
算法金 | K-均值、层次、DBSCAN聚类方法解析
赞
踩

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」

聚类分析概述
聚类分析的定义与意义
聚类分析(Clustering Analysis)是一种将数据对象分成多个簇(Cluster)的技术,使得同一簇内的对象具有较高的相似性,而不同簇之间的对象具有较大的差异性。这种方法在无监督学习(Unsupervised Learning)中广泛应用,常用于数据预处理、模式识别、图像处理和市场分析等领域
通过聚类分析,可以有效地发现数据中的结构和模式,为进一步的数据分析和挖掘提供基础。例如,在市场分析中,聚类分析可以帮助企业将客户群体进行细分,从而制定更有针对性的营销策略
常见聚类算法概览
聚类算法种类繁多,常见的主要有以下几种:
- K-均值(K-Means):一种基于划分的聚类方法,通过迭代优化目标函数将数据分为K个簇。它具有计算简单、效率高等优点,但对初始值敏感,容易陷入局部最优
- 层次聚类(Hierarchical Clustering):一种基于层次结构的聚类方法,包括凝聚式和分裂式两种。凝聚式层次聚类从每个对象开始逐步合并,分裂式层次聚类从整个数据集开始逐步分裂。它可以生成树状结构(树状图),但计算复杂度较高
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise):一种基于密度的聚类方法,通过定义核心点、边界点和噪声点来识别簇。它能有效处理噪声和发现任意形状的簇,但对参数选择较为敏感
聚类分析在数据科学中的应用
聚类分析在数据科学中有广泛的应用,以下是一些典型场景:
- 客户细分:通过对客户进行聚类分析,企业可以将客户分成不同的群体,从而制定更加精准的营销策略
- 图像分割:在图像处理领域,聚类分析可以用于图像分割,将图像分成具有相似像素特征的区域
- 异常检测:聚类分析可以帮助识别数据中的异常点,这在金融欺诈检测、网络入侵检测等方面有重要应用
- 文本聚类:在自然语言处理领域,聚类分析可以用于文本聚类,将具有相似主题的文档分在一起,方便后续的信息检索和推荐系统
K-均值聚类方法
定义与基本原理
K-均值(K-Means)是一种常见的划分式聚类算法,其目标是将数据集分成 ( K ) 个簇,使得每个簇内的数据点与该簇的中心点(质心)之间的距离平方和最小。该算法的基本原理是通过迭代优化,逐步调整簇中心位置,直到簇中心不再发生变化或达到预设的迭代次数
算法步骤
K-均值算法的具体步骤如下:
- 随机选择 ( K ) 个初始质心
- 将每个数据点分配到最近的质心所在的簇
- 计算每个簇的质心,即该簇中所有数据点的平均值
- 检查质心是否发生变化,若发生变化,则重复步骤2和3,直到质心不再变化或达到预设的迭代次数
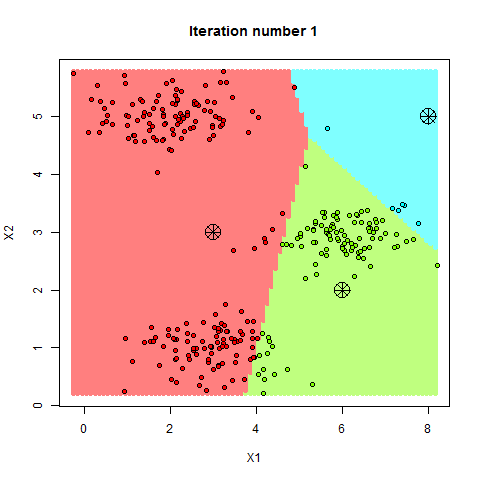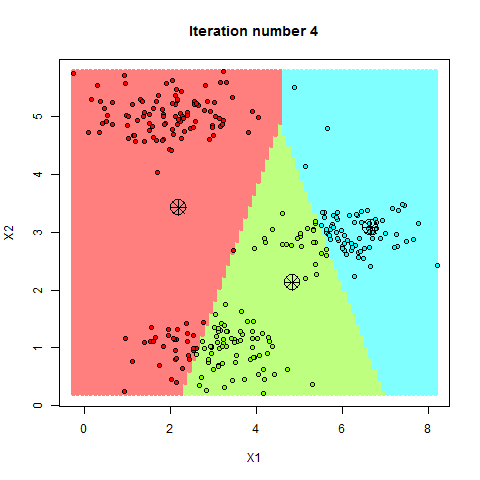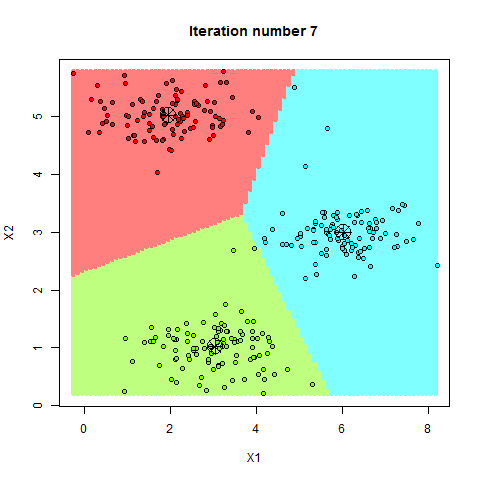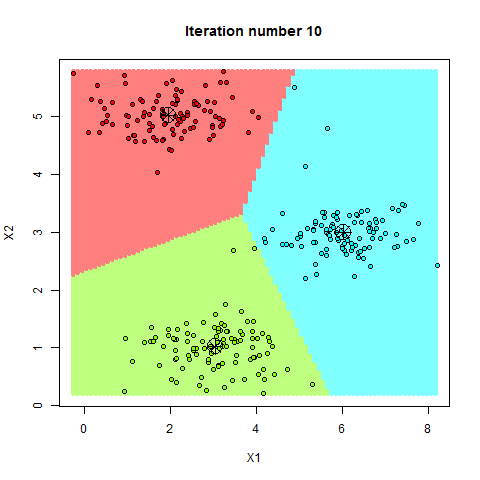
K值选择与初始中心问题
K值选择是K-均值聚类中的一个关键问题。通常可以通过肘部法则(Elbow Method)来选择合适的 ( K ) 值。肘部法则通过绘制不同 ( K ) 值对应的聚类误差平方和(SSE),选择拐点处的 ( K ) 值
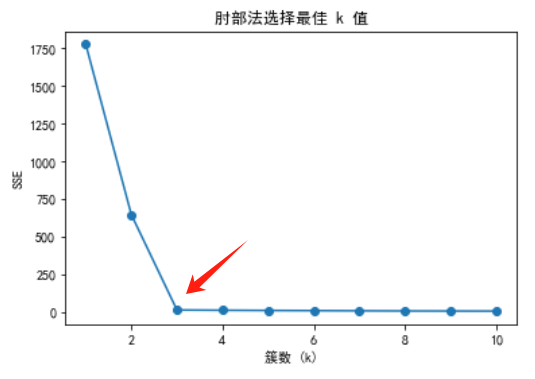
初始中心的选择对K-均值算法的收敛速度和聚类效果有重要影响。常用的改进方法是K-means++,它通过一种概率分布方法选择初始质心,能有效提高算法性能
优缺点分析
优点:
- 算法简单,计算效率高,适用于大规模数据集
- 易于实现和理解
缺点:
- 对初始质心敏感,可能陷入局部最优
- 需要预先指定 ( K ) 值
- 不能处理非凸形状的簇和具有不同大小的簇
- 对噪声和异常值敏感
适用场景及实例
K-均值聚类适用于以下场景:
- 数据集规模较大,且簇的形状接近凸形
- 需要快速获取聚类结果,用于初步数据分析
- 希望对簇进行简单的解释和可视化

