为两层。
-
Self-Attention Layer
-
Feed Forward Neural Network,前馈神经网络
输入Encoder的文本数据,首先会经过一个self-attention层,这个层处理一个词的时候,不仅会使用这个词本身的信息,还会关注上下文其它词的信息。
self-attention的输出会被传入一个全连接的前馈神经网络,每个Encoder的前馈神经网络参数个数都是相同的,但是他们的作用是独立的。如下图:
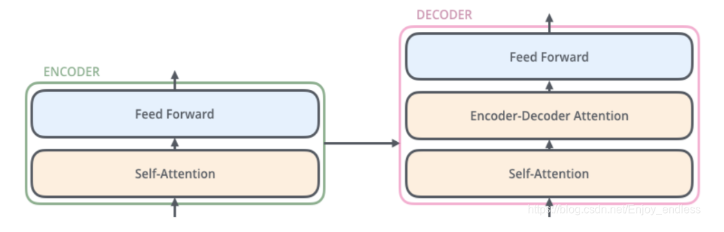
每个Decoder也同样具有这样的层级结构,但是在这之间有一个Attention层,这个层能帮助Decoder聚焦于输入句子的相关部分。
2.2. 微观层面
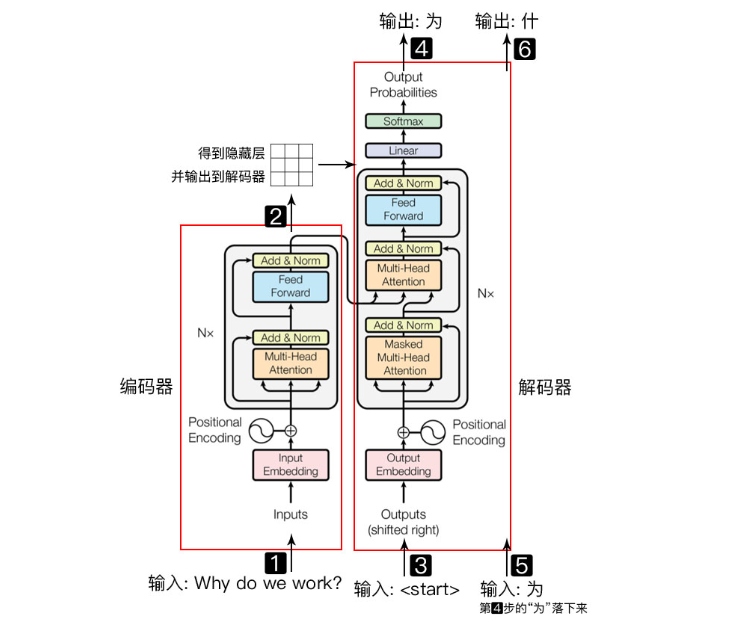
Transformer内部结构如下图所示,由Encoder和Decoder两大部分组成。其中,Encoder负责将输入的自然语言序列映射成为隐藏层,然后Decoder将隐藏层映射为自然语言序列。
如下图所示是以机器翻译为例,说明模型具体运行过程:
-
输入自然语言序列到Encoder:Why do we work?(我们为什么工作);
-
Encoder输出的隐藏层,再输入到解码器;
-
输入
<start>(起始)符号到解码器; -
得到第一个字"为";
-
将得到的第一个字"为"落下来再输入到解码器;
-
得到第二个字"什";
-
将得到的第二字再落下来,直到解码器输出
<end>(终止符),即序列生成完成。
2.2.1. Encoder
下面我们再逐步拆开理解,首先是Encoder,即把自然语言序列映射为隐藏层的数学表达的过程。下图为一个Encoder block结构图。
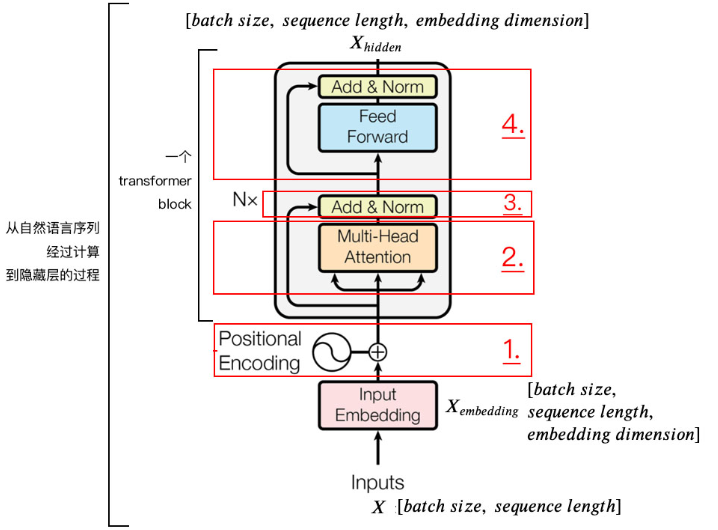
2.2.1.1. 输入嵌入(input Embedding)
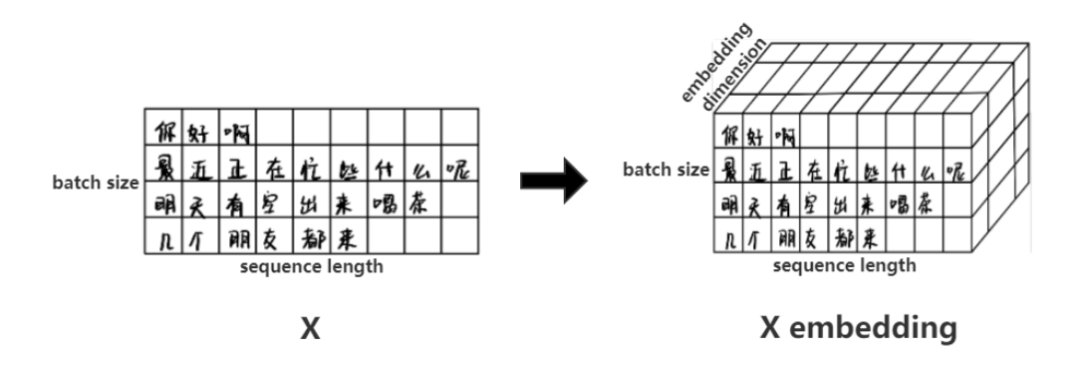
输入数据X维度为:[batch_size, sequence_length],比如输入“你好啊。最近正在忙什么呢?明天有空出来喝茶。几个朋友都来。”,batch size指的是句子数,sequence length指的是输入的句子中最长的句子的字数。这里共四句话,所以bacth_size为4。最长的句子是8个,所以sequence_length为8。输入数据维度为[4,8]。
但是,我们不能直接将这些语句输入到Encoder中,因为Transformer不认识,所以需要先进行Embedding,找到每个字的数学表达,即得到图中的input Embedding,通过查表得到字向量,它的维度就变为
[batch_size,sequence_length,embedding_dimmension],
其中,embedding_dimmension表示字向量的长度。
简单来说,就是字->词向量的转换,这种转换是将字转换为计算机能够辨识的数学表示,用到的方法是Word2Vec。得到的的维度是
[batch_size,sequence_length,embedding_dimmension]。其中,embedding_dimmension的大小由Word2Vec算法决定,例如Transformer采用512长度的词向量。因此,的维度是[4,8,512]。如下图所示。
