
- 1利用Tensorflow构建生成对抗网络GAN以生成数据_使用对抗网络进行数据生成 csdn
- 2Java服务和Gradle禁用代理
- 3近端梯度下降与软阈值迭代:PGD and ISTA_ista软阈值迭代 证明
- 4基于uniapp+vue3+vite实现小程序构建Android、iOS多端项目配置详解_uniapp vue3
- 5为什么建议iOS开发使用Swift_ios swift
- 6Doris:数据表设计_doris aggregate
- 7产品应用 | 小盒子跑大模型!英码科技基于算能BM1684X平台实现大模型私有化部署_算能1684
- 8Mysql权限问题: Access denied; you need (at least one of) the RELOAD privilege(s) for this operation_access denied; you need (at least one of) the relo
- 9Android Studio gradle下载失败_gradle-8.0-bin.zip 下载失败
- 10分享我的Android蓝牙开源作品—HBluetooth
Serverless Computing:现状与基础知识
赞
踩
说明:文章内容来自网络文章的整理和翻译以及ATA文章知识的汇总,知识点及数据具体出处见参考部分
背景
云计算的发展在经历了IaaS(Infrastructure as a Service-基础设施即服务),PaaS(Platform as a Service-平台即服务),SaaS(Software as a Service-软件即服务)几个阶段后,Serverless(无服务器化)趋势越发明显,时至今日,无服务器计算(Serverless Computing)作为云原生计算模型的应用也日臻完善,相关产品也是各云厂商竞相角逐的战场。
Serverless落地情况(Serverless Landscape)
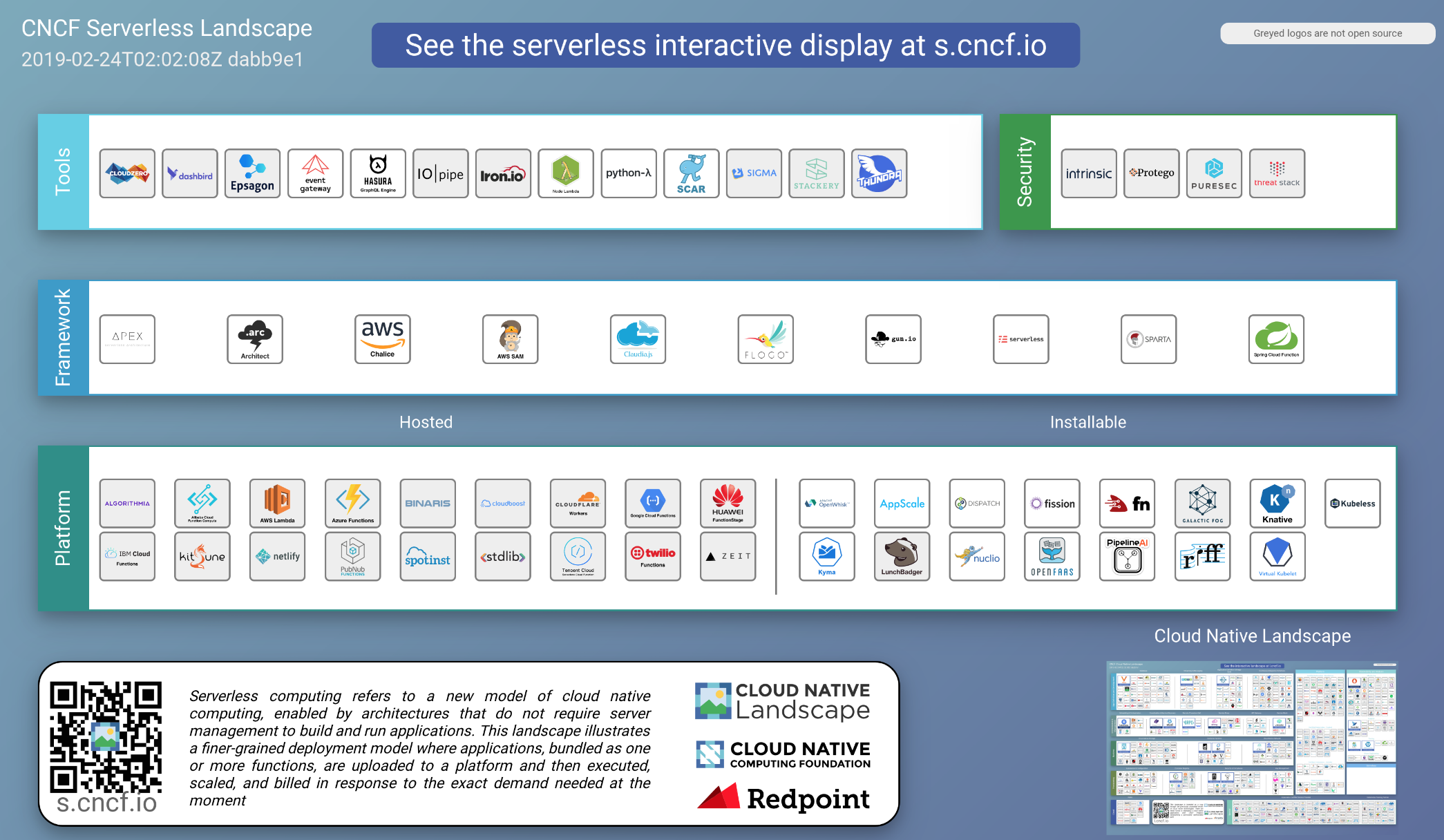
从CNCF Serverless Landscape中看出,Serverless落地产品形态一般分为如下三类:
- 公有云Severless平台,代表性的有:
- 私有云Severless框架,代表性的有:
- Fission (Kubernetes)
- Funktion (Kubernetes)
- Kubeless (Kubernetes)
- Gestalt (DC/OS)
- IBM OpenWhisk (Docker)
- Iron Functions (Docker,Swarm, Kubernetes)
- Serverless平台的包装框架,代表性的有:
- Serverless(Node,大多数平台)
- Apex(Go,AWS)
- Zappa(Python,AWS)
- Chalice(Python,AWS)
- Claudia.js(Node,AWS)
- Gordon (Python,AWS)
Serverless发展趋势
截至2018年12月Google Trends 的结果所示,“Serverless”的搜索量在过去三年中增加了近 20 倍。

"RightScale 2018 State of the Cluoud Report" 中指出Serverless是增长最快的扩展云服务,不仅在基本计算、存储和网络服务领域,即使在最流行的扩展服务、关系数据库、推送通知和缓存中仍保持在前三位

相比于2017年Serverless的年增长率达到了75%,已经超过了Container-as-aservice(容器即服务),位列第一


The New Stack 的一份报告中的付费调研也指出,78%的参与者表示他们将在未来几个月内使用或计划使用 Serverless 技术。

Serverless Computing概念
云原生计算基金会CNCF(Cloud Native Computing Foundation, CNCF)Serverless Whitepaper v1.0对无服务器计算作了如下定义:
Serverless computing refers to the concept of building and running applications that do not require server management. It describes a finer-grained deployment model where applications, bundled as one or more functions, are uploaded to a platform and then executed, scaled, and billed in response to the exact demand needed at the moment.
无服务器计算(Serverless Computing)是指在构建和运行应用时无需管理服务器等基础设施。它描述了一个更细粒度的部署模型,在该模型中,应用被拆解为一个或多个细粒度的函数被上传到一个平台,然后根据当前所需执行、扩展和计费。
无服务器计算并不意味着我们不再使用服务器来承载和运行代码,也不意味着不再需要运维工程师。而是指无服务器计算的消费者不再需要花费时间和资源在服务器配置、维护、更新、扩展和容量规划上。所有这些任务和功能都由无服务器平台处理,并且完全从开发人员和IT/操作团队中抽象出来。因此,开发人员专注于编写应用程序的业务逻辑。运营工程师能够将他们的重点提升到更关键的业务任务上。
FaaS & BaaS
无服务器计算平台可以提供以下一种或两种服务:
- FaaS(Functions-as-a-Service-函数即服务),通常提供事件驱动(event-driving)的计算。开发人员使用由事件(event)或HTTP请求触发的函数运行和管理应用程序代码。开发人员将小的代码单元部署到FaaS,FaaS按需执行和扩展,开发人员无需管理服务器或任何其他底层基础设施。
- Baas(Backend-as-a-Service后端即服务),是第三方基于API的服务,用于替换应用程序中的核心功能子集。因为这些API是作为一个自动扩缩容和透明操作的服务提供的,所以开发人员认为这是无服务器的 ,如:OSS
Pros & Cons
无服务器计算(Serverless Computing)应用利弊大致如下:
Pros:
- 0服务器操作。无服务器通过消除维护服务器资源所涉及的开销,极大地改变了运行软件应用程序的成本模型。
- 没有配置、更新和管理服务器基础结构。
- 弹性伸缩:无服务器FaaS或BaaS产品可以立即精确地伸缩以处理每个单独的传入请求。对于开发人员来说,无服务器平台没有“预先计划的容量”的概念,也不需要配置“自动伸缩”触发器或规则。在没有开发人员干预的情况下,自动进行缩放。在完成请求处理后,无服务器FaaS会自动缩小计算资源的规模,以确保永远没有空闲的容量。
- 低成本。无服务器计算服务对空闲的虚拟机或容器不收费;也就是说当代码没有运行或没有进行有意义的工作时,不收费。
Cons:
- 作为一种新兴的计算模型、缺乏标准化和生态系统成熟度。
- 由于运行时更具动态性,与iaas和paas相比,调试可能更具挑战性。
- 由于按需结构,如果运行时在空闲时删除函数的所有实例,则某些无服务器运行时的“冷启动”方面可能是性能问题。
- 在更复杂的情况下(例如,触发其他功能的功能),对于相同数量的逻辑,可以有更多的操作表面积。
Serverless处理模型(Serverless Processing Model)
CNCF白皮书对于无服务器框架中的函数用法,函数约束、生命周期、调用类型和所需的抽象等定义了规范,以便同一个函数可以一次性编码,并在不同的无服务器框架中使用。

FaaS解决方案概括为具有以下图中所示的几个关键元素:
- 事件源(Event sources)-触发器或流事件到一个或多个函数实例中
- 函数实例(Function instances)-单个函数/微服务,可根据需求进行扩展
- FaaS控制器(FaaS Controller)-部署、控制和监视函数实例及其源
- 平台服务(Platform services )-FaaS解决方案使用的通用集群或云服务(有时称为后端即服务-BaaS)
CNCF函数相关规范
函数定义(Function Definition)
无服务器函数定义可以包含以下规范和元数据,函数定义是特定于版本的:
- 唯一ID
- 名字
- 描述
- 标签
- 版本ID(和/或版本别名)
- 版本创建时间
- 上次修改时间(函数定义的)
- 函数处理程序
- 运行时语言
- 代码+依赖项或代码路径和凭据
- 环境变量
- 执行角色和密钥
- 资源(所需的CPU、内存)
- 执行超时时间
- 日志失败(死信队列)
- 网络策略/vpc
- 数据绑定(Metadata Binding)
元数据详细信息(Metadata details)
- 版本(Version)-每个函数版本都应该有一个唯一的标识符,此外,可以使用一个或多个别名(例如“最新”、“生产”、“测试版”)标记版本。API网关和事件源将流量/事件路由到特定的函数版本。
- 环境变量(Environment Variables)-用户可以指定将在运行时提供给函数的环境变量。环境变量也可以从机密和加密内容派生,或者从平台变量派生(例如,kubernetes envvar定义)。环境变量使开发人员能够控制函数行为和参数,而无需修改代码和/或重建函数,从而获得更好的开发人员体验和函数重用。
- 执行角色(Execution Role)-该函数应在特定的用户或角色标识下运行,该标识授予并审核其对平台资源的访问权限。
