
- 1[MAC]只读的移动硬盘?_wd my passport mac 只读
- 2接入世界30年: 展望中国互联网发展趋势
- 3P1886 滑动窗口 /【模板】单调队列(单调队列)
- 4结果解读_潜分类logit模型的STATA应用及结果解读
- 5主流X86-ARM-RISC-V-MIPS芯片架构分析_津逮 指令集
- 6ieee32位浮点格式转十进制_JavaScript 深入系列之浮点数精度
- 7ANR原理篇 - ANR信息收集过程_android anr 日志收集机制
- 8REST Assured 61 - Deserialize Using JsonPath_deserializeusing
- 9JNI 数据类型转换_unexpected jboolean value: -657205248
- 10Python--模块和包_python 模块和包
Flink CDC3.1版本数据同步记录_flink cdc 3.1
赞
踩
官网文档
Flink、Flink-CDC相关官方最新文档,浏览自己所使用的版本官方文档还是很有必要的,百度搜索的不一定是你使用的版本,可能会造成困惑。
1.安装部署flink
下载:
flink安装包下载地址:Index of /dist/flink,按需下载对应的版本,本文使用了Flink1.18.1的版本
解压:
tar -zxvf flink-1.18.1-bin-scala_2.12.tgz进入解压文件夹,修改基础配置:

修改conf/flink-conf.yaml文件:
#注:一定要配置进行checkpoint的开启,否则数据库后续的cdc可能不会生效
execution.checkpointing.interval: 3000
#配置自己的ip,用于flink-web-ui的界面访问 rest.address: 10.xx.xx.xxx
rest.bind-address: 10.xx.xx.xxx
执行启动:
./bin/start-cluster.sh访问ip:8081即可

此为最简单的flink部署,具体依据生产项目需要选择集群部署,部署方式网上很多,不做赘述
2.安装部署flink-cdc
下载
Index of /flink,选择flink-cdc版本压缩包,本文使用flink-cdc3.1新版本,如果没有你想要的版本可以去github上进行下载:Releases · apache/flink-cdc · GitHub
解压
tar -zxvf flink-cdc-3.1.0-bin.tar.gz准备工作
需要下载flink-cdc需要的连接器胖包,放在解压flink-cdc后的lib下。此处按需source源和sink源进行下载,本人使用mysql to kafka,(也是去官方的github上下载Releases · apache/flink-cdc · GitHub,比较全)
本文需要下载mysql的source、kafka的pipeline
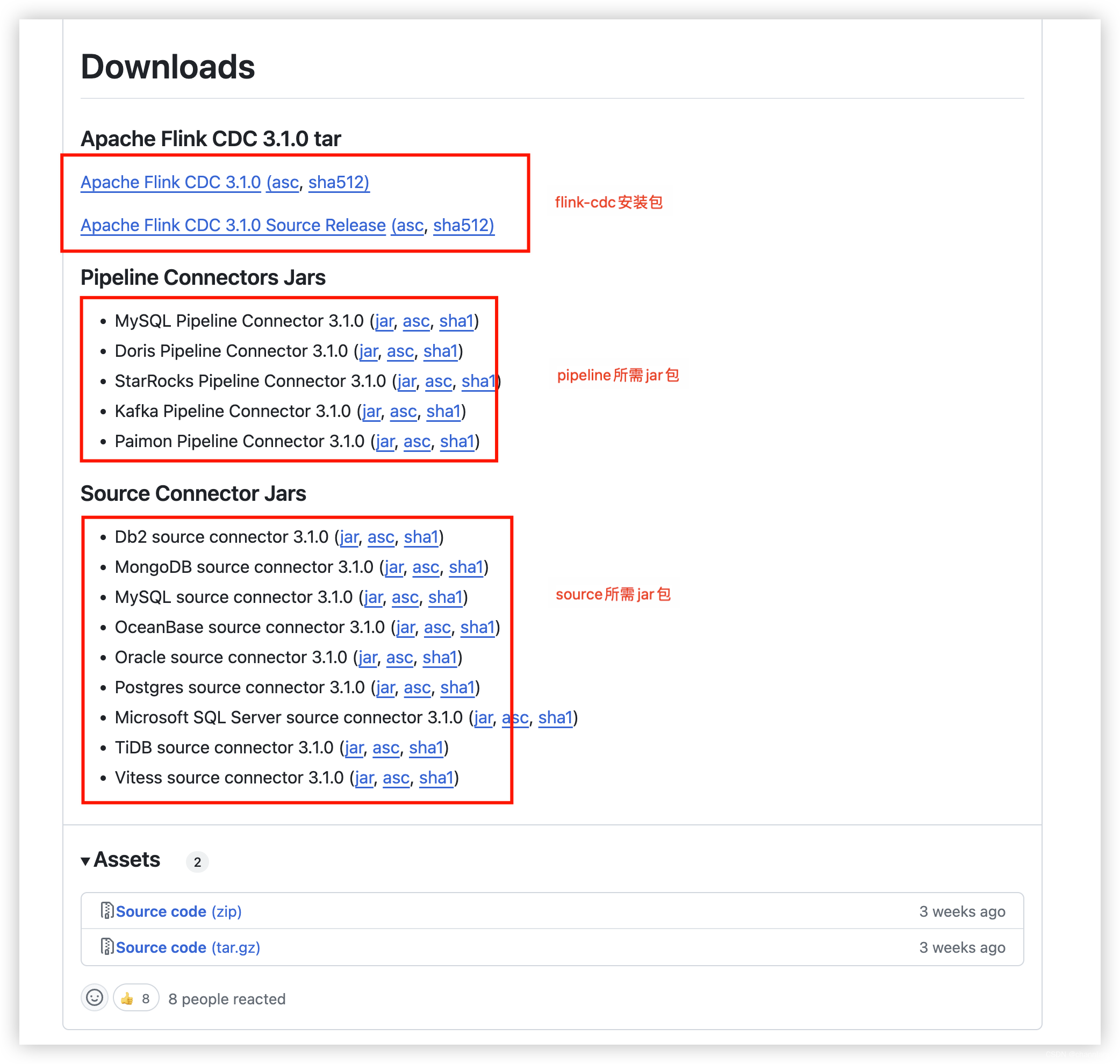