2.2.1.2. 位置编码(Positional Encoding)
Transformer以token作为输入,将token进行input Embedding之后,再和Positional Encoding相加。「注意这里不是拼接,而是对应位置上的数值进行加和。」
上文我们提到,input Embedding的维度是512,由于是相加关系,自然而然地,这里Positional Encoding的维度也是512。
为什么要使用Positional Encoding呢?我们知道,NLP领域中,模型的输入是一串文本,也就是序列Sequence。
而在以前的模型(RNN或LSTM)中,NLP的每个序列都是一个字一个字的输入到模型当中。比如有一句话是“我喜欢吃洋葱”,那么输入模型的顺序就是
“我”,“喜”,“欢“,”吃“,”洋“,”葱”,一个字一个字的。
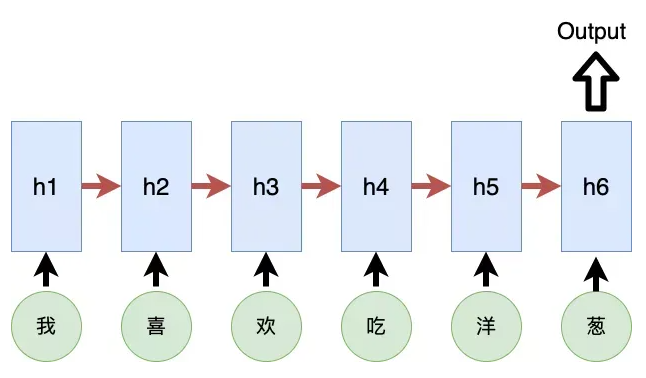
这样的输入方式其实就引入了一个问题。一个模型每次只吃了一个字,那么模型只能学习到前后两个字的信息,无法知道整句话讲了什么。为了解决这个问题,Transformer模型引用了Self-attention来解决这个问题。Self-attention的输入方式如下:
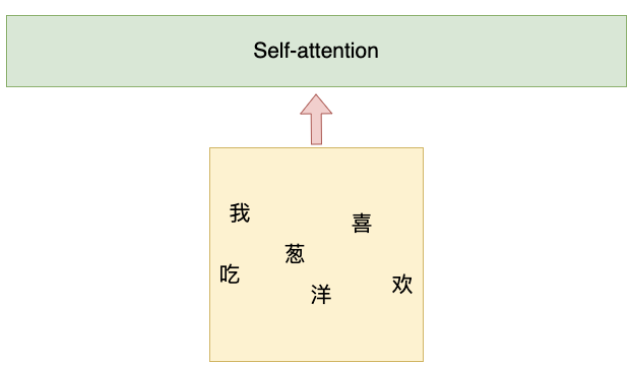
它可以一次性输入所有的字。但是NLP的输入文本要按照一定的顺序才可以,因为不同的语序,语义很有可能是不同的。比如下面两句话:
句子1:我喜欢吃洋葱 句子2:洋葱喜欢吃我
所以,对于Transformer结构而言,为了更好的发挥并行输入的特点,首先要解决的问题就是要让模型输入具有一定的位置信息。「因此,Transformer加入了Positional Encoding机制。」
2.2.1.2.1. 构造位置编码
「用整型值标记位置」
说起标记位置,大概首先能想到的方法就是给第一个字标记1,第二个字标记2…,以此类推。但是,
-
在处理不同长度的句子时,模型可能碰到比训练的序列更长的句子,这将不利于模型泛化。
-
随着序列长度增加,位置标记值越来越大,模型将很难学习到这些位置信息。
「用[0,1]范围标记位置」
这时候可以将模型位置值限制在[0,1]范围内,来解决上述问题。其中,第一个字标记0,最后一个字标记1,中间的均分,比如共3个字,位置信息就是[0, 0.5, 1];4个字位置信息就是[0, 0.33, 0.69, 1]。
但是这样,序列长度不同时,字与字的相对距离是不同的。
所以,理想情况下,Positional Encoding的设计应该满足以下条件:
-
为每个字输出唯一的编码可以表示每个字在序列中的绝对位置;
-
不同长度的序列之间,任意两个字的距离/相对位置应该保持一致;
-
可以表示模型在训练中未遇到过的句子长度。
「绝对位置」:“我”是第一个字,“喜”是第二个字,…
「相对位置」:“喜”在“我”的后面一位,“吃”在“喜”的后面两位…
「两个字之间的距离」:“我”和“喜”差1个位置,“我”和“吃”差3个位置…
「用二进制向量标记位置」
