
- 1python VTK example(2) --.vtp文件加载、保存_python读取vtp
- 2Tomcat6.0 Form验证及单点登陆配置
- 3人工智能就业待遇大揭秘,薪资为什么这么高?
- 4撤销 git add_idea git add 取消
- 5GraphWaveletNeuralNetwork:深度学习与图信号处理的创新融合
- 6自定义监控进程、日志、mysql主从状态、mysql主从延迟_监控mysql主从
- 7image segmentation_使用Python/scikit-image实现图像分割
- 8python爬取今日头条_使用python-aiohttp爬取今日头条
- 9github修改默认的分支_github修改默认分支
- 10KEPServerEX 6 之 安装报错-缺少根证书_kep6.4装不了
将大模型装进PC和手机,需要怎样的底层创“芯”?
赞
踩


当前,以生成式AI为代表的新一代人工智能技术持续火热,大模型推理场景向端侧加速迁移,在深度变革人机交互界面的同时,也为手机、PC等消费电子产业注入源源动能。然而,生成式AI对硬件的快速赋能背后,也对算力、存储等方面提出了新的需求。这些新的需求,也为芯片厂商、终端厂商以及应用开发者带来了新的挑战与新的机遇。
我们应该如何应对这些挑战?如何把握生成式AI带来的机遇呢?产业各界已经联手给出了答案。
近日,国内领先的通用计算CPU设计公司此芯科技正式推出了其首款专为AI PC打造的异构高能效芯片产品——“此芯P1”。据了解,这款芯片不仅异构集成了Armv9 CPU核心与Arm Immortalis GPU,还搭载了安谋科技“周易”NPU等自研业务产品,能够提供高效能的异构算力资源、系统级的安全保障以及技术生态支持,将更好地满足生成式AI在PC等端侧场景的应用需求。

除AI PC以外,AI手机同样热度高涨,三星、华为、小米、vivo、OPPO、荣耀等各大手机厂商也都在积极探索与端侧AI的深度融合,力求为用户带来更加智能化的新体验。
如此看来,推动端侧AI快速落地,需要更多类似的创新应用方案,而其中的底层技术革新更是关键所在。

众所周知,AI大模型从生产到应用主要包括“训练”和“推理”两个步骤。其训练和推理过程需要占用大量的计算资源和存储空间,通常部署在云计算平台上。而当用户调用智能对话助手等AI大模型时,必须联网接入。但云端大模型不仅算力成本高昂,而且在实时性、数据隐私安全等方面也面临着诸多挑战。
在此背景下,端侧大模型顺势而生。其核心是将AI大模型直接部署到终端设备,让这些设备拥有“本地智能”,无需依赖网络连接,即可自行完成数据处理和智能决策。
在新一轮端侧大模型热潮中,以下两大趋势正逐步显现:
首先是大模型逐渐小型化,通过将大模型的参数规模进行有效压缩,以适配终端设备的软硬件性能范围。目前,大模型厂商新品往往包含大、中、小等不同参数量级,其最小的模型参数多在百亿以下。这背后的原因主要是出于对计算成本、功耗和性能等因素的综合考量,尤其是在端侧部署大模型时,百亿参数级大模型能够更好地匹配现阶段的大众级终端设备。
第二个趋势是终端厂商正加速端侧大模型“装机”。以PC和手机为例,自去年以来,头部PC厂商相继推出了内置本地大模型的AI PC新品,国内主流手机厂商也已经在其旗舰产品中成功部署70亿参数规模的大模型,AI PC和AI手机随即进入了应用爆发期。除此之外,端侧大模型也已扩展到智能汽车以及具身智能机器人、AR/VR等IoT设备领域。
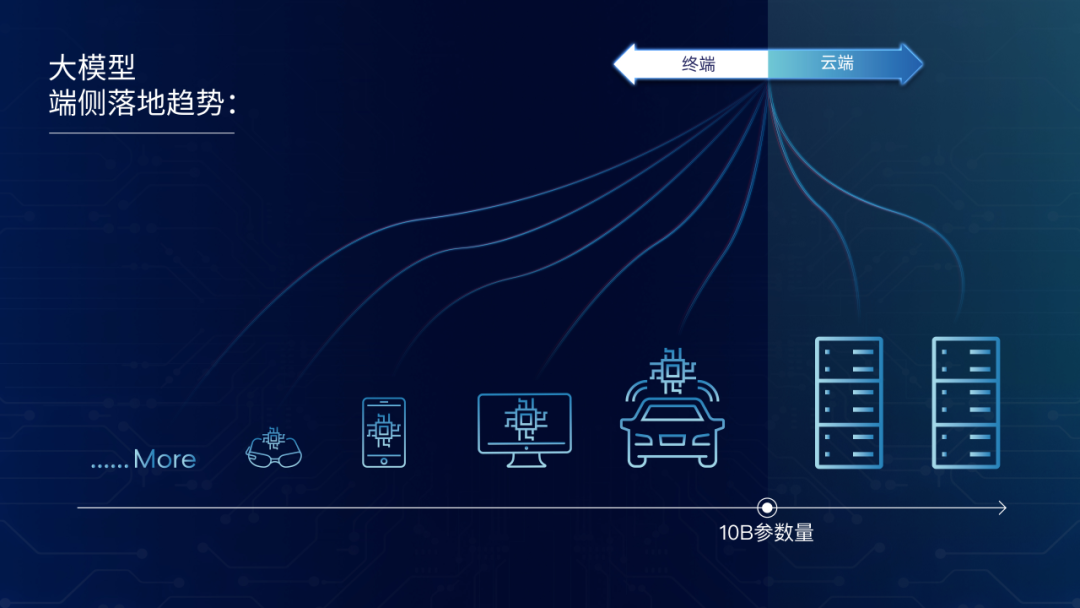
综上所述,模型公司与终端硬件公司正相向而行,共同推动端侧大模型的场景化落地,让更多普通消费者也能轻松享用到大模型带来的智能体验。而大模型与终端产品二者间的交汇点,正是边缘端设备的计算基础——芯片。
其中,CPU作为最为核心的计算“大脑”,在端侧推理过程中发挥着不容小觑的作用。