- 资源(Resources)-定义功能所需的或最大的硬件资源,如内存和CPU。
- 超时(Timeout)-指定函数调用在被平台终止之前可以运行的最长时间。
- 失败日志(死信队列)(Failure Log (Dead Letter Queue))-队列或流的路径,用于存储失败的函数执行列表,并提供适当的详细信息。
- 网络策略(Network Policy)-分配给功能的网络域和策略(用于与外部服务/资源通信的功能)。
- 执行语义(Execution Semantics)-指定应如何执行函数(例如,每个事件至少执行一次、至多执行一次、完全执行一次)。
数据绑定(Data Bindings)
一些无服务器框架允许用户指定函数使用的输入/输出数据资源,这使开发人员能够简化、提高性能(在执行之间保留数据连接,可以预取数据等)和更好的安全性(数据资源凭据是上下文的一部分,而不是代码)。
绑定数据可以是文件、对象、记录、消息等形式,函数规范可以包括一组数据绑定定义,每个定义指定数据资源、其凭证和使用参数。数据绑定可以引用事件数据(例如,db键是从事件“用户名”字段派生的),示例:https://docs.microsoft.com/azure/azure-functions/functions-triggers-bindings
函数约束(Function Requirements)
函数和无服务器运行时应该满足的通用需求:
- 函数必须与不同事件类的基础实现分离
- 可以从多个事件源调用函数
- 每个调用方法不需要不同的函数
- 事件源可以调用多个函数
- 函数可能需要与底层平台服务进行持久绑定的机制,这可能是跨函数调用。函数可能是短暂的,但如果需要在每次调用(例如在日志记录、连接和装载外部数据源的情况下)上都进行引导,则引导可能会很昂贵。
- 每个函数可以用不同于同一应用程序中使用的其他函数的代码语言编写。
- 函数运行时应尽可能减少事件序列化和反序列化开销(例如,使用本机语言结构或有效的编码方案)
函数调用类型(Function Invocation Types)
根据不同的用例,可以从不同的事件源调用函数,例如:
- 同步请求(Synchronous Request (Req/Rep)),例如http请求、grpc调用
- 客户机发出请求并等待立即响应。这是一个阻塞呼叫。
- 异步消息队列请求(pub/sub)(Asynchronous Message Queue Request),例如RabbitMQ, AWS SNS, MQTT, Email, Object (S3) change、计划事件(如cron作业)
- 消息发布到交换并分发到订阅服务器
- 没有严格的消息顺序, 可一次处理
- 消息/记录流(Message/Record Streams):Kafka, AWS Kinesis, AWS DynamoDB Streams, Database CDC
- 一组有序的消息/记录(必须按顺序处理)
- 通常,一个流被分割到多个分区/碎片(partitions/shards ),每个碎片有一个worker(碎片使用者)
- 流可以从消息、数据库更新(日志)或文件(例如csv、json、parquet)生成。
- 事件可以推送到函数运行时,也可以由函数运行时拉取。
- 批处理作业(Batch Jobs),例如ETL作业、分布式深度学习、HPC模拟
- 作业(Jobs)被调度或提交到队列,并在运行时使用多个并行函数实例进行处理,每个实例处理工作集(任务)的一个或多个部分。
- 当所有并行工作人员成功完成所有计算任务时,作业完成。

函数生命周期(Function LifeCycle)
函数部署管道(Function Deployment Pipeline)

函数生命周期:
- 编写代码、提供规范和元数据
- 获取代码和规范,编译并将其转化为一个工件(二进制代码、包或容器镜像)
- 工件部署到一个集群上,控制器实体负责根据事件流量和/或实例上的负载调整函数实例的数量。
函数操作(Function Operations)
无服务器框架可能允许以下操作和方法定义和控制功能生命周期:
- 创建(Create)-创建一个新函数,包括其规范和代码
- 发布(Publish)-创建可部署在群集上的函数的新版本
- 更新别名/标签(Update Alias/Label [of a version])-更新版本别名
- 执行/调用(Execute/Invoke)-不通过事件源调用特定版本
- 事件源关联(Event Source association )-将函数的特定版本连接到事件源
- 获取(Get)-返回函数元数据和规范
- 更新(Update)-修改函数的最新版本
- 删除(Delete)-删除一个函数,可以删除一个特定的版本或函数的所有版本