位置信息是作用在input Embedding上的,因此可以用一个和input Embedding维度一致的向量表示位置。这里以d_model=3为例,位置向量可以表示为下图所示。
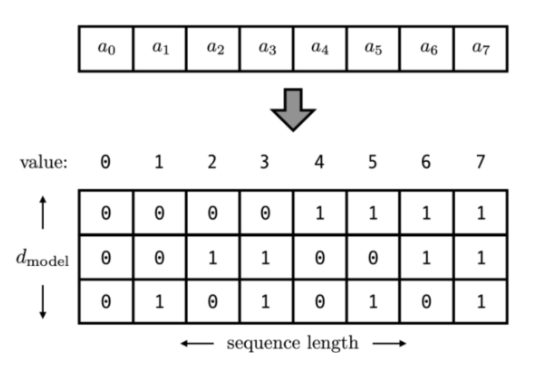
这样满足所有值都是有界的(位于0、1之间),且Transformer中d_model=512,足够将每个位置都编码出来了。
但是,这样编码的位置向量,处在一个离线空间,不同位置间的变化是不连续的。
「用周期函数(sin)标记位置」
到这里,我们更明确了,需要的是有界且连续的函数,最先想到的,正弦函数sin可以满足吧。
我们可以将位置向量中的每个元素都用一个sin函数表示,第t个字的位置可以表示为:

如下图所示,每一行表示一个,每一列表示中的第i个元素。旋钮用于调整精度,越往右边的旋钮,需要调整的精度越大,因此指针移动的步伐越小。
每一排的旋钮都在上一排的基础上进行调整(函数中t的作用)。通过频率控制sin函数的波长,频率不断减小,则波长不断变大,此时sin函数对t的变动越不敏感,以此来达到越向右的旋钮,指针移动步伐越小的目的。
「为什么波长与频率成反比?」
对于三角函数,
周期是π,频率是π,因此B越大,频率越大,一个周期内函数图像重复次数越多,波长越短。
这也类似于二进制编码,每一位上都是0和1的交互,越往低位(左移),交互的频率越慢。

此外,由于sin是周期性函数,纵向看,如果函数频率偏大,引起波长偏短,则不同t对应的位置向量可能会存在重合。例如下图中(d_model=3),图中点表示序列中每个字的位置向量,颜色越深,字的位置越靠后,在频率偏大时,位置向量点连成了一个闭环。
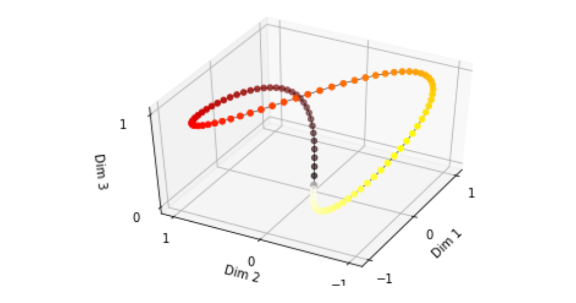
为了避免这种情况,则要尽量把波长拉长。最简单的方法就是把所有的频率尽可能设小。因为,在Transformer论文中,频率设为。
所以,到这里,位置向量可以表示为:
其中,
「用sin和cos交替标记位置」
目前为止,位置向量已经满足:
-
每个字的向量唯一(每个sin函数频率足够小,波长足够长,不会重合)。
-
位置向量的值有界,且连续。模型在处理位置向量时泛化性强,即更好处理长度和训练数据分布不一致的序列。
但是,我们还希望不同的位置向量是可以通过线性变换得到的。这样,不仅能表示一个字的绝对位置,还可以表示一个字的相对位置。即:
这里,T表示一个线性变化矩阵。假设t是一个角度值,就是旋转的角度,则上面的公式可以写为:
这样就可以把原来元素全都是sin函数的做一个替换,让位置两两一组,分别用sin和cos的函数对表示。即:
在这样的表示下,我们可以很容易用一个线性变换,把转变为
2.2.1.3. Transformer位置编码
Positional Encoding定义如下:
其中,
-
t表示序列中某个字的实际位置,例如第一个字为1,第2个字为2。
-
表示t位置处的字的Positional Encoding向量,该向量可以用来给句子中每个字提供位置信息。换句话说,就是我们通过注入每个字的位置信息,增强了模型输入。
-
k表示向量中每个元素的index。
-
表示向量的维度,即512。
其实这里的公式和上面提到的是一模一样。
把512维的向量两两一组,每组都是一个cos和一个sin,这两个函数共享一个频率,共256组,由于从0开始编号,所以最后编号是255。