CPU作为智能终端的运算及控制中枢,其性能直接关系到端侧设备的响应速度、处理能力、能效、用户体验和安全性等,是衡量终端性能的关键指标。生成式AI兴起后,随着大模型小型化和推理任务向端侧迁移,CPU始终稳居终端硬件的核心地位,能够出色胜任本地AI推理,为海量设备提供强有力的计算支持。具体来看:
首先,AI处理始于CPU。早期智能手机上的AI功能大多基于自然语言处理(NLP)和计算机视觉(CV)等技术,如文字转写、人脸识别、相册分类、美颜滤镜等细分功能。此类AI工作负载或是全权交由CPU处理,或是结合其他协处理器共同支持。
其次,AI处理爆发于CPU。CPU的通用性使其能够快速响应端侧大模型在不同场景的落地需求。例如面对入门级智能手机、汽车智能座舱、AIoT设备等应用场景,CPU可高效处理参数规模在数十亿级别的小型计算任务。而在PC和旗舰智能手机等更高阶的应用场景,所需处理的计算任务则相对复杂且庞大,即便配备了AI专用加速器,CPU依旧是不可或缺的计算基石,且能独立承担处理百亿参数级别的更大规模计算任务。
Arm CPU凭借其在低功耗、高能效上的显著优势,被广泛应用于各类消费电子设备。得益于Arm CPU的AI计算能力,目前全世界约99%的智能手机都具备在端侧处理大模型所需的技术,包括NEON扩展架构、SVE可扩展向量扩展技术、SME可扩展矩阵扩展技术等关键Arm架构功能。以当今的安卓平台来看,第三方应用中有70%的AI运行在Arm CPU上。除手机外,基于Arm CPU的PC市场规模也在迅速增长。
面向下一代AI终端设备,全新Arm终端计算子系统(CSS)应运而生,这是迄今为止运行速度最快的Arm计算平台,不仅在计算和图形性能上实现30%以上的提升,而且AI推理速度提高了59%,适用于更广泛的AI、机器学习(ML)和计算视觉工作负载。同步推出的还有Arm Kleidi软件开发平台,能够帮助开发者快速获得开发生成式AI应用所需的性能、工具和软件库。

Arm终端CSS和Arm KleidiAI等新一代终端计算技术将进一步加速AI终端普及。预计2025年底,基于Arm架构的AI设备有望突破1000亿台。

与此同时,随着端侧推理需求的日渐高涨,生成式AI用例将在更多元化的应用场景中“遍地开花”,然而计算任务复杂度和数据量也随之激增,将对未来AI终端硬件提出更高的要求。由此,兼具通用性和专用性的异构计算解决方案已是大势所趋,它能够有机融合CPU、GPU、NPU等不同处理器,以满足端侧大模型部署的多样化计算需求。

其中,NPU全称Neural Processing Unit(神经网络处理单元),专门针对神经网络进行设计与优化,能更加高效地运行Transformer架构的AI模型。随着AI手机、AI PC概念的普及,NPU的重要性也日益凸显,它可以在视频、图像、系统管理等各类场景中发挥出色的AI加速能力,解决日益增长的终端推理需求。
安谋科技早在成立之初既已布局AI赛道,本土自研的“周易”NPU目前已迭代了Z系列和X系列的多款产品,广泛应用于中高端安防、智能家居、移动设备、物联网、智能座舱、ADAS、边缘服务器等市场。
开篇提到的“此芯P1”则采用了基于第三代“周易”架构设计的NPU。通过对低功耗与高算力的针对性优化,“周易”NPU不仅能够胜任长时间、高负载的任务处理,还支持多核多Cluster的算力扩展。在“周易”NPU的设计上,安谋科技从性能、精度、带宽、调度管理、算子支持等多个维度,对各类图像、视频AI模型算法进行了深度优化,并且完成了对主流大模型的适配,进一步强化其在面对高性能AI计算需求时的表现。
面对端侧生成式AI的高速发展和算力需求的不断攀升,CPU无疑是为终端设备提供了得以接入AI功能的广泛计算基础,而异构计算与NPU则为多模态大模型等新兴AI应用在端侧落地打开了新的想象空间。但无论设备和应用如何演进,算力始终是支撑端侧AI发展的基石,也是引领终端AI创新的核心引擎。

·
·

