
- 1mysql编写函数_mysql函数编写
- 2chatgpt赋能python:Python虚拟环境virtualenv_virtualenv 退出
- 3Web3系列之1-MERLIN链Airdrop[BianXian]_web3撸空投
- 42024软件测试自动化面试题(含答案)_下单测试
- 5记录一次壮烈牺牲的阿里巴巴面试
- 62022起重机司机(限门式起重机)试题及模拟考试_关于门式、桥式起重机,下列说法正确的是()。【多选】 a.起重机路基和轨道的铺设应
- 7Java多线程并发编程技术详解_java多线程并发代码
- 8java面试题_2019 最新 200 道 Java 面试题
- 9硕果累累 IBM与高校在人工智能落地方面的那些事
- 10python马尔可夫链_3阶马尔可夫链 自然语言处理python
尚硅谷云原生学习笔记(76~143集)_尚硅谷 云原生 网盘
赞
踩
笔记列表:
目录
- 76、为什么用kubernetes
- 77、kubernetes简介
- 78、kubernetes架构原理
- 79、集群交互原理
- 80、k8s—安装的所有前置环境
- 81、k8s-每个节点安装kubeadm、kubelet、kubectl
- 82、k8s-每个节点下载基本镜像
- 83、k8s-master节点准备就绪
- 84、k8s-其他工作节点准备就绪
- 85、k8s-集群创建完成
- 86、k8s-helloworld部署一个应用
- 87、k8s-集群又一次安装
- 88、k8s-集群架构复习
- 89、k8s-创建一次部署,可以自愈
- 90、k8s-了解Pod,自愈
- 91、k8s-需要记住会用的一些命令
- 92、k8s-手动扩缩容操作
- 93、k8s-service将Pod封装一个统一服务
- 94、k8s-滚动升级
- 95、k8s-对象描述文件
- 96、k8s-安装官方dashboard
- 97、k8s-集群中的资源会达到最终一致
- 98、k8s-对象描述文件
- 99、k8s-名称空间
- 100、k8s-如何编写一个k8s的资源描述文件
- 101、k8s-自己该如何往下摸索
- 102、k8s-核心组件的配置文件位置以及所有命令
- 103、k8s-命令自动补全功能
- 104、k8s-容器镜像使用秘钥从私有仓库下载
- 105、k8s-容器启动命令、环境变量等
- 106、k8s-containers的写法就是对应docker run的写法
- 107、k8s-containers的生命周期钩子
- 108、k8s-containers-容器探针是什么?
- 109、k8s-如何接下来学习k8s
- 110、k8s-小总结
- 111、k8s工作负载-什么是工作负载
- 112、k8s工作负载-Pod的概念
- 113、k8s工作负载-Pod的多容器协同
- 114、k8s工作负载-Pod的初始化容器
- 115、k8s工作负载-Pod的生命周期
- 116、k8s工作负载-临时容器的使用简介
- 117、k8s工作负载-静态Pod
- 118、k8s工作负载-Pod的探针
- 119、k8s工作负载-XXX
- 120、k8s工作负载-Deployment-简单编写
- 121、k8s工作负载-Deployment-滚动更新原理01
- 122、k8s工作负载-Deployment-滚动更新暂停与恢复等
- 123、k8s工作负载-Deployment-按比例缩放的滚动更新
- 124、k8s工作负载-Deployment安装metrics-server
- 125、k8s工作负载-Deployment-HPA(自动动态扩缩容)
- 126、k8s工作负载-Deployment-灰度发布原理
- 127、k8s工作负载-Deployment-金丝雀的案例
- 128、k8s工作负载-Deployment-最后问题解决
- 129、k8s工作负载-Deployment-Deployment总结
- 130、k8s工作负载-RC、RS的区别
- 131、k8s工作负载-DamonSet-让每个节点都部署一个指定Pod
- 132、k8s工作负载-StatefulSet-什么是有状态应用
- 133、k8s工作负载-StatefulSet-示例
- 134、k8s工作负载-StatefulSet-分区更新机制
- 135、k8s工作负载-Job
- 136、k8s工作负载-定时任务
- 137、k8s工作负载-垃圾回收简单了解
- 138、k8s工作负载-Service、Pod端口
- 139、k8s网络-ClusterIP与NodePort类型的Service
- 140、k8s网络-Service与EndPoint原理
- 141、k8s网络-Service所有字段解析_1
- 142、k8s网络-Service的会话保持技术_1
- 143、k8s网络-Service中Pod指定自己主机名
76、为什么用kubernetes
77、kubernetes简介
77.1、kubernetes背景
77.1.2、部署方式的变迁
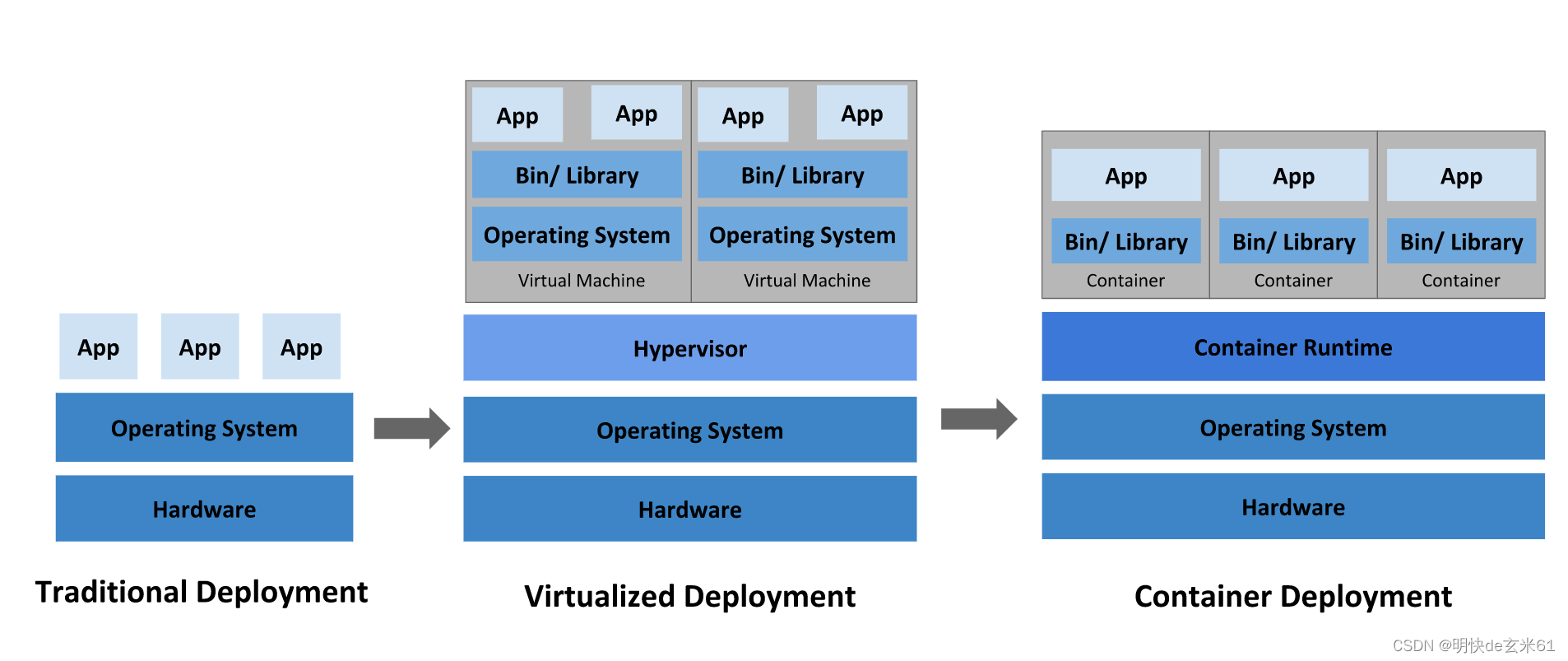
- 传统部署时代:
- 在物理服务器上运行应用程序
- 无法为应用程序定义资源边界,一旦某个应用程序出现问题,将会导致该虚拟机上的全部应用程序都会受到影响,所以应用程序的资源隔离性不是很好
- 导致资源分配出现问题,毕竟没做限制就无法控制
- 虚拟化部署时代
- 需要安装虚拟机,安装不方便,伸缩性不好
- 虚拟机运行需要占用内存和存储空间
- 容器部署时代
- 应用程序伸缩扩容很方便
- 应用程序的部署、迁移都很方便
- 可以很好控制容器对内存和存储空间的占用,并且能起到很好的物理隔离作用
77.1.3、容器化优势
- 敏捷性:敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 及时性:持续开发、集成和部署,通过快速简单的回滚(由于镜像不可变性),支持可靠且频繁的 容器镜像构建和部署。
- 解耦性:关注开发与运维的分离,在构建/发布时创建应用程序容器镜像,而不是在部署时。 从而将应用程序与基础架构分离。
- 可观测性:可观察性不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨平台:跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
- 可移植:跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 简易性:以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 大分布式:松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 隔离性:资源隔离:可预测的应用程序性能。
- 高效性:资源利用:高效率和高密度
77.1.4、为什么用 Kubernetes
简单来说,kubernetes就是容器管家
容器是打包和运行应用程序的好方式。在生产环境中,你需要管理运行应用程序的容器,并确保不会停机。 例如,如果一个容器发生故障,则需要启动另一个容器。如果系统处理此行为,会不会更容易?
这就是 Kubernetes 来解决这些问题的方法! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。linux之上的一个服务编排框架;
Kubernetes 会满足你的扩展要求、故障转移、部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary 部署。
Kubernetes 为你提供:
- 服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。 - 存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。 - 自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态 更改为期望状态。例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。 - 自动完成装箱计算
Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。 - 自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。 - 密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥
77.1.5、市场份额
77.1.5.1、市场份额
77.1.5.2、服务编排
77.2、kubernetes简介
77.2.1、kubernetes是什么
Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态系统。Kubernetes 的服务、支持和工具广泛可用。
名称 Kubernetes 源于希腊语,意为“舵手”或“飞行员”。Google 在 2014 年开源了 Kubernetes 项目。 Kubernetes 建立在 Google 在大规模运行生产工作负载方面拥有十几年的经验 的基础上,结合了社区中最好的想法和实践。
77.2.2、kubernetes不是什么
-
Kubernetes 不是传统的、包罗万象的 PaaS(平台即服务)系统。
-
Kubernetes 在容器级别,而不是在硬件级别运行
-
它提供了 PaaS 产品共有的一些普遍适用的功能, 例如部署、扩展、负载均衡、日志记录和监视。
-
但是,Kubernetes 不是单体系统,默认解决方案都是可选和可插拔的。 Kubernetes 提供了构建开发人员平台的基础,但是在重要的地方保留了用户的选择和灵活性。
-
不限制支持的应用程序类型。 Kubernetes 旨在支持极其多种多样的工作负载,包括无状态、有状态和数据处理工作负载。 如果应用程序可以在容器中运行,那么它应该可以在 Kubernetes 上很好地运行。
-
不部署源代码,也不构建你的应用程序。 持续集成(CI)、交付和部署(CI/CD)工作流取决于组织的文化和偏好以及技术要求。
-
不提供应用程序级别的服务作为内置服务,例如中间件(例如,消息中间件)、 数据处理框架(例如,Spark)、数据库(例如,mysql)、缓存、集群存储系统 (例如,Ceph)。这样的组件可以在 Kubernetes 上运行,并且/或者可以由运行在 Kubernetes 上的应用程序通过可移植机制(例如, 开放服务代理)来访问。
-
不要求日志记录、监视或警报解决方案。 它提供了一些集成作为概念证明,并提供了收集和导出指标的机制。
-
不提供或不要求配置语言/系统(例如 jsonnet),它提供了声明性 API, 该声明性 API 可以由任意形式的声明性规范所构成。RESTful;写yaml文件
-
不提供也不采用任何全面的机器配置、维护、管理或自我修复系统。
-
此外,Kubernetes 不仅仅是一个编排系统,实际上它消除了编排的需要。 编排的技术定义是执行已定义的工作流程:首先执行 A,然后执行 B,再执行 C。 相比之下,Kubernetes 包含一组独立的、可组合的控制过程, 这些过程连续地将当前状态驱动到所提供的所需状态。 如何从 A 到 C 的方式无关紧要,也不需要集中控制,这使得系统更易于使用 且功能更强大、系统更健壮、更为弹性和可扩展。
78、kubernetes架构原理
79、集群交互原理
79.1、常见集群方式
- 主从模式
- 主从同步
- 主从复制
- 主管理从
- 分片模式(数据集群):
- 所有节点存储内容都一样
- 每个节点都只存储一部分内容,全部加起来就是全部内容
我们的k8s集群是主管理从的方式,将会存在一个或者多个master节点,然后管理多个node节点
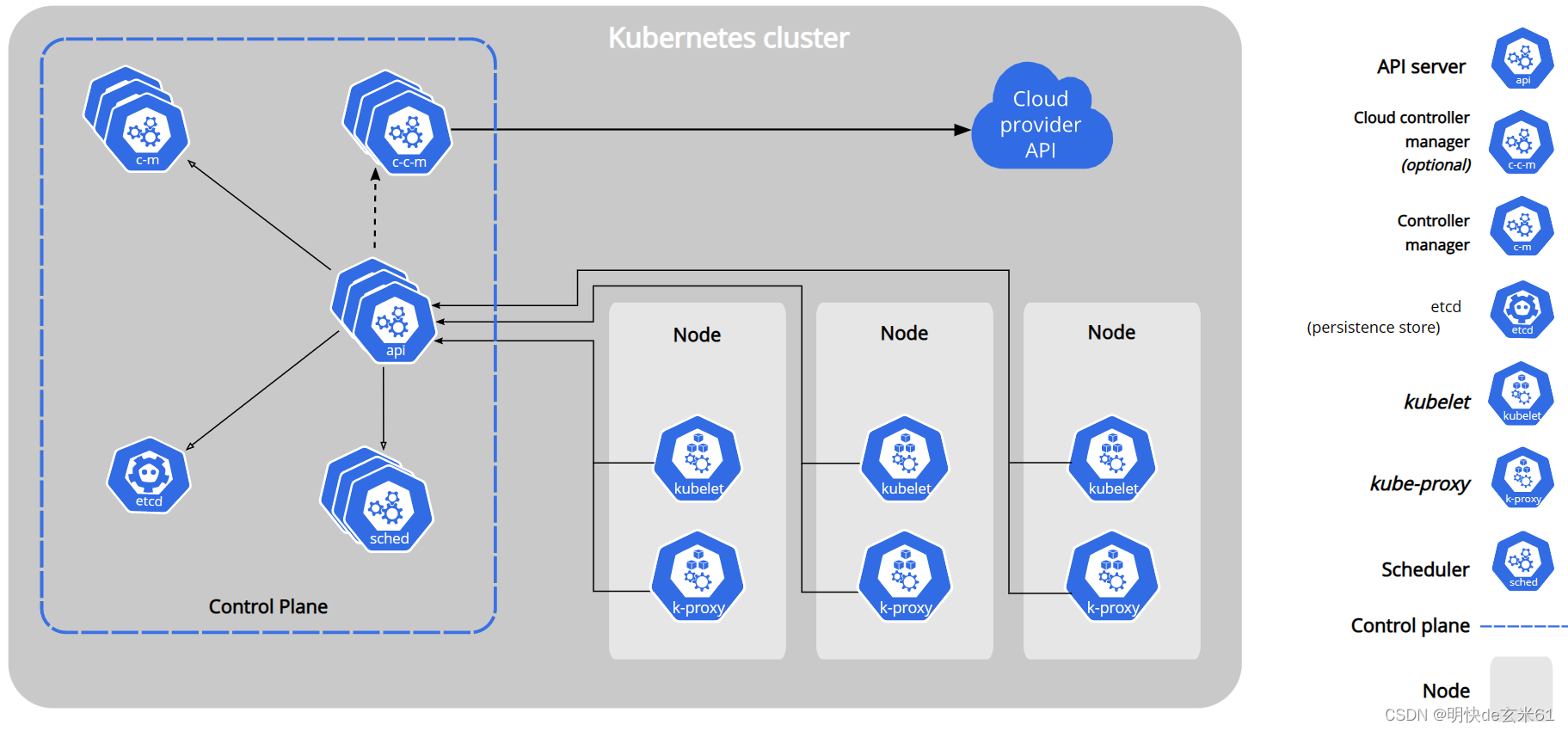
79.2、k8s集群结构
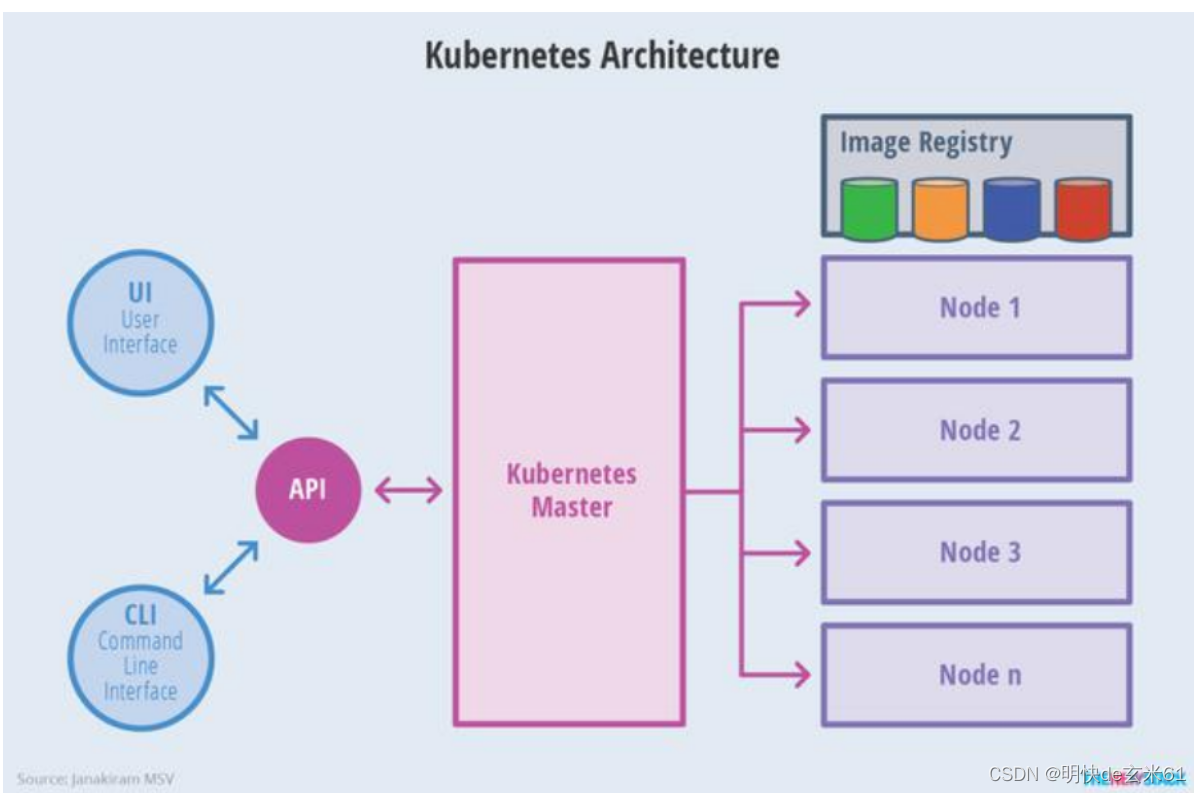
79.3、工作原理
解释图1:
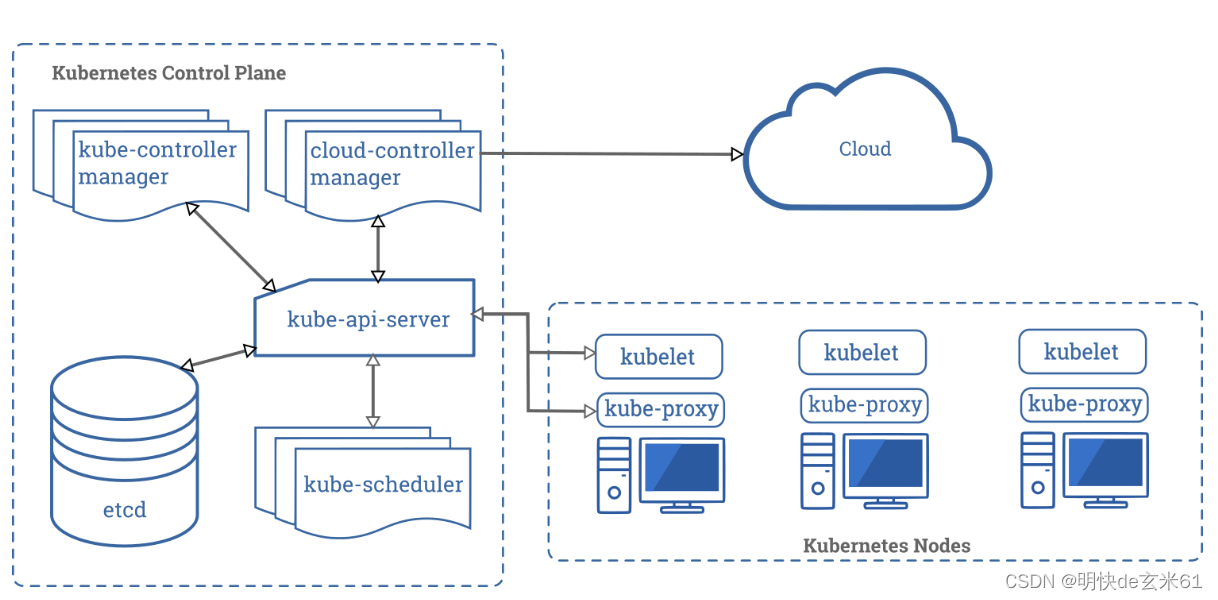
解释图2:
master和node节点简介:
master节点(Control Plane【控制面板】):master节点控制整个集群
master节点上有一些核心组件:
- Controller Manager:控制管理器
- etcd:键值数据库(redis)【记账本,记事本】
- scheduler:调度器
- api server:api网关(所有的控制都需要通过api-server)
node节点(worker工作节点):
- kubelet(监工):每一个node节点上必须安装的组件。
- kube-proxy:代理。代理网络
如何部署一个应用?
程序员:调用CLI告诉master,我们现在要部署一个tomcat应用
- 程序员的所有调用都先去master节点的网关api-server。这是matser的唯一入口(mvc模式中的c层)
- 收到的请求先交给master的api-server。由api-server交给controller-mannager进行控制
- controller-mannager 进行 应用部署
- controller-mannager 会生成一次部署信息。 tomcat --image:tomcat6 --port 8080 ,真正不部署应用
- 部署信息被记录在etcd中
- scheduler调度器从etcd数据库中,拿到要部署的应用,开始调度。看哪个节点合适,
- scheduler把算出来的调度信息再放到etcd中
- 每一个node节点的监控kubelet,随时和master保持联系的(给api-server发送请求不断获取最新数据),所有节点的kubelet就会从master
- 假设node2的kubelet最终收到了命令,要部署。
- kubelet就自己run一个应用在当前机器上,随时给master汇报当前应用的状态信息,分配ip
- node和master是通过master的api-server联系的
- 每一个机器上的kube-proxy能知道集群的所有网络。只要node访问别人或者别人访问node,node上的kube-proxy网络代理自动计算进行流量转发
79.4、原理分解
79.4.1、主节点master
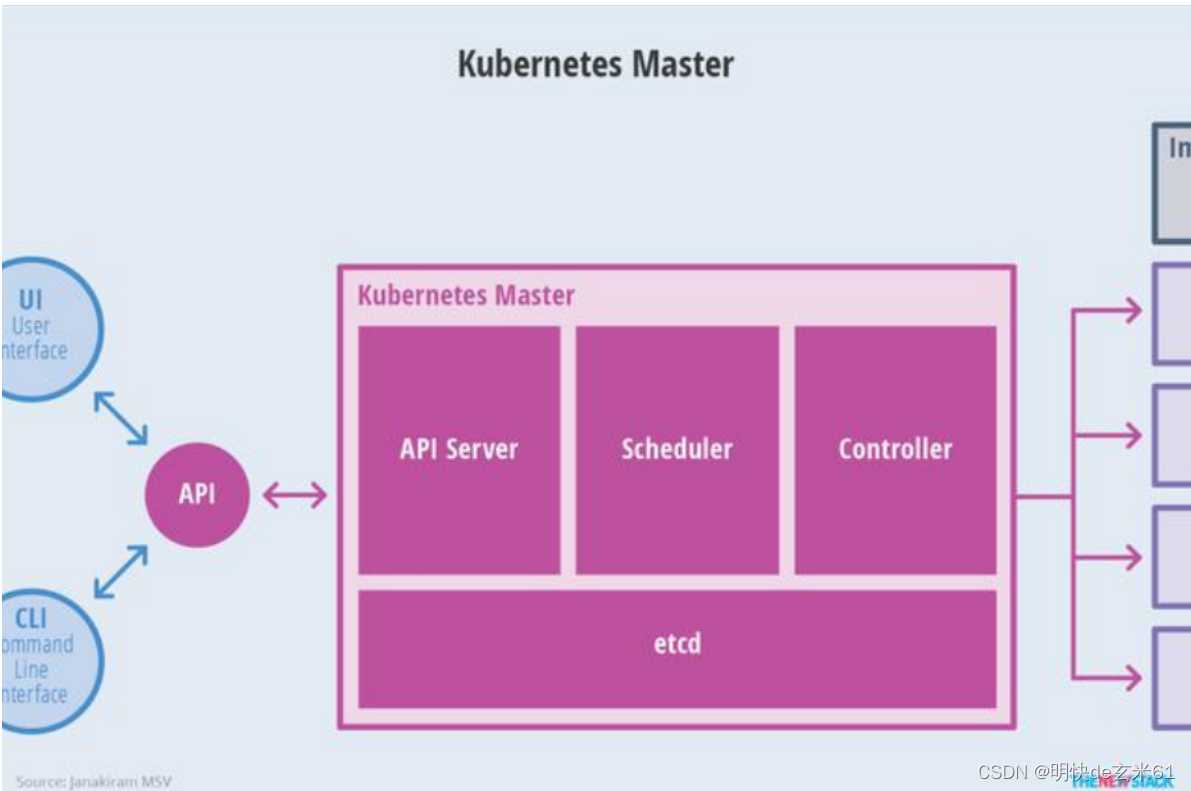
- kube-apiserver
- scheduler
- controller manager
- etcd
- kubelet+kubeproxy每一个节点的必备(包括master节点)+docker(容器运行时环境)
79.4.2、工作节点node
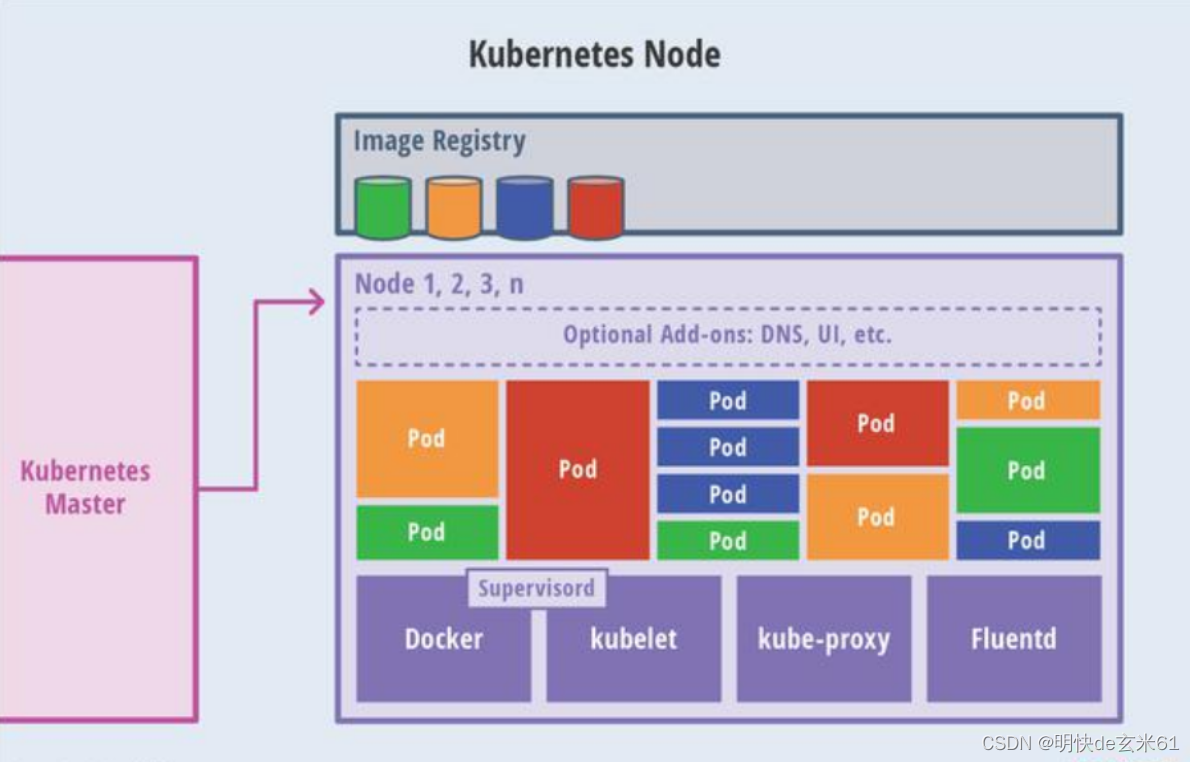
- Pod:
- docker run 启动的是一个container(容器),容器是docker的基本单位,一个应用是一个容器
- kubelet run 启动的一个应用称为一个Pod;其中Pod是k8s的基本单位,并且Pod是容器的一个再封装,一个pod里面可以包含多个容器
- k8s的基本单位是pod,而不是容器的原因:容器是docker的基本单位,k8s如果也以容器为基本单位,那就需要受到docker的制约,所以pod相当于是将k8s和docker隔离开始,不让k8s受到docker的束缚
- Kubelet:监工,负责和master的api-server交互,以及当前机器应用的启停等,在master机器就是master的小助手。每一台机器真正干活的都是这个 Kubelet
- Kube-proxy:网络代理,每一个node可以连接到其他机器,全归功于kube-proxy
79.5、组件交互原理
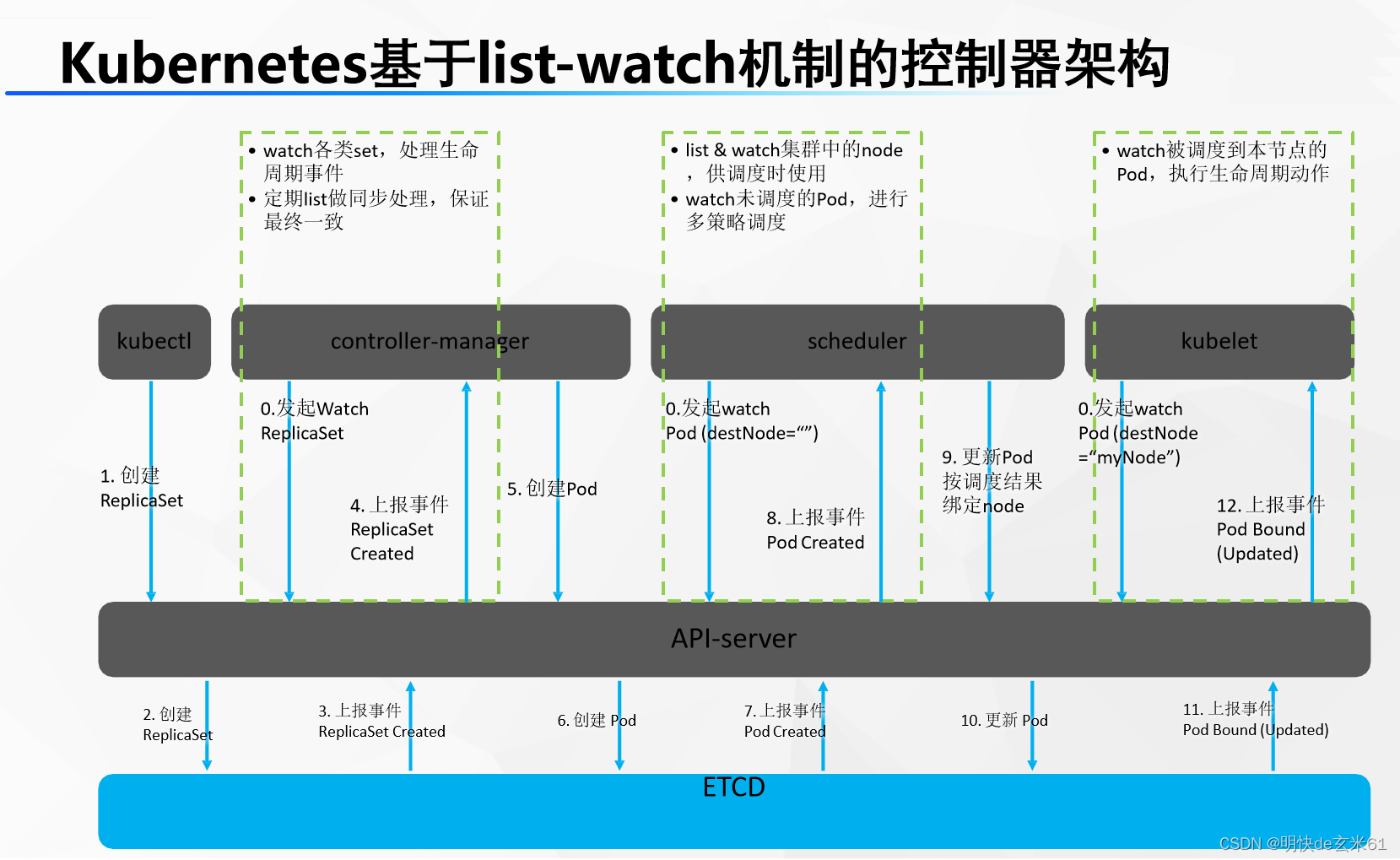
想让k8s部署一个tomcat?
0、开机默认所有节点的kubelet、master节点的scheduler(调度器)、controller-manager(控制管理器)一直监听master的api-server发来的事件变化(for ::)
1、程序员使用命令行工具: kubectl ; kubectl create deploy tomcat --image=tomcat8(告诉master让集群使用tomcat8镜像,部署一个tomcat应用)
2、kubectl命令行内容发给api-server,api-server保存此次创建信息到etcd
3、etcd给api-server上报事件,说刚才有人给我里面保存一个信息。(部署Tomcat[deploy])
4、controller-manager监听到api-server的事件,是 (部署Tomcat[deploy])
5、controller-manager 处理这个 (部署Tomcat[deploy])的事件。controller-manager会生成Pod的部署信息【pod信息】
6、controller-manager 把Pod的信息交给api-server,再保存到etcd
7、etcd上报事件【pod信息】给api-server。
8、scheduler专门监听 【pod信息】 ,拿到 【pod信息】的内容,计算,看哪个节点合适部署这个Pod【pod调度过后的信息(node: node-02)】,
9、scheduler把 【pod调度过后的信息(node: node-02)】交给api-server保存给etcd
10、etcd上报事件【pod调度过后的信息(node: node-02)】,给api-server
11、其他节点的kubelet专门监听 【pod调度过后的信息(node: node-02)】 事件,集群所有节点kubelet从api-server就拿到了 【pod调度过后的信息(node: node-02)】 事件
12、每个节点的kubelet判断是否属于自己的事情;node-02的kubelet发现是他的事情
13、node-02的kubelet启动这个pod。汇报给master当前启动好的所有信息
80、k8s—安装的所有前置环境
81、k8s-每个节点安装kubeadm、kubelet、kubectl
82、k8s-每个节点下载基本镜像
83、k8s-master节点准备就绪
84、k8s-其他工作节点准备就绪
85、k8s-集群创建完成
1、准备虚拟机
2台虚拟机即可,一台做master节点,另外一台做worker节点不会安装的可以看这个:在VMvare中安装CentOS,建议安装centos7
安装之后需要配置静态ip和语言,记得先切换root用户(CentOS如何切换超级用户/root用户),然后根据以下文章配置即可:
2、安装前置环境(注意:所有虚拟机都执行)
2.1、基础环境
修改虚拟机名称(注意:每个虚拟机单独执行,不能是localhost,每个虚拟机的主机名称必须不同,比如可以是k8s-01、k8s-02……):
# 例如:hostnamectl set-hostname k8s-01
hostnamectl set-hostname 主机名称
- 1
- 2
修改其他配置,直接复制执行即可(注意:在所有虚拟机上都执行相同指令即可)
######################################################################### #关闭防火墙: 如果是云服务器,需要设置安全组策略放行端口 # https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/#check-required-ports systemctl stop firewalld systemctl disable firewalld # 查看修改结果 hostnamectl status # 设置 hostname 解析 echo "127.0.0.1 $(hostname)" >> /etc/hosts #关闭 selinux: sed -i 's/enforcing/disabled/' /etc/selinux/config setenforce 0 #关闭 swap: swapoff -a sed -ri 's/.*swap.*/#&/' /etc/fstab #允许 iptables 检查桥接流量 #https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/#%E5%85%81%E8%AE%B8-iptables-%E6%A3%80%E6%9F%A5%E6%A1%A5%E6%8E%A5%E6%B5%81%E9%87%8F ## 开启br_netfilter ## sudo modprobe br_netfilter ## 确认下 ## lsmod | grep br_netfilter ## 修改配置 #####这里用这个,不要用课堂上的配置。。。。。。。。。 #将桥接的 IPv4 流量传递到 iptables 的链: # 修改 /etc/sysctl.conf # 如果有配置,则修改 sed -i "s#^net.ipv4.ip_forward.*#net.ipv4.ip_forward=1#g" /etc/sysctl.conf sed -i "s#^net.bridge.bridge-nf-call-ip6tables.*#net.bridge.bridge-nf-call-ip6tables=1#g" /etc/sysctl.conf sed -i "s#^net.bridge.bridge-nf-call-iptables.*#net.bridge.bridge-nf-call-iptables=1#g" /etc/sysctl.conf sed -i "s#^net.ipv6.conf.all.disable_ipv6.*#net.ipv6.conf.all.disable_ipv6=1#g" /etc/sysctl.conf sed -i "s#^net.ipv6.conf.default.disable_ipv6.*#net.ipv6.conf.default.disable_ipv6=1#g" /etc/sysctl.conf sed -i "s#^net.ipv6.conf.lo.disable_ipv6.*#net.ipv6.conf.lo.disable_ipv6=1#g" /etc/sysctl.conf sed -i "s#^net.ipv6.conf.all.forwarding.*#net.ipv6.conf.all.forwarding=1#g" /etc/sysctl.conf # 可能没有,追加 echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf echo "net.bridge.bridge-nf-call-ip6tables = 1" >> /etc/sysctl.conf echo "net.bridge.bridge-nf-call-iptables = 1" >> /etc/sysctl.conf echo "net.ipv6.conf.all.disable_ipv6 = 1" >> /etc/sysctl.conf echo "net.ipv6.conf.default.disable_ipv6 = 1" >> /etc/sysctl.conf echo "net.ipv6.conf.lo.disable_ipv6 = 1" >> /etc/sysctl.conf echo "net.ipv6.conf.all.forwarding = 1" >> /etc/sysctl.conf # 执行命令以应用 sysctl -p