回到定义中,k越来越大,越来越小,π也越来越小,所以,频率随着k的递增而递减,周期递增。时,周期最小是2π;时,周期也就是波长最大是10000*2π。
为什么要将Transformer的每个维度设计成周期形式呢?如下图所示是0-15的二进制形式。可以看出,不同位置的数字都会出现0、1的交替变化。
2.2.1.4. 可视化
如下图所示是一串序列长度为50、位置编码维度是为128位置编码可视化效果。
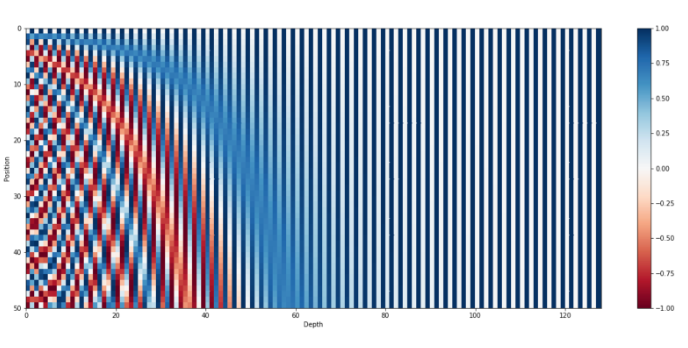
由此可以发现位置向量的每一个值都位于[-1, 1]之间。同时,纵向来看,图的右半边几乎都是蓝色的,这是因为越往后的位置,频率越小,波长越长,所以不同的t对最终的结果影响不大。而越往左边走,颜色交替的频率越频繁。
2.2.2. 自注意力机制(Self Attention Mechanism)
注意力机制,顾名思义,就是我们对某件事或某个人或物的关注重点。举个生活中的例子,当我们阅读一篇文章时,并非每个词都会被同等重视,我们会更关注那些关键的、与上下文紧密相关的词语,而非每个停顿或者辅助词。
对于没有感情的机器来说其实就是赋予多少权重(比如0-1之间的小数),越重要的地方或者越相关的地方赋予的权重越高。
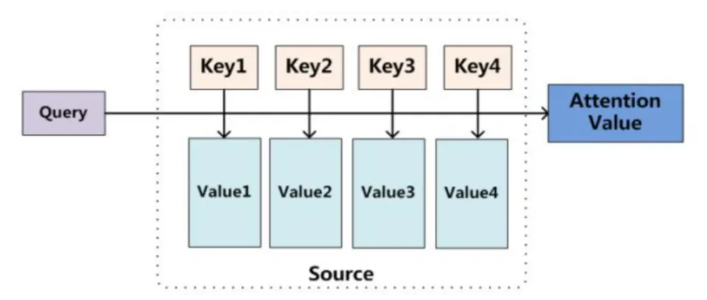
在技术实现层面,注意力机制通常涉及三个核心概念:Query、Key和Value。其中,
-
查询(Query,Q):指的是查询的范围,自主提示,即主观意识的特征向量。
-
键(Key,K):指的是被比对的项,非自主提示,即物体的突出特征信息向量。
-
值(Value,V) : 则是代表物体本身的特征向量,通常和Key成对出现。
注意力机制是通过Query与Key的注意力汇聚(给定一个 Query,计算Query与 Key的相关性,然后根据Query与Key的相关性去找到最合适的 Value)实现对Value的注意力权重分配,生成最终的输出结果。
举个例子,
-
我们淘宝购物时,会输入一句关键词(比如:高腰),这个就是Query。
-
搜索系统会根据关键词查找一系列相关的key(商品名称+图片)。
-
最后系统会将相应的Value(具体的衣服)输出。
Q、K和V虽然在不同的空间,其实它们是有一定潜在联系的,也就是说通过某种变换,可以使得三者的属性在一个相近的空间中。
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
注意力机制和自注意力机制的区别:
-
注意力机制的Q和K是不同来源的,例如,在Encoder-Decoder模型中,K是Encoder中的元素,而Q是Decoder中的元素。在中译英模型中,Q是中文单词特征,而K则是英文单词特征。
-
自注意力机制的Q和K则都是来自于同一组的元素,例如,在Encoder-Decoder模型中,Q和K都是Encoder中的元素,即Q和K都是中文特征,相互之间做注意力汇聚。也可以理解为同一句话中的词元或者同一张图像中不同的batch,这都是一组元素内部相互做注意力机制,因此,自注意力机制也被称为内部注意力机制。
2.2.2.1. 运行步骤