层次聚类方法
定义与基本原理
层次聚类(Hierarchical Clustering)是一种基于层次结构的聚类方法。它通过构建树状的簇结构,逐层合并或分裂数据点,形成一个层次化的簇结构。层次聚类主要有两种类型:凝聚式(Agglomerative)和分裂式(Divisive)。
- 凝聚式聚类:从每个数据点开始,将最近的两个簇逐步合并,直到所有数据点都被合并到一个簇中。
- 分裂式聚类:从整个数据集开始,将数据点逐步分裂成更小的簇,直到每个数据点都成为一个单独的簇。
算法步骤
以凝聚式层次聚类为例,算法步骤如下:
- 初始化:将每个数据点作为一个单独的簇
- 计算簇之间的相似度矩阵
- 合并最相似的两个簇,更新相似度矩阵
- 重复步骤3,直到所有数据点合并到一个簇中
分裂式与凝聚式聚类
- 分裂式聚类:从整个数据集开始,通过递归地分裂数据集,形成树状结构。
- 凝聚式聚类:从每个数据点开始,通过递归地合并最近的簇,形成树状结构。
两者的主要区别在于聚类过程的方向,分裂式自顶向下,凝聚式自底向上。
优缺点分析
优点:
- 无需预先指定簇数 ( K )
- 能够生成树状结构(树状图),方便观察不同层次的聚类结果
- 对任意形状的簇有较好的适应性
缺点:
- 计算复杂度高,尤其是大规模数据集
- 对噪声和异常值敏感
- 聚类结果不可逆,一旦合并或分裂无法撤销
适用场景及实例
层次聚类适用于以下场景:
- 需要观察不同层次的聚类结果
- 数据集规模较小,计算复杂度可接受
- 希望获得更直观的聚类结构