因MySQL Connector 采用的 GPLv2 协议与 Flink CDC 项目不兼容,官方有解释,故如果是mysql的话还需要下载驱动
mysql驱动地址:https://mvnrepository.com/artifact/mysql/mysql-connector-java/8.0.27
官方解释地址:MySQL | Apache Flink CDC
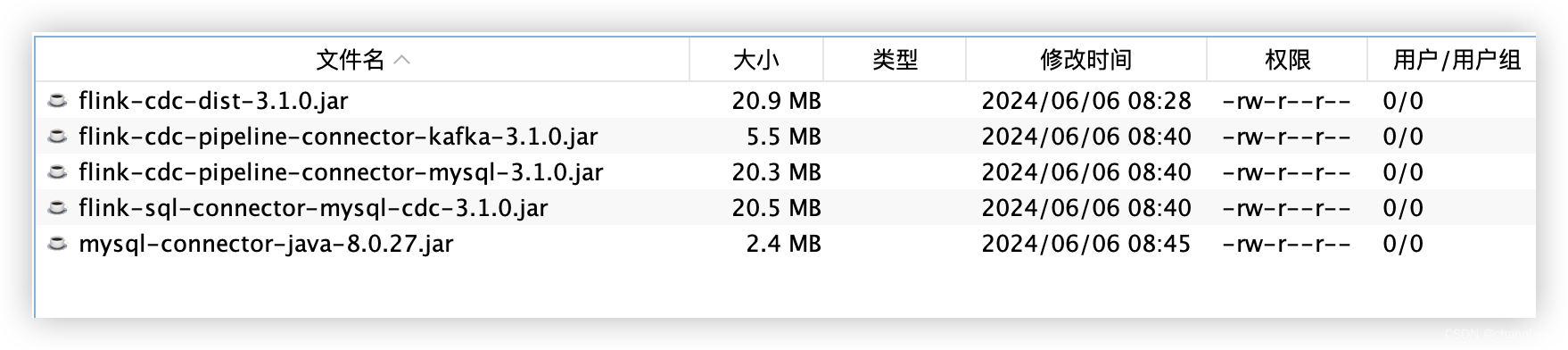
将下载的jar包放入flink-cdc的lib中,注意:flink解压包处也需要同步一份,且flink同步后,重启一下
#先关闭,最好多执行几次,直到控制台说无服务了
./bin/stop-cluster.sh
#再启动
./bin/start-cluster.sh
编写mysql-to-kafka.yaml
source: type: mysql name: MySQL Source hostname: ip port: 3306 username: root password: pass tables: 库名.表名 server-id: 184154 # 默认采用initial模式,此处防止启动初始化数据过多,配置了从最新记录读取,生产应该以endpoint # scan.startup.mode: latest-offset scan.snapshot.fetch.size: 2 sink: type: kafka name: Kafka Sink properties.bootstrap.servers: PLAINTEXT://ip:9092 # kafka主题,如果不写,则默认以source.tables下命名 # topic: test1 value.format: debezium-json pipeline: name: MySQL to Kafka Pipeline parallelism: 1
执行
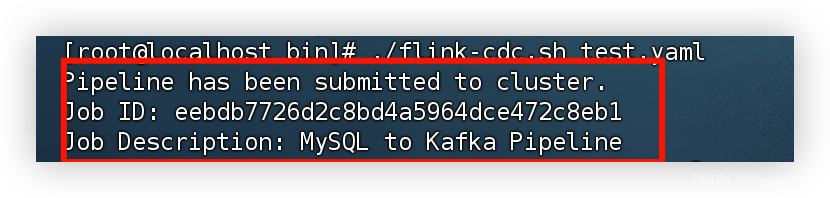
./flink-cdc.sh /path/mysql-to-kafka.yaml
代表已经执行提交flink任务成功
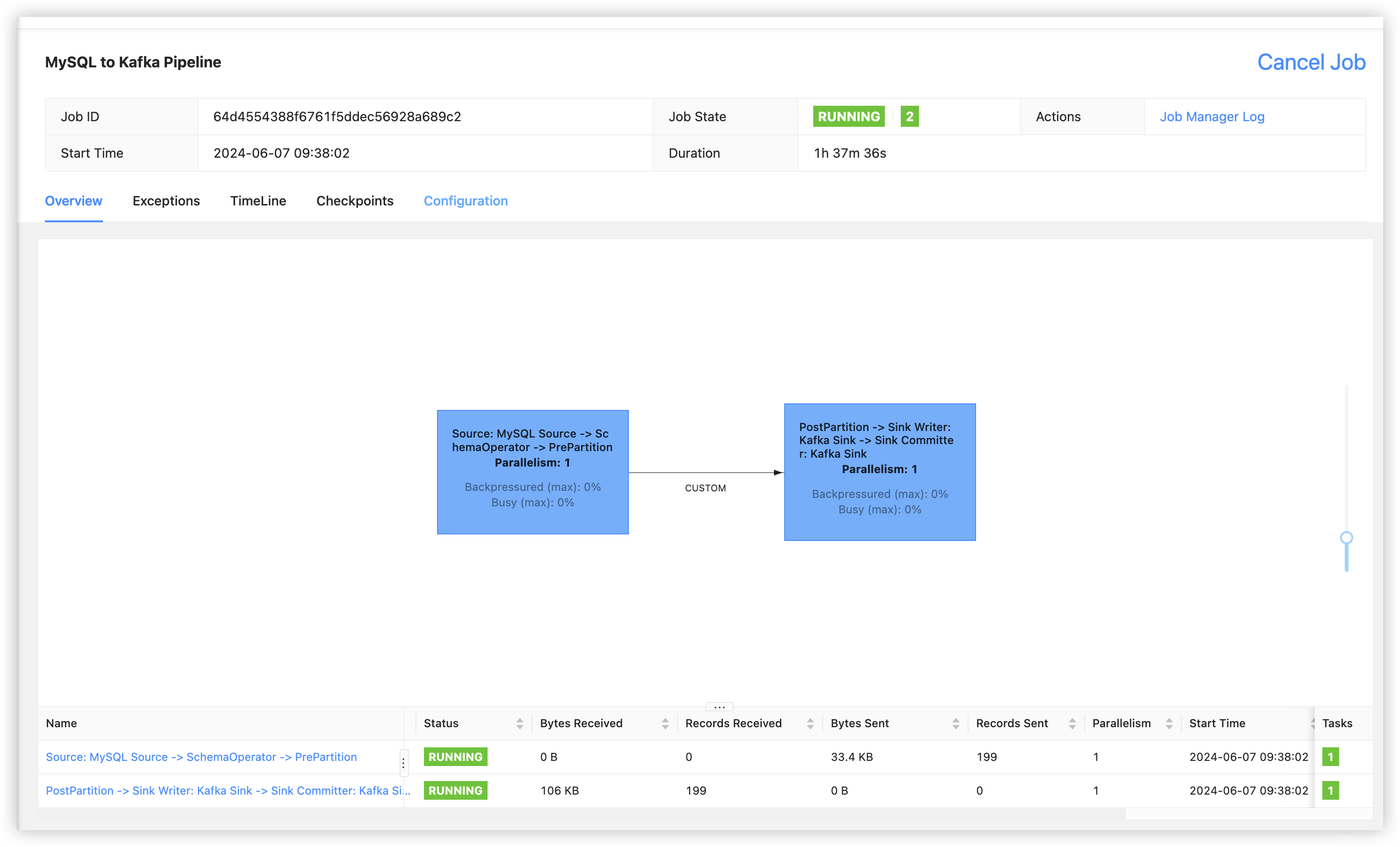
访问flink-web-ui可查看到刚刚提交的cdc同步任务
验证
修改监听的mysql表数据后,可在kafka的topic消息中查看到
此处选用了kafka的ui组件,能够方便直观看见消息,如下
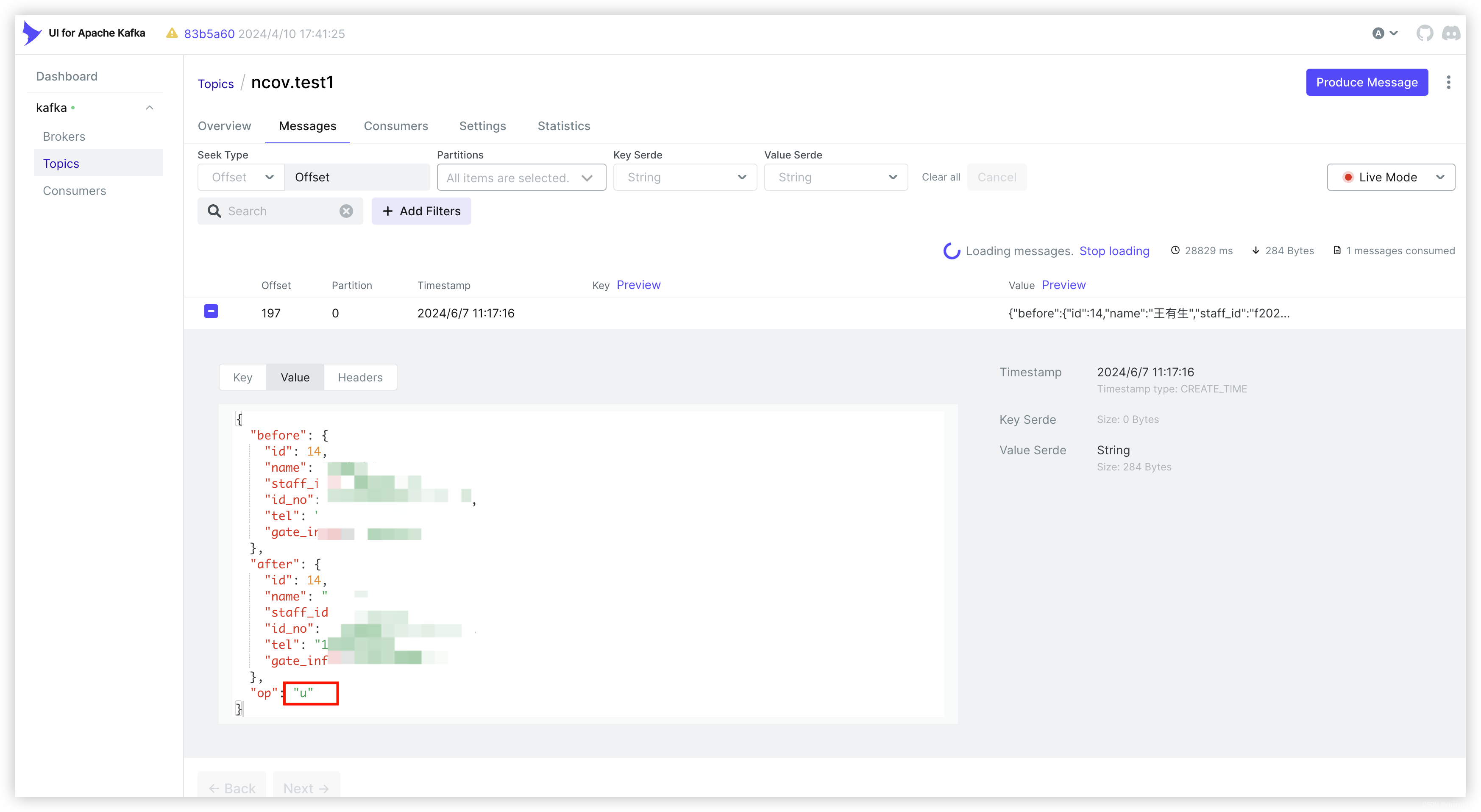
3.Q&A
1.只有在启动的时候才会去全量同步数据,后续的数据变更捕获不到,怎么办?
首先,监听的数据得开启binlog,拿mysql举例,需注意排查事项如下,
1.检查是否开启binlog:SHOW VARIABLES LIKE 'log_bin';
(ON为开启)
2.确认binlog的记录格式:SHOW VARIABLES LIKE 'binlog_format';
(得是ROW)
3.查看binlog是否设置有白名单或黑名单:SHOW MASTER STATUS;

2. 待续补充......