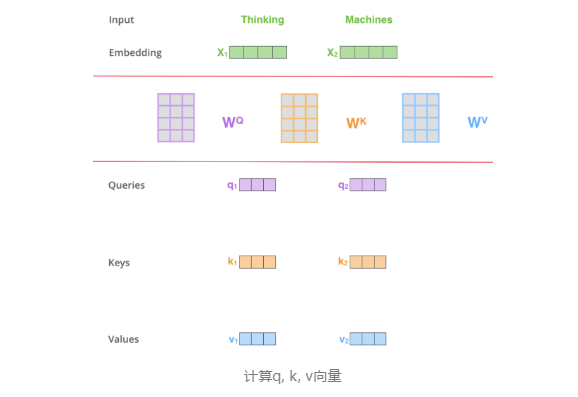
步骤1. 对输入Encoder的每个词向量,都创建3个向量,分别是:Q向量,K向量,V向量。
上文中提到,
input= input Embedding+ Positional Embedding
词嵌入与位置向量相加可以得到句中每个单词的词向量表示,第t个词的词向量记作。
对于每个词向量,分别乘以权重矩阵、、,即可得到新的向量、、。而权重矩阵、、即为我们要学习的参数。
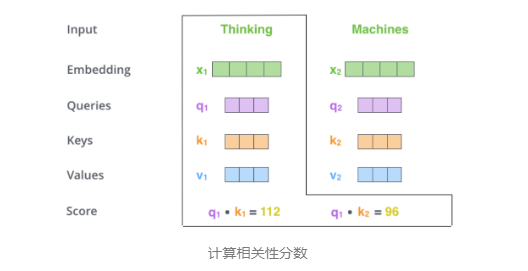
步骤2. 计算一个注意力分数Attention Score。假设我们正在计算本例中第一个词“Thinking”的注意力分数。这个分数就决定着“Thinking”这个词在某句话中与其他词的关联程度,所以“Thinking”这个词要与其他所有词都计算一个分数。
这个分数是通过Q向量与其它位置的每个词的K向量进行点积求得。例如我们要计算句子中第一个位置单词的score,那么第一个分数就是 q1 和 k1 的内积,第二个分数就是 q1 和 k2 的点积。
其意义就是比较两个向量的相关程度,越相关值越大。如下图。
步骤3. 每个score除以(是key向量的长度)。也可以除以其他数,这里除以一个数是为了在反向传播时,求取梯度更加稳定。论文中除以Q向量维度的平方根8,即。
然后通过softmax操作映射出最后的结果。Softmax对分数进行归一化处理,使它们都为正且加起来为1。如下图所示:
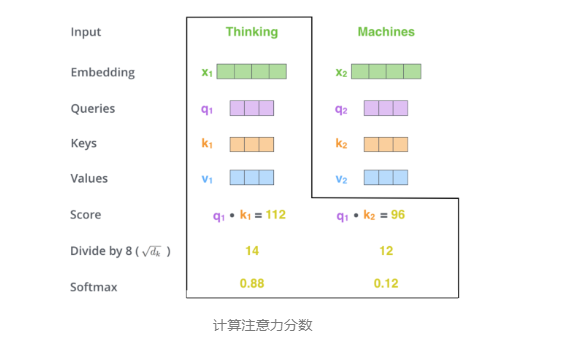
softmax结果决定了每个词在句子中每个位置的重要性。很明显,这个词与其本身的softmax结果最高,因为它的Q、K、V向量都是源于其本身。
步骤4. 得到每个位置的分数后,将每个分数分别与每个Value向量相乘,使得每个单词重要程度进行重新分配。对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的,这样我们就忽略了这些位置的词。
最后再加权值求和,产生Self-Attention输出。如下图所示:
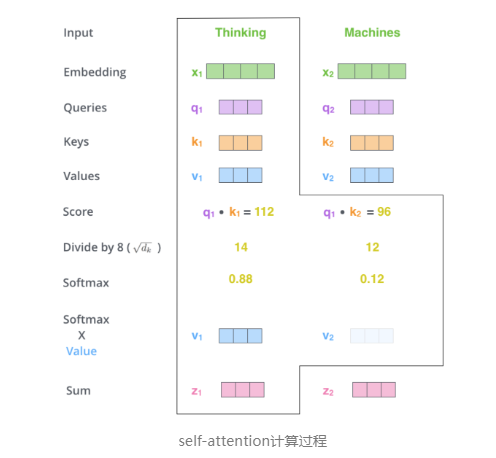
自注意力计算到此结束。
「Tip」
在实际中,我们通常会将输入词向量打包成矩阵,然后分别和3个权重矩阵、、相乘,得到Q,K,V矩阵。如下图所示:
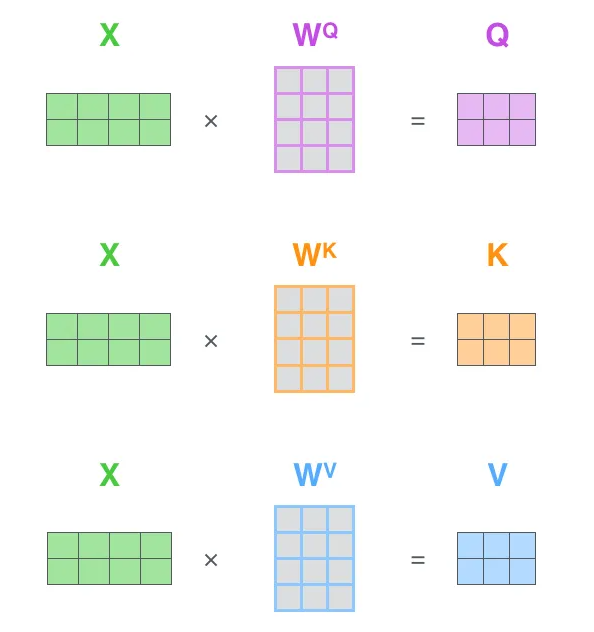
矩阵X中的每一行,表示句子中的每一个词的词向量,长度是512。Q,K,V 矩阵中的每一行表示Query向量,Key向量,Value向量,向量长度是64。
接着进行矩阵运算,直接得到Self Attention的输出。
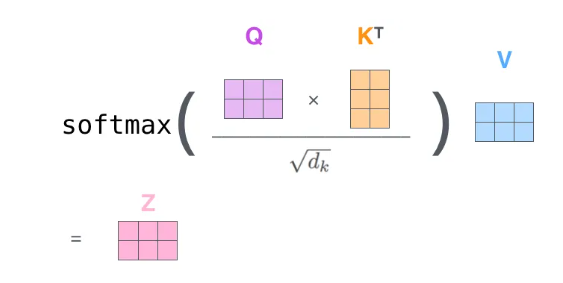
整体矩阵运算过程如下图所示,
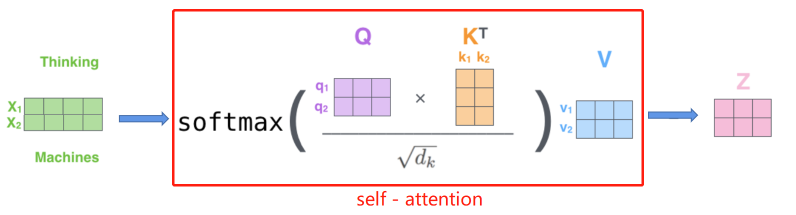
「自注意力机制的问题」
1)模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,有效信息抓取能力就差一些。2)我们前文也有提到,它会一次性输入所有的字,而没有考虑位置信息。但是NLP的输入文本要按照一定的顺序才可以,因为不同的语序,语义很有可能是不同的。