- 清单(List)-显示函数及其元数据的列表
- 状态获取(get stats)-返回有关函数运行时使用情况的统计信息
- 日志获取(get logs)-返回函数生成的日志

关键步骤说明:
- Create:在创建函数时,提供其元数据(稍后在函数规范中描述)作为函数创建的一部分,将对其进行编译并可能发布。稍后可以启动、禁用和启用功能。功能部署需要能够支持以下用例:
- 事件流(Event streaming),在这种情况下,队列中可能总是有事件,但是可能需要通过显式请求暂停/恢复处理。
- 热启动(Warm startup)-在任何时候具有最少实例数的函数,例如,接收到的“第一个”事件具有热启动,因为该函数已经部署并准备好服务于该事件(而不是在“传入”事件第一次调用时部署该函数的冷启动)。
- Publish:用户可以发布一个函数,这将创建一个新版本(最新版本的副本),发布的版本可能会被标记/标记或有别名,请参阅下面的详细信息。
- 用户可能希望为调试和开发过程直接执行/调用函数(绕过事件源或API网关)。用户可以指定调用参数,如所需版本、同步/异步操作、详细级别等。
- 用户可能希望获得函数统计信息(例如调用次数、平均运行时间、平均延迟、失败、重试次数等),统计信息可以是当前度量值或一系列值(例如存储在Prometheus或云提供程序设施(如AWS Cloud Watch))。
- 用户可能希望检索函数日志数据。这可以根据严重性级别和/或时间范围和/或内容进行筛选。日志数据是每个函数的,它包括诸如函数创建和删除、显式错误、警告或调试消息等事件,还可以选择函数的stdout或stderr。每次调用最好有一个日志条目,或者一种将日志条目与特定调用关联的方法(以便更简单地跟踪函数执行流)。
事件源(Event Source)
不同类型的事件源包括:
- 事件和消息服务,例如: RabbitMQ, MQTT, SES, SNS, Google Pub/Sub
- 存储服务,例如:S3, DynamoDB, Kinesis, Cognito, Google Cloud Storage, Azure Blob, iguazio V3IO (object/stream/DB)
- 端点服务,例如:物联网(IoT)、HTTP网关(HTTP Gateway)、移动设备、Alexa、Google Cloud Endpoints
- 配置存储库,例如:Git, CodeCommit
- 使用特定于语言的sdk的用户应用程序
- 定时事件-允许定期调用函数。
事件源到函数的关联(Event Source to Function Association)
函数是由事件源触发的事件调用的。函数和事件源之间有一个n:m映射。每个事件源可以用来调用多个函数,一个函数可以由多个事件源触发。事件源可以映射到函数的特定版本或函数的别名,后者提供了更改函数的方法,并部署了一个新版本,而不需要更改事件关联。事件源也可以定义为使用同一函数的不同版本,定义应为每个函数分配多少流量。
在创建了一个函数之后,或者在以后的某个时间点,需要将事件源关联起来,该事件源应该作为该事件的结果触发函数调用。这需要一组操作和方法,例如:
- 创建事件源关联
- 更新事件源关联
- 列出事件源关联
函数输入(Function Input)
函数输入包括事件数据(event data)和元数据(metadata),并且可以包括一个上下文对象(context object)。
事件数据和元数据(Event data and metadata)
事件详细信息应传递给函数处理程序,不同的事件可能具有不同的元数据,因此函数需要能够确定事件的类型并轻松解析通用和特定于事件的元数据。
将事件类与实现分离是可取的,例如:处理消息流的函数将工作相同,而不管流存储是Kafka还是Kinesis。在这两种情况下,它都将接收消息体和事件元数据,消息可以在不同的框架之间路由。
事件可以包括单个记录(例如,在请求/响应模型中),或者接受多个记录或微批(例如,在流模式中)。
FaaS解决方案使用的常见事件数据和元数据示例:
- 事件类别
- 版本
- 事件ID
- 事件来源/来源
- 源识别
- 内容类型
- 消息体
- 时间戳
事件/记录特定元数据的示例:
- HTTP: 路径、方法、头、查询参数
- Message Queue:消息队列:主题,标题
- 记录流(Record Stream):表、键、op、修改时间、旧字段、新字段
事件源结构示例:
- AWS Lambda:http://docs.aws.amazon.com/lambda/latest/dg/eventsources.html
- Microsoft Azure Functions:https://docs.microsoft.com/azure/azure-functions/functions-triggers-bindings
- Google Cloud Functions:https://cloud.google.com/functions/docs/concepts/events-triggers
有些实现将JSON作为向函数传递事件信息的机制来关注。这可能会增加高速函数(例如流处理)或低能耗设备(IOT)的大量序列化/反序列化开销。在这些情况下,将本机语言结构或其他序列化机制视为选项可能是值得的。
函数上下文(Function Context)
当调用函数时,框架可能希望提供对跨多个函数调用的平台资源或常规属性的访问,而不是将所有静态数据放在事件中,或强制函数在每次调用时初始化平台服务。
上下文作为一组输入属性、环境变量或全局变量传递。有些实现使用这三种方法的组合。
上下文示例:
- 函数名、版本、ARN
- 存储限制(Memory Limit)
- 请求ID(Request ID)
- 云区(Cloud Region)
- 环境变量(Environment Variables)
- 安全密钥/令牌(Security keys/tokens)
- 运行时/bin路径(Runtime/Bin paths)
- 日志(Log )
- 数据绑定(Data binding)
一些实现使用日志对象初始化日志对象(例如,作为AWS中的全局变量或Azure中的部分上下文),用户可以使用集成平台工具跟踪函数执行。除了传统的日志记录之外,未来的实现可能会将计数器/监视和跟踪活动抽象为平台上下文的一部分,以进一步提高功能的可用性。
数据绑定作为函数上下文的一部分,平台根据用户配置启动到外部数据资源的连接,这些连接可以在多个函数调用中重用。
函数输出(Function Output)
当函数退出时,它可以:
- 向调用者返回一个值(例如,在HTTP请求/响应示例中)
- 将结果传递到工作流中的下一个执行阶段
- 将输出写入日志
应该有一种确定的方法来知道函数是否通过返回的错误值或退出代码成功或失败。
函数输出可以是结构化的(如HTTP响应对象)或非结构化的(如某些输出字符串)。
无服务器函数工作流(Serverless Function Workflow)
- 在无服务器域中,用例(Use Case)属于以下类别之一:
- 一个事件触发一个函数
- 事件的和/或组合触发一个函数
- 一个事件触发顺序或并行执行的多个函数
- 函数的结果可能是另一个函数的触发器
- n个事件(i n和/或)触发m个函数,即事件函数交错的工作流,如事件1触发函数1,完成函数1和事件2以及事件3触发函数2,然后函数2的不同结果触发分支到函数3或函数4。
用户需要一种方法来指定他们的无服务器用例或工作流。例如,一个用例可以是“在照片上传到云存储时在照片上进行人脸识别(发生照片存储事件)。”另一个物联网用例可以是“在接收到运动检测事件时进行运动分析”,然后根据分析功能的结果,或者“触发房屋警报并调用e警察部门“或只是”将运动图像发送给房主。“有关详细信息,请参阅用例部分。
AWS提供“步骤函数”(step function),供用户指定其工作流,但步骤函数不允许指定触发工作流中哪些函数的事件/事件。
下图是涉及事件和函数的用户工作流的示例。使用这种函数图,用户可以轻松地指定事件和函数之间的交互,以及如何在工作流中的函数之间传递信息。

功能图状态包括:
- Event State(事件状态):此状态允许等待来自事件源的事件,然后触发函数运行或多个函数按顺序、并行或在分支中运行。
- Operation/Task State(操作/任务状态):此状态允许按顺序或并行运行一个或多个函数,而不等待任何事件。
- Switch/Choice State(切换/选择状态):此状态允许转换到多个其他状态(例如,前一个函数结果触发分支/转换到不同的下一个状态)。
- End/Stop State(结束/停止状态):此状态以失败/成功终止工作流。
- Pass State(通过状态):此状态在两个状态之间插入事件数据。
- Delay/Wait State(延迟/等待状态):此状态导致工作流执行延迟指定的持续时间或直到指定的时间/日期。
状态和相关信息需要保存在一些持久存储中,以便进行故障恢复。在某些用例中,用户可能希望将来自一个状态的信息传递到下一个状态。这些信息可以是函数执行结果的一部分,也可以是与事件触发器关联的输入数据的一部分。需要在每个状态定义一个信息过滤器,以过滤出需要在状态之间传递的信息。
参考
- CNCF Serverless Whitepaper v1.0
- CNCF Serverless WG
- An I&O Leader’s Guide to Serverless Computing
- Guide to Serverless Technologies


