
- 1Android修改包名 方法二:不修改文件名,自动配置_app只变更包名 但是源文件名不变
- 2Hadoop3.x启动后无法访问9870_9870 hadoop3 没运行
- 3自然语言处理(NLP)原理、用法、案例、注意事项_nlp的实现逻辑
- 4路径规划——搜索算法详解(二):Floyd算法详解与MATLAB代码_floyd算法matlab程序
- 5演唱会门票抢不到?不要慌,教你用python实现自动化抢票_python3.x能抢演唱会门票吗
- 6Altera FPGA 配置flash读写_fpga 配置flash接口
- 7探索深度学习的新边界:Megatron-DeepSpeed
- 8笔记—— 24指令硬布线单周期mips cpu设计 (华中科技大学/谭志虎)计算机组成原理/计算机硬件系统设计_单周期硬布线控制器
- 9STM32 MDK Keil5软件调试功能使用(无需连接硬件)
- 10Windows Shell命令_windows的shell在哪
自然语言处理(NLP)—— 深度学习
赞
踩
1. 词嵌入(Embeddings)
1.1 词嵌入的基本概念
词嵌入(Embeddings)是一种将词语映射到高维空间(比如N=300维)的技术,使得词语之间的欧几里得距离与它们的语义距离相关联。这意味着在这个向量空间中,语义上相近的词语会被映射到彼此接近的点上。
此外,在词嵌入中,某些语言关系(如复数形式、性别变化、最高级等)与特定的欧几里得方向相关联。这允许我们通过简单的向量运算(如向量加法和减法)来捕捉和表示这些语言关系。例如,通过词嵌入,可以发现"king" - "man" + "woman"的结果与"queen"非常接近,这展示了词嵌入能够捕捉到复杂的语义关系。
1.2 两种对称的方法
Mikolov等人在2013年引入了两种对称的方法:连续词袋模型(CBOW)和跳字模型(Skip-grams)。

这幅图展示了生成词嵌入的两种模型:Skip-gram 和 CBOW(连续词袋)。
1.2.1 CBOW(连续词袋)
CBOW(Continuous Bag-Of-Words):这个模型预测一个目标词基于它周围的上下文词。换句话说,它将上下文词的特征作为输入,来预测目标词。
左侧,CBOW 模型的结构图表示它是用上下文词(如“bark”,“chocolate”等)来预测目标词(本例中为“dog”)。过程如下:
- 上下文词通过独热编码(one-hot encoding)转化为输入。
- 输入通过线性层(实质是一个权重矩阵)映射到连续的空间中,形成词嵌入。
- 通过另一个线性层,使用这些词嵌入来预测目标词,为词汇表中的每个词生成一个分数。
- 分数最高的词被选作预测的目标词。
1.2.2 Skip-gram
Skip-gram:与CBOW相反,Skip-gram模型使用一个词来预测它周围的上下文词。这意味着模型以一个词为输入,尝试预测它在文本中的上下文词。
Skip-gram 模型。Skip-gram 与 CBOW 正好相反:
- 目标词(这里是“heard”)被输入模型。
- 目标词通过线性层映射到词嵌入空间。
- 从词嵌入中,模型通过另一个线性层预测上下文词(如“a”,“barking”等),为可能的上下文词生成分数。
- 目标是在嵌入空间中为实际周围的词获取高分。
在这两种方法中,通过多个上下文-目标词对来训练线性层(起到查找表的作用),调整词嵌入使正确的预测更频繁地发生。最终结果是,具有相似上下文的词具有相似的嵌入,捕获了语义意义和关系。这些嵌入然后可用于多种自然语言处理任务。
这两种方法都基于分布假设,即语义上相近的词语通常会出现在相似的上下文中。通过大量文本数据的训练,这些模型能够学习到词语的密集向量表示(即词嵌入),这些向量捕捉了词语的语义属性和它们之间的关系。
词嵌入已经成为自然语言处理(NLP)中的一种基础技术,广泛应用于各种任务中,包括文本分类、情感分析、机器翻译以及问答系统等。通过提供一种有效的方式来表示文本数据,词嵌入使得机器能够更好地理解语言的复杂性和细微差别。
1.3 GloVe(全局向量词嵌入)模型

在图片中,展示了GloVe(全局向量词嵌入)模型的架构,这是另一种用于生成词嵌入的技术。GloVe结合了矩阵分解和词-词共现统计的优点,旨在捕捉词之间的全局统计信息。
GloVe模型的工作原理如下:
1. 统计词共现:首先,计算语料库中每对词(例如"dog"和"bark")共同出现的次数,通常表示为。
2. 构建共现矩阵:使用整个语料库中的词汇构建一个共现矩阵。矩阵的每个元素,比如,代表两个词在特定距离内共现的频率。
3. 训练词嵌入:接下来,GloVe模型通过学习这个共现矩阵,为每个词生成词嵌入。它不是简单地使用共现频率,而是尝试学习词嵌入,使得它们的点积与词之间的共现概率的对数值成正比。
4. 最终词嵌入:通过这种方式,得到的词嵌入捕捉到了丰富的语义和统计信息。在向量空间中,语义上或统计上相关的词会被映射到相互接近的点上。
GloVe模型的优势在于它同时考虑了局部上下文(类似于Skip-gram和CBOW)和全局统计特性(通过整个语料库的词共现信息)。这使得GloVe在许多NLP任务中表现出色,能够捕捉到词语之间复杂的语义关系。
1.4 fastText(全局向量词嵌入)模型
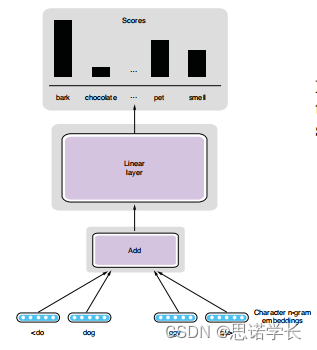
这张图描述了使用fastText模型创建词嵌入的过程。fastText是一种用于文本分类和词嵌入的库,它特别关注词的形态学结构,即词内部的字符级模式。
fastText的关键特点是考虑了字符级的n-gram,这是一种从词中抽取的子字符串序列。比如说对于词“dog”,可能会考虑字符n-gram“<do”,“dog”,“og>”等,其中“<”和“>”被用于标记词的开头和结尾。
创建词嵌入的过程如下:
1. 字符n-gram嵌入:首先,为词中的每个字符n-gram创建嵌入向量。这些向量捕捉词内部的字符模式信息。
2. 向量求和:“Add”操作表示将一个词的所有字符n-gram嵌入向量相加,得到词的最终嵌入表示。
3. 线性层:然后,这个累加后的向量通过一个线性层(可能是用于特定任务的一个全连接层),来进行进一步的处理或用于预测。
4. 得分:最终,模型会为每个词生成一个得分,这个得分反映了词在训练过程中的重要性或与预测任务的相关性。
fastText模型的优点在于它不仅能够学习到全词的嵌入,还能通过字符n-gram捕捉到词形变化和拼写差异的信息。这使得模型对于语言中的形态学变化具有更好的适应性,尤其是对于处理词汇稀疏或新词(比如拼写错误或新造词)的场景。此外,fastText还特别适合于处理词形丰富的语言,如拼写规则复杂的德语或土耳其语。
1.5 doc2vec模型

这张图似乎描绘的是文档向量(Doc2Vec)模型的过程,它是一种用于将段落、句子或文档转换为向量表示的算法。Doc2Vec基于Word2Vec,但扩展了其功能,使其可以处理比单个词更大的文本单元。
在Doc2Vec中,每个段落或文档都有一个唯一的标识符(在图中为"paragraph_id"),这个标识符在训练过程开始时是随机初始化的。然后通过以下步骤进行训练:
- 初始段落向量:段落ID作为输入,与段落中的词向量一起,参与模型的训练。
- 词嵌入:文档中的每个词都被转换为词向量,这些向量可以通过Word2Vec、fastText或其他词嵌入方法获得。
- 组合向量:通过"Join"操作,段落ID向量与文档中每个词的向量结合。这可能是通过向量加法或连接来完成的。
- 线性层:组合向量经过一个线性层,该层可能进行一些变换,并用于后续任务,如分类或相似性度量。
- 反向传播:通过训练过程中的反向传播(backpropagation),段落ID向量开始累积关于其上下文的信息,最终转换成一个富含文档语义信息的段落向量。
- 得分:最终,模型将输出用于评估或预测的得分。
Doc2Vec模型特别适用于需要考虑上下文信息的NLP任务,如情感分析、文档分类或信息检索。通过这种方法,模型不仅能够捕捉到单个词的含义,还能够理解整个文档的内容。
2. 句子分类
2.1 循环神经网络(Recurrent Neural Network, RNN)
这张图展示了循环神经网络(Recurrent Neural Network, RNN)在句子分类任务中的应用。循环神经网络特别适用于处理序列数据,如文本或时间序列。
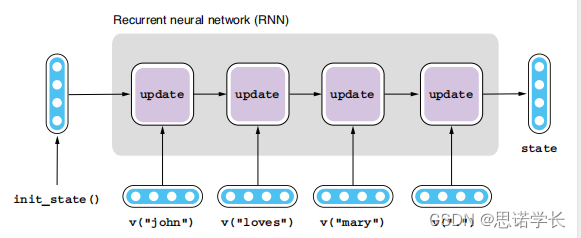
在图中,RNN是这样工作的:
- 初始化状态:“init_state()”代表RNN的初始状态,通常是一个全零向量。
- 词嵌入:每个单词(如"John", "loves", "Mary", ".")都被转换为一个向量,通常通过词嵌入来实现,即`v("word")`表示一个单词的向量表示。
- 状态更新:RNN通过“update”块逐个处理句子中的每个词向量。每个词都会根据前一个词的“更新”状态和当前词的嵌入来更新网络的状态。这样,网络能够“记住”序列中之前的信息,并将这些信息融入到当前的处理中。
- 最终状态:在处理完所有单词后,RNN的最后一个状态(图中的“state”)包含了整个句子的信息。这个状态可以用于句子分类或其他任务,因为它已经学习并捕获了整个句子的上下文信息。
RNN的优势在于能够处理可变长度的句子,并且每个词的处理都考虑到了前面词的上下文。这对于很多NLP任务来说非常重要,比如情感分析、机器翻译或语言模型。然而,RNN也有其缺点,特别是在处理长序列时可能会遇到梯度消失或梯度爆炸的问题,这使得模型难以捕捉长距离依赖。为了解决这些问题,后来发展了更先进的RNN变体,如长短期记忆网络(Long Short-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)。
2.2 LSTM(长短期记忆)单元

这张图展示了一个LSTM(长短期记忆)单元,这是一种用于处理序列数据的递归神经网络(RNN)的特殊类型。LSTM特别设计用来解决传统RNN在处理长序列时遇到的梯度消失和梯度爆炸问题。在句子分类任务中,LSTM能够记住和利用长距离的依赖信息,这对于理解句子的整体意义非常有用。
LSTM单元通过以下机制操作:
- 词输入:每个时间步,一个词被输入到LSTM单元。
- 遗忘门(Forget):遗忘门决定了哪些信息应该从单元状态中被移除。这是通过将前一个时间步的单元状态与一个介于0和1之间的值(由遗忘门的输出决定)相乘来实现的。如果遗忘门的输出接近0,那么相应的信息将被“忘记”;如果接近1,则保留。
- 输入门/加法操作(Add):新的信息通过输入门被添加到单元状态中。这通常涉及将新的输入数据与学习到的权重相乘,生成一个候选值,该候选值通过加法操作被加到单元状态上。
- 单元状态(Cell State):单元状态是LSTM的核心,它携带通过序列传递的信息,可以认为是LSTM的“记忆”。
- 更新隐藏状态(Update Hidden):隐藏状态是LSTM单元的输出,也可以作为下一个时间步的隐藏状态的输入。它是单元状态的函数,但通过输出门进行过滤。
- 输出:LSTM单元的输出由当前的隐藏状态和单元状态组成,这些状态可以传递给下一个时间步的LSTM单元,或者用于当前时间步的预测。
在句子分类的上下文中,LSTM可以用来逐个词地处理整个句子,最后一个LSTM单元的输出可以用于预测句子的分类,比如情感分析中的正面或负面。LSTM能够通过它的门控机制来学习何时引入新信息、何时遗忘无关信息,以及何时利用已有信息,这使得它在处理各种顺序和时间序列数据时非常强大。
2.3 序列到序列(Seq2Seq)的递归神经网络(RNN)

这张图展示的是序列到序列(Seq2Seq)的递归神经网络(RNN)结构,它通常用于需要处理输入序列和生成输出序列的任务,如机器翻译、文本摘要或者语音识别。
Seq2Seq RNN 的工作流程如下:
- 初始状态:RNN 从一个初始状态开始,这个状态通常是零向量,代表了网络在处理序列之前的状态。
- 逐词更新状态:网络逐个单词接收输入序列。每个单词都被转换为一个向量(通常通过词嵌入),并且这个向量会被送入 RNN。
- 更新“心智状态”:对于输入序列中的每个单词,RNN 都会更新它的“心智状态”(即隐藏状态),这个状态捕获了到目前为止所有单词的信息。每一个新单词的输入都会与前一个隐藏状态相结合,产生一个新的隐藏状态。这个过程中,“update”步骤涉及对隐藏状态的更新,这通常包括对先前的状态进行某种形式的加权和,加入当前单词的信息。
- 保持状态传递:RNN 维持一个状态传递,随着序列的推进,这个状态包含了截至当前步骤的所有先前单词的信息。这使得网络可以考虑整个序列的上下文。
- 输出向量:每个更新步骤可能都会产生一个输出向量,这个向量代表了当前步骤的输出。在一个 Seq2Seq 任务中,输出序列可以是另一种语言的翻译,或者是标记序列,指示输入序列中每个单词的语言属性(如词性标记)。
Seq2Seq RNN 特别适合处理那些输入和输出都是序列的问题,它通过编码输入序列的上下文信息,并在每个时间步生成输出,来完成这一任务。在实践中,Seq2Seq 模型通常由一个编码器和一个解码器组成,编码器处理输入序列,解码器则基于编码器的最终状态来生成输出序列。
在句子分类任务中,Seq2Seq模型可能不是最直接的选择,因为它是为那些输入和输出都是序列的任务设计的。然而,如果句子分类任务涉及到根据输入句子生成标签序列(例如,给句子中的每个单词分配语法标签),Seq2Seq RNN就会非常适用。
这个模型的关键在于,每个单词不仅影响当前的“心智状态”(也就是隐藏状态),而且这个状态也会影响后续单词的处理。通过这种方式,RNN能够捕获序列的上下文信息,使得每个单词的处理都依赖于它前面的单词。
在机器学习中,Seq2Seq RNN通常需要大量的数据来训练,以便模型可以学习如何最好地更新其状态并生成准确的输出。这种类型的RNN在自然语言处理领域非常有价值,因为它们能够处理变长的序列,并且理解序列中元素之间复杂的依赖关系。
我们看到了一个双层循环神经网络(RNN)的结构,它被用于序列标记任务,比如词性标注。图中描述的网络结构包括两个RNN层,这些层串行相连,以处理更复杂的序列数据和捕获更深层次的时序特征。在自然语言处理中,双层RNN可以更有效地学习句子中词汇的上下文依赖关系。
2.4 双层RNN

2.4.1 双层RNN的工作步骤
- 输入序列:诸如“Time flies like arrows”这样的句子被输入到模型中。每个单词都通过词嵌入转换成一个向量。
- 第一层RNN(Layer 1):首先,这些词向量被送入第一层RNN。在这一层,每个单词的向量都会更新模型的隐藏状态。
- 第二层RNN(Layer 2):第一层的输出(隐藏状态)随后被用作第二层RNN的输入。第二层RNN进一步处理这些信息,生成新的隐藏状态,这些状态捕获了更长范围的依赖关系。
- 线性层:然后,从第二层RNN出来的每个隐藏状态都通过一个共享的线性层转换为一个输出向量(logits)。线性层的作用是将高维的隐藏状态映射到一个更低维的空间,该空间对应于任务的可能标签。
- 生成标签:最后,这些输出向量通常会通过一个softmax函数转换成概率分布,这个分布表示了每个单词属于不同标签的概率。例如,在词性标注中,每个单词可能会被标注为名词、动词等语法类别。
在这个过程中,句子中的每个单词通过两个RNN层的处理后,我们可以得到每个单词的上下文表示。然后通过线性层将这些表示转换为预测标签的得分或概率,最终确定每个单词的标签。
例如,在处理“Time flies like arrows”这句话时,模型可能会生成序列标签:“NOUN”(名词)、“VERB”(动词)、“ADP”(介词)等。这种双层RNN非常适合于捕捉更长距离的单词依赖关系,这对于理解和翻译诸如“La belle porte le voile”这样的语言结构也同样重要。
使用这种结构的RNN模型在训练时,需要大量标注好的数据来学习如何准确地对序列中的每个单词进行分类。这些模型通常在自然语言处理的多个任务中表现良好,包括机器翻译、语音识别以及文本生成等。
2.5 双向序列到序列(Bidirectional Seq2Seq)递归神经网络(RNN)
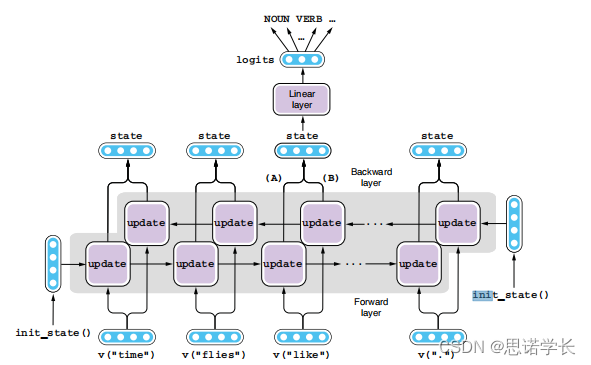
这张图展示了一个双向序列到序列(Bidirectional Seq2Seq)递归神经网络(RNN)的结构,它用于序列标注任务。在这种网络中,每个输入单词不仅依赖于之前的词,而且还考虑了之后的词,这对于诸如词性标注这样的任务非常有帮助。
双向RNN由两层组成:
前向层(Forward layer):这一层处理序列的正向信息流,即从第一个词到最后一个词。
后向层(Backward layer):这一层处理序列的反向信息流,即从最后一个词回到第一个词。
在给定时刻,每个层都会更新它的隐藏状态,并将其发送到下一时刻。对于前向层来说,隐藏状态的更新依赖于当前词及之前的所有词;对于后向层,它依赖于当前词及之后的所有词。
双向Seq2Seq RNN的工作步骤如下:
- 初始化状态:每个RNN层从一个初始化状态开始。
- 逐词更新状态:随着序列中的每个新词的输入,前向层和后向层都会分别更新它们的隐藏状态。
- 合并状态:在每个时间步,来自前向层和后向层的隐藏状态被合并,这样每个词都包含了整个句子的上下文信息。
- 线性层:合并后的隐藏状态通过一个共享的线性层,该层生成用于后续分类任务的logits。
- 生成标签:最终,logits通过激活函数(如softmax)转换成标签的预测概率,每个概率对应一个特定的词性或其他标签。
例如,对于句子“Time flies like arrows”,双向RNN可以标注出“Time”为名词(NOUN),“flies”为动词(VERB),等等。通过同时考虑每个词之前和之后的词,双向RNN能够更准确地捕捉语言的语义信息,提高序列标注的准确率。
2.6 编码器-解码器序列到序列(Seq2Seq)模型

这张图片展示了一个机器翻译(MT)任务中的编码器-解码器序列到序列(Seq2Seq)模型的结构。这种类型的模型通常用于需要将一个序列转换为另一个序列的任务,如机器翻译。
在这个例子中,编码器-解码器模型包括两个部分:
- 编码器(Encoder):编码器的任务是读取输入序列(例如一句话),并产生这个序列的内部表示。在图中,输入序列是西班牙语的句子 "Maria no baba verde."。每个词被模型转换为一个向量表示,这些向量经过编码器的处理,最终生成整个句子的内部表示。编码器可以是循环神经网络(RNN)、双向循环神经网络(bi-RNN)、长短期记忆网络(LSTM)或双向长短期记忆网络(bi-LSTM)。
- 解码器(Decoder):解码器接收编码器生成的内部表示,并以此为基础生成输出序列。输出序列可以是任意长度的句子。在图中,解码器开始于一个特殊的开始标记 "<START>",然后生成翻译后的英语句子 "Mary did not watch .",每生成一个词,解码器就会更新它的状态,并依此状态和之前生成的词来预测下一个词。解码器也可以使用类似于编码器的网络结构。
这个过程持续进行,直到解码器产生一个特殊的结束标记 "<END>",标志着翻译句子的结束。
这种类型的模型能够处理变长的输入和输出序列,适用于各种序列生成任务。在机器翻译中,模型学习如何将一种语言中的句子映射到另一种语言中的等价句子。
2.7 注意力机制(Attention Mechanism)
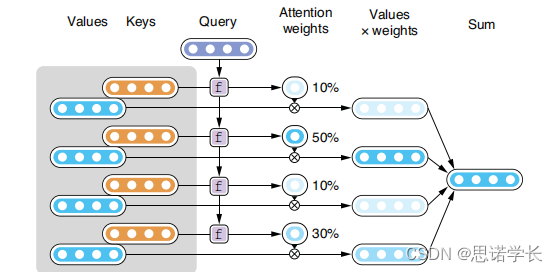
这张图片展示了一个注意力机制(Attention Mechanism)的工作原理,它是神经网络中的一种常见技术,特别是在序列到序列的模型中,如机器翻译。
注意力机制可以帮助模型专注于输入序列中的重要信息,从而更好地执行诸如翻译、摘要或图片描述生成等任务。
在这个图示中,注意力机制涉及以下几个步骤:
- 值(Values):这些通常是编码器隐藏状态的表示,包含了输入序列(如一句话)的信息。
- 键(Keys):这些是通过学习得到的向量,它们与值(Values)一起用来生成注意力分数。每个键对应一个值。
- 查询(Query):查询是一个表示当前解码器状态的向量,它用来查找最相关的输入信息。
- 函数f:这个函数计算查询(Query)和每个键(Keys)之间的相似度或对齐分数。
- 注意力权重(Attention weights):通过函数f计算得到的分数将转换成权重,表示每个值的重要性。
- 加权的值(Values x weights):每个值将乘以其相应的注意力权重,反映了其在当前解码步骤的重要性。
- 总和(Sum):所有加权的值加起来,形成一个单一的向量,这个向量是当前解码步骤下对输入序列的加权表示。
在给定的例子中,注意力权重分别是10%,50%,10%和30%,这意味着第二个值最重要,因此在生成当前词时它将最多地影响解码器的输出。
简而言之,注意力机制使得模型能够动态地关注输入序列的不同部分,并根据这些信息来改善其性能。在机器翻译的场景下,这意味着解码器在翻译每个词时可以专注于输入句子中与之最相关的部分。
2.8 编码器-解码器结构中的注意力机制(Attention Mechanism)

这张图片展示了编码器-解码器结构中的注意力机制(Attention Mechanism)。注意力机制是一种能够使模型在处理一个数据点时,有选择性地集中注意力于数据集中的其他相关数据点的技术。在机器翻译中,这允许解码器在生成翻译的每个词时重点关注输入句子中最相关的部分。
在这个图示中:
- 键(Keys)和值(Values):键通常是编码器的输出,它们与相对应的值一起,表示输入句子中每个词的信息。这些值是编码器隐藏状态的表示。
- 查询(Query):查询是解码器的隐藏状态,代表当前正在解码的步骤。
- 注意力权重(Attention Weights):使用一个查询和所有键计算相似度得分,这些得分通过一个函数(例如 softmax)转换为概率分布,称为注意力权重。这意味着每个键的权重反映了当前查询与该键的相对关联程度。
- 加权和(Weighted Sum):通过将每个值与其相应的注意力权重相乘,然后将它们相加,来计算加权和。这个加权和被称为上下文向量,是对输入句子的加权表示,重点是对当前查询来说最相关的部分。
- 上下文向量(Context Vector):上下文向量随后用于解码器的下一个时间步,帮助解码器决定下一个输出词应该是什么。在图中,上下文向量是由解码器的当前隐藏状态(查询)和编码器的输出(键和值)共同计算得出。