2.2.2.2. 多头注意力(Multi-Head Attention)
多头注意力即为:用独立学习得到的h组(一般h=8)不同的线性投影(linear projections)来变换查询Q、键K和值V。然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换,以产生最终输出。
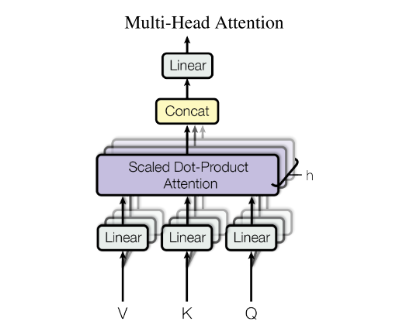
步骤1. 定义多组W,生成多组Q、K、V。刚才我们已经理解了,Q、K、V是输入向量分别乘上三个系数、、得到,、、是可训练的参数矩阵。
现在,对于同样的,我们定义多组不同的、、,比如、、、、、每组分别计算生成不同的Q、K、V,最后学习到不同的参数。
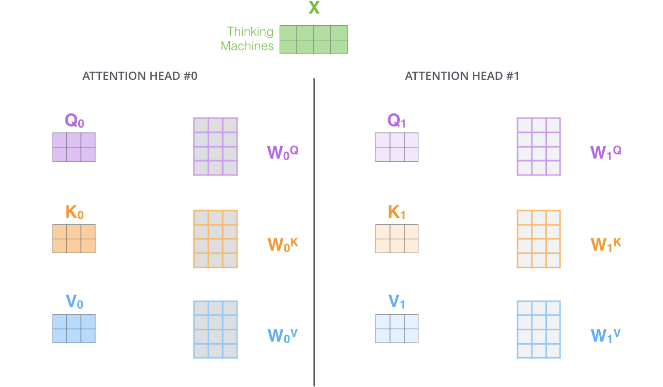
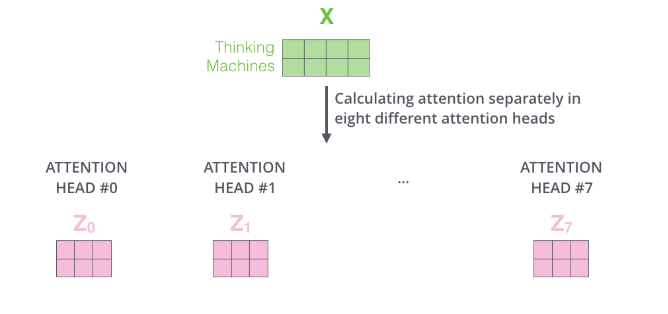
步骤2. 定义8组参数。对应8组参数矩阵、、,再分别进行self-attention,即可得到。每一组、、都可以得到一个输出矩阵。
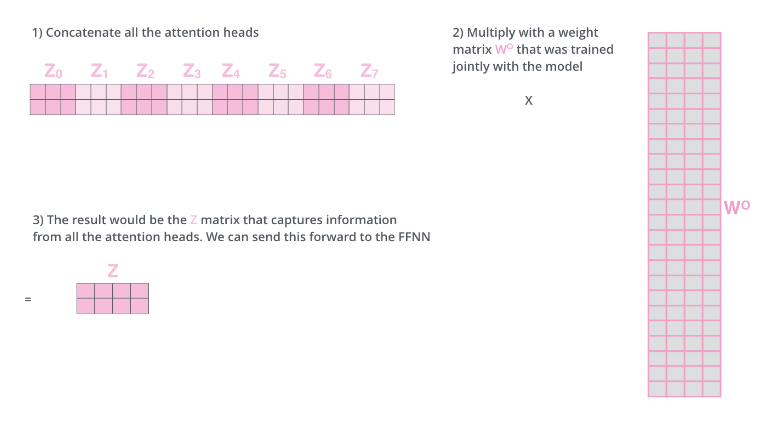
步骤3. 将多组输出拼接后乘以矩阵以降低维度。首先在输出到下一层前,需要将拼接,再乘以矩阵做一次线性变换降维,得到Z。
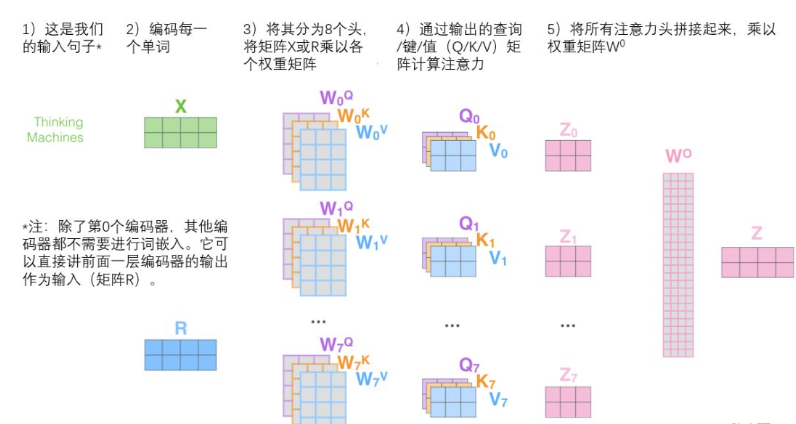
完整流程图如下:
2.2.2.3. 残差连接(Residual Connections)和层归一化(Layer Normalization)
「残差连接」
在上一步得到了经过注意力矩阵加权之后的V,也就是
现在进行转置,使其和维度一致,也就是[batch-size,sequence_length,embedding_dimmension],再把他们对应元素加起来做残差连接。
在之后的运算里,每经过一个模块的运算,都要把运算之前的值和运算之后的值相加,从而得到残差连接,训练的时候可以使梯度直接走捷径反传到最初始层:
「Layer Normalization」
Layer Normalization的作用是把神经网络中隐藏层归一为标准正态分布,也就是独立同分布,以起到加快训练速度,加速收敛的作用。
μ
上式中以矩阵的行(row)为单位求均值:
μ
上式中以矩阵的行(row)为单位求方差:
¥
然后用每一行的每一个元素减去这行的均值,再除以这行的标准差,从而得到归一化后的数值,是为了防止除0。之后引入两个可训练参数α,β来弥补归一化的过程中损失掉的信息,注意⊙表示元素相乘而不是点积,我们一般初始化α 为全1,而β为全0。
2.2.2.4. Add&Norm
Add & Norm层Add和Norm两部分组成,其计算公式如下:
其中,X表示输入向量,MultiheadAttention(X)表示多头注意力输出,FeedForward(X)表示前馈网络输出,输出与输入X 维度是一样的,所以可以相加。
Add指X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在ResNet中经常用到:

Norm指Layer Normalization,通常用于RNN结构,Layer Normalization会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
2.2.2.5. Feed Forward
Feed Forward层比较简单,是一个两层的全连接层,第一层的激活函数为Relu,第二层不使用激活函数,对应的公式如下。
X是输入,Feed Forward最终得到的输出矩阵的维度与X一致。
至此,MultiHeadAttention、FeedForward、Add&Norm就可以造出一个Encoder Block,Encoder block接收输入矩阵 ,并输出一个矩阵 。通过多个Encoder block叠加组成Encoder。
第一个Encoder block的输入为句子单词的表示向量矩阵,后续Encoder block的输入是前一个Encoder block的输出,最后一个Encoder block输出的矩阵就是编码输出,这一矩阵后续会用到Decoder中。
2.2.3. Decoder
由下图可以看出,Decoder结构从上到下依次是:
-
Masked Multi-Head Self-Attention
-
Multi-Head Encoder-Decoder Attention
-
FeedForward Network
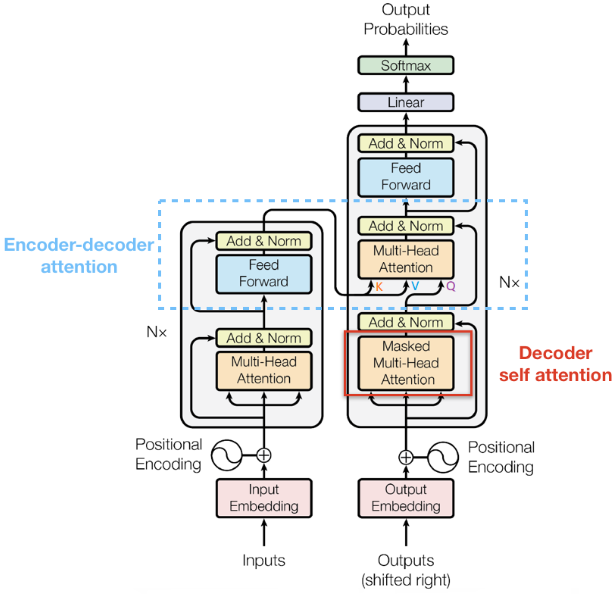
和Encoder一样,上面三个部分的每一个部分,都有一个残差连接,后接一个Layer Normalization。Decoder的中间部件并不复杂,大部分在前面Encoder里我们已经介绍过了,但是Decoder由于其特殊的功能,因此在训练时会涉及到一些细节。
-
包含两个Multi-Head Attention模块。
-
第一个 Multi-Head Attention层采用了Masked操作。
-
第二个 Multi-Head Attention层的K、V矩阵使用Encoder输出进行计算,而Q使用上一个Decoder block的输出计算。
-
最后有一个 Softmax 层计算下一个翻译单词的概率。
2.2.3.1. 第一个Multi-Head Attention
Decoder block的第一个Multi-Head Attention采用了Masked操作,因为在翻译的过程中是顺序翻译的,即翻译完第i个单词,才可以翻译第i+1个单词。通过Masked操作可以防止第i个单词知道i+1个单词之后的信息。下面以"我有一只猫"翻译成 "I have a cat"为例,了解一下Masked操作。
下面的描述中使用了类似Teacher Forcing的概念。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 “Begin” 预测出第一个单词为 “I”,然后根据输入 “Begin I” 预测下一个单词 “have”。

Decoder可以在训练的过程中使用Teacher Forcing并且并行化训练,即是指将正确的单词序列(I have a cat)和对应输出(I have a cat)传递到Decoder。那么在预测第i个输出时,就要将第i+1之后的单词掩盖住,注意Mask操作是在Self-Attention的Softmax之前使用的,下面用0 1 2 3 4分别表示 "I have a cat "。