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
2.2、docker环境(在所有虚拟机上都执行下列指令即可)
sudo yum remove docker* sudo yum install -y yum-utils #配置docker yum 源 sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo #安装docker 19.03.9 yum install -y docker-ce-3:19.03.9-3.el7.x86_64 docker-ce-cli-3:19.03.9-3.el7.x86_64 containerd.io # 首先启动docker,然后让docker随虚拟机一起启动 systemctl start docker systemctl enable docker #配置加速,使用网易镜像加速器 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["http://hub-mirror.c.163.com"] } EOF sudo systemctl daemon-reload sudo systemctl restart docker
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.3、安装k8s核心组件(在所有虚拟机上都执行相同指令即可)
# 配置K8S的yum源 cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF # 卸载旧版本 yum remove -y kubelet kubeadm kubectl # 查看可以安装的版本 yum list kubelet --showduplicates | sort -r # 安装kubelet、kubeadm、kubectl 指定版本 yum install -y kubelet-1.21.0 kubeadm-1.21.0 kubectl-1.21.0 # 开机启动kubelet systemctl enable kubelet && systemctl start kubelet
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2.4、导入k8s所需镜像
直接使用docker load -i 镜像tar包名称即可导入,镜像在下面
链接:https://pan.baidu.com/s/17LEprW3CeEAQYC4Dn_Klxg?pwd=s5bt
提取码:s5bt
说明:
这些镜像是atguigu雷丰阳老师传到阿里云上的,我直接放到百度网盘中,大家可以直接导入即可
2.5、导入calico镜像
因为我们所用的k8s版本是1.21.0,根据https://projectcalico.docs.tigera.io/archive/v3.21/getting-started/kubernetes/requirements可以看到对应的calico版本是v3.21,截图在下面
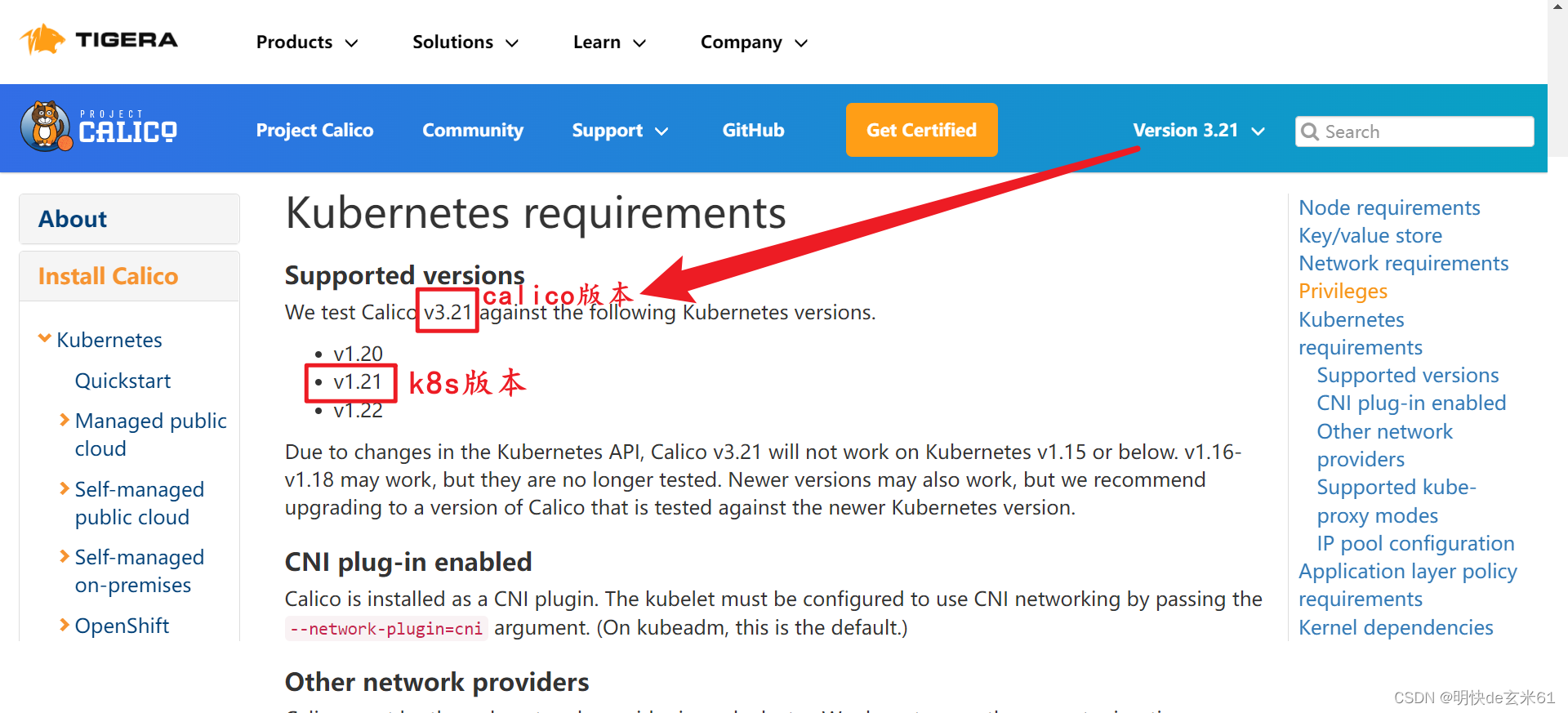
直接使用docker load -i 镜像tar包名称即可导入,镜像在下面
链接:https://pan.baidu.com/s/122EoickH6jsSMJ8ECJ3P5g?pwd=vv8n
提取码:vv8n
3、初始化master节点(注意:只能在master节点虚拟机上执行)
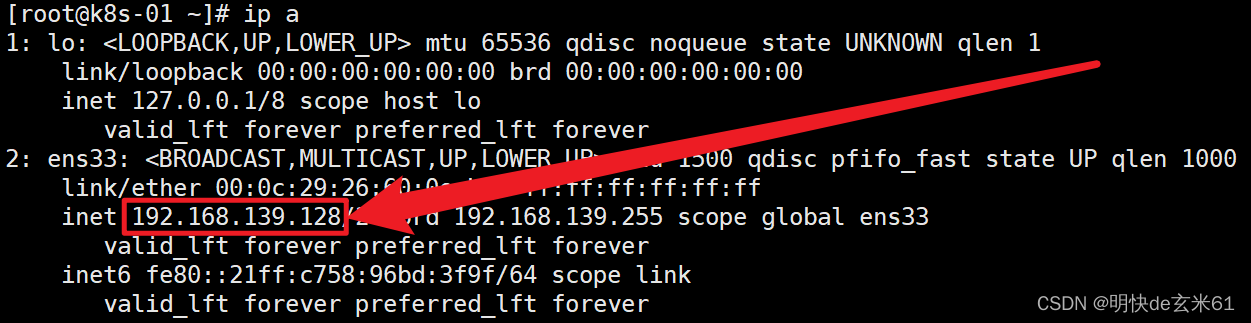
3.1、确定master节点ip
执行ip a就可以找到了,如下:
3.2、找到合适的service地址区间、pod地址区间
service地址区间、pod地址区间和master节点的ip只要不重复就可以了,由于我的是192.168.139.128,所以我选择的两个地址区间如下:
service地址区间:10.98.0.0/16(注意:16代表前面XX.XX是固定的)
pod地址区间:10.99.0.0/16(注意:16代表前面XX.XX是固定的)
3.3、执行kubeadm init操作
注意:将master主节点id、service地址区间、pod地址区间改成你自己主节点的,查找方法在上面
kubeadm init \
--apiserver-advertise-address=master主节点id \
--image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \
--kubernetes-version v1.21.0 \
--service-cidr=service地址区间 \
--pod-network-cidr=pod地址区间
- 1
- 2
- 3
- 4
- 5
- 6
比如我的就是
kubeadm init \
--apiserver-advertise-address=192.168.139.128 \
--image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \
--kubernetes-version v1.21.0 \
--service-cidr=10.98.0.0/16 \
--pod-network-cidr=10.99.0.0/16
- 1
- 2
- 3
- 4
- 5
- 6
说明:
指令中的registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images对应k8s相关镜像的前缀,这些镜像来自于atguigu雷丰阳老师的阿里云镜像仓库,我直接把它放到百度网盘中了,大家可以直接下载导入即可
3.4、根据初始化结果来执行操作
下面是我的初始化结果:
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.139.129:6443 --token gjkehd.e68y3u6csud6mz8y \ --discovery-token-ca-cert-hash sha256:0425228dfd80644425f3a1cbd5cb4a8a610f7e45b2d3d3b2f7f6ccddf60a98d7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3.4.1、复制相关文件夹
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
- 1
- 2
- 3
3.4.2、导出环境变量
export KUBECONFIG=/etc/kubernetes/admin.conf
- 1
3.4.3、导入calico.yaml
链接:https://pan.baidu.com/s/1EWJNtWQuekb0LYXernjWew?pwd=70ku
提取码:70ku
说明:
虽然我已经给大家提供了calico.yaml文件,但是还想和大家说一下该文件的来源,首先在2.5、导入calico镜像中可以知道,我们本次使用的calico版本是v3.21,那么可以在linux上使用wget https://docs.projectcalico.org/v3.21/manifests/calico.yaml --no-check-certificate指令下载(注意链接中的版本号是v3.21),其中--no-check-certificate代表非安全方式下载,必须这样操作,不然无法下载
另外对于calico.yaml来说,我们将所有image的值前面的docker.io/去掉了,毕竟我们已经将calico镜像导入了,就不用去docker.io下载镜像了
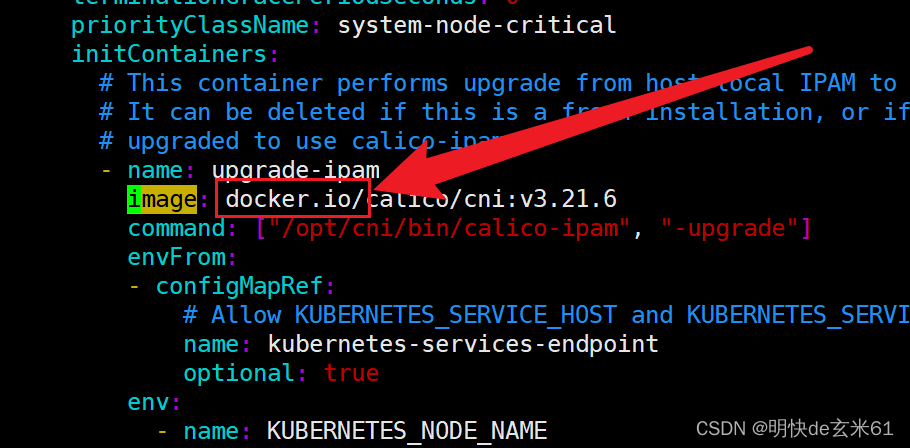
下一个需要修改的位置就是3.4.4、修改calico.yaml里面的值了,这个直接跟着下面修改即可
3.4.4、修改calico.yaml(注意:必须修改)
根据ifconfig找到我们所用ip前面的内容,比如我的是ens33,如下:
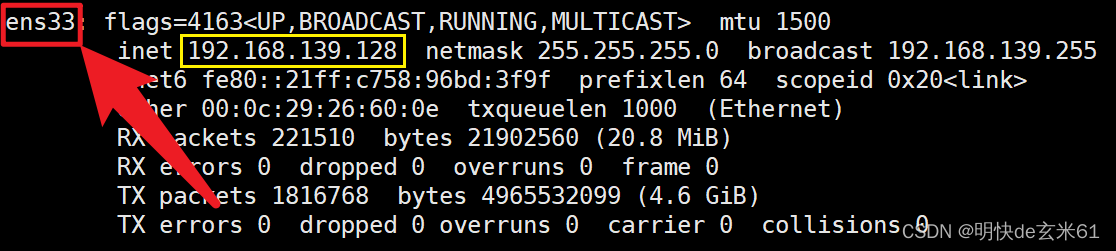
根据你ip前面的结果来修改文件中interface的值,如下:
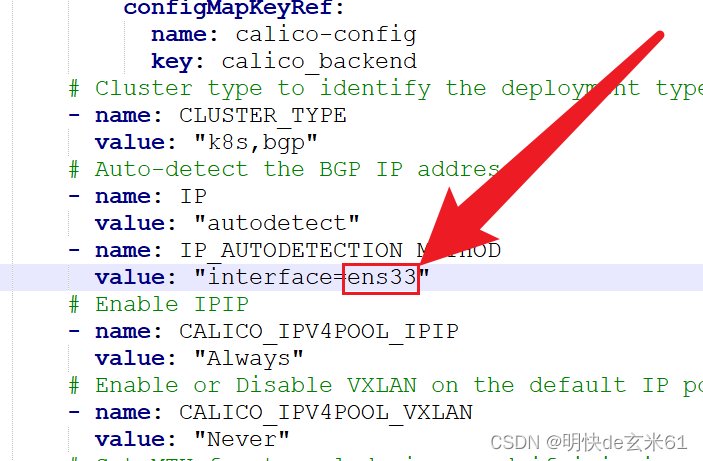
其实下面这些指令都是我自己添加的,原来的calico.yaml中是没有的,添加的原因是执行calico.yaml报错了,然后根据这篇calico/node is not ready来添加的,添加之后在执行yaml文件,然后calico的所有容器都运行正常了
- name: IP_AUTODETECTION_METHOD
value: "interface=ens33"
- 1
- 2
3.4.5、执行calico.yaml
kubectl apply -f calico.yaml
- 1
4、初始化worker节点(注意:只能在所有worker节点虚拟机上执行)
找到3.4、根据初始化结果来执行操作的master主节点中的最后结果,记得用你自己的初始化结果哈,然后在所有worker节点执行即可

如果命令中的token失效,可以在主节点虚拟机中通过kubeadm token create --print-join-command得到最新的指令,然后在所有worker节点的虚拟机中执行即可
5、设置ipvs模式(推荐执行,但是不执行也没影响;注意:只能在master节点虚拟机上执行)
5.1、设置ipvs模式
默认是iptables模式,但是这种模式在大集群中会占用很多空间,所以建议使用ipvs模式
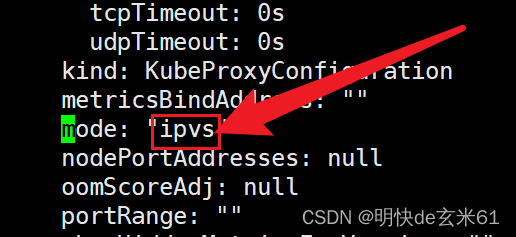
首先执行kubectl edit cm kube-proxy -n kube-system,然后输入/mode,将mode的值设置成ipvs,保存退出即可,如下:
5.2、找到kube-proxy的pod
kubectl get pod -A|grep kube-proxy
- 1
例如pod如下:

5.3、删除kube-proxy的pod
kubectl delete pod pod1名称 pod2名称…… -n kube-system
- 1
根据上面的命令,可以找到kube-proxy的pod名称,比如我上面的就是kube-proxy-cxh25、kube-proxy-ws4nn,那么删除命令就是:kubectl delete pod kube-proxy-cxh25 kube-proxy-ws4nn -n kube-system,由于k8s拥有自愈能力,所以proxy删除之后就会重新拉起一个pod
5.4、查看pod启动情况
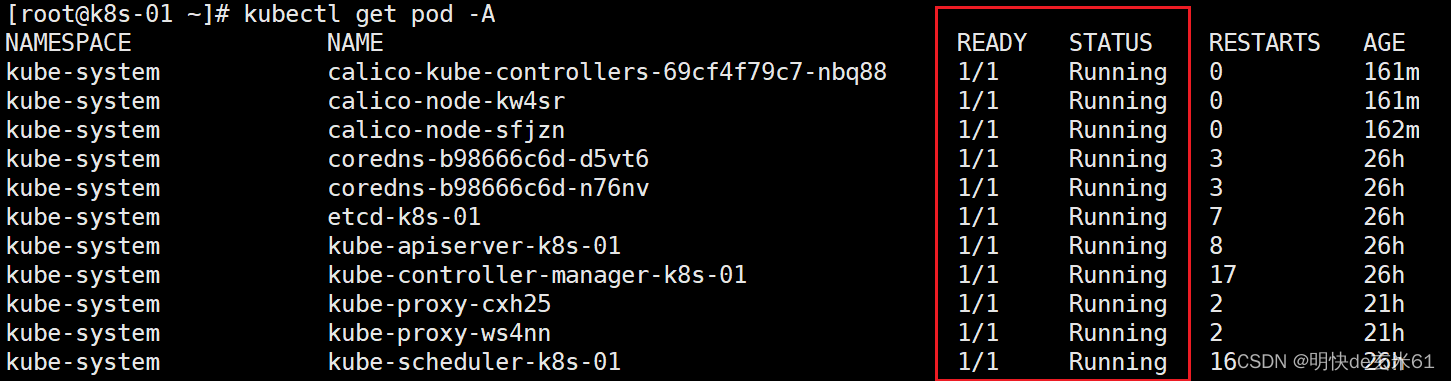
使用kubectl get pod -A命令即可,我们只看NAMESPACE下面的kube-system,只要看到所有STATUS都是Running,并且READY都是1/1就可以了,如果pod一直不满足要求,那就可以使用kubectl describe pod pod名称 -n kube-system查看一下pod执行进度,如果把握不准,可以使用reboot命令对所有虚拟机执行重启操作,最终结果是下面这样就可以了
6、部署k8s-dashboard(注意:只能在master节点虚拟机上执行)
6.1、下载并执行recommended.yaml
6.1.1、下载recommended.yaml
链接:https://pan.baidu.com/s/1rNnCUa7B7GaX2SFjiPgZTQ?pwd=z2zp
提取码:z2zp
说明:
该yaml来自于https://github.com/kubernetes/dashboard中的该位置:

直接通过wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.2.0/aio/deploy/recommended.yaml下载该yaml即可
由于我们通过浏览器直接访问kubernetes dashboard,所以还需要在yaml文件中添加type:NodePort,如下:
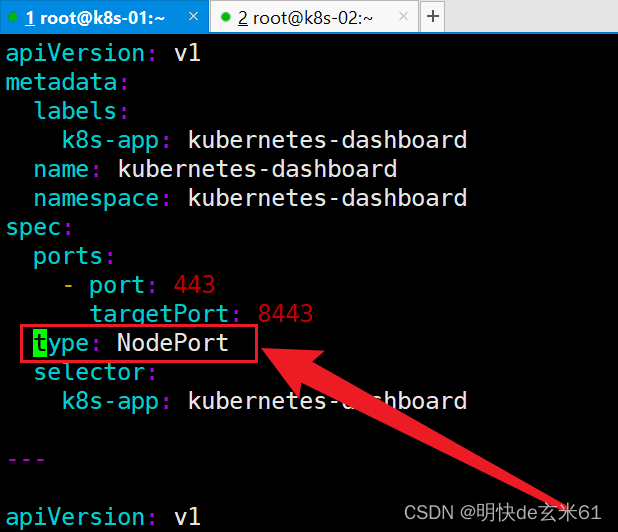
然后直接执行kubectl apply -f recommended.yaml即可
6.1.2、执行recommended.yaml
kubectl apply -f recommended.yaml
- 1
6.2、下载并执行dashboard-admin.yaml
6.2.1、下载dashboard-admin.yaml
链接:https://pan.baidu.com/s/14upSiYdrZaw5EVFWRDNswg?pwd=co3g
提取码:co3g
说明:
该yaml来自于https://github.com/kubernetes/dashboard中的该位置:

进入Access Control链接之后,找到下列位置即可,复制到dashboard-admin.yaml文件中即可
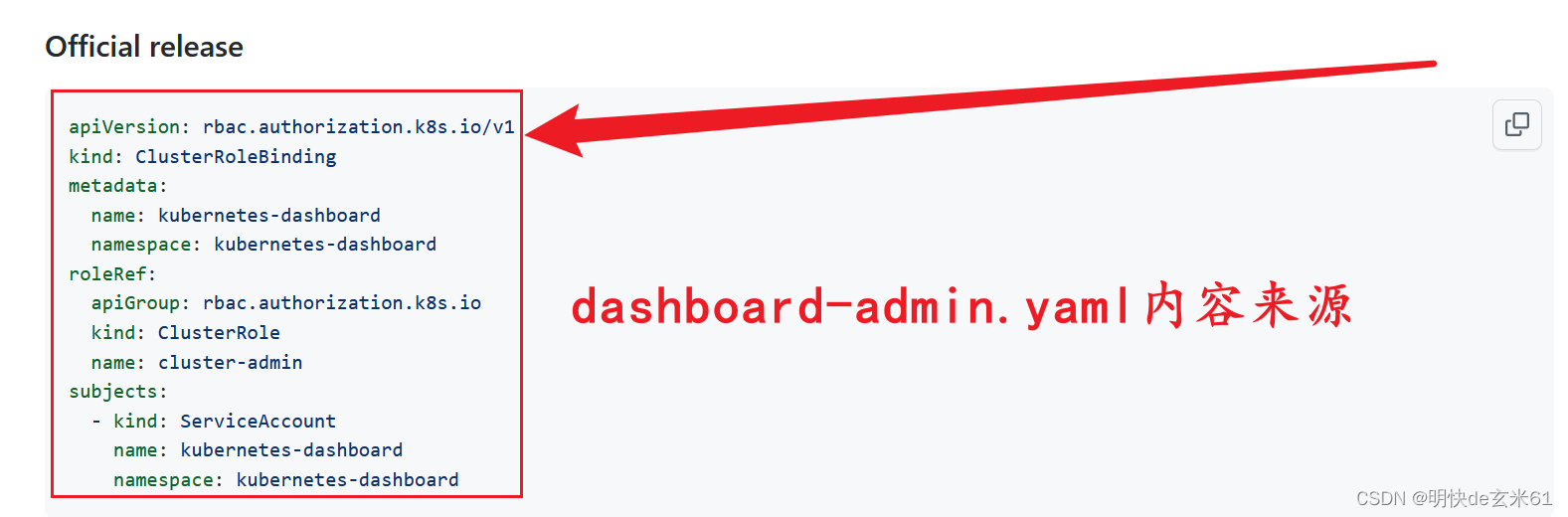
6.2.2、执行dashboard-admin.yaml
# 删除原有用户,避免启动报错
kubectl delete -f dashboard-admin.yaml
# 添加新用户
kubectl apply -f dashboard-admin.yaml
- 1
- 2
- 3
- 4
- 5
6.3、找到k8s-dashboard访问端口
使用kubectl get all -A命令即可,找到:

6.4、访问k8s-dashboard
直接在浏览器上根据你的虚拟机ip和上述端口访问即可(注意:协议是https),如下:
我们需要获取token,指令如下:
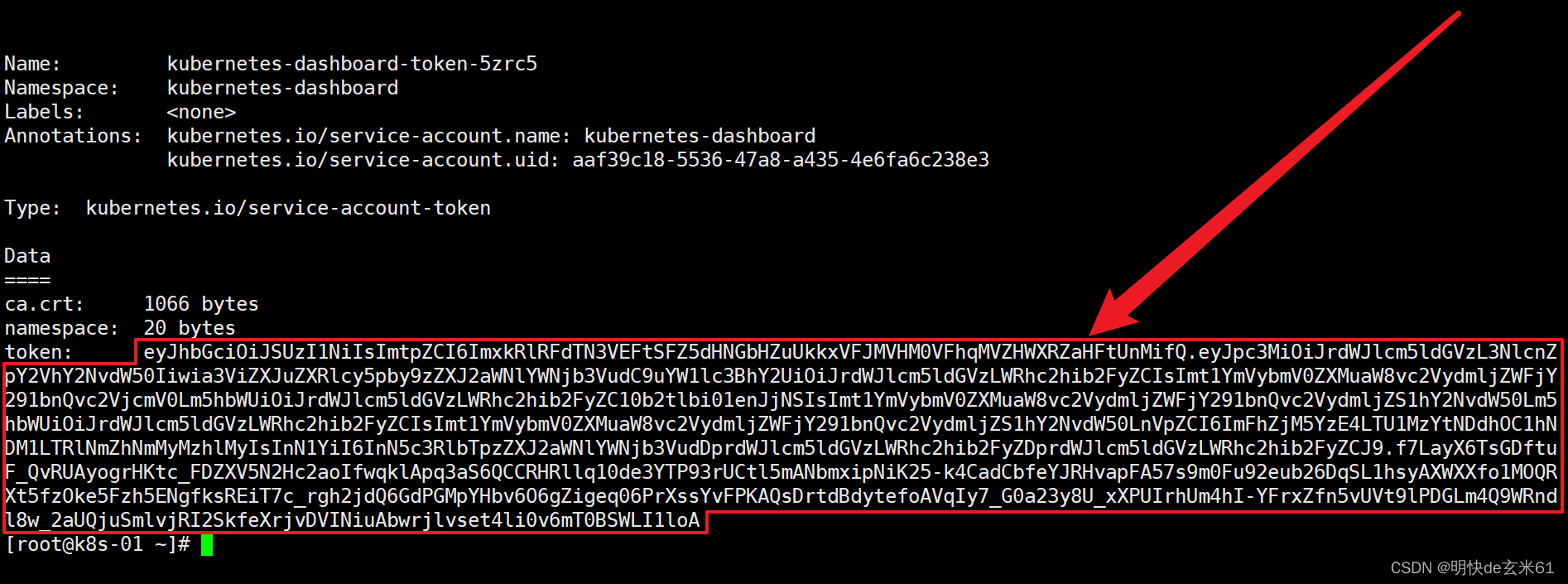
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
- 1
复制红框框中的内容输入到文本框中,然后点击登录按钮即可,如下:
然后k8s-dashboard首页如下:
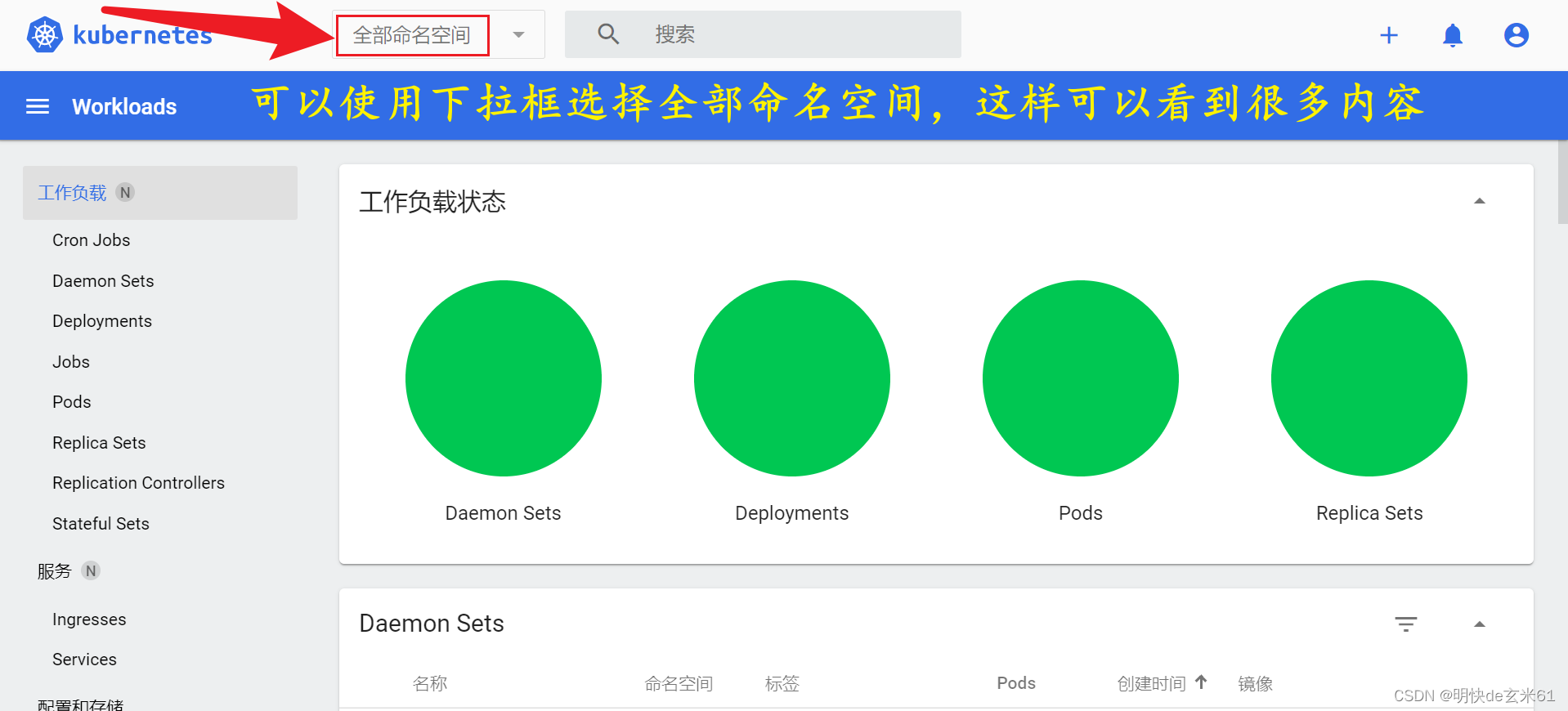
7、添加kubectl命令自动补全功能
先执行:
kubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null
- 1
在执行:
source /usr/share/bash-completion/bash_completion
- 1
我们在执行kubectl命令的时候可以用tab键进行自动补全
说明: 大家可以通过https://kubernetes.io/zh-cn/docs/tasks/tools/included/optional-kubectl-configs-bash-linux/了解更多信息
8、安装nfs
8.1、master节点安装nfs(说明:可以是其他节点也行)
// 安装nfs-utils工具包 yum install -y nfs-utils // 安装rpcbind,用于rpc通信 yum install -y rpcbind // 创建nfs文件夹 mkdir -p /nfs/data // 确定访问ip,其中*代表所有ip,当然也可以设置cidr,比如我的master节点ip是192.168.139.128,那么下面的*就可以换成192.168.0.0/16,这样可以限制访问nfs目录的ip echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports // 开机启动nfs相关服务 systemctl enable rpcbind systemctl enable nfs-server systemctl start rpcbind systemctl start nfs-server // 检查配置是否生效 exportfs -r exportfs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
8.2、所有node节点安装nfs
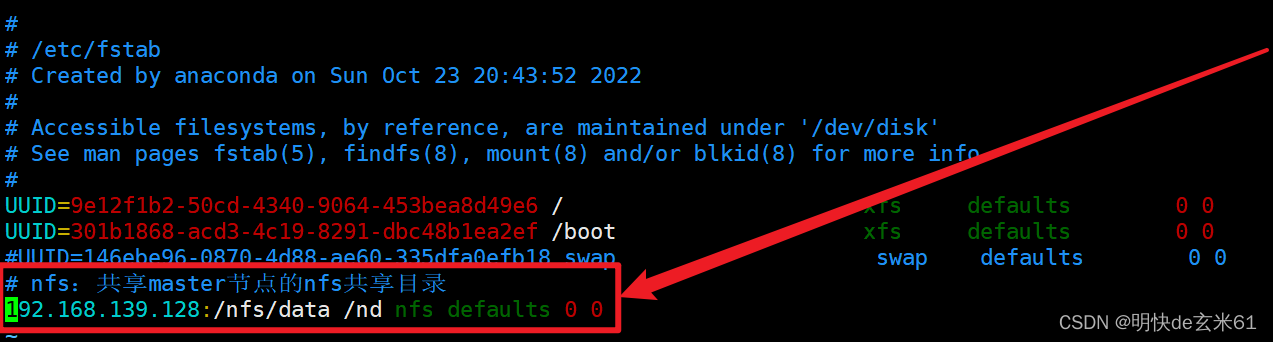
// 安装nfs-utils工具包 yum install -y nfs-utils // 检查 nfs 服务器端是否有设置共享目录,如果输出结果如下就是正常的:Export list for 192.168.139.128: /nfs/data * showmount -e master节点所在服务器ip // 创建nd共享master节点的/nfs/data目录 mkdir /nd // 将node节点nfs目录和master节点nfs目录同步(说明:假设node节点的nfs目录是/nd,而master节点的nfs目录是/nfs/data) mount -t nfs master节点所在服务器ip:/nfs/data /nd // 测试nfs目录共享效果 比如在node节点的/nd中执行echo "111" > a.txt,然后就可以去master节点的/nfs/data目录中看下是否存在a.txt文件 // 开启自动挂载nfs目录(注意:先启动master节点虚拟机,然后在启动node节点虚拟机,如果node节点虚拟机先启动,除非重新启动,不然只能通过mount -t nfs master节点所在服务器ip:/nfs/data /nd指令进行手动挂载) 执行 vim /etc/fstab 命令打开fstab文件,然后将 master节点所在服务器ip:/nfs/data /nd nfs defaults 0 0 添加到文件中,最终结果如下图,其中ip、nfs共享目录、 当前节点的nfs目录都是我自己的,大家可以看着配置成自己的即可
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
9、安装nfs动态供应
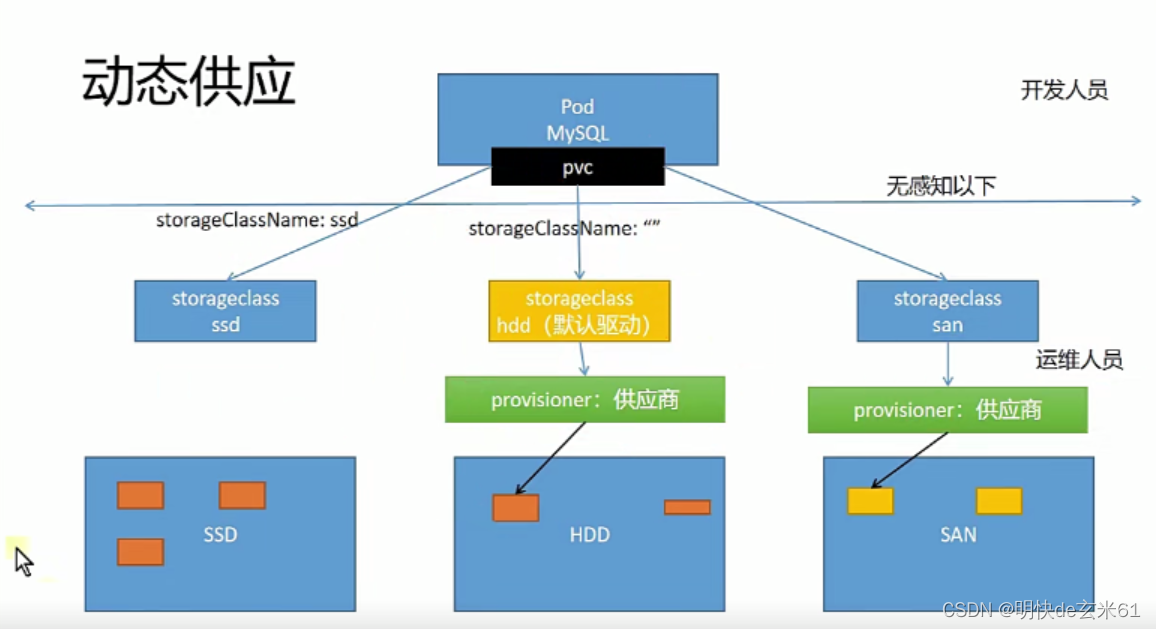
9.1、概念
开发人员只用说明自己的需求,也就是pvc,在pvc里面指定对应的存储类,我们的需求到时候自然会被满足
运维人员会把供应商(比如nfs)创建好,另外会设置好存储类的类型,开发人员只用根据要求去选择合适的存储类即可
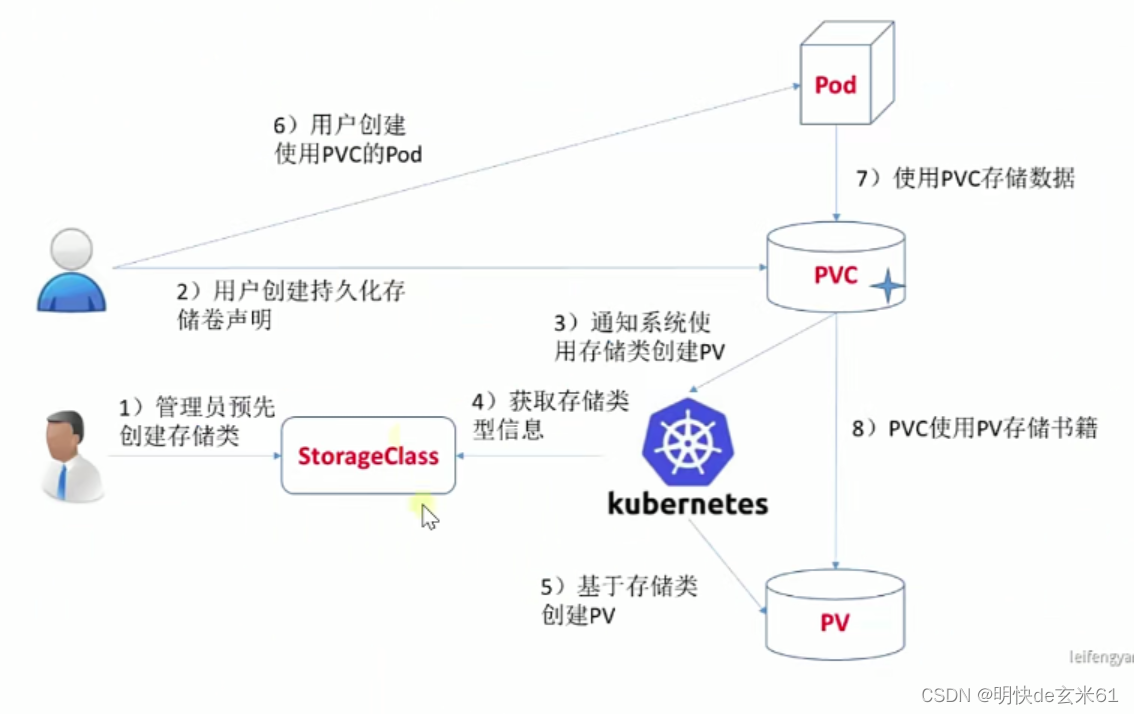
具体过程如下:
9.2、安装步骤(只用在nfs主节点执行)
9.2.1、三合一操作(注意:本节操作之后,下面9.2.2、9.2.3、9.2.4就不用操作了)
下面两个链接看下就行,主要从说明看起
操作文件所在路径:https://github.com/kubernetes-retired/external-storage/tree/master/nfs-client
目前使用deploy安装方式,具体路径是:https://github.com/kubernetes-retired/external-storage/tree/master/nfs-client/deploy
说明: 上面三个yaml可以整合到一个yaml之中,然后用---进行分隔,然后一次性执行即可,我这里提供一下合并之后的yaml,大家按照下面的说明自己改下,然后执行即可
链接:https://pan.baidu.com/s/1mtMjSDNqipi-oBTPDNjbNg?pwd=tgcj
提取码:tgcj
注意: 如果里面的镜像失效了,大家可以通过以下方式下载,然后通过kubectl load -i XXX.tar方式导入即可
链接:https://pan.baidu.com/s/1FZy7bRUlFcGko4_OzLbAqA?pwd=041z
提取码:041z
9.2.2、创建存储类(根据自己要求设置,可以设置多个)
地址:https://github.com/kubernetes-retired/external-storage/blob/master/nfs-client/deploy/class.yaml
我使用的内容可能和上面不一样,建议大家使用我下面的yaml,可以直接使用kubectl apply -f 下面的yaml文件执行即可
## 创建了一个存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage # 存储类名称
annotations:
storageclass.kubernetes.io/is-default-class: "true" # 是否是默认分类,也就是pvc不选择存储分类的时候就用这个,一般只用设置一个默认的即可
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
#provisioner指定一个供应商的名字。
#必须匹配 k8s-deployment 的 env PROVISIONER_NAME的值
parameters:
archiveOnDelete: "true" ## 删除pv的时候,pv的内容是否要备份,这个也是可选参数
#### 这里可以调整供应商能力。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
9.2.3、设置供应商信息
我使用的内容可能和上面不一样,建议大家使用我下面的yaml,不能直接复制粘贴使用,注意把yaml里面XXX代表的nfs主机ip和nfs共享目录修改成自己的,修改完成之后可以直接使用kubectl apply -f 下面的yaml文件执行即可
另外里面使用的镜像是尚硅谷雷丰阳老师的阿里云仓库镜像,如果哪一天他的镜像不在了,大家可以使用docker load -i 镜像tar包名称导入下面的镜像即可
链接:https://pan.baidu.com/s/1VT9pbmCIsh4tHdcLx5ryvA?pwd=o17g
提取码:o17g
apiVersion: apps/v1 kind: Deployment metadata: name: nfs-client-provisioner labels: app: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default spec: replicas: 1 strategy: type: Recreate selector: matchLabels: app: nfs-client-provisioner template: metadata: labels: app: nfs-client-provisioner spec: serviceAccountName: nfs-client-provisioner containers: - name: nfs-client-provisioner image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2 # 使用尚硅谷雷丰阳的镜像 # resources: # limits: # cpu: 10m # requests: # cpu: 10m volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: k8s-sigs.io/nfs-subdir-external-provisioner - name: NFS_SERVER value: XXX ## 指定自己nfs服务器地址,也就是装nfs服务器的主机ip,比如我的就是192.168.139.128 - name: NFS_PATH value: XXX ## 指定自己nfs服务器共享的目录,比如我的就是/nfs/data volumes: - name: nfs-client-root nfs: server: XXX ## 指定自己nfs服务器地址,也就是装nfs服务器的主机ip,比如我的就是192.168.139.128 path: XXX ## 指定自己nfs服务器共享的目录,比如我的就是/nfs/data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
9.2.4、设置rbac权限
地址:https://github.com/kubernetes-retired/external-storage/blob/master/nfs-client/deploy/rbac.yaml
我使用的内容可能和上面不一样,建议大家使用我下面的yaml,直接使用kubectl apply -f 下面的yaml文件执行即可
apiVersion: v1 kind: ServiceAccount metadata: name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: nfs-client-provisioner-runner rules: - apiGroups: [""] resources: ["nodes"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["create", "update", "patch"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: run-nfs-client-provisioner subjects: - kind: ServiceAccount name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default roleRef: kind: ClusterRole name: nfs-client-provisioner-runner apiGroup: rbac.authorization.k8s.io --- kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get", "list", "watch", "create", "update", "patch"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default subjects: - kind: ServiceAccount name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default roleRef: kind: Role name: leader-locking-nfs-client-provisioner apiGroup: rbac.authorization.k8s.io
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
9.3、验证
将下面yaml文件通过kubectl apply -f yaml文件命令执行,然后通过kubectl get pvc、kubectl get pv看到对应的pvc和pv信息,并且能在nfs共享目录下面看到对应的文件夹,那就说明没有问题
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx-pvc-2
namespace: default
labels:
app: nginx-pvc-2
spec:
storageClassName: managed-nfs-storage ## 存储类的名字,按照你自己的填写,如果设置了默认存储类,可以把不设置该值
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100m
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
10、安装helm
10.1、helm安装包
链接:https://pan.baidu.com/s/1qF4zrQm8FYUqMZxMYU0aAg?pwd=ju13
提取码:ju13
10.2、解压
tar -zxvf helm-v3.5.4-linux-amd64.tar.gz
- 1
10.3、移动
mv linux-amd64/helm /usr/local/bin/helm
- 1
10.4、验证
helm
- 1
10.5、添加repo仓库
helm repo add bitnami https://charts.bitnami.com/bitnami
- 1
仓库说明:默认仓库是hub,常用的第三方仓库是bitnami,这些仓库都隶属于https://artifacthub.io/平台
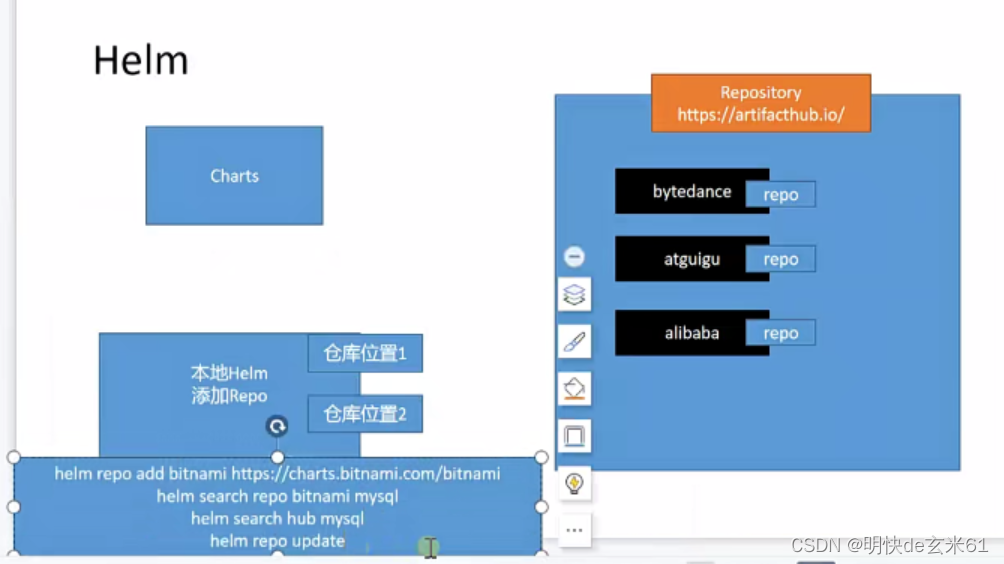
86、k8s-helloworld部署一个应用
87、k8s-集群又一次安装
88、k8s-集群架构复习
不需要总结
89、k8s-创建一次部署,可以自愈
90、k8s-了解Pod,自愈
90.1、自愈情况说明
- 可以自愈的情况:对于通过
kubectl create deploy XXX方式启动的pod,即使这个pod挂了,k8s也会自动重新拉起一个pod,当然在yaml中通过Deployment方式部署的pod也拥有自愈功能 - 无法自愈的情况:对于通过
kubectl run XXX方式启动的pod,如果pod挂了,无法重新拉取一个pod
90.2、了解Pod
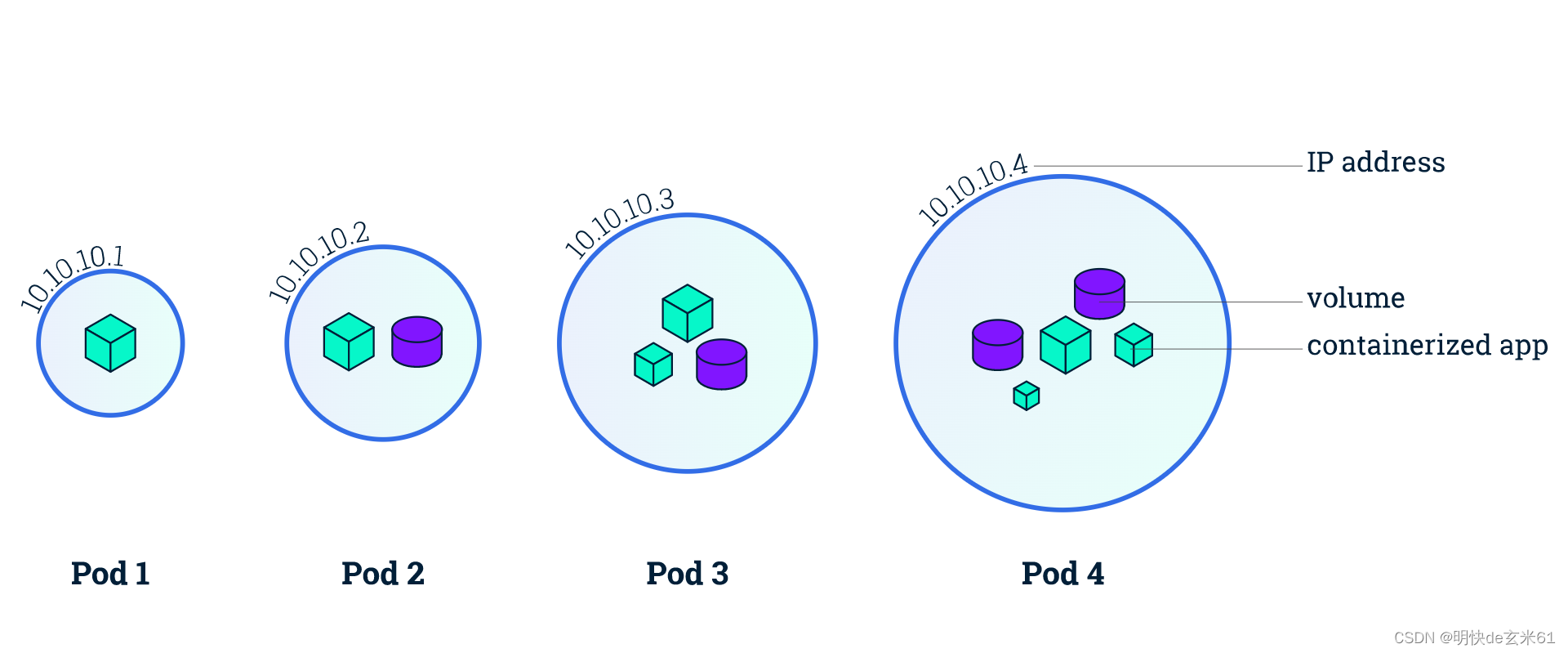
Pod (容器组) 是一个k8s中一个抽象的概念,用于存放一组 container(可包含一个或多个 container 容器,即图上正方体),以及这些 container (容器)的一些共享资源。这些资源包括:
- 共享存储,称为卷(Volumes),即图上紫色圆柱
- 网络,每个 Pod(容器组)在集群中有个唯一的 IP,pod(容器组)中的 container(容器)共享该IP地址
Pod(容器组)是 k8s 集群上的最基本的单元。当我们在 k8s 上创建 Deployment 时,会在集群上创建包含容器的 Pod (而不是直接创建容器)。每个Pod都与运行它的 worker 节点(Node)绑定,并保持在那里直到终止或被删除。如果节点(Node)发生故障,则会在群集中的其他可用节点(Node)上运行相同的 Pod(从同样的镜像创建 Container,使用同样的配置,IP 地址不同,Pod 名字不同)。
TIP
重要:
- Pod 是一组容器(可包含一个或多个应用程序容器),以及共享存储(卷 Volumes)、IP 地址和有关如何运行容器的信息。
- 如果多个容器紧密耦合并且需要共享磁盘等资源,则他们应该被部署在同一个Pod(容器组)中。
91、k8s-需要记住会用的一些命令
- kubectl get namespace:查看所有名称空间
- kubectl api-versions:查看yaml文件中所有apiVersion的值
- kubectl api-resources:查看所有资源信息,其中KIND对应yaml文件中kind的值,其中APIVERSION对应yaml文件中apiVersion的值
- kubectl api-resources --namespaced=true:查看在名称空间下面的所有资源信息
- kubectl api-resources --namespaced=false:查看不在名称空间下面的所有资源信息
- kubectl get nodes:查看所有节点信息
- kubectl get node --show-labels:查看节点的标签信息
- kubectl label pod pod资源名称 标签key=标签value:给Pod打标签,例如:kubectl label pod nginx-6799fc88d8-kwx5z name=gm
- kubectl label pod pod资源名称 标签key=标签value --overwrite:更新Pod的标签,例如:kubectl label pod nginx-6799fc88d8-kwx5z name=gm1 --overwrite
- kubectl label pod pod资源名称 标签key-:删除Pod的标签,例如:kubectl label pod nginx-6799fc88d8-kwx5z name-
- kubectl get pod:查询
default名称空间中的所有pod - kubectl get pod -n 名称空间:查看该名称中的pod
- kubectl get pod -A:查询所有名称空间中的pod
- kubectl get pod -owide:查询
default名称空间中的所有pod的详细信息,包括部署的节点名称等 - kubectl get pod --show-labels:查看pod标签Labels
- kubectl get pod -l 标签key=标签value:根据标签查询名称空间中的pod
- kubectl get deploy:查看
default名称空间中的所有deploy - kubectl get deploy -n 名称空间:查看该名称中的deploy
- kubectl get deploy -A:查询所有名称空间中的deploy
- kubectl get deploy -owide:查询
default名称空间中的所有deploy的详细信息,包括容器信息、镜像信息、可选标签等 - kubectl get all:获取
default名称空间中的所有资源 - kubectl get all -n 名称空间:查看该名称空间中的所有资源
- kubectl get all -A:查询所有名称空间中的所有资源
- kubectl get all -owide:查询
default名称空间中的所有资源的详细信息 - kubectl get 资源类型1,资源类型2…:查看
default名称空间中的上述资源的信息,例如:kubectl get pod,deploy - kubectl describe pod pod名称:查看pod描述信息
- kubectl describe deployment 部署名称:查看部署描述信息
- kubectl logs pod名称 -n 名称空间:查看pod中容器日志,单一容器可以这样做
- kubectl logs -f pod名称 -n 名称空间:动态查看pod中容器日志,单一容器可以这样做
- kubectl logs -f pod名称 -n 名称空间 -c 容器名称:动态查看pod中容器日志,多个容器可以这样做
- kubectl exec -it pod名称 – /bin/bash:进入pod内部,单一容器可以这样做;其中
/bin/bash也不是固定不变的,有的是/bin/sh,所以注意点 - kubectl exec -it pod名称 -c 容器名称 – /bin/bash:进入容器内部,多个容器需要这样做,否则进入的是Pod中的默认容器,例如:
kubectl exec -it multi-container-pod -c alpine-container -- /bin/sh;其中/bin/bash也不是固定不变的,有的是/bin/sh,所以注意点 - exit:从pod内部退出
- kubectl run pod名称 --image=镜像信息:创建一个pod
- kubectl create deploy deploy名称 --image=镜像信息:创建一次部署,拥有自愈能力
- kubectl delete 资源类型(全称或者缩写) 资源名称:用于删除资源,比如
kubectl delete pod my-ali用于删除pod,当然也可以写成kubectl delete pod/my-ali;如果需要删除多个,中间用空格隔开即可,例如:kubectl delete pod/my-ali1 pod/my-ali2 - kubectl delete 资源类型(全称或者缩写) 资源名称 --force --grace-period=0 -n 名称空间:用于强制删除资源,场景是删除了部分Pod,但是Pod的状态很长时间都是Terminating,所以需要强制删除;例如:
kubectl delete pod/gitlab-55b5687489-j5mqv --force --grace-period=0 -n gitlab - kubectl get 资源类型(全称或者缩写) 资源名称 -oyaml:查看资源yaml,比如
kubectl get pod my-ali -oyaml、kubectl delete pod/my-ali这些写法都可以,其中资源名称可以用全名,也可以用缩写 - kubectl explain 资源类型(全称或者缩写).key名称……:在编写
yaml文件的时候,我们经常会遇到不太懂某个属性值的写法,那我们就可以这样来解释一下属性值的具体写法,比如kubectl explain pod.metadata.labels就是解释下labels属性的写法 - kubectl get pod -w:主要说明
-w的用法,其实作用就是-w会将变化往下追加,所以建议还是使用watch -n 秒数 命令来监控 - kubectl get 资源类型 -l 标签名称=标签值:根据标签信息查找资源,例如:
kubectl get pod -l version=v1用来查找标签中version是v1的pod资源 - 命令 --dry-run=client -oyaml:查看命令对应的
yaml文件内容,例如:kubectl run my-nginx --image=nginx --dry-run=client -oyaml - kubectl get 资源类型 资源名称 -oyaml:查看当前资源对应的
yaml文件,例如:kubectl get pod my-nginx-pod-test -oyaml - kubectl edit 资源类型 资源名称:编辑当前资源对应的
yaml文件,例如:kubectl edit pod my-nginx-pod-test,编写完成之后输入:wq就可以保存了
92、k8s-手动扩缩容操作
我们先来创建一个部署,脚本如下:
// 第一个nginx是部署名称,第二个nginx是镜像名称
kubectl create deploy nginx --image=nginx
- 1
- 2
然后查看一些部署情况,如下:
kubectl get deploy
- 1
现在部署中只有一个pod,然后我们将部署中的pod进行扩容,脚本是:
// 副本数是5,副本数变大就是扩容,反之就是缩容,deploy是deployments的缩写,可以通过kubectl api-resources命令查看,然后nginx是上面的部署名称
kubectl scale --replicas=5 deploy/nginx
- 1
- 2
93、k8s-service将Pod封装一个统一服务
93.1、创建ClusterIP类型的service服务
接着上一次的扩容例子继续讲解,上次创建的部署名称是nginx,扩容之后存在多个pod,本次我们将这次部署暴露出去,然后统一负载均衡的访问多个pod,脚本如下:
// nginx是部署名称,81是service的端口名称,80代表pod的端口名称(pod中是nginx,所以访问端口是80),这样我们访问service的81端口就相当于访问pod的80端口,ClusterIP代表一种方式,这种方式只能在虚拟机内部访问,无法在浏览器上访问
kubectl expose deploy nginx --port=81 --target-port=80 --type=ClusterIP
- 1
- 2
我们可以通过kubectl get all查看ClusterIP的情况,如下:
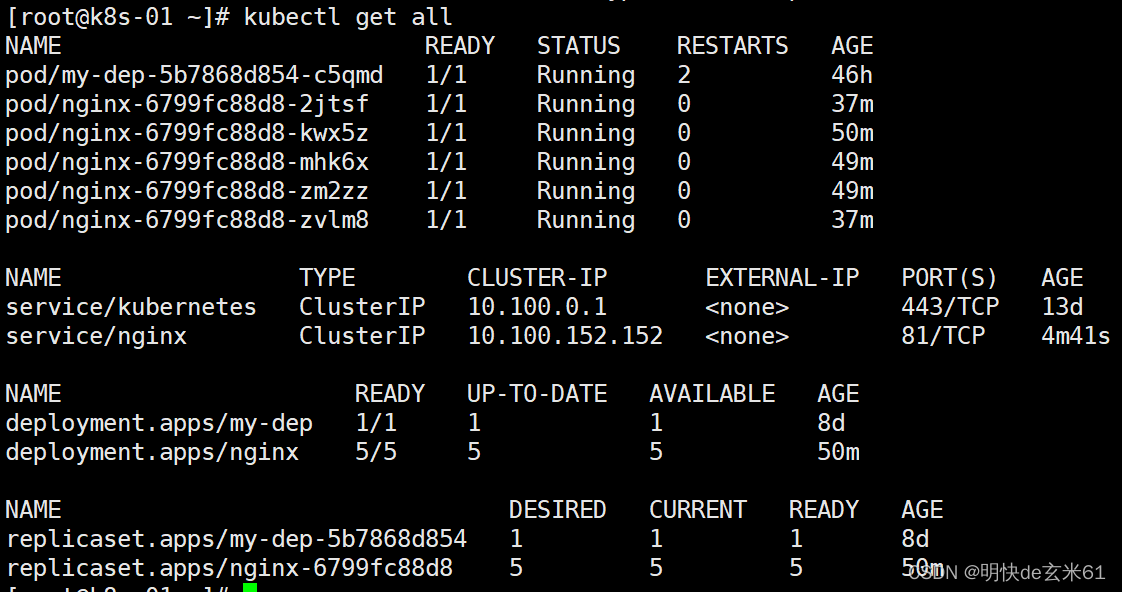
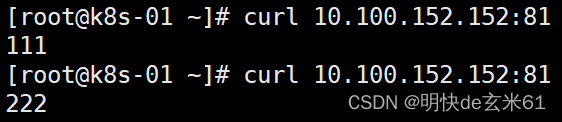
我们可以通过curl ip:port来访问service中的pod,比如本次就是curl 10.100.152.152:81
我们可以通过kubectl exec -it pod名称 -- /bin/bash命令进入容器内部,之后把/usr/share/nginx/html中的index.html删除,之后把一些特定数字(比如:111、222)写入index.html中,然后我们多次访问service就能看到负载均衡的效果,如下:
93.2、创建NodePort类型的service服务
上面提到,ClusterIP类型的service服务无法在浏览器上访问,而NodePort类型的service服务可以在浏览器上访问,所以我们把上述暴露服务命令更改为如下内容:
kubectl expose deploy nginx --port=81 --target-port=80 --type=NodePort
- 1
注意: 已经暴露为ClusterIP形式的service需要先删除,然后在使用上面的命令重新暴露即可,然后通过kubectl get all查看NodePort方式的service访问方式,其中81也会把端口暴露到外面,例如:
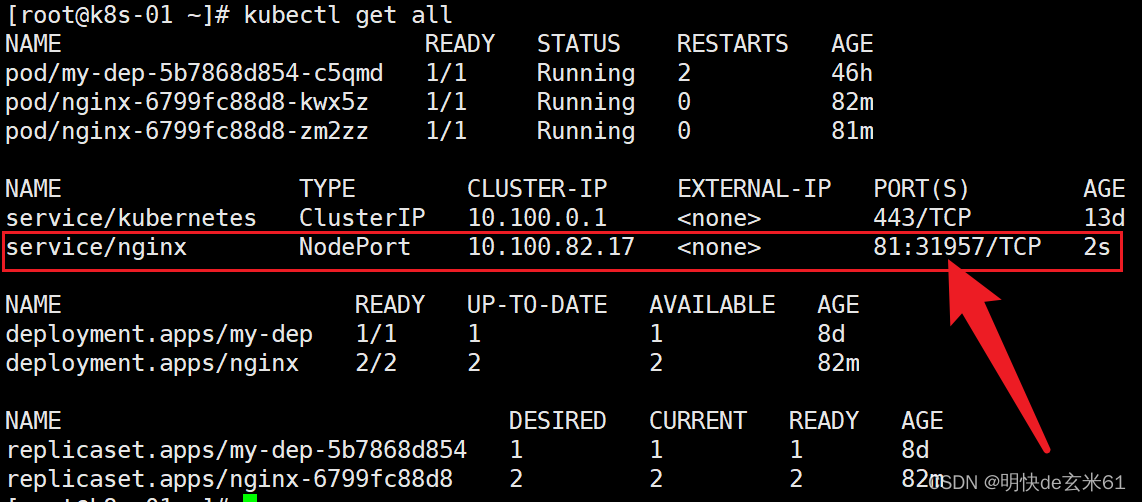
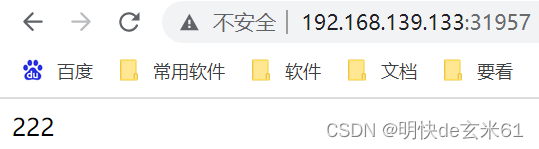
然后我们在浏览器上访问即可,其中ip是虚拟机ip,而端口是上图中的31957,截图如下:
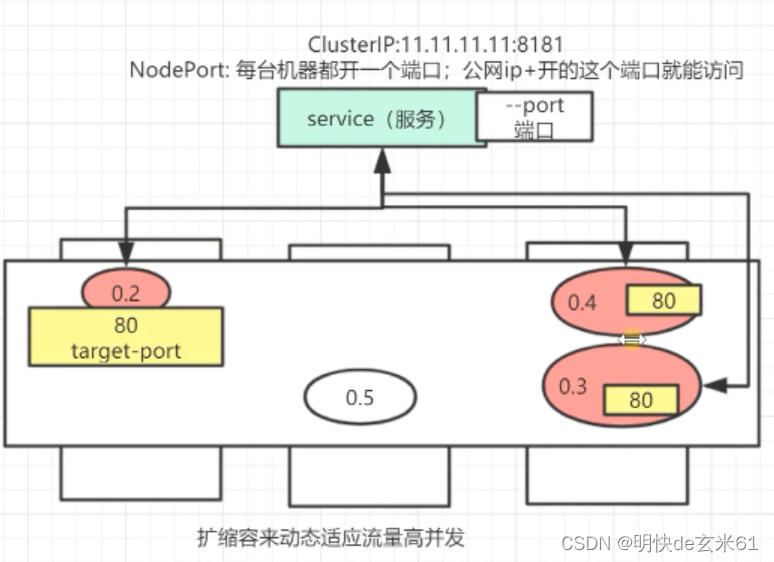
如果用图形表示,类似于:
93.3、给node打标签
我们想要给node添加一些角色,但是需要对node打标签,所以我们先看下节点标签的样子,首先输入kubectl get node,可以看到ROLES下面的值对应绿框框中的内容,所以只有标签键,根本没有标签值,如下所示:

那我们给k8s-02节点添加worker角色,其实是一个打标签的过程,命令如下:
// node是资源类型,k8s-02是资源名称,node-role.kubernets.io/worker是标签键,=代表添加
kubectl label node k8s-02 node-role.kubernetes.io/worker=
- 1
- 2
如果我们想删除k8s-02节点中的worker角色,命令如下:
// node是资源类型,k8s-02是资源名称,node-role.kubernets.io/worker是标签键,-代表减去
kubectl label node k8s-02 node-role.kubernetes.io/worker-
- 1
- 2
93.4、给pod打标签
在上面给node打标签的时候已经大致说过了,脚本如下:
// pod是资源类型,nginx-6799fc88d8-kwx5z是资源名称,name是标签键,而gm是标签值
kubectl label pod nginx-6799fc88d8-kwx5z name=gm
- 1
- 2
如果我们想把值gm切换成gm1,脚本如下:
kubectl label pod nginx-6799fc88d8-kwx5z name=gm1 --overwrite
- 1
如果我们想把这个pod删除了,那么脚本如下:
// pod是资源类型,nginx-6799fc88d8-kwx5z是资源名称,name是标签键,而-就代表删除指令
kubectl label pod nginx-6799fc88d8-kwx5z name-
- 1
- 2
94、k8s-滚动升级
94.1、滚动升级解释
滚动升级也就是让用户无感知的情况下,也就是不影响用户使用的情况下达到应用升级的目的,依然用上面的情况举例子,我们暴露了一个service服务,该服务对应一个deploy部署,而该部署中存在多个pod,假设此时我们升级image镜像版本,那就用到了k8s的滚动升级策略
94.2、滚动升级具体流程
依然用上面暴露的nginx服务为例,我们来说明滚动升级的具体流程和现象
镜像滚动升级命令如下:
// deploy是资源类型,第一个nginx是deployment部署名称,第二个nginx代表nginx:latest,也就是原有镜像信息,而nginx:1.9.1代表最新的nginx镜像信息,最后的--record=true代表记录本次变动的命令
// 作用:将nginx部署中的nginx镜像版本从latest更改为1.9.1
kubectl set image deploy nginx nginx=nginx:1.9.1 --record=true
- 1
- 2
- 3
如果我们同步使用kubectl get pod命令监控pod变化,可以发现k8s会先启动一个pod,当这个pod真正运行之后,在杀掉原来的pod,从而达到不停机维护的目的
如果大家不知道部署中的镜像使用的是什么版本,我们可以对pod执行如下脚本:
// nginx-6799fc88d8-7525w是nginx的pod名称,-o yaml代表获取pod对应的yaml文件,然后通过grep image命令查看pod中所用的镜像信息
kubectl get pod nginx-6799fc88d8-7525w -o yaml | grep image
- 1
- 2

94.3、版本回滚具体流程
首先我们先来查看一下有哪些可以恢复的历史版本,命令如下:
// deploy是资源类型,nginx是deploy部署名称
kubectl rollout history deploy nginx
- 1
- 2
结果如下:

此时我们想回到revision=1的情况,脚本如下:
// deploy是资源类型,nginx是deploy部署名称,--to-revision=1代表回到版本为1的状态
kubectl rollout undo deploy nginx --to-revision=1
- 1
- 2
95、k8s-对象描述文件
使用命令来对文件进行操作实在太麻烦了,另外运维在部署的时候也不好使用,所以最好使用文件来描述一下操作
我们来举一个例子,把下面内容复制到一个yaml文件中,比如nginx.yaml,内容如下:
apiVersion: apps/v1 #与k8s集群版本有关,使用 kubectl api-versions 即可查看当前集群支持的版本 kind: Deployment #该配置的类型,我们使用的是 Deployment metadata: #译名为元数据,即 Deployment 的一些基本属性和信息 name: nginx-deployment #Deployment 的名称 labels: #标签,可以灵活定位一个或多个资源,其中key和value均可自定义,可以定义多组,目前不需要理解 app: nginx #为该Deployment设置key为app,value为nginx的标签 spec: #这是关于该Deployment的描述,可以理解为你期待该Deployment在k8s中如何使用 replicas: 1 #使用该Deployment创建一个应用程序实例 selector: #标签选择器,与上面的标签共同作用,目前不需要理解 matchLabels: #选择包含标签app:nginx的资源 app: nginx template: #这是选择或创建的Pod的模板 metadata: #Pod的元数据 labels: #Pod的标签,上面的selector即选择包含标签app:nginx的Pod app: nginx spec: #期望Pod实现的功能(即在pod中部署) containers: #生成container,与docker中的container是同一种 - name: nginx #container的名称 image: nginx:1.7.9 #使用镜像nginx:1.7.9创建container,该container默认80端口可访问
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
假设文件名称是nginx.yaml,我们执行如下脚本来创建一次部署,如下:
kubectl apply -f nginx.yaml
- 1
此时就会为我们创建一次部署
如果我们想修改nginx.yaml文件中的内容,比如副本数量、镜像版本等,那我们可以直接修改该配置文件即可,例如我们把镜像改成最新的镜像,那么nginx:1.7.9就变成了nginx,修改完成之后,依然执行kubectl apply -f nginx.yaml即可完成更新操作
如果我们想删除之前的部署,我们只用对yaml文件进行删除操作,那么相关部署、pod都会被删除,对应脚本如下:
kubectl delete -f nginx.yaml
- 1
96、k8s-安装官方dashboard
上面已经总结了,这里不再总结
97、k8s-集群中的资源会达到最终一致
97.1、期望状态和当前状态的解释
k8s中的每一种资源都有期望状态(也叫做目标状态)和当前状态,当前状态可能不等于期望状态,但是它会不断的超期望状态去靠近,直到达到期望状态
97.2、从yaml文件中看期望状态和当前状态
对于k8s中的任意一种资源都存在期望状态和目标状态,我们以上面进行的部署为例说明,先通过kubectl get all查看部署情况,然后找到我们之前的部署信息,然后执行如下脚本,用来查看部署对应的yaml文件:
kubectl get deployment.apps/nginx-deployment -oyaml
- 1
yaml文件具体内容如下:
apiVersion: apps/v1 kind: Deployment metadata: annotations: deployment.kubernetes.io/revision: "1" kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"labels":{"app":"nginx"},"name":"nginx-deployment","namespace":"default"},"spec":{"replicas":3,"selector":{"matchLabels":{"app":"nginx"}},"template":{"metadata":{"labels":{"app":"nginx"}},"spec":{"containers":[{"image":"nginx","name":"nginx"}]}}}} creationTimestamp: "2023-02-01T11:58:50Z" generation: 1 labels: app: nginx name: nginx-deployment namespace: default resourceVersion: "126322" uid: d7014776-7200-4451-a585-bf18334f1264 spec: progressDeadlineSeconds: 600 replicas: 3 revisionHistoryLimit: 10 selector: matchLabels: app: nginx strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 25% type: RollingUpdate template: metadata: creationTimestamp: null labels: app: nginx spec: containers: - image: nginx imagePullPolicy: Always name: nginx resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 status: availableReplicas: 3 conditions: - lastTransitionTime: "2023-02-01T11:59:00Z" lastUpdateTime: "2023-02-01T11:59:00Z" message: Deployment has minimum availability. reason: MinimumReplicasAvailable status: "True" type: Available - lastTransitionTime: "2023-02-01T11:58:50Z" lastUpdateTime: "2023-02-01T11:59:00Z" message: ReplicaSet "nginx-deployment-6799fc88d8" has successfully progressed. reason: NewReplicaSetAvailable status: "True" type: Progressing observedGeneration: 1 readyReplicas: 3 replicas: 3 updatedReplicas: 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
可以看到里面有一个spec:,它下面指示的是期望状态,而status:下面指示的是当前状态,其中当前状态是一直在变化的,如果我们杀死pod,那我们在执行上述命令查看yaml文件,那就可以看到status:内容发生变化了
status:信息是自动生成的,而我们在编写yaml文件的时候只需要指定spec:内容就可以了
98、k8s-对象描述文件
98.1、编写yaml方法
98.1.1、从正在运行的同类资源中获取yaml
比如我想编写一个deploy部署的yaml,那就可以找到一个deploy,然后查看对应的yaml,命令如下:
kubectl get deployment.apps/nginx-deployment -oyaml
- 1
获取该yaml之后模仿着写就是了
98.1.2、用命令生成yaml
直接上命令,如下:
kubectl run my-nginx --image=nginx --dry-run=client -oyaml
- 1
我们运行一个nginx的pod,使用--dry-run=client来表示干跑一遍,但是不会真正部署pod,然后我们在获取到它的yaml文件
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: my-nginx
name: my-nginx
spec:
containers:
- image: nginx
name: my-nginx
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
98.1.3、自己手动编写yaml文件
比如生成一个最简单的nginx的pod,该yaml文件的名称是nginx.yaml
# typeMeta开始…… apiVersion: v1 # 对应 kubectl api-resources 命令中返回的APIVERSION kind: Pod # 对应 kubectl api-resources 命令中返回的KIND # typeMeta结束…… # ObjectMeta开始…… metadata: name: my-nginx-pod # 资源名称 namespace: default # ObjectMeta结束…… # 期望状态开始…… spec: containers: # 指定启动的容器信息 - image: nginx # 指定镜像 name: my-nginx-container # 容器名称 # 期望状态结束……
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
那么执行的脚本是:
kubectl apply -f my-nginx.yaml
- 1
99、k8s-名称空间
99.1、比较当前运行的资源和yaml文件呈现的资源的不同之处
还以98.1.3、自己手动编写yaml文件为例,我们通过kubectl apply -f my-nginx.yaml生成了一个pod,然后我们把nginx.yaml中的镜像版本从latest改成了1.9.1,此时我们执行如下脚本来对比现在正在运行的pod和yaml文件中的pod之间的不同之处,如下:
kubectl diff -f my-nginx.yaml
- 1
执行结果如下图:
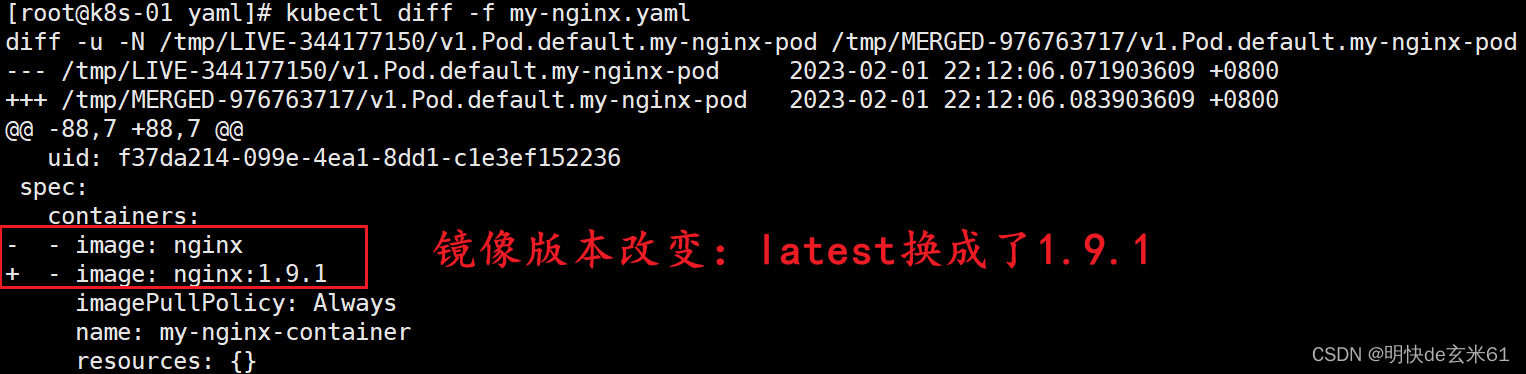
如果我们在执行kubectl apply -f my-nginx.yaml,将会执行更新操作,然后让当前状态status达到现在的期望状态spec
99.2、根据yaml文件删除资源
还以上面的nginx.yaml为例,删除的时候只需要执行如下脚本即可:
kubectl delete -f my-nginx.yaml
- 1
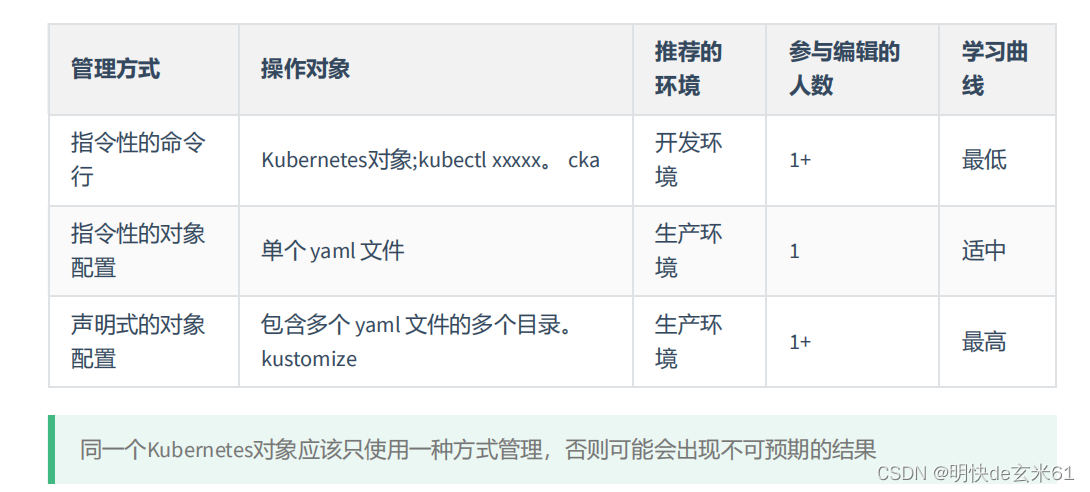
99.3、管理k8s对象的几种方式
99.4、不同名称空间下的资源能共享吗,网络能互通吗?
不同名称空间下的资源不同共享,但是网络可以互通
99.5、名称空间如何隔离?
- 基于环境隔离:比如prod代表生产环境,test代表测试环境,dev代表开发环境
- 基于产品线:比如android、ios等
- 基于团队隔离:比如taobao、jingdong、zijie
我们公司的k8s集群使用了基于环境隔离和基于团队隔离的方式
99.6、名称空间命名规范
- 最长不超过 253个字符
- 必须由小写字母 / 数字 / 减号 - / 小数点. 组成
- 某些资源类型有更具体的要求
99.7、使用命令创建、删除名称空间
创建: kubectl create ns dev,说明:创建dev名称空间
查看: kubectl get ns,说明:查看所有名称空间
删除: kubectl delete ns dev,说明:删除dev名称空间
99.7、使用yaml文件创建、删除名称空间
首先把名称空间的yaml文件放在yaml文件中,如下:
apiVersion: v1
kind: Namespace
metadata:
name: dev
- 1
- 2
- 3
- 4
创建: kubectl apply -f ns.yaml,说明:创建dev名称空间
查看: kubectl get ns,说明:查看所有名称空间
删除: kubectl delete -f ns.yaml,说明:删除dev名称空间
100、k8s-如何编写一个k8s的资源描述文件
前提准备:
先编写之前,我们需要知道该类型的yaml文件大致怎么写的,那可以通过命令获取yaml的方式或者查看现有同类资源yaml的方式,上面已经说过了这两种方式,这里在说明一下
通过命令获取yaml:kubectl run my-nginx --image=nginx --dry-run=client -oyaml,这是生成镜像为nginx的pod的yaml文件
查看现有同类资源yaml:kubectl get deployment.apps/nginx-deployment -oyaml,这是获取pod中镜像为nginx的yaml文件
中途准备:
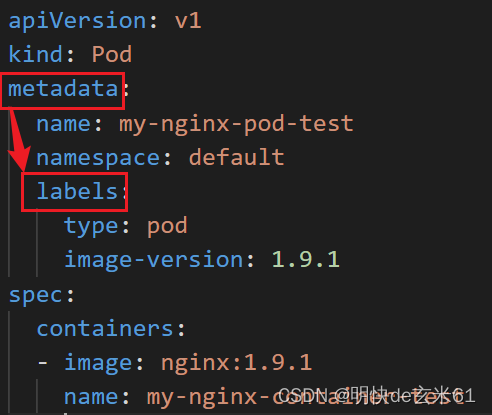
在编写yaml文件的时候,我们会遇到某个属性的键或者值不会写了,这样我们就可以借助于kubectl explain命令来解释一下属性,我们下面的脚本就是解释pod的yaml文件中metadata下面labels的写法,这种写法是链式写法
kubectl explain pod.metadata.labels
- 1
对于上面脚本中用法的解释,下图是一个pod的yaml的截图,metadata是其中一个属性,而labels是metadata中的一个子属性,如下图:
最终执行:
一般使用kubectl apply就可以了,不仅可以用来新增,还可以用来更新已有的资源,而kubectl create只可用用来新增,但是不能用了更新,因此建议使用kubectl apply
kubectl apply -f XXX.yaml
- 1
错误修复:
如果我们yaml文件写的存在问题,那我们在执行kubectl apply的时候就会出现错误提示,基本会明显的告诉我们yaml文件哪里写错了
101、k8s-自己该如何往下摸索
101.1、给vscode安装插件
101.1.1、安装YAML

101.1.2、安装Kubernetes Templates

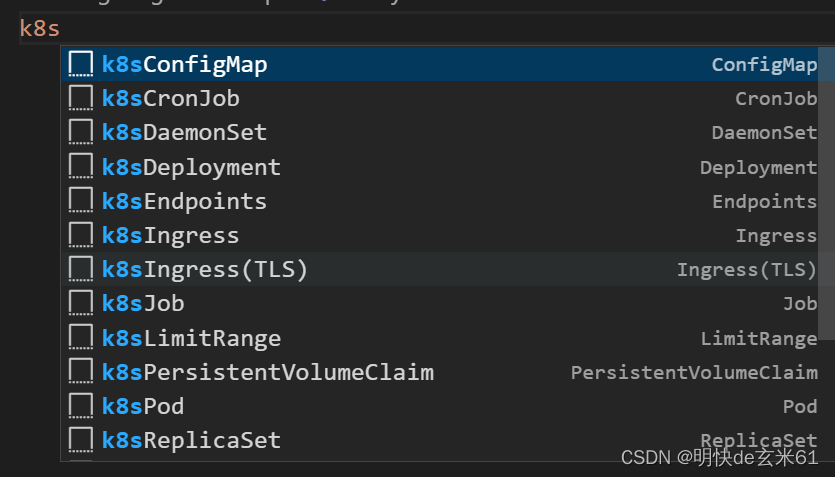
101.1.3、插件如何使用
在yaml文件中输入k8s就可以看到很多可以选项,如下图:
我们在选中一些单词的的时候,点击Ctrl+D,然后就可以依次选择一样的单词
101.1、kubectl explain如何往下探索
我们依然来举一个例子,输入kubectl explain pod.spec.containers.resources回车可以看到如下内容:
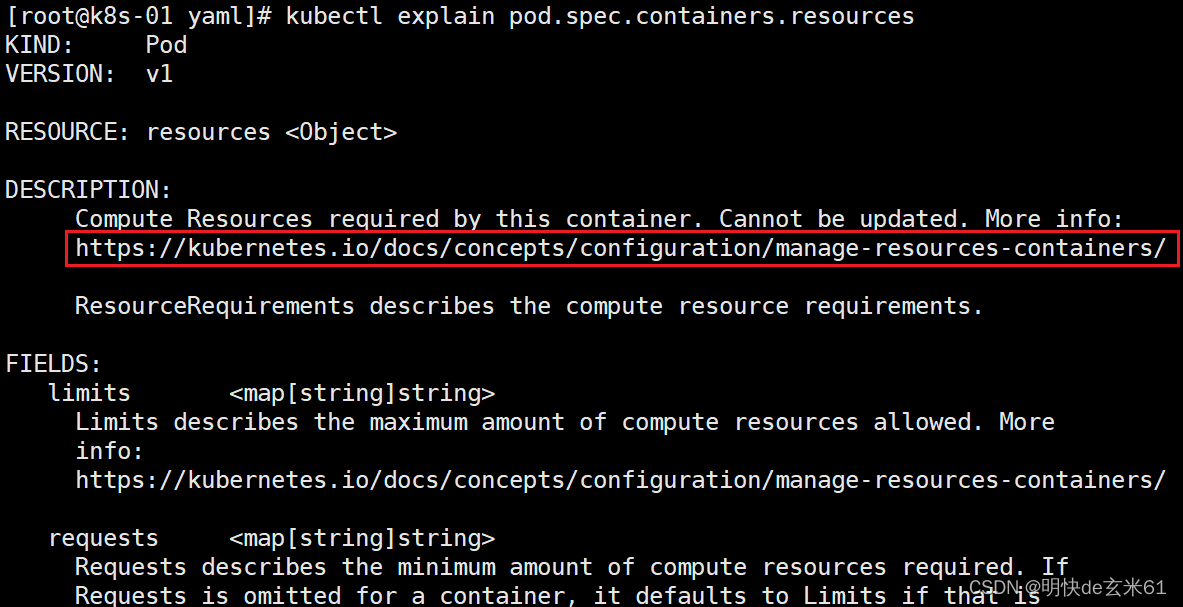
如果我们想了解更多resource的信息,可以访问上图红色框中的链接,但是这是英文文档的链接,我们可以把链接中的https://kubernetes.io/替换成https://kubernetes.io/zh-cn/,那样就可以查看中文文档了,例如:https://kubernetes.io/zh-cn/docs/concepts/configuration/manage-resources-containers/
102、k8s-核心组件的配置文件位置以及所有命令
102.1、核心组件的配置文件位置
- 核心文件夹:
/etc/kubernetes、/etc/kubernetes/manifests,以pod方式安装核心组件 - kubelet额外参数配置:
/etc/sysconfig/kubelet - kubelet配置位置:
/var/lib/kubelet/config.yaml
102.2、相关命令
- API 概述:https://kubernetes.io/zh-cn/docs/reference/using-api/
- 命令行工具 (kubectl):https://kubernetes.io/zh-cn/docs/reference/kubectl/
103、k8s-命令自动补全功能
上面已经说过了,这里不再赘述
104、k8s-容器镜像使用秘钥从私有仓库下载
104.1、镜像拉取策略
首先先看一下镜像拉取策略在yaml中文件中的使用位置,如下:
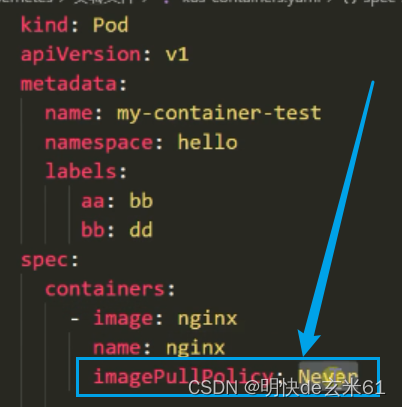
我们再来看一下有哪几种镜像拉取策略,如下:
- Always:默认策略;不管本机有没有,都要去镜像仓库拉取镜像,当然镜像是分层的,如果当前层在本机已经有了,那就不拉取了,否则就拉取,所以无论如何都会去远程仓库拉取镜像;注意:如果远程镜像镜像仓库没有镜像,那就会报错,无论本机是否存在镜像
- Never:不会去镜像仓库拉取镜像,直接使用本机的镜像,如果本机没有该版本的镜像就会报错
- IfNotPresent:先查看本机是否存在该镜像,如果有就直接使用,否则就去远程镜像仓库拉取镜像
说明: 镜像拉取策略还是很有用的,我们公司有一个k8s演示集群,它部署在单独的服务器上,而harbor镜像仓库在其他服务器上,在我们公司内部,k8s集群和harbor仓库网络是通的,所以能拉取镜像,但是在演示项目的时候需要把服务器拉到客户单位,那就需要改变yaml文件中的镜像拉取策略,那就不能使用默认的Always了,否则镜像拉取就会报错
104.2、如何从私有镜像仓库下载镜像
104.2.1、创建镜像拉取密钥
创建镜像拉取密钥的具体语法:
kubectl create secret -n 命名空间 docker-registry 密钥名称(用在yaml文件中) \
--docker-server=镜像仓库地址 \
--docker-username=用户名 \
--docker-password=密码
- 1
- 2
- 3
- 4
注意:-n 命令空间是可选的,默认是default命名空间
我们使用上面的语法举一个例子,如下:
// 默认使用default命名空间,也可以使用-n指定名称空间
// my-aliyun是镜像密钥名称,可以在yaml文件中使用
// registry.cn-hangzhou.aliyuncs.com是镜像服务器地址
kubectl create secret docker-registry my-aliyun \
--docker-server=registry.cn-hangzhou.aliyuncs.com \
--docker-username=阿里云镜像仓库用户名 \
--docker-password=阿里云镜像仓库密码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果大家想得到对应的yaml文件,可以在上述命令之后添加--dry-run=client -oyaml获得yaml文件
104.2.2、在yaml文件中使用上面的镜像密钥
直接上yaml文件,我的目的是从阿里云私有镜像仓库中拉取一个镜像,然后部署成pod,大家主要看imagePullSecrets下面name属性的写法,我写的是my-aliyun,我把下面的yaml文件用kubectl apply -f java-devops-demo.yaml执行了,然后用kubectl describe pod my-java-devops-demo命令查看了具体信息,发现镜像拉取都是正常的,截图如下:

yaml文件如下:
apiVersion: v1
kind: Pod
metadata:
name: "my-java-devops-demo"
namespace: default
labels:
app: "my-java-devops-demo"
spec:
imagePullSecrets:
- name: my-aliyun
containers:
- name: my-java-devops-demo
image: "registry.cn-hangzhou.aliyuncs.com/mingkuaidexuanmi61/java-devops-demo:v2.0"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
105、k8s-容器启动命令、环境变量等
105.1、确定镜像拉取的仓库位置
总结: 是否使用镜像拉取密钥是根据待拉取镜像的镜像仓库地址来的,能对上就用,对不上就去中央仓库拉取
直接上yaml文件,在下面的yaml文件中可以看到containers下面有两个镜像,但是spec下面的imagePullSecrets只配置了一个,那两个镜像的拉取方式是不一样的,首先第一个镜像的镜像仓库地址是registry.cn-hangzhou.aliyuncs.com,而imagePullSecrets下的my-aliyun中配置的也是阿里云镜像仓库的地址,所以拉取第一个镜像的时候肯定会用到这个镜像拉取密钥的;而第二个镜像仓库没有写明地址,那就是中央仓库地址,所以肯定不会用到上面阿里云镜像仓库的密钥的,毕竟地址对不上嘛
apiVersion: v1
kind: Pod
metadata:
name: "my-java-devops-demo-test"
namespace: default
labels:
app: "my-java-devops-demo-test"
spec:
imagePullSecrets:
- name: my-aliyun
containers:
- name: my-java-devops-demo-test
image: "registry.cn-hangzhou.aliyuncs.com/mingkuaidexuanmi61/java-devops-demo:v2.0"
- name: my-nginx-test
image: nginx:latest
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
105.2、env环境变量怎么写
直接上yaml,该yaml文件的作用是创建一个包含mysql容器的pod,我们首先应该关注env的写法,其中name后面就是环境变量名称,而value后面就是环境变量真实值,比如下面的123456是密码,但是密码是字符串而不是数字,所以值需要用字符串包裹起来
其次我们来聊一下env的值从哪里获取,它肯定不是凭空来的,一般来自于dockerhub,比如本次mysql容器的值就来自于https://hub.docker.com/_/mysql
如果大家想了解env环境变量的详细信息,可以访问 为容器设置环境变量 页面
apiVersion: v1 kind: Pod metadata: name: "my-mysql" namespace: default labels: app: "my-mysql" spec: containers: - name: my-mysql image: mysql:5.7 env: - name: MYSQL_ROOT_PASSWORD value: "123456" - name: MYSQL_DATABASE value: "atguigu"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
105.3、env环境变量怎么用
上面已经说明了env环境变量怎么定义,下面我们说下环境变量怎么用,一般都是使用$(环境变量名称)这种形式来使用环境变量,示例如下图:
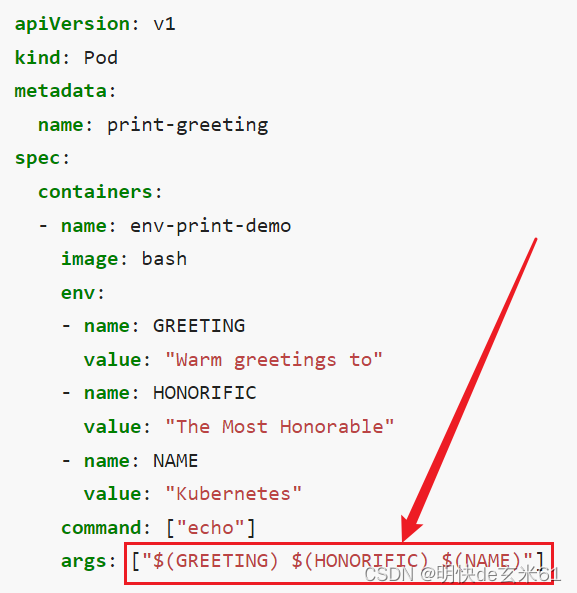
105.3、容器启动命令怎么用
直接上yaml,我们在env中定义了环境变量msg,然后在command中通过$(msg)使用了环境变量的值,在执行yaml之后可以通过kubectl logs my-command-test可以查看日志信息
apiVersion: v1 kind: Pod metadata: name: "my-command-test" namespace: default labels: app: "my-command-test" spec: containers: - name: my-command-test image: nginx env: - name: msg value: "hello command" command: - /bin/sh - -c - "echo $(msg);sleep 3600"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
我们来说一下command的写法,我们可以写成数组的形式,比如:command: ["/bin/sh", "-c", "echo $(msg);sleep 3600"],或者写成上面的写法都是可以的
另外说下镜像中命令和yaml文件中command命令的使用优先级,我们直接看第3列,如果yaml文件中写了command命令,那么镜像中的命令就完全不起效了,所以有谨慎使用;另外第4列是yaml文件中args属性的用法,第5列是命令执行列