DBSCAN聚类方法
定义与基本原理
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类方法,通过识别数据点的密度连接区域来形成簇。DBSCAN不需要预先指定簇的数量,能够识别任意形状的簇,并且对噪声和异常点有较好的处理能力
DBSCAN的基本原理是定义两个参数:( \varepsilon ) (Epsilon,邻域半径)和 ( \text{minPts} ) (最小点数),以确定簇的密度。数据点分为三类:
- 核心点(Core Point):在其 ( \varepsilon ) 邻域内包含至少 ( \text{minPts} ) 个点的点
- 边界点(Border Point):在其 ( \varepsilon ) 邻域内包含少于 ( \text{minPts} ) 个点,但在核心点邻域内的点
- 噪声点(Noise Point):既不是核心点,也不是边界点的点
算法步骤
DBSCAN 算法的具体步骤如下:
- 随机选择一个未访问的数据点
- 检查该点的 ( \varepsilon ) 邻域,如果邻域内的数据点数量大于等于 ( \text{minPts} ),则将该点标记为核心点,并将邻域内的所有点加入同一簇
- 对邻域内的点进行递归扩展,直到所有核心点的邻域都被访问
- 对所有未标记的点,如果其属于任何一个核心点的邻域,则标记为边界点;否则,标记为噪声点
- 重复上述步骤,直到所有点都被访问
核心点、边界点与噪声点
- 核心点:邻域内包含至少 ( \text{minPts} ) 个点
- 边界点:邻域内少于 ( \text{minPts} ) 个点,但在核心点邻域内
- 噪声点:既不是核心点,也不是边界点的点
优缺点分析
优点:
- 无需预先指定簇数 ( K )
- 能处理任意形状的簇
- 对噪声和异常点有较好的处理能力
缺点:
- 对参数 ( \varepsilon ) 和 ( \text{minPts} ) 较为敏感
- 计算复杂度较高,不适合大规模数据集
适用场景及实例
DBSCAN 聚类适用于以下场景:
- 数据集具有任意形状的簇
- 存在噪声和异常点,需要识别并处理
- 希望在不预先指定簇数的情况下进行聚类
[ 抱个拳,总个结 ]
聚类方法比较与应用
三种聚类方法的比较
在前面章节中,我们详细介绍了K-均值、层次聚类和DBSCAN这三种聚类方法。下面将从多个维度对这三种方法进行比较。

如何选择适合的聚类方法
在实际应用中,选择适合的聚类方法需要考虑以下因素:
- 数据集规模:对于大规模数据集,优先选择计算复杂度较低的方法,如K-均值。
- 簇的形状:如果数据中的簇形状不规则或具有不同的密度,优先选择DBSCAN或层次聚类。
- 噪声和异常点:如果数据集中存在较多噪声和异常点,DBSCAN是较好的选择,因为它能够有效处理噪声。
- 计算资源:层次聚类的计算复杂度较高,适用于小规模数据集。在计算资源有限的情况下,可以选择K-均值。
- 对簇数的预知:如果不能预先确定簇的数量,可以选择层次聚类或DBSCAN。
通过以上内容,我们对K-均值、层次聚类和DBSCAN这三种聚类方法进行了解析,并比较了它们的优缺点和适用场景。希望这些内容能帮助大侠们在实际数据分析中选择合适的聚类方法,提高数据处理和分析的效果。
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵
内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
基础还是很重要的
能一步一步往前走是很幸福的
毕竟,不确定是常态
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖

