
热门标签
热门文章
- 1【AI绘画】从零开发AI绘画微信小程序_可以利用ai设计图形界面吗微信小程序界面
- 2 Serverless Computing:现状与基础知识
- 3Fixed-Point Designer:Create Fixed-Point Data
- 4Navicat Premium15 下载与安装(免费版)以及链接SqlServer数据库_navicat premium 15下载
- 5零信任相关标准、框架及落地实践(下)_华三零信任 反向代理
- 6Triton inference server系列(0)——相关资料整理_triton server 相关文献
- 7Mac 更新 Homebrew软件包时提示 zsh: command not found: brew 错误
- 8十大开源测试工具和框架_bestdb 6.0.0是开源的吗
- 9[注意力机制]--Non-Local注意力的变体及应用_nonlocal注意力
- 10Linux安装oracle 19c_linux安装oracle19c
当前位置: article > 正文
爬虫爬取必应和百度搜索界面的图片_必应图片爬虫
作者:神奇cpp | 2024-07-09 02:32:22
赞
踩
必应图片爬虫
爬取bing搜索图片界面
浏览器驱动下载地址
对应版本即可
mad直接用
import os import re from selenium import webdriver from selenium.webdriver import Keys from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By import time os.chdir(r"D:\software_project\超声波水流量专利\code") # 下载图片的函数 import requests from fake_useragent import UserAgent # 添加了一个额外的参数 image_number 来跟踪图片编号 def download_image(url, folder, image_number): try: # 生成随机的User-Agent ua = UserAgent() headers = {'User-Agent': ua.random} # 发送带有User-Agent的请求 response = requests.get(url, headers=headers, stream=True) response.raise_for_status() # 使用图片编号来生成文件名 file_name = f"{image_number}.png" file_path = os.path.join(folder, file_name) with open(file_path, 'wb') as f: for chunk in response.iter_content(1024): f.write(chunk) print(f"图片下载成功: {file_name}") except requests.exceptions.RequestException as e: print(f"图片下载失败: {e}") # 指定ChromeDriver的路径 chrome_driver_path = r"D:\software_project\超声波水流量专利\code\chromedriver\chromedriver.exe" service = Service(executable_path=chrome_driver_path) # 创建WebDriver实例 driver = webdriver.Chrome(service=service) # 搜索关键词 keyword = "饮料" # 可以替换为其他关键词 # driver.get("https://cn.bing.com/images/search?q=" + keyword) # 第二种写法,找到搜索框并输入关键词 # 适合精准收索 driver.get("https://cn.bing.com/images/") search_box = driver.find_element(By.ID, "sb_form_q") # 设置sb_form_q的值为0 driver.execute_script("document.getElementById('sb_form_q').value ='';") search_box.send_keys(keyword + Keys.ENTER) # 等待页面加载 time.sleep(1) # 根据您的网络速度,可能需要调整等待时间 # 滚动页面加载更多图片 for i in range(10): # 滚动 5 次 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(1) # 等待页面加载 # 获取图片元素 image_elements = driver.find_elements(By.CSS_SELECTOR, "img.mimg") # 提取图片URL image_urls = [img.get_attribute("src") for img in image_elements if img.get_attribute("src") is not None] for index, url in enumerate(image_urls[3:], start=1): download_image(url, "下载的图片", index) # 关闭浏览器 driver.quit()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
爬取百度搜索界面图片
mad直接用
import os import re import requests from selenium import webdriver from selenium.webdriver import Keys from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By import time from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys import time os.chdir(r"D:\software_project\超声波水流量专利\code") # 清理文件名的函数 def clean_filename(filename): return re.sub(r'[\\/*?:"<>|]', '', filename) # 下载图片的函数 import requests from fake_useragent import UserAgent # 添加了一个额外的参数 image_number 来跟踪图片编号 def download_image(url, folder, image_number): try: # 生成随机的User-Agent ua = UserAgent() headers = {'User-Agent': ua.random} # 发送带有User-Agent的请求 response = requests.get(url, headers=headers, stream=True) response.raise_for_status() # 使用图片编号来生成文件名 file_name = f"{image_number}.png" file_path = os.path.join(folder, file_name) with open(file_path, 'wb') as f: for chunk in response.iter_content(1024): f.write(chunk) print(f"图片下载成功: {file_name}") except requests.exceptions.RequestException as e: print(f"图片下载失败: {e}") # 指定ChromeDriver的路径 chrome_driver_path = r"D:\software_project\超声波水流量专利\code\chromedriver\chromedriver.exe" service = Service(executable_path=chrome_driver_path) # 创建WebDriver实例 driver = webdriver.Chrome(service=service) # 搜索关键词 keyword = "饮料" # 可以替换为其他关键词 driver.get(f"https://image.baidu.com/search/index?tn=baiduimage&word={keyword}") # 记得对比链接 # https://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&dyTabStr=MCwzLDEsMiw2LDQsNSw4LDcsOQ%3D%3D&word=%E5%9B%BE%E7%89%87 # 等待页面加载 time.sleep(2) # 根据您的网络速度,可能需要调整等待时间 # 滚动页面加载更多图片 for i in range(5): # 滚动 5 次 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(1) # 等待页面加载 # 获取图片链接 image_elements = driver.find_elements(By.CLASS_NAME, "main_img") image_urls = [] for img in image_elements: # 尝试从不同的属性中获取图片URL src = img.get_attribute("src") or img.get_attribute("data-src") or img.get_attribute("data-original") if src: image_urls.append(src) for index, url in enumerate(image_urls[3:], start=1): download_image(url, "下载的图片2", index) # 关闭浏览器 driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
结果如下
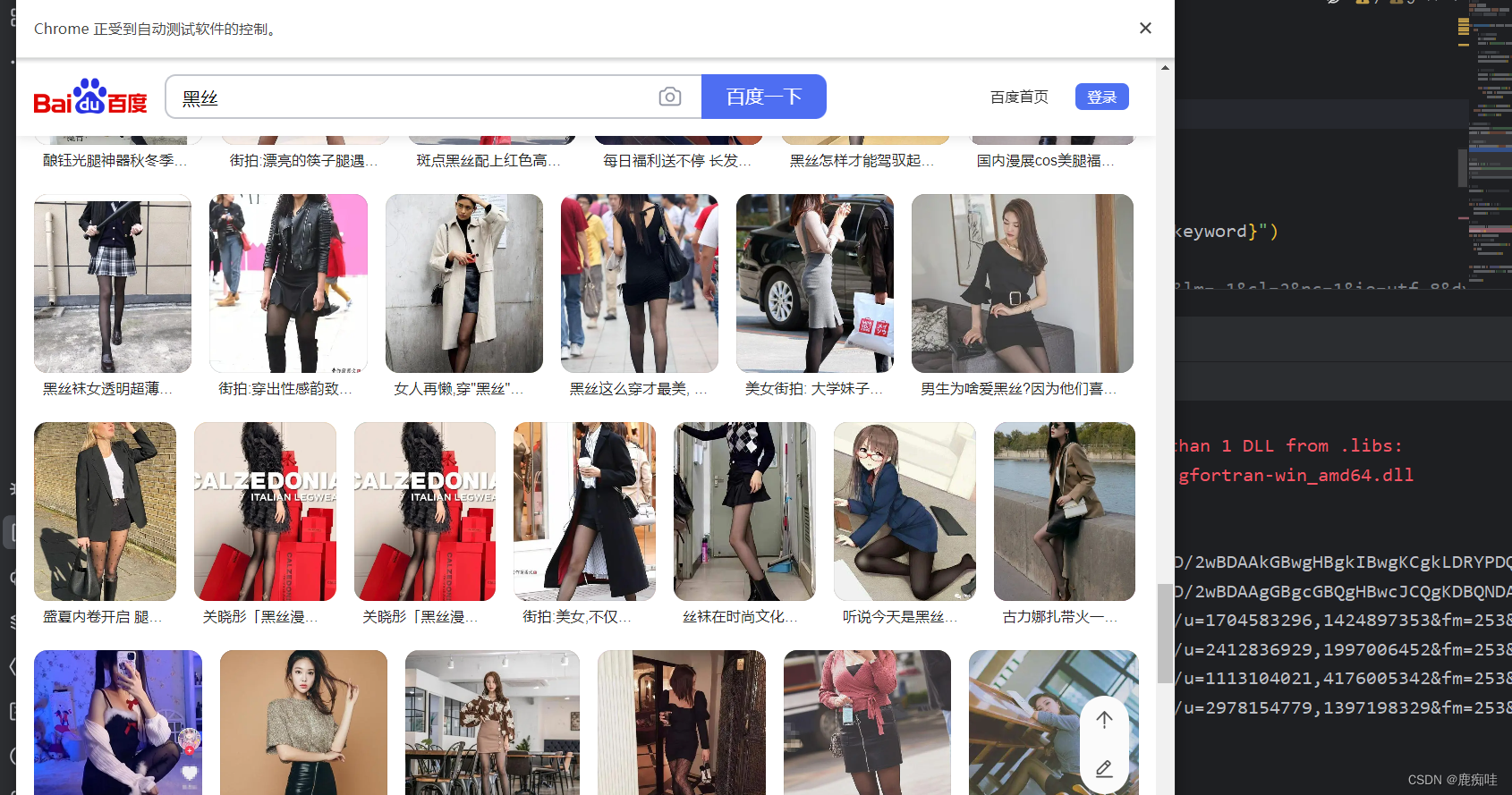
在这里插入图片描述
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签