步骤1. Decoder的输入矩阵和Mask矩阵。输入矩阵包含"<start>I have a cat" (0, 1, 2, 3, 4)五个单词的表示向量,Mask是一个5×5的矩阵。在Mask可以发现单词0只能使用单词0的信息,而单词1可以使用单词0, 1的信息,即只能使用之前的信息。
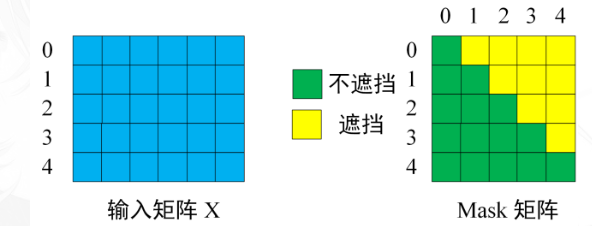
步骤2. 通过输入矩阵X计算得到Q、K、V矩阵。然后计算Q和的乘积。
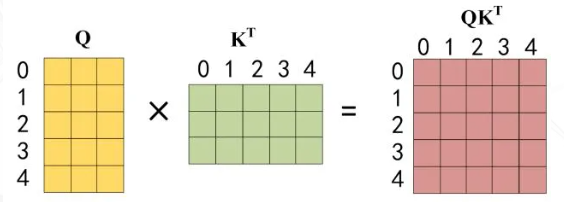
步骤3. 在得到之后需要进行Softmax,计算attention score。另外我们在Softmax之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
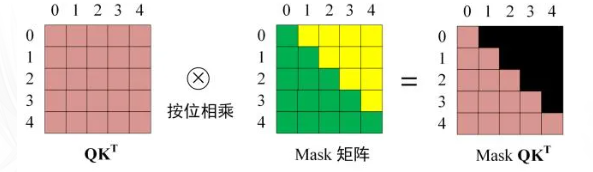
得到Mask之后在Mask上进行Softmax,每一行的和都为1。但是单词0在单词1, 2, 3, 4上的attention score都为0。
步骤4. 使用Mask与矩阵V相乘,得到输出Z,则单词I的输出向量是只包含单词1信息的。
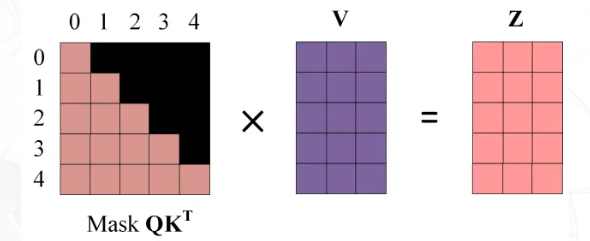
步骤5. 通过上述步骤就可以得到一个Mask Self-Attention的输出矩阵,然后和Encoder类似,通过Multi-Head Attention拼接多个输出然后计算得到第一个Multi-Head Attention的输出Z,Z与输入X维度一样。
2.2.3.2. 第二个Multi-Head Attention
Decoder block第二个Multi-Head Attention变化不大,主要的区别在于其中Self-Attention的K、V矩阵不是使用上一个Decoder block的输出计算的,而是使用Encoder的编码输出计算的。
根据Encoder的输出C计算得到K、V,根据上一个Decoder block的输出Z计算Q (如果是第一个Decoder block则使用输入矩阵X进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在Decoder的时候,每一位单词都可以利用到Encoder所有单词的信息 (这些信息无需Mask)。
2.2.3.3. Softmax预测输出单词
Decoder block最后的部分是利用Softmax预测下一个单词,在之前的网络层我们可以得到一个最终的输出Z,因为Mask的存在,使得单词0的输出Z0只包含单词0的信息,如下:
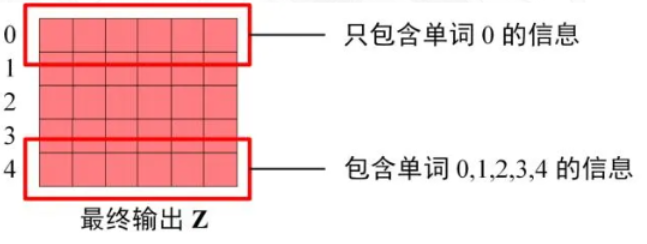
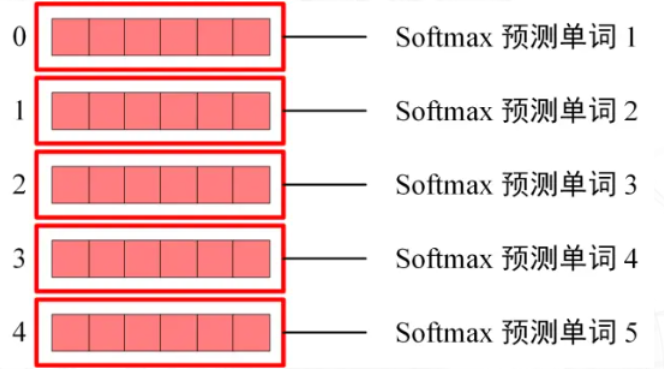
Softmax根据输出矩阵的每一行预测下一个单词:
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/926265
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