在这个示例中,解码器在尝试生成翻译的 "Mary did ..." 部分时,会使用注意力机制来确定输入句子 "Maria no baba verde." 中的哪些词对当前步骤最相关。每个解码步骤都会产生一个新的上下文向量,导致解码器在生成翻译时会聚焦于输入句子中不同的部分。
2.9 多头自注意力(Multihead Self-Attention)

这张图片展示的是多头自注意力(Multihead Self-Attention)的一个可视化示例。自注意力是一种特殊形式的注意力机制,它允许模型在同一序列内部的不同位置之间进行交互,以便捕捉到不同词之间的依赖关系。这在处理诸如翻译、文本摘要等序列到序列的任务时非常有用。
在多头自注意力中,"多头"意味着模型不止进行一次注意力计算,而是并行地进行多次,每一次都有不同的权重,这样可以让模型同时从多个角度学习信息。
在这个例子中,我们看到的是单词序列 "The animal didn't cross the street because it was too tired"。每个单词对序列中其他单词的注意力分布是通过连接线的粗细表示的。线越粗,表示注意力权重越高,也就是说模型认为这两个词之间的关系越重要。
自注意力可以捕捉多种类型的词间对应关系,包括语法结构、词义相关性、以及长距离依赖等。例如,在这个句子中,模型可能学习到“it”与“animal”具有强关联性,因为“it”通常用来指代前文提到的主体。
多头自注意力机制的核心思想是让模型自动学习序列内部的复杂依赖关系,无需外部指导或复杂的预处理。这种注意力机制是Transformer模型的基础,而Transformer已经成为了自然语言处理任务的一个主要架构。
2.10 Transformer模型
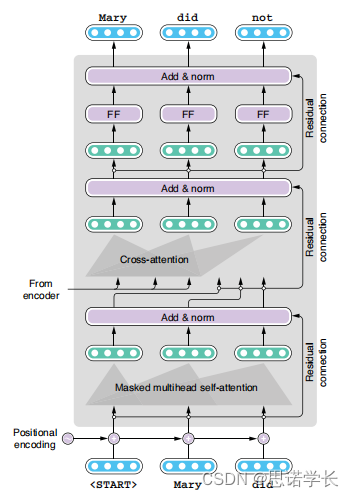
这张图片展示了Transformer模型中解码器部分的结构。Transformer 是一种重要的深度学习模型,它在处理序列数据,尤其是在自然语言处理领域取得了显著成果。图中的每一层都执行不同的操作,为解码过程提供所需的上下文信息和序列位置信息。
- 位置编码(Positional Encoding):由于Transformer模型本身不处理序列的顺序信息,位置编码通过向输入的每个元素添加一个独特的编码来引入元素的顺序信息。通常,这是通过正弦和余弦函数的组合来实现的,以确保每个位置的编码是唯一的。
- 掩蔽多头自注意力(Masked Multihead Self-Attention):掩蔽是必要的,因为在解码时,一个词只能依赖于它之前的词(即它不应该看到未来的词)。多头自注意力允许模型在生成当前词时,捕获输入序列中不同位置的信息。
- 交叉注意力(Cross-Attention):这一层使用编码器的输出来增强解码器。它允许解码器的每个位置关注编码器输出的相应位置,这有助于解码器理解和翻译输入序列。
- 前馈网络(Feed-Forward Networks, FF):这是由两个线性变换和一个ReLU激活函数组成的简单网络,用于处理自注意力层的输出。
- 加法 & 规范化(Add & Norm):每个子层的输出都会与其输入相加(残差连接),然后进行层规范化。这有助于防止训练过程中的梯度消失问题,并加速收敛。
- 残差连接(Residual Connection):这是确保网络可以学习到深层次特征而不丢失浅层次信息的关键设计。通过将输入直接添加到子层的输出上,残差连接可以帮助缓解梯度消失问题。
图中展示的是在解码 "Mary did not" 这个序列时的各个阶段。从 "<START>" 代表的解码起始位置开始,每一个步骤都加上位置编码,然后通过掩蔽多头自注意力机制、交叉注意力机制和前馈网络,最终生成序列的下一个词。这个过程会一直重复,直到生成 "<END>" 代表序列的终止。

