
热门标签
热门文章
- 1Python对接海康威视机器视觉工业相机_海康相机 python
- 2idea插件开发入门_ideanotifications通知设置
- 3第十四届蓝桥杯JavaB组省赛真题 - 蜗牛_蓝桥杯第十四届javab组
- 4Git 仓库的整体迁移_gitlab移动整体目录代码会受影响吗
- 5TCP/IP协议工作原理和工作流程_tcp工作原理
- 6uniapp_canvas生成海报_微信小程序海报_uniapp小程序生成海报
- 7星途重启:244亿公里外的「旅行者1号」,修好了
- 8Mac Apache php 配置域名_php mac 本机绑定域名
- 9OSPF邻居建立过程详解_ospf建立过程
- 10Linux-磁盘挂载_linux永久挂载磁盘
当前位置: article > 正文
python数据分析与可视化--体育收入排行榜
作者:神奇cpp | 2024-06-24 20:27:10
赞
踩
python数据分析与可视化--体育收入排行榜
目录
题目
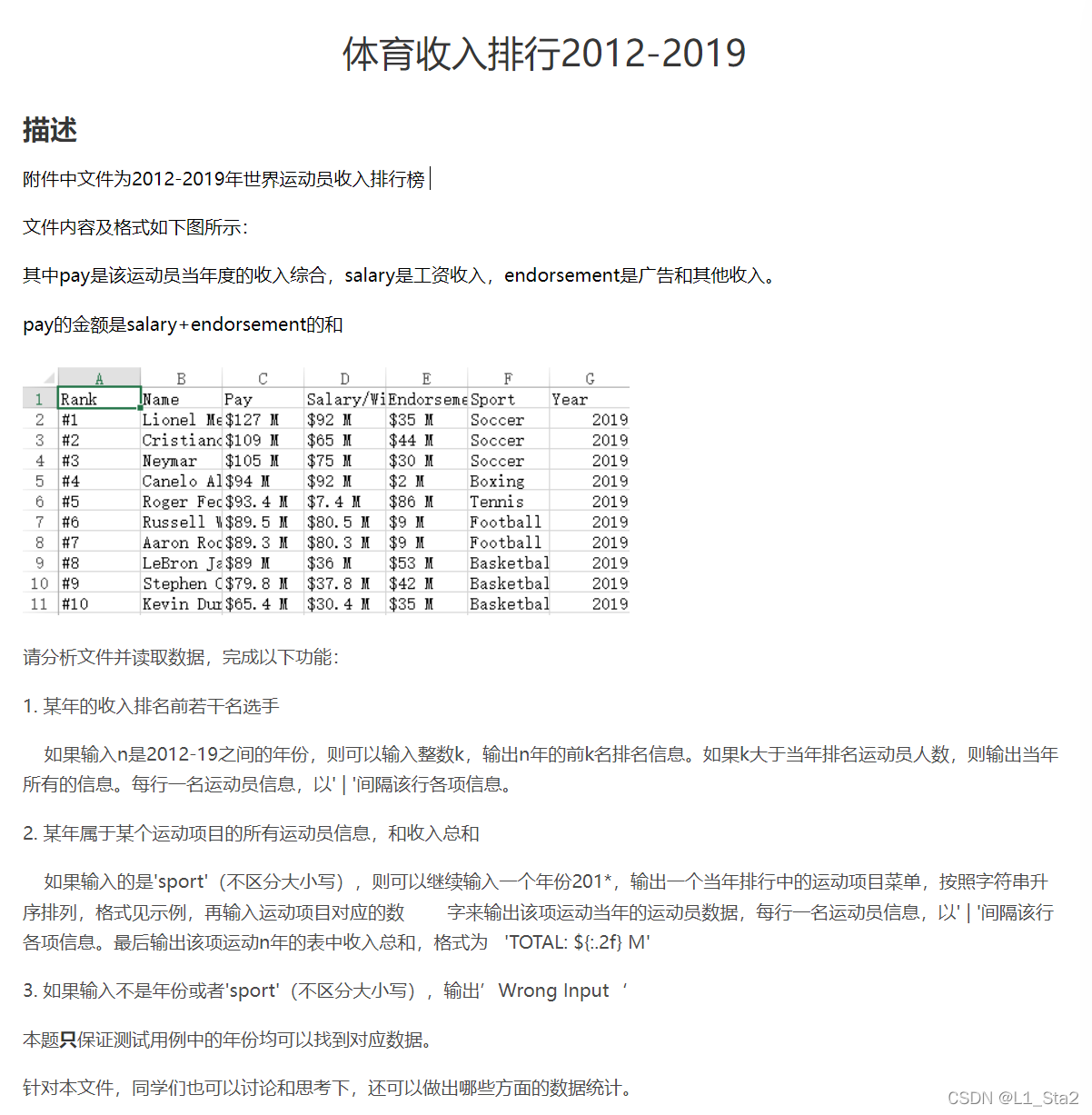

思路:
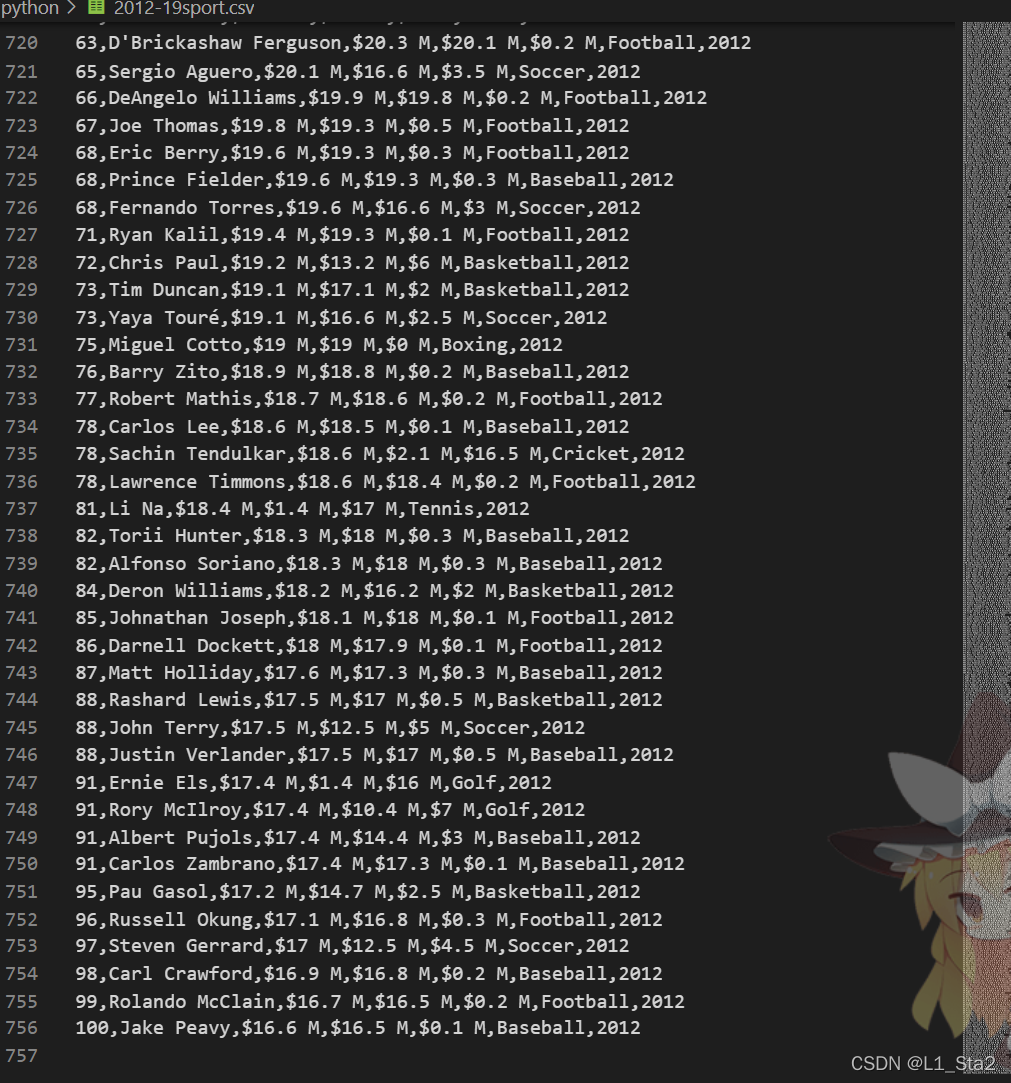
1.其实没有太大的技术含量,就是把数据整理后输出,折磨人的反而是调整输出的格式,数据量有点大,但是有行列标,比较方便整理。其实本题更适合用pandas,但是我还是用了numpy,因为大部分比赛允许用numpy而不允许用pandas
2.首先读取数据并转化为二维列表,再来看题目的需求
3.示例1给出的是错误输出,我们不妨放到最后的else里面解决
4.示例2输入了sport和年份得到一个年度的运动列表并按升序排列,在输入一个数获得前几名的信息和总收入。说白了就是要把得到的二维列表先取出特定的年份,再把年份当中的体育汇总并去重,最后进行排列。如果用pandas可以先groupby年份,最后直接排序,而numpy则较为复杂。排序完成后要输出信息,所以排序的时候不能把列单独拿出来作为一个列表排列,而应该用到按列排序或者lambda函数来排序,我采用的是把他拿出来排序的,对数据排序记得删掉字符串并转整形或者浮点型
5.无语了之前写的屎山自己看不下去了,改天写个pandas版本的,直接放代码吧。
代码:
- import numpy as np
-
- with open ('2012-19sport.csv', encoding='utf-8') as file:
- file.readline()
- data = file.read().strip().replace('\n', ',').split(',')
-
- def sport_thing():
- year = input()
- set1 = set()
- sum = 0
- yearly_data = np.array(data).reshape(755, 7)# 全表
- for x, i in enumerate(yearly_data[:,6]):
- if i == year:
- set1.add(yearly_data[x, 5])
- else:
- list1 = sorted(list(set1))
- for num, sp in enumerate(list1):
- print(f'{num + 1}: {sp}')
- cho = int(input()) - 1
- sport_name = list1[cho]
- for x, i in enumerate(yearly_data[:,6]):
- if i == year and yearly_data[x, 5] == sport_name:
- sum = sum + float(yearly_data[x, 2].replace('$', '').replace(' M', ''))
- for item in yearly_data[x]:
- if item != year:
- print(item.replace('#', ''),end = ' ')
- print('|', end=' ')
- if item == year:
- print(item)
- else:
- print(f'TOTAL: ${sum :.2f} M')
-
- def print_thing():
- n = int(input())
- yearly_data = np.array(data).reshape(755, 7)# 全表
- number = 0
- for i in range(755):
- if yearly_data[i,6] == what:
- for num,j in enumerate(yearly_data[i]):
- if j != what:
- print(j.replace('#', ''), end = ' ')
- print('|', end = ' ')
- elif j == what and num != len(yearly_data):
- print(j)
- number = number + 1
- if number >= n:
- break
-
- if __name__ == '__main__':
- what = input()
- if what.lower() == 'sport':
- sport_thing()
- elif 2012 <=int(what) <= 2019:
- print_thing()
- else:
- print('Wrong Input')
- # 自己写的狗屎自己看不下去了

补充:
pandas版思路
1.读文件,并转为dataframe,把header设置为0以把第一行设置为索引
2.对数据进行分类(groupby),第一问按年分后取出sport内的值,并用sort_values来排序,随后输入运动类型后按相应类型groupby并排序输出
3.pandas的输出格式懒得改了,大同小异,pandas部分代码无法直接再python123上提交,需要像np一样修改输出格式后才可以输出
pandas版代码(简化)
- import pandas as pd
- data = pd.DataFrame(pd.read_csv('2012-19sport.csv', header=0))
- what = input()
- if what.lower() == 'sport':
- year = int(input())
- year_data = sorted(pd.DataFrame(data.loc[data['Year'] == year]['Sport'].unique()).values.tolist())
- for x, i in enumerate(year_data):
- print(f"{x+1}: {''.join(map(str, i))}")
- sport = year_data[int(input())-1]
- data = data.loc[data['Year'] == 2019].loc[data['Sport'] == ''.join(sport)]
- for x, i in enumerate(data.values):
- print(''.join(map(str, i)))
- elif 2012 <= int(what) <= 2019:
- num = int(input())
- year_data = (pd.DataFrame(data.loc[data['Year'] == int(what)]).values)
- for x, i in enumerate(year_data):
- if x < num :
- print(''.join(map(str, i)))
- else:print('Wrong Input')
总结
今天有点划水,可能是到了周末有点懈怠了
pandas比numpy好用很多 但是一般比赛都会被ban 建议平常要练手用np 要生产力用pandas
以上
坚持 共勉
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/神奇cpp/article/detail/753884
推荐阅读
相关标签