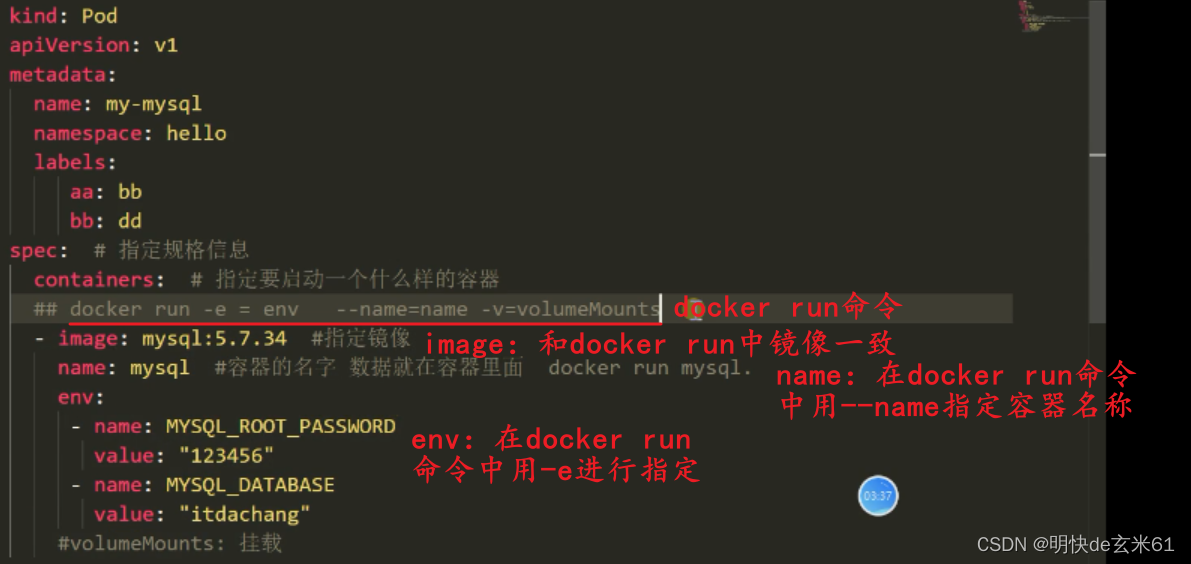
106、k8s-containers的写法就是对应docker run的写法
说明: 只要我们会写docker run命令,那就能写出来yaml文件中containers中的内容
107、k8s-containers的生命周期钩子
说明: 我们都知道pod中是容器,容器是存在生命周期的,在容器创建成功之后以及删除之前都是可以通知我们的
直接上yaml文件,postStart中的配置代表在nginx容器创建完成之后就会发送http请求到某位置,我发送的位置是本机另外一个nginx的pod,方便用来测试嘛,可以用kubectl apply -f my-life-test.yaml测试;preStop中的配置代表在nginx容器删除之前就会发送http请求,我依然使用的是本机另外一个nginx的pod,可以用kubectl delete -f my-life-test.yaml测试,测试结果在下面的截图中

yaml文件如下:
apiVersion: v1 kind: Pod metadata: name: "my-life-test" namespace: default labels: app: "my-life-test" spec: containers: - name: my-life-test image: nginx lifecycle: postStart: httpGet: host: "10.101.179.43" path: "/postStart" port: 80 scheme: HTTP preStop: httpGet: host: "10.101.179.43" path: "/preStop" port: 80 scheme: HTTP
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
上面介绍的是httpGet方式,还有其他通知方式,截图如下:

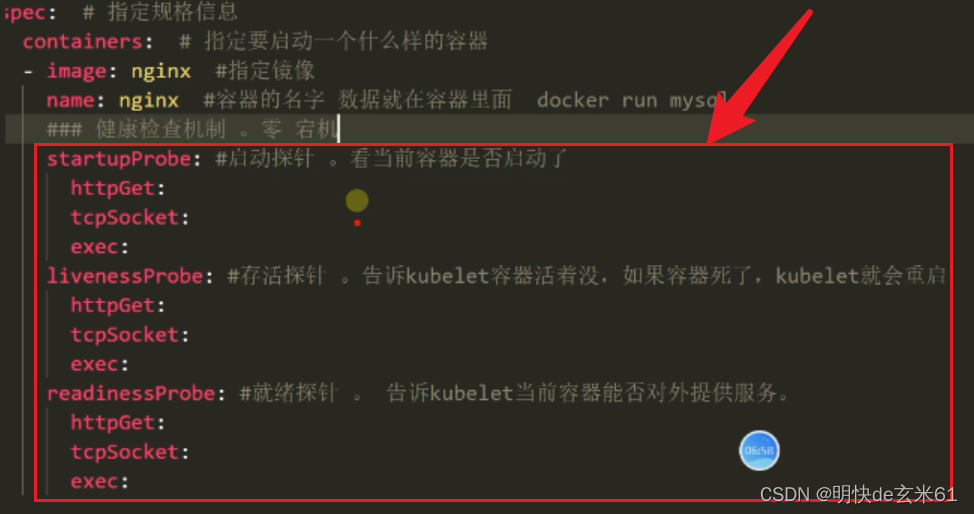
108、k8s-containers-容器探针是什么?
- 启动探针:告诉kubelet容器是否启动
- 存活探针:告诉kubelet容器是否存活,如果容器死亡,kubelet就会重启容器
- 就绪探针:告诉kubelet容器是否能提供服务
下面就是这几种探针的详细解释和具体写法,如下:
109、k8s-如何接下来学习k8s
110、k8s-小总结
以后写yaml文件主要注意两点:
- kubectl explain命令
- 官网
111、k8s工作负载-什么是工作负载
111.1、工作负载的概念
- 工作负载是运行在 Kubernetes 上的一个应用程序。
- 一个应用很复杂,可能由单个组件或者多个组件共同完成。无论怎样我们可以用一组Pod来表示一个应用,也就是一个工作负载
- Pod又是一组容器(Containers),所以关系又像是这样
- 工作负载(Workloads)控制一组Pod
- Pod控制一组容器(Containers)
- 比如Deploy(工作负载) 3个副本的nginx(3个Pod),每个nginx里面是真正的
- nginx容器(container)
111.2、工作负载的分类
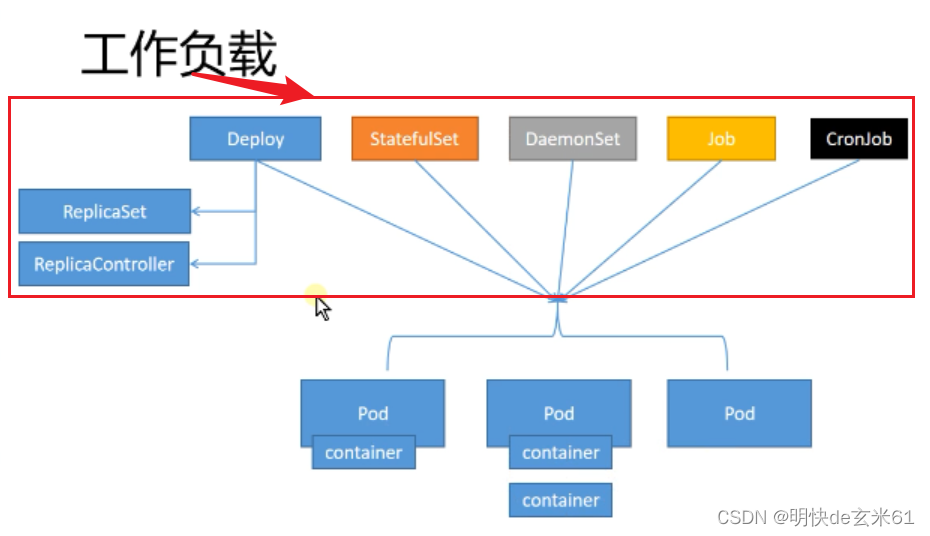
112、k8s工作负载-Pod的概念
- Pod概念:Pod 是一组(一个或多个) 容器(docker容器)的集合 。Pod中的所有容器共享存储、网络……,也就是大家存储空间是公共的,大家都可以用
- Pod对容器具有自恢复能力
- Pod自身没有自恢复能力
- Pod启动之后会自动启动一个Pause容器,该容器将会自动设置Pod中里面所有容器的网络、名称空间等信息,这也正是Pod中多个容器可以共享存储、网络的原因
113、k8s工作负载-Pod的多容器协同
先来说下面yaml文件的作用,首先一个pod中的两个容器分别是nginx-container和alpine-container,大家可以看到两个容器的volumeMounts中用的都是common-vol,对于nginx容器的/usr/share/nginx/html目录,和alpine容器的/app目录都是一致的,如果我们去更改共享目录中的index.html文件内容,那么访问nginx得到的内容就会发生改变,所以以下yaml的作用是通过alpine容器往index.html中写入日期,然后访问nginx容器的时候就会看到这个变化的日期,这也体现了Pod中多容器协同
apiVersion: v1 kind: Pod metadata: name: "multi-container-pod" namespace: default labels: app: "multi-container-pod" spec: containers: - name: nginx-container image: "nginx" volumeMounts: - name: common-vol mountPath: /usr/share/nginx/html - name: alpine-container image: "alpine" command: ["/bin/sh", "-c", "while true; do sleep 1; date > /app/index.html; done;"] volumeMounts: - name: common-vol mountPath: /app volumes: - name: common-vol emptyDir: {} # docker匿名挂载
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
114、k8s工作负载-Pod的初始化容器
114.1、yaml文件中spec.initContainers的用途说明
所有的初始化容器都必须有终结的时间点,可以短暂运行,但是不能一直运行,比如默认的nginx容器是绝对不能接受的,毕竟它是一直在运行的
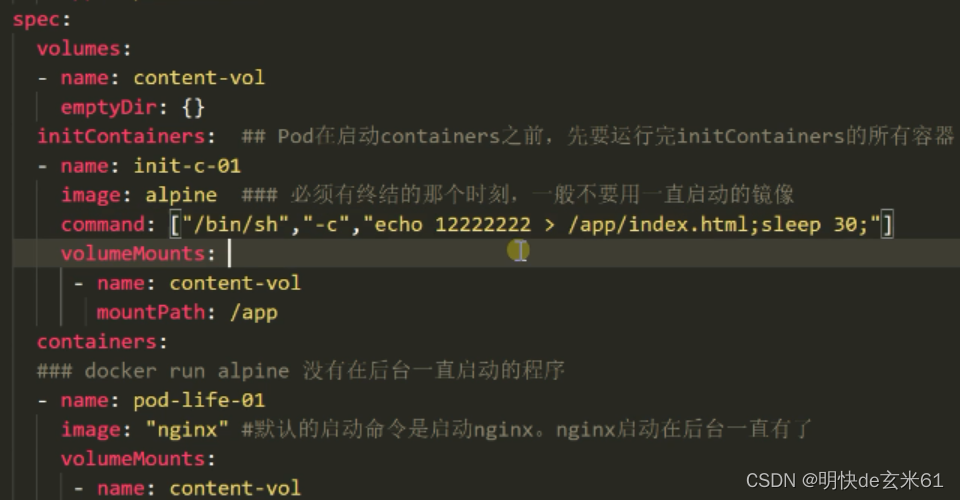
114.2、yaml文件中spec.containers的用途说明
所有的正式容器都需要能启动起来,并且长期运行,一旦无法启动或者停止运行,那么Pod的状态将会是NotReady状态,这样的话Pod将无法为外界提供服务;如果Pod中容器一旦启动失败或者停止运行,那么Pod将会自动重启这些容器
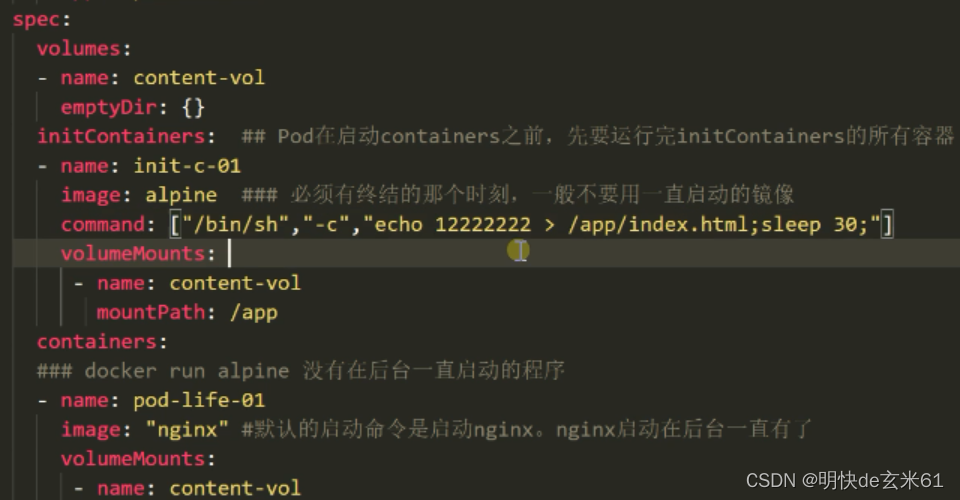
115、k8s工作负载-Pod的生命周期
主要讲述了一个临时容器用于Pod排错的事情,原因是pod的容器中多个命令其实都是不可使用的,甚至ping、curl……等命令都是无法使用的,那我们可以借助于临时容器共享工作容器中的所有资源(网络、存储…),然后在临时容器中操作就相当于在操作Pod中的工作容器一样;
但是目前临时容器还是试用版本,不能正式使用
116、k8s工作负载-临时容器的使用简介
暂时是实验版本,老师也没有演示具体使用,先不学了
117、k8s工作负载-静态Pod
在每一个节点中都存在/etc/kubernetes/manifests位置,只要我们把Pod的yaml文件放在该目录下面,kubelet就会自动拉起该pod,如果我们手动把该pod删除,然后kubelet便会再次拉起该pod,不需要用户手动干预,这就是静态pod
118、k8s工作负载-Pod的探针
118.1、探针分类
说明: kubelet会去检测这些探针
- 启动探针:
- 启动探针不成功就一直保持启动中状态,只有启动成功才能运行存活探针和就绪探针,启动完成之后就不会在运行该探针了
- 存活探针:
- 存活探针不成功就会重新启动这个容器
- 就绪探针:
- 就绪探针决定是否要负载均衡流量到该容器中,不会导致容器重启,如果没就绪,那从外界过来的流量就过不来,比如service负载均衡就无法把流量达到该Pod上
118.2、使用示例
以下就是使用的yaml文件,首先我们执行kubectl apply -f XXX.yaml之后,然后通过kubectl get pod -owide查看pod分配在哪个节点上,想要容器启动成功,那就需要去该节点上新建/app/abc文件,并且想要存活探针、就绪探针都是成功的,那就需要新建/html/abc.html文件
apiVersion: v1 kind: Pod metadata: labels: app: nginx-probe-test name: nginx-probe-test spec: containers: - name: nginx image: nginx # 启动探针 startupProbe: exec: command: ["/bin/sh", "-c", "cat /app/abc"] # 对于exec来说,只要执行不成功(命令执行之后可以通过echo $?返回值来确定成功与否,如果是0那就是成功,否则那就是失败),那就是启动探针没成功,失败之后很长时间不会在重启了 # 以下几个参数在存活探针和就绪探针中都有,不过我们只在此处详细解释 initialDelaySeconds: 5 # 在容器启动之后,并且存活探针初始化之前的延时秒数 periodSeconds: 5 # 每隔几秒运行一次,最小值是1 timeoutSeconds: # 探测超时秒数,最小值是1 successThreshold: 1 # 成功阈值,在失败之后,连续几次成功才算成功,默认值是10,最小值是1 failureThreshold: 5 # 失败阈值,连续几次成功才算成功,默认值是3,最小值是1 # 存活探针 livenessProbe: exec: command: ["/bin/sh", "-c", "cat /usr/share/nginx/html/abc.html"] # 就绪探针 readinessProbe: httpGet: # 访问本容器的话,不要写host,不然会导致接口无法调通 path: /abc.html port: 80 scheme: HTTP volumeMounts: - name: nginx-vol mountPath: /app - name: nginx-html mountPath: /usr/share/nginx/html volumes: - name: nginx-vol hostPath: path: /app - name: nginx-html hostPath: path: /html
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
119、k8s工作负载-XXX
老师没有录这一节
120、k8s工作负载-Deployment-简单编写
120.1、Deployment控制器的作用
当我们执行kubectl apply -f XXX.yaml命令之后,api-server就收到了部署请求,然后就把信息存储到etcd里面,然后controller-manager从etcd中得到了部署请求信息,然后就调用Deployment控制器进行监控,并且把处理过后的部署信息存储到etcd中,然后api-server就让某一节点的kubelet去执行部署操作,当然Deployment控制器的作用是保证部署最终能够达到期望目标,并且始终保证部署维持在期望目标
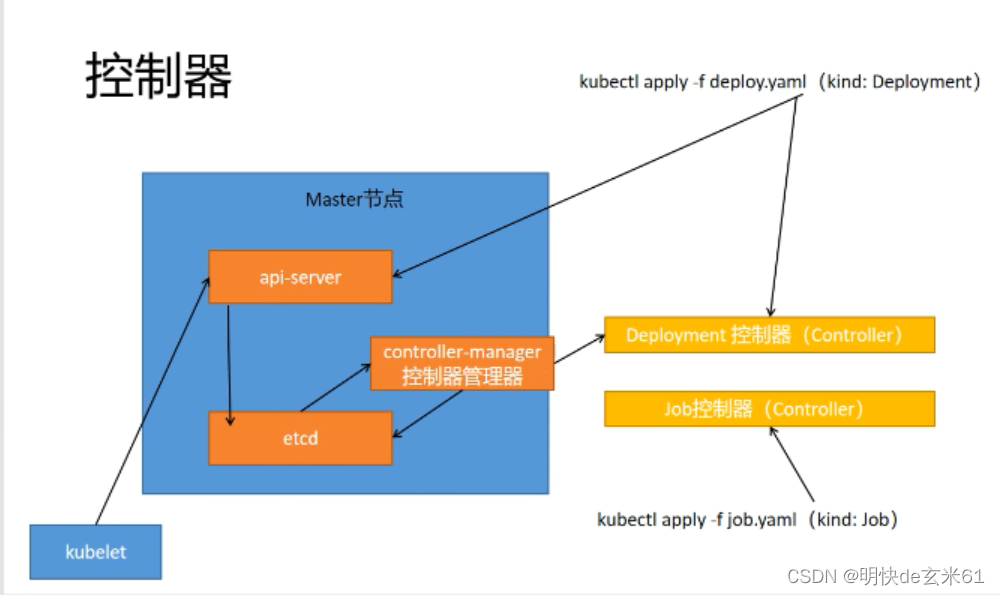
120.2、基础deployment的yaml文件怎么写
下面就是对应的nginx-deployment-test.yaml文件,作用就是部署了一个deployment,其中对应3个pod,我们这样部署之后将会产生deployment、replicaset、pod,其中deployment控制replicaset,而replicaset控制pod的数量,如下图:

apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment-test namespace: default # deployment所属名称空间 labels: app: nginx-deployment-test # deployment的标签,在这里面没啥用 spec: selector: matchLabels: app: nginx-pod-test # 必须和下面pod的labels对应,我们deployment绑定pod就是根据该标签来的 replicas: 3 # pod副本数量,默认值是1,由副本集ReplicaSet控制器实现 template: # 下面就是编写pod内容的位置 metadata: labels: app: nginx-pod-test spec: containers: - name: nginx-pod-test image: nginx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
121、k8s工作负载-Deployment-滚动更新原理01
121.1、镜像滚动升级
其实在前面我们提到过滚动更新,只是当时使用的是纯命令行,但是现在使用的是yaml文件,不过原理都是类似的,举一个场景吧,还以上面的yaml文件为例,我们上面使用的是最新的nginx版本,现在我们想更换nginx版本,比如更换成nginx:1.9.1,那么我们就可以把上述yaml文件中的nginx版本更改之后,在执行kubectl apply -f nginx-deployment-test.yaml即可,此时我们在查看kubectl get all | grep nginx-deployment-test,发现现在多了一个副本集记录,如下图:

如果我们同时观察pod的变更情况,可以看到pod是先启动新的,等新的pod完全启动之后,才会杀死老的pod,反之如果pod不能成功启动,那就无法删除老的pod,保证服务即使在更新失败的情况下依然可以提供良好的服务
现在我们来模拟由于镜像基本错误导致更新失败的情况,现在我们把镜像版本改成nginx:111,那肯定不能正常更新的,我们来看下最新的pod和所有部署信息的情况,如下:
pod情况:
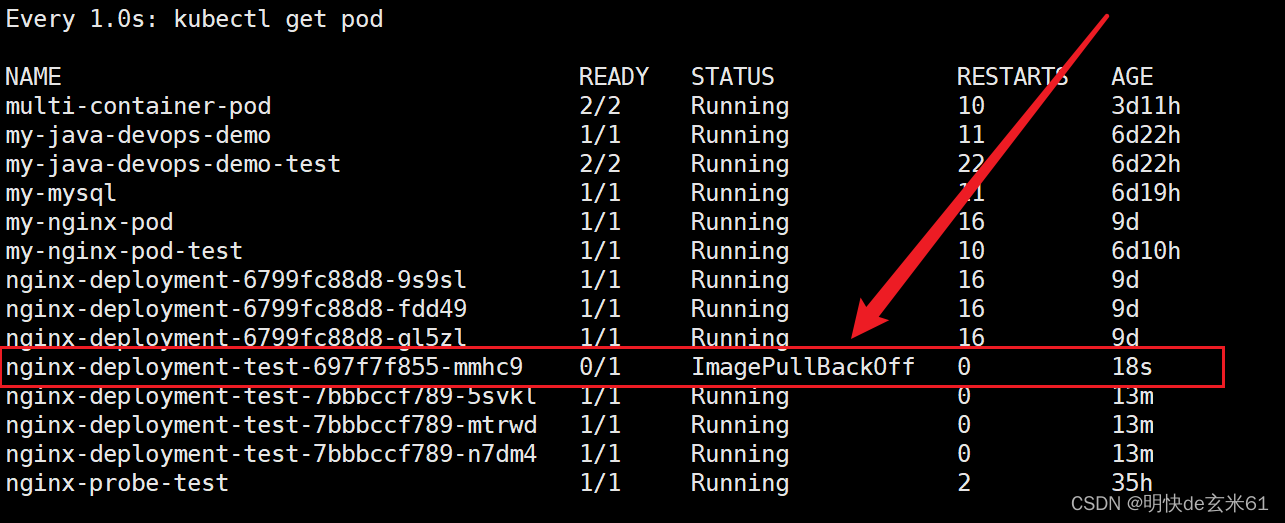
所有部署信息情况:
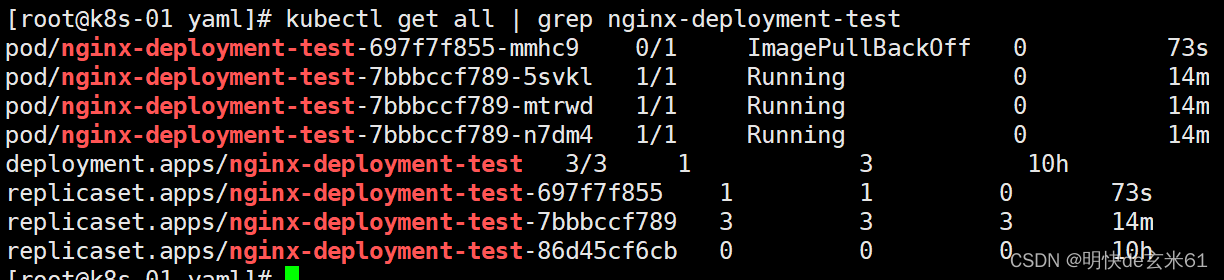
现在可以看到所有部署信息的截图中又多了一个副本集replicaset,并且数量是1 1 0,也就是kubectl当前希望新pod有1个,并且现在就有了1个,但是准备好的是0个,毕竟镜像版本是错误的,没法拉下来嘛
这是一种修改镜像的版本方式,当然也可以是通过kubectl edit deployment.apps/nginx-deployment-test命令进入正在运行的deployment对应的yaml文件中,然后修改对应镜像版本,之后:wq保存就可以进行更新了。另外每一个副本集都对应我们的一种状态,如果我们在将接镜像版本变更回到了之前副本集的版本,那就不会在新创建副本集了,而是会沿用之前的副本集
我们还可以通过通过这种形式来进行镜像的滚动升级,如下:
// deploy是资源类型,第一个nginx是deployment部署名称,第二个nginx代表nginx:latest,也就是原有镜像信息,而nginx:1.9.1代表最新的nginx镜像信息,最后的--record=true代表记录本次变动的命令
// 作用:将nginx部署中的nginx镜像版本从latest更改为1.9.1
kubectl set image deploy nginx nginx=nginx:1.9.1 --record=true
- 1
- 2
- 3
121.2、镜像回滚
在镜像滚动升级出现了问题或者镜像滚动升级的办法不对的时候如何进行回滚呢,这个不要慌,我们现在来说几种办法
- 更改
yaml文件之后,执行kubecl apply -f XXX.yaml,例如:kubectl apply -f nginx-deployment-test.yaml - 更改现在正在运行的资源对应的
yaml,执行kubectl edit 资源类型 资源名称,然后:wq保存退出即可,例如:kubectl edit deployment.apps/nginx-deployment-test - 如果是镜像版本问题,可以直接通过
kubectl set image 资源类型 资源名称 原镜像信息=新镜像信息 --record=true直接更改镜像版本,例如:kubectl set image deploy nginx nginx=nginx:1.9.1 --record=true - 想要回滚动以前的版本,我们先通过
kubectl rollout history 资源类型 资源名称查看资源历史版本,例如:kubectl rollout history deployment.apps/nginx-deployment-test,然后在通过kubectl rollout undo 资源类型 资源名称 --to-revision=版本号命令回滚到以往版本,例如:kubectl rollout undo deploy nginx-deployment-test --to-revision=1
122、k8s工作负载-Deployment-滚动更新暂停与恢复等
122.1、历史资源版本(旧副本集)数量限制revisionHistoryLimit
默认情况下可以保留15个历史资源版本,不过可以通过revisionHistoryLimit参数去设置,如下:
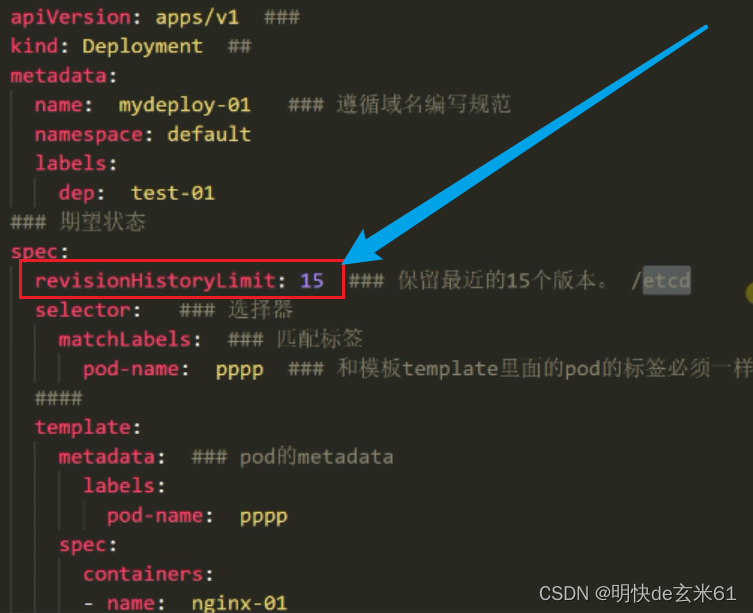
我们公司中设置最多10个历史版本
122.2、最大部署时间(单位:秒)限制progressDeadlineSeconds(一般不设置)
这个时间默认是600s,如果600s之后还没有部署成功,那就是出现问题了,kubelet也会报告问题,这个值不建议设置的太小
122.3、部署启动之后先暂停paused(没啥大用)
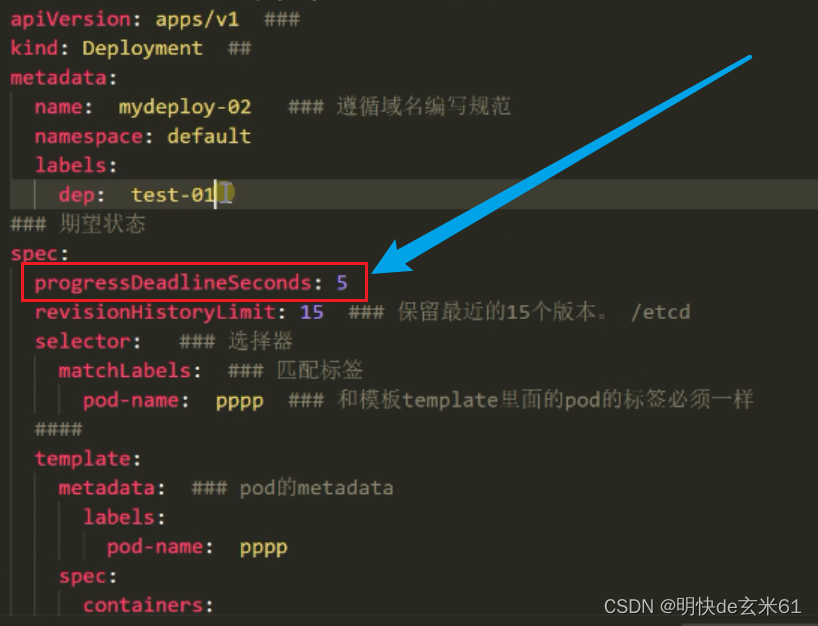
也就是下面的paused属性,默认值是false,如果我们这样设置,然后在启动之后只会创建一个deployment部署,并且状态是0/3,不会产生ReplicaSet副本集,更不会产生Pod,如果需要产生ReplicaSet副本集和Pod,那就需要恢复启动状态了,脚本是kubectl rollout resume 资源类型 资源名称,例如:kubectl rollout resume deployment.apps/nginx-deployment-test
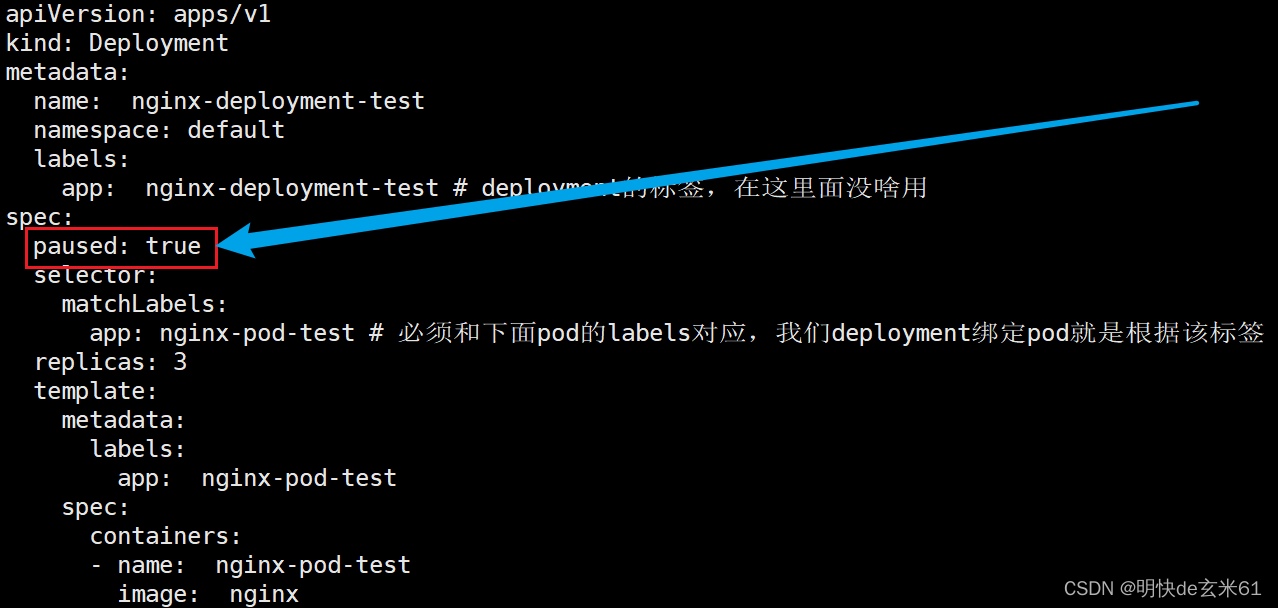
如果大家想要现在正在运行的deployment部署暂停,脚本是kubectl rollout pause 资源类型 资源名称,例如:kubectl rollout pause deployment.apps/nginx-deployment-test,但是我没有看出来有啥变化
122.4、Pod启动之后,被认为准备就绪的秒数minReadySeconds(没啥大用)
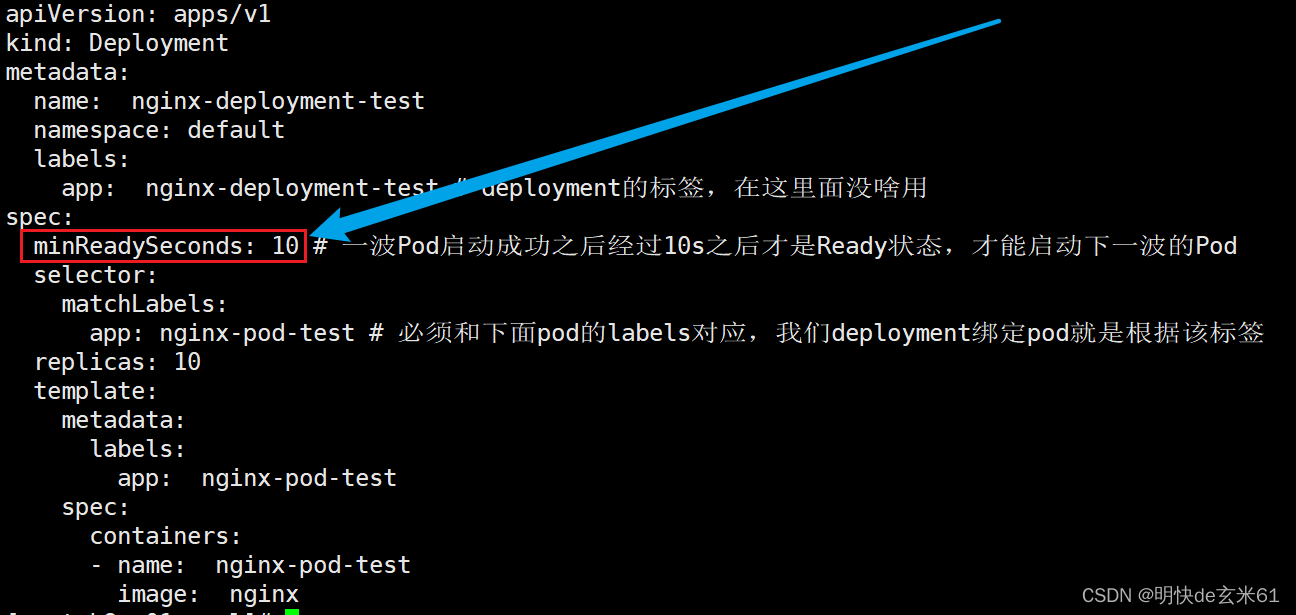
就是下面的minReadySeconds,默认值是0,也就是pod一准备就绪即视为可用,而添加该参数之后,就代表该pod准备就绪之后经过该秒数之后才被认为是准备就绪,只有准备就绪的pod后期才会把流量分到它上面
123、k8s工作负载-Deployment-按比例缩放的滚动更新
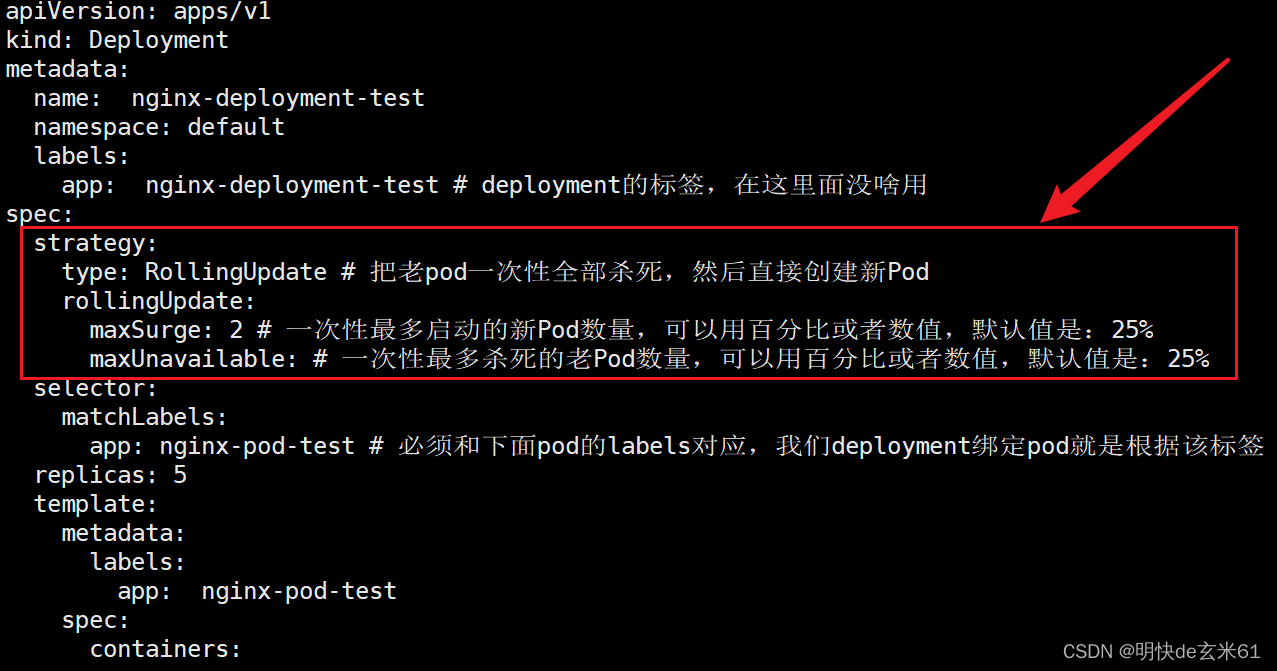
123.1、更新策略strategy(一般不用)
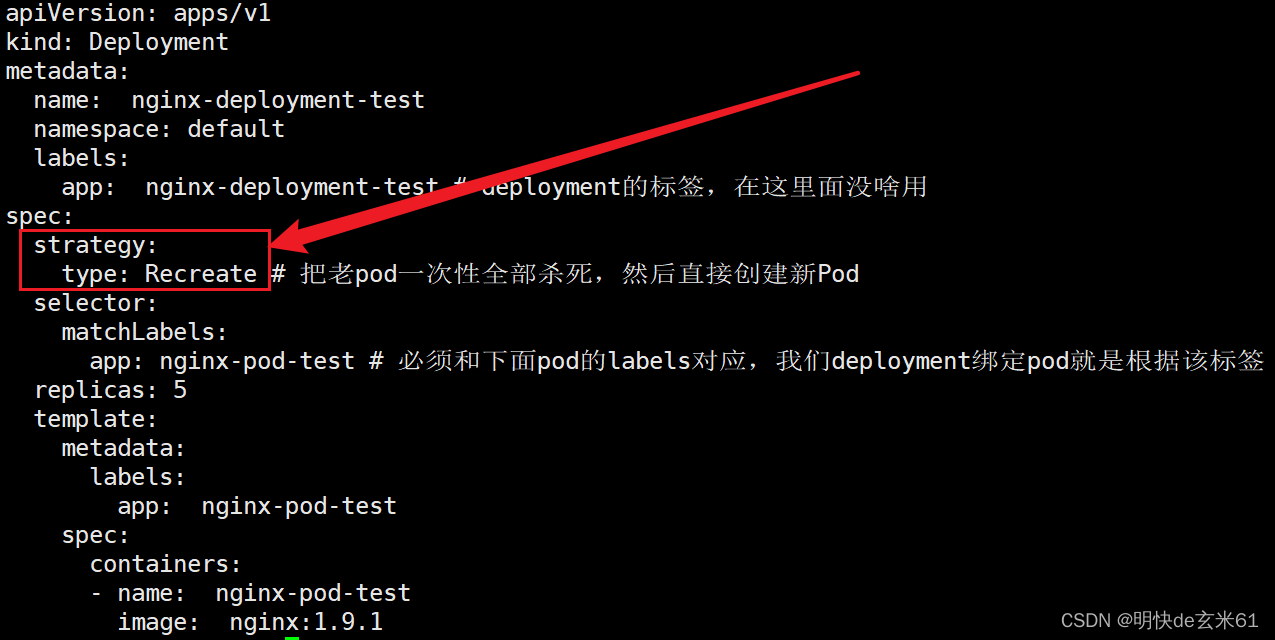
默认存在两种更新策略,分别是Recreate和RollingUpdate,默认使用RollingUpdate可以达到滚动更新的效果,现在一个一个来聊
Recreate举例:
说明:这种策略会将老的pod全部一次性杀死,然后在把所有新pod启起来
RollingUpdate举例:
说明:滚动更新是默认策略,一般情况下我们不需要去调整该比例
124、k8s工作负载-Deployment安装metrics-server
124.1、安装metrics-server
镜像导入:
直接使用docker load -i 镜像tar包名称即可导入,镜像在下面
链接:https://pan.baidu.com/s/1Ploa1i1VVcZUC-rpc4ZAew?pwd=wmla
提取码:wmla
metrics-server.yaml:
使用kubectl apply -f metrics-server.yaml命令执行以下yaml即可
apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server rbac.authorization.k8s.io/aggregate-to-admin: "true" rbac.authorization.k8s.io/aggregate-to-edit: "true" rbac.authorization.k8s.io/aggregate-to-view: "true" name: system:aggregated-metrics-reader rules: - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server name: system:metrics-server rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats - namespaces - configmaps verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: system:metrics-server roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-server subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: v1 kind: Service metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: ports: - name: https port: 443 protocol: TCP targetPort: https selector: k8s-app: metrics-server --- apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: selector: matchLabels: k8s-app: metrics-server strategy: rollingUpdate: maxUnavailable: 0 template: metadata: labels: k8s-app: metrics-server spec: containers: - args: - --cert-dir=/tmp - --kubelet-insecure-tls # 避免安全认证,少去很多麻烦,来自https://github.com/kubernetes-sigs/metrics-server#configuration - --secure-port=4443 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port image: metrics-server:v0.4.3 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /livez port: https scheme: HTTPS periodSeconds: 10 name: metrics-server ports: - containerPort: 4443 name: https protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: https scheme: HTTPS periodSeconds: 10 securityContext: readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 volumeMounts: - mountPath: /tmp name: tmp-dir nodeSelector: kubernetes.io/os: linux priorityClassName: system-cluster-critical serviceAccountName: metrics-server volumes: - emptyDir: {} name: tmp-dir --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: labels: k8s-app: metrics-server name: v1beta1.metrics.k8s.io spec: group: metrics.k8s.io groupPriorityMinimum: 100 insecureSkipTLSVerify: true service: name: metrics-server namespace: kube-system version: v1beta1 versionPriority: 100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
124.2、用命令行方式使用metrics-server
- kubectl top node:查看node节点占用CPU、内存信息
- kubectl top pod:查看pod占用CPU、内存信息
124.3、在k8s-dashboard中使用metrics-server
125、k8s工作负载-Deployment-HPA(自动动态扩缩容)
125.1、动态扩缩容概念
我们上面大多数讲的都是滚动更新,但是没有提到动态更新的事情,其实动态更新就是在Pod不够用(CPU占用过高)的时候就去新启动一些Pod,如果Pod够用了,那就在把多余的Pod删除掉,这都是自动完成的过程,这叫做自动动态扩缩容
125.2、文档地址
https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough
124.3、使用前提
安装 Metrics Server ,我们在上面已经完成了

125.4、测试自动动态扩缩容功能
125.4.1、运行 php-apache 服务器并暴露服务
来源:
yaml:
执行的命令是kubectl apply -f php-apache.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: php-apache spec: selector: matchLabels: run: php-apache replicas: 1 template: metadata: labels: run: php-apache spec: containers: - name: php-apache image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/php-hpa:latest ports: - containerPort: 80 resources: limits: cpu: 500m requests: cpu: 200m --- apiVersion: v1 kind: Service metadata: name: php-apache labels: run: php-apache spec: ports: - port: 80 selector: run: php-apache
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
125.4.2、创建 自动扩缩容 控制器
来源:
yaml:
执行的命令是kubectl apply -f hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache # 自动扩缩容资源自己的标签名,暂时没啥用
spec:
maxReplicas: 10 # 扩容最大副本数
minReplicas: 1 # 缩容最小副本数
scaleTargetRef:
apiVersion: apps/v1 # 资源版本
kind: Deployment # 资源类型
name: php-apache # 资源名称
targetCPUUtilizationPercentage: 50 # Pod的CPU占用率超过这个比率就去扩容Pod
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
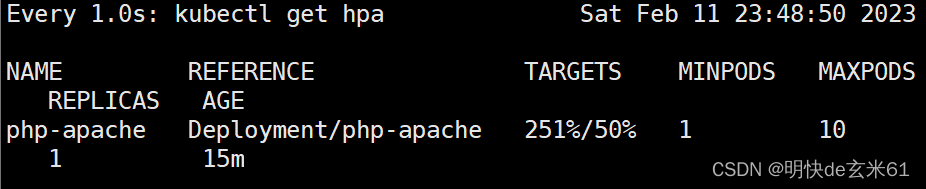
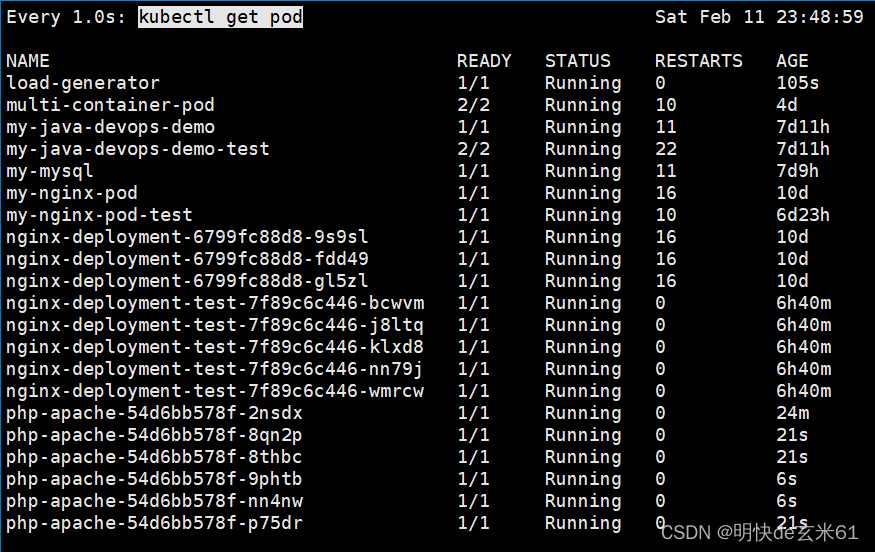
125.4.3、测试 自动扩缩容 能力
来源:
观察命令:
-
watch -n 1 kubectl get hpa:查看占用CPU总比率
-
watch -n 1 kubectl get pod:查看pod扩容情况
测试命令:
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
- 1
命令执行之后稍微等待一段时间,就可以通过watch -n 1 kubectl get hpa命令看到CPU占用率明显升高,然后通过watch -n 1 kubectl get pod命令看到pod的数量变化
如果我们此时在上述测试命令后面使用Ctrl+C按钮截止了,那CPU占用肯定减少了,不过pod的数量减少效果需要等好一会才能看出来
126、k8s工作负载-Deployment-灰度发布原理
127、k8s工作负载-Deployment-金丝雀的案例
128、k8s工作负载-Deployment-最后问题解决
129、k8s工作负载-Deployment-Deployment总结
129.1、滚动更新、蓝绿部署、金丝雀部署
- 滚动更新::简单方便好操作,默认自带。几分钟就搞完了,很快从一个版本切换到另外一个版本了,之前那个版本的就停止了
- 蓝绿部署:两个版本同时存在,新版本(蓝版本)好了之后直接将全部流量都切换到蓝版本,然后等蓝版本运行稳定之后就把老版本(绿版本)杀死。比如蓝绿版本都可以使用Deployment控制Pod的方式,并且蓝绿版本的Pod标签要有区别,用以帮助service选择某一版本,例如蓝版本的标签是version=2,而绿版本的标签是version=1,所以service对Pod选择的标签就可以使用version=2,这就可以将全部流量切换到蓝版本了
- 金丝雀部署:两个版本同时存在,新老版本一起运行,如果运行一段时间发现没啥问题,那就停掉老版本。比如新老版本都可以使用Deployment控制Pod的方式,并且新老版本的Pod标签有相同的地方,也有有区别的地方,比如老版本是app=nginx-test,version=1,而新版本是app=nginx-test,version=2,那service对Pod选择的标签就可以使用app=nginx-test,然后就可以达到新老版本同时工作的状态
129.2、金丝雀部署示例
前提:
直接使用docker load -i 镜像tar包名称即可导入,镜像在下面
链接:https://pan.baidu.com/s/1CBOrbuTBBJSa15xl7lMlsQ?pwd=kqgx
提取码:kqgx
说明:
只需要把下面3个yaml文件都使用kubectl apply -f XXX.yaml命令执行,然后直接在浏览器上访问http://虚拟机ip:31666/就能看到不同的效果,因为老版本输出111111111,而新版本输出nginx默认页面,这样达到了service的流量可以分配到新老版本Pod的目的
yaml文件:
k8s-canary-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: canary-service-test # 目前没啥用
namespace: default
spec:
selector:
app: canary-nginx-test # 新老版本都有这个标签,所以可以把service可以把流量分配给新老版本的pod
type: NodePort ### 可以直接在浏览器上访问
ports:
- name: canary-service-test
port: 80 ### service端口,对应tarPort
targetPort: 80 ### Pod的访问端口
protocol: TCP
nodePort: 31666 ### 浏览器访问的端口,对应port,所以在浏览器上访问的时候,可以通过nodePort(浏览器)》por(service)》targetPort(Pod)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
k8s-canary-deploy1.yaml(老版本):
apiVersion: apps/v1 kind: Deployment metadata: name: canary-deployment-test-v1 namespace: default labels: app: canary-deployment-test-v1 # 目前没啥用 spec: selector: matchLabels: # 使用这两个标签可以控制下面的pod app: canary-nginx-test version: v1 replicas: 1 template: metadata: labels: app: canary-nginx-test # 和老版本相同 version: v1 # 和老版本不同 spec: containers: - name: nginx-test image: nginx-test:env-msg
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
k8s-canary-deploy2.yaml(新版本):
apiVersion: apps/v1 kind: Deployment metadata: name: canary-deployment-test-v2 namespace: default labels: app: canary-deployment-test-v2 # 目前没啥用 spec: selector: matchLabels: # 使用这两个标签可以控制下面的pod app: canary-nginx-test version: v2 replicas: 1 template: metadata: labels: app: canary-nginx-test # 和老版本相同 version: v2 # 和老版本不同 spec: containers: - name: nginx image: nginx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
129.3、如何查看kubectl describe展示的描述信息
无论是查看pod、deployment、service、node,其实里面的信息都是类似的,一般都会说明资源的基本信息、当前状态、相关事件,当资源出现问题的时候还会告诉你问题是什么,所以在辅助我们排查的时候很有帮助,这里就简单举个Pod为nginx的例子吧,分析截图如下:
Name: my-nginx-pod-test # Pod名称 Namespace: default # 名称空间 Priority: 0 # 优先级 Node: k8s-02/192.168.139.134 # 节点信息,ip也是节点的ip Start Time: Sun, 05 Feb 2023 00:16:11 +0800 Labels: image-version=1.9.1 # Pod标签,用作筛选 type=pod Annotations: cni.projectcalico.org/containerID: bb64363d1f1b5008b8ea9ed5631fdd3ccb8f4afd646ba359867af3174d034af6 cni.projectcalico.org/podIP: 10.101.179.7/32 cni.projectcalico.org/podIPs: 10.101.179.7/32 # 注解信息,作用比较大 Status: Running # 当前状态 IP: 10.101.179.7 # Pod的ip IPs: IP: 10.101.179.7 # Pod的ip Containers: my-nginx-container-test: Container ID: docker://5ce48ea1f133654241bb106bb20cf1e69ff4342e23394dca00dbc2f7b6c85d8d Image: nginx:1.9.1 # 镜像版本 Image ID: docker-pullable://nginx@sha256:2f68b99bc0d6d25d0c56876b924ec20418544ff28e1fb89a4c27679a40da811b Port: <none> Host Port: <none> State: Running Started: Sun, 12 Feb 2023 19:15:44 +0800 Last State: Terminated Reason: Completed Exit Code: 0 Started: Sun, 12 Feb 2023 11:32:15 +0800 Finished: Sun, 12 Feb 2023 16:28:50 +0800 Ready: True Restart Count: 12 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-k85ld (ro) Conditions: Type Status Initialized True # 初始化完成 Ready True # 准备完成 ContainersReady True # 容器准备完成 PodScheduled True Volumes: kube-api-access-k85ld: Type: Projected (a volume that contains injected data from multiple sources) TokenExpirationSeconds: 3607 ConfigMapName: kube-root-ca.crt ConfigMapOptional: <nil> DownwardAPI: true QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s node.kubernetes.io/unreachable:NoExecute op=Exists for 300s Events: <none>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
130、k8s工作负载-RC、RS的区别
130.1、RC、RS、Deployment的区别
- RC:ReplicaSController,副本集控制器,这是老版,一般不用
- RS:ReplicasSet,副本集,这是新版,一般不直接用
- Deployment:部署,自动生成RS,常用
130.2、RS副本集的高级条件选择用法
130.2.1、复习deploy.spec.selector.matchLabels选择器
用来选择Pod,可以设置一个或者多个标签键和值,例如:
apiVersion: apps/v1 #与k8s集群版本有关,使用 kubectl api-versions 即可查看当前集群支持的版本 kind: Deployment #该配置的类型,我们使用的是 Deployment metadata: #译名为元数据,即 Deployment 的一些基本属性和信息 name: nginx-deployment #Deployment 的名称 labels: #标签,可以灵活定位一个或多个资源,其中key和value均可自定义,可以定义多组,目前不需要理解 app: nginx #为该Deployment设置key为app,value为nginx的标签 spec: #这是关于该Deployment的描述,可以理解为你期待该Deployment在k8s中如何使用 replicas: 1 #使用该Deployment创建一个应用程序实例 selector: #标签选择器,与上面的标签共同作用,目前不需要理解 matchLabels: #选择包含标签app:nginx的资源 app: nginx template: #这是选择或创建的Pod的模板 metadata: #Pod的元数据 labels: #Pod的标签,上面的selector即选择包含标签app:nginx的Pod app: nginx spec: #期望Pod实现的功能(即在pod中部署) containers: #生成container,与docker中的container是同一种 - name: nginx #container的名称 image: nginx:1.7.9 #使用镜像nginx:1.7.9创建container,该container默认80端口可访问
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
130.2.2、学习deploy.spec.selector.matchExpressions选择器
注意: 该属性不能和matchLabels一起使用,避免造成冲突
使用说明:
可以设置3个子属性,分别是key(必须)、operator(必须)、values(非必须)
- key:标签名称
- operator:可选值是In(标签名称对应值在values中即可)、 NotIn(标签名称对应值不在values中即可)、Exists(标签名称存在即可,不要求值) 、DoesNotExist(标签名称不存在即可)
- values:可以写单个值(例如:“a”),也可以写成数组的形式(例如:[“a”, “b”])
举例:

131、k8s工作负载-DamonSet-让每个节点都部署一个指定Pod
131.1、DamonSet用途
可以为集群中所有节点(不包含master,因为master节点含有污点)都部署一个Pod。并且集群中新加入的节点中也会自动部署一个Pod,将节点从该集群中移除之后,由于DamonSet部署的Pod也会自动移除。删除创建DamonSet资源之后,所有相关Pod都将被删除
131.2、DamonSet和Deployment比较
用法基本一致,只是DamonSet不能指定副本数量,毕竟它可以为集群中的所有节点(不包含master,因为master节点含有污点)都部署一个Pod(有且仅有一个),所以既不能指定,也不用指定
131.3、DamonSet使用场景
- 在每个节点上运行集群的存储守护进程,例如 glusterd、ceph
- 在每个节点上运行日志收集守护进程,例如 fluentd、logstash
- 在每个节点上运行监控守护进程,例如 Prometheus Node Exporter、Sysdig Agent、collectd、Dynatrace OneAgent、APPDynamics Agent、Datadog agent、New Relic agent、Gangliagmond、Instana Agent 等
131.4、示例yaml
效果:每一个节点(不包含master,因为master节点含有污点)中都有且仅有一个pod
apiVersion: apps/v1 kind: DaemonSet metadata: name: daemonset-test namespace: default labels: app: daemonset-test spec: selector: matchLabels: app: daemonset-test template: metadata: labels: app: daemonset-test spec: containers: - name: daemonset-test image: nginx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
132、k8s工作负载-StatefulSet-什么是有状态应用
- 无状态应用:Deployment部署的应用一般是无状态应用。无状态应用的网络、存储都可能会变,并且Pod部署的名称也是无序的。业务代码服务一般是无状态应用
- 有状态应用:StatefulSet部署的应用一般是有状态应用。有状态应用的网络、存储都不会变,并且Pod部署的名称也是有序的。中间件(比如Mysql、Redis……)一般是有状态应用
133、k8s工作负载-StatefulSet-示例
133.1、概述图片
service下面对应StatefulSet,StatefulSet下面连接Pod,如果StatefulSet的serviceName对应service的name,并且service的ClusterIP是None(即ClusterIP不对应内容,那service就成为了无头服务),这样我们可以通过Pod名称.service名称.名称空间名称的方式来访问pod,当然也可以省略名称空间,默认是default嘛,如果直接访问service名称来负责均衡访问Pod也是可以的
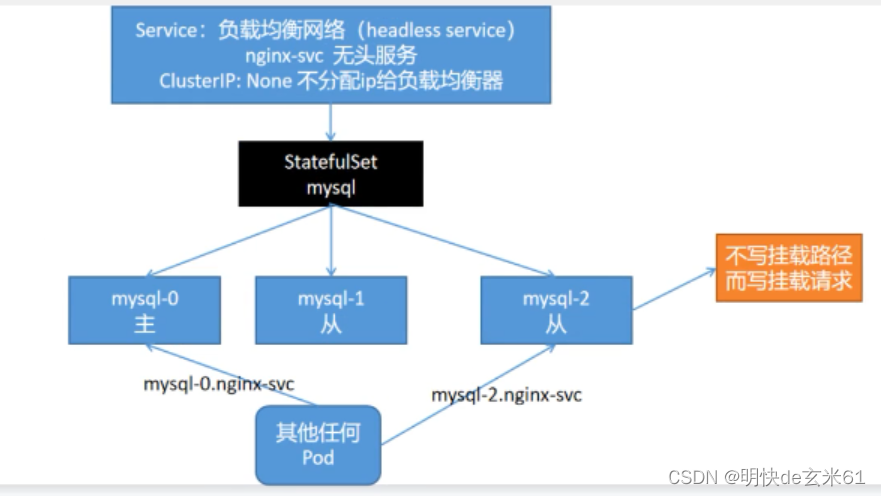
133.2、示例
通过DNSS解析访问Pod的3步全部都在下面(测试发现第2步不是必须的),我们可以进入另外一个容器内部,然后通过curl statefulset-test-0.statefulset-service-test方式访问部署的pod,当然也可以通过curl statefulset-service-test方式来负责均衡访问Pod
apiVersion: apps/v1 kind: StatefulSet metadata: name: statefulset-test namespace: default spec: selector: matchLabels: app: statefulset-test # 和下面spec.template.metadata.labels一一对应 serviceName: "statefulset-service-test" # 3、设置serviceName是和service中metadata.name的值一致(通过DNS解析访问Pod第3步) replicas: 3 template: metadata: labels: app: statefulset-test # 和上面spec.selector.matchLabels一一对应 spec: containers: - name: nginx image: nginx --- apiVersion: v1 kind: Service metadata: name: statefulset-service-test namespace: default spec: selector: app: statefulset-test # 和上面deployment中的Pod的标签对应 type: ClusterIP # 1、设置type是ClusterIP(通过DNSS解析访问Pod第1步) clusterIP: None # 2、设置ClusterIP是None(通过DNSS解析访问Pod第2步) ports: - name: http protocol: TCP port: 80 targetPort: 80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
134、k8s工作负载-StatefulSet-分区更新机制
134.1、Pod管理策略
- OrderedReady:默认值,有序创建,也就是先启动第一个Pod,然后依次启动第2、第3……个Pod
- Parallel:并发创建,一般不用,原因是会破坏有序性,它是让所有Pod一起创建
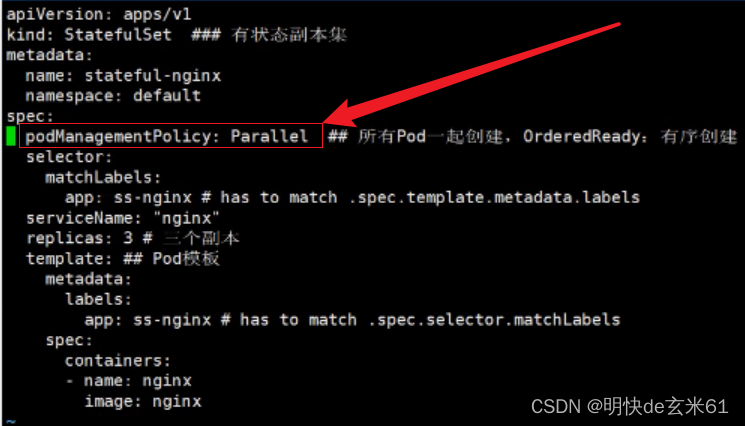
134.2、更新策略
主要介绍一下分区升级,和滚动升级不一样,它可以按照要求去升级部分Pod,它将更新Pod索引大于等于相应区块的Pod
比如下面红框中的内容,Pod原有下标大于等于分区号2的才会在执行kubectl apply -f XXX.yaml之后被更新,其他Pod不会更新
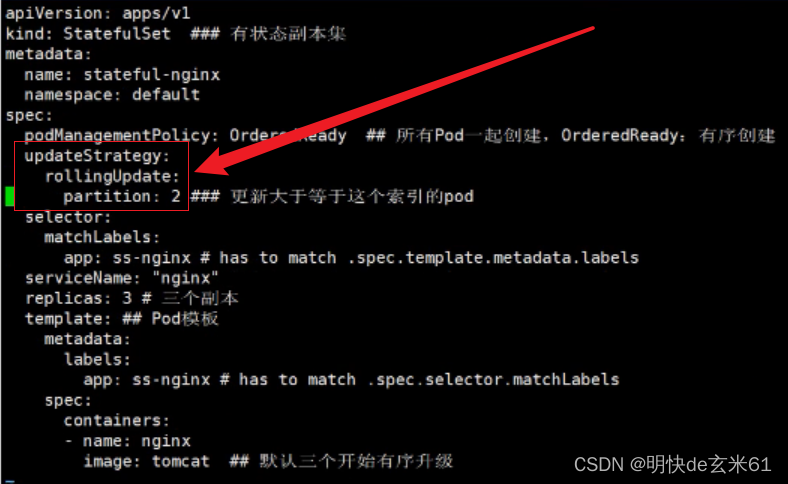
对于Pod原有下标的解释,比如我们部署了一个名称叫做statefulset-test的有状态服务,里面有3个Pod副本,那下标如下所示:

135、k8s工作负载-Job
直接把yaml文件列出来吧,大多数属性的使用都在里面说明了
属性详细解释版yaml:
apiVersion: batch/v1 kind: Job metadata: name: job-test namespace: default labels: app: job-test spec: activeDeadlineSeconds: 600 # 存活到期时间,一旦到期之后Job中的所有Pod都会被强制终止,单位:s backoffLimit: 4 # 标记Job失败之前的重试次数,默认值是6 parallelism: 2 # 并行运行的pod数量,默认按照次序运行,也就是第1个运行结束,才运行第2个 completions: 4 # 4次都成功才算成功,默认是1 ttlSecondsAfterFinished: 5 # Job完成之后删除该Job的倒计时时间,单位:s template: metadata: name: job-test labels: app: job-test spec: restartPolicy: Never # 重启策略:不重启 containers: - name: job-test image: busybox command: ['/bin/sh', '-c', 'ping -c 4 www.baidu.com'] # 镜像+执行指令必须能够结束,因为任务必须结束
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
简化版yaml:
apiVersion: batch/v1 kind: Job metadata: name: job-test namespace: default labels: app: job-test spec: template: metadata: name: job-test labels: app: job-test spec: restartPolicy: Never # 重启策略:不重启 containers: - name: job-test image: busybox command: ['/bin/sh', '-c', 'ping -c 4 www.baidu.com'] # 镜像+执行指令必须能够结束,因为任务必须结束
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
注意点:
- 镜像+命令一定要是能够执行完成的,不能使用阻塞式的,否则任务无法完成
136、k8s工作负载-定时任务
注意事项:
必须谨慎操作,如果产生Pod过多,将导致新pod中的容器出现ContainersNotReady containers with unready status情况,这时候就必须删除定时任务,否则很多Pod无法正常运行
属性详细解释版yaml:
apiVersion: batch/v1 kind: CronJob metadata: name: cronjob-test namespace: default spec: schedule: "*/1 * * * *" # cron表达式,五个级别按照顺序依次是分、时、日、月、周,这个代表每一分钟执行一次 # 并发策略 # Allow:允许,也是默认级别(说明:允许并发执行,即任务1没执行完成,但是根据cron表达式需要执行任务2,那么任务2也可以执行,多个任务并发执行) # Forbid:禁止(说明:如果任务1没执行完成,但是根据cron表达式需要执行任务2,那就不执行任务2了,继续执行任务1) # Replace:替换(说明:如果任务1没执行完成,但是根据cron表达式需要执行任务2,那就停止任务1,并且开始执行任务2) concurrencyPolicy: "Allow" successfulJobsHistoryLimit: 3 # 执行成功记录次数,默认值是3 failedJobsHistoryLimit: 3 # 执行失败记录次数,默认值是1,后期可以分析失败的原因 startingDeadlineSeconds: 600 # TODO 启动截止秒数,没看太懂,后续在补充吧 suspend: false # 暂停定时任务,默认是false;对已经执行了的任务,不会生效。作用是我需要排查问题的时候,不想让定时任务执行,那就先把定时任务暂停下 jobTemplate: # 下面都是job的内容,这里不再详细解释,详细属性解释请看上一节 spec: template: spec: containers: - name: cronjob-test image: busybox args: ['/bin/sh', '-c', 'date; echo Hello from the Kubernetes cluster'] restartPolicy: OnFailure
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
简化版yaml:
apiVersion: batch/v1 kind: CronJob metadata: name: cronjob-test namespace: default spec: schedule: "*/1 * * * *" # cron表达式,五个级别按照顺序依次是分、时、日、月、周,这个代表每一分钟执行一次 jobTemplate: # 下面都是job的内容,这里不再详细解释,详细属性解释请看上一节 spec: template: spec: containers: - name: cronjob-test image: busybox args: ['/bin/sh', '-c', 'date; echo Hello from the Kubernetes cluster'] restartPolicy: OnFailure
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
137、k8s工作负载-垃圾回收简单了解
137.1、级联删除
默认是级联删除的,也就是设置–cascade的值,如果为true的时候就是级联删除,反之就不是级联删除
我们举个不级联删除的例子,如下:
# 删除副本集,但不删除级联的Pod
kubectl delete replicaset my-repset --cascade=false
- 1
- 2
137.2、垃圾回收器介绍
Kubernetes garbage collector(垃圾回收器)的作用是删除那些曾经有 owner,后来又不再有 owner 的对象。比如我们上面不级联删除之后的Pod就是这种对象,该特性在v1.12版本还是实现阶段,默认关闭,需要手动开启,一般用不到
138、k8s工作负载-Service、Pod端口
139、k8s网络-ClusterIP与NodePort类型的Service
139.1、网络互通
- Pod中的容器互通:通过本地回路(loopback)通信。
- Pod和Pod互通:集群网络在不同 pod 之间提供通信
- Service和Pod互通:Service 资源允许你对外暴露 Pod 中运行的应用程序,以支持来自于集群外部的访问
- 外部和Service要通:可以使用 Services 来发布仅供集群内部使用的服务
k8s网络架构图如下:
拓展: 可以在pod中通过service名称去访问service
139.2、service的type
139.2.1、普通ClusterIP
分析:
普通ClusterIP这种类型拥有IP,并且只能在集群内部访问,不能在浏览器上访问。默认是随机IP,不过可以指定访问IP。另外再说一下它的IP来源,来自于我们搭建K8s时的--pod-network-cidr=pod地址区间
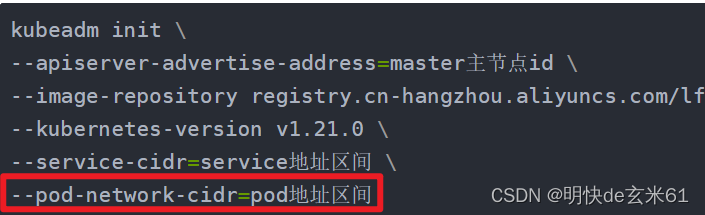
随机IP举例(默认):
指定IP举例:
IP来源,来自于我们搭建K8s时的--pod-network-cidr=pod地址区间
139.2.2、无头ClusterIP
无头ClusterIP这种类型不会分配到IP,只能在资源内部(比如Pod)通过service名称这种形式访问,当然之前说的针对无头服务可以通过pod名称.service名称.名称空间方式在资源内部访问pod
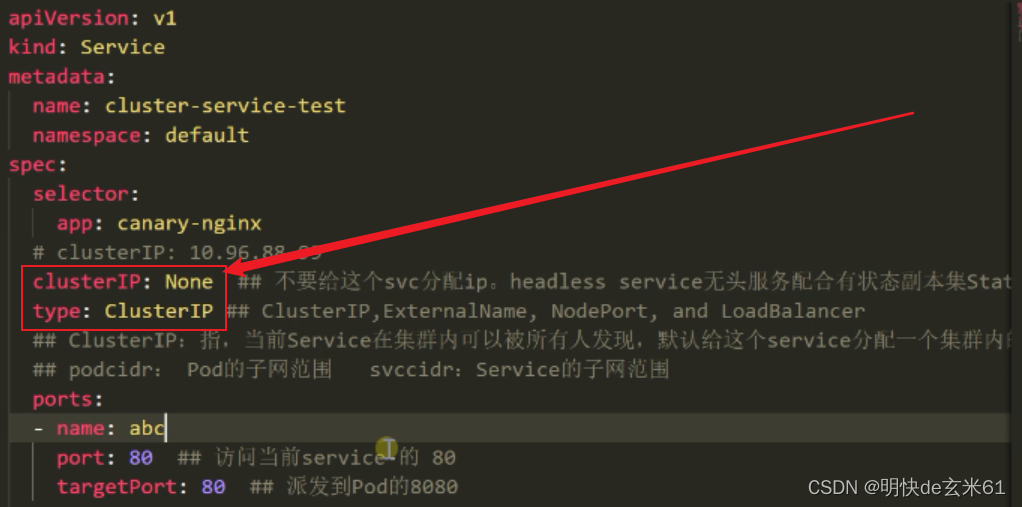
139.2.3、NodePort
NodePort这种方式可以在浏览器上访问,并且可以指定浏览器上的访问端口
随机端口举例(默认):
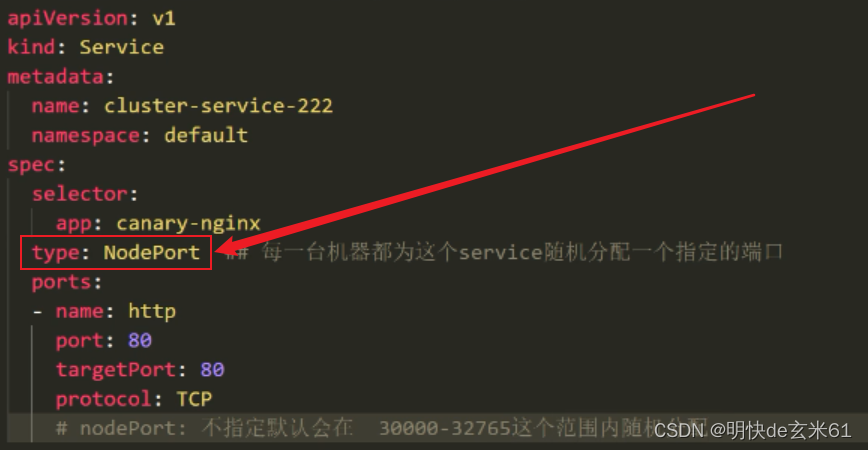
指定端口举例:
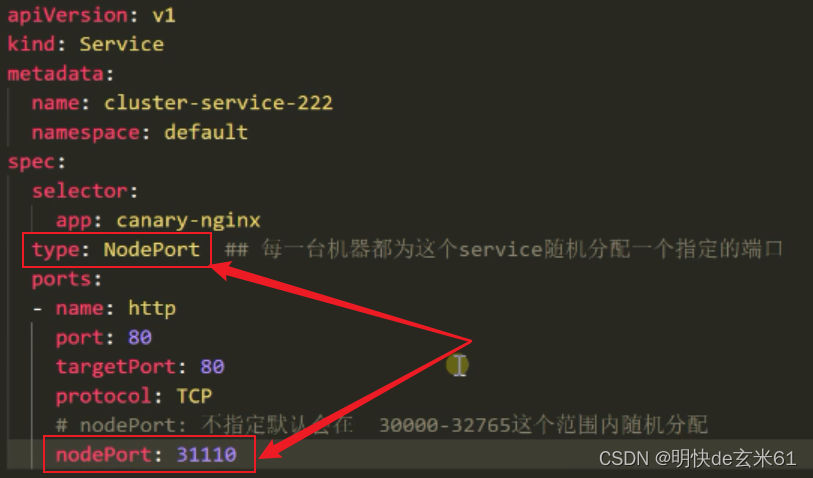
139.3、service和pod端口对应关系
- 金标准:只要有IP相同,那它就相当于一台虚拟机,那它的端口就可以和别的资源相同,比如service、pod等
- 同一个IP,也就是说同一个资源,那它里面的端口不能相同,比如Pod中容器的端口不能相同,Service的暴露的访问端口不能相同
- 无论是ClusterIP还是NodePort,其中port对应service的端口,targetPort对应Pod端口,也对应容器端口containerPort,nodePort对应真正虚拟机的端口,也就是可以在浏览器上访问的端口
139.4、访问集群中任何一个节点的nodePort端口都能访问成功的原因
我们把nodePort暴露出去,那集群中所有节点中的kube-proxy都会监听该端口,只要我们向任何一个节点发送请求,都会回到同样的返回值,在所有节点中都可以查看端口监听情况,如下:

140、k8s网络-Service与EndPoint原理
140.1、Service、EndPoint、Pod关系
从下图中可以看出,我们service其实访问的是EndPoint,然后EndPoint访问Pod,所以EndPoint相当于中间人
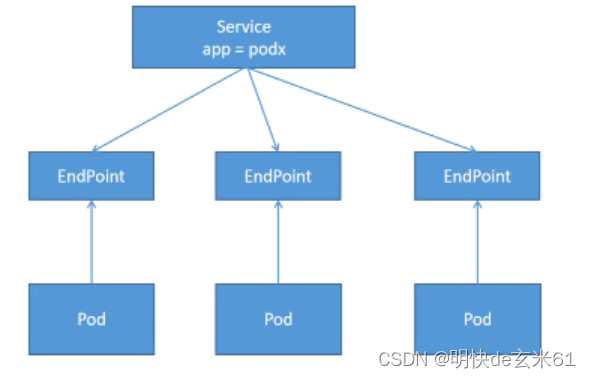
140.2、EndPoint的用途
假设我们多台Mysql部署在其他Ip的多台机器上,然后我们想统一访问这些Mysql,那我们可以只用访问service就可以了,然后service访问endpoint,endpoint指代到那些mysql
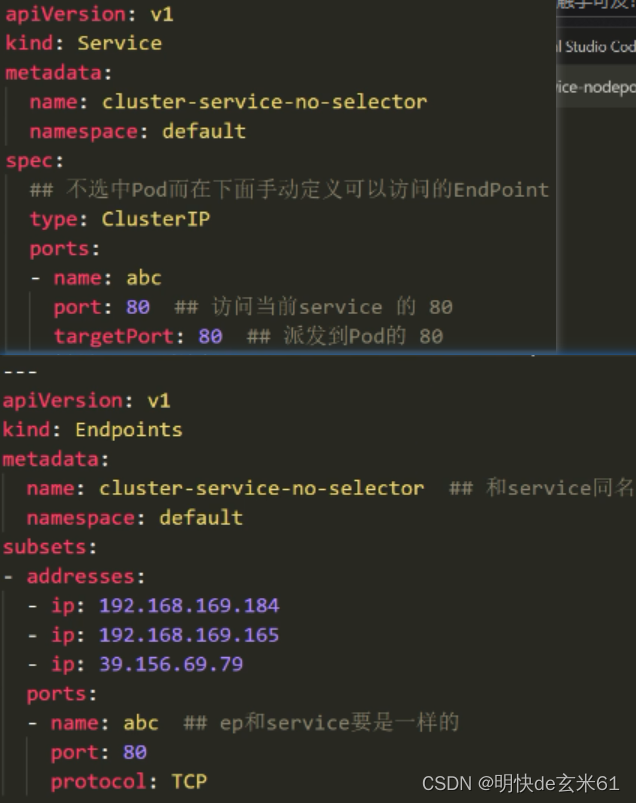
可以看到在定义service的时候并没有使用标签方式去选择Pod,下面EndPoints中的addresses中定义的就是Mysql的地址,然后注意service和endpoint中ports的name属性值要一致
141、k8s网络-Service所有字段解析_1
142、k8s网络-Service的会话保持技术_1
142.1、访问service说明
- service有IP:那在任意位置都可以使用IP访问,当然在节点中可以使用service的IP去访问,而对于NodePort类型的service,那就可以在浏览器上通过节点IP和暴露端口去访问了;
当然无论service是否有IP,在k8s内部都是可以使用service名称.名称空间方式来访问的,详细来说就是针对同一个名称空间这种情况,在k8s内部直接使用service名称进行访问。针对不同名称空间这种情况,在k8s内部使用service名称.名称空间进行访问。 - service没有IP:比如
无头服务,也就是service的type是ClusterIP,并且clusterIP的值是None,这就是无头服务;
对于无头服务,针对同一个名称空间这种情况,在k8s内部直接使用service名称进行访问。针对不同名称空间这种情况,在k8s内部使用service名称.名称空间进行访问。
142.2、k8s网络互通情况
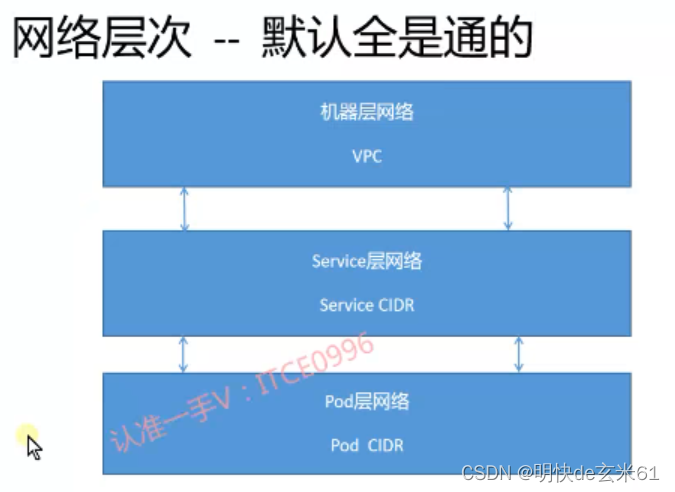
142.3、ExternalName(不常用,了解即可)
直接上yaml文件,然后注意type类型,以及externalName的值只能是外网域名,不能是IP,作用就是当我们k8s服务想访问外网域名的时候可以直接访问service名称.名称空间就可以了,和外网域名调用的相关问题都是由该service进行处理
apiVersion: v1
kind: Service
metadata:
name: externalname-test
namespace: default
spec:
type: ExternalName # 注意类型
externalName: "atguigu.com" # 只能是域名,注意存在的跨域、伪装请求头问题
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
142.4、LoadBalancer(云平台实现的,开发不用)
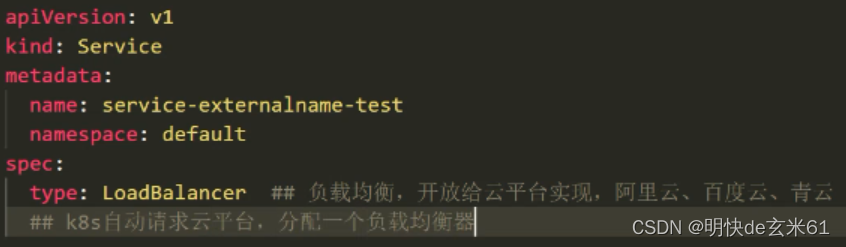
142.5、service中相关字段介绍
-
selector(类型:String):当type是ClusterIP、NodePort、LoadBalancer的时候,用来设置Pod的标签,作用是让我们在访问service的时候就可以负载均衡访问到对应标签的Pod
-
publishNotReadyAddress(类型:布尔值):是否发布未就绪的Pod,也就是流量到达service的时候,是否把流量打到未就绪的Pod,默认是false
-
ports(类型:列表):当type是ClusterIP、NodePort、LoadBalancer的时候,用来设置port(service端口)、targetPort(Pod端口,也是容器端口)、nodePort(浏览器用)的一一对应关系列表
-
ipFamilyPolicy(类型:String):下面截图是默认值,还有和IPV6相关的双栈协议等,如果真的使用,可以用
kubectl explain svc.spec.XXX解释
-
externalTrafficPolicy:默认值是Cluster,其中Cluster有负载均衡效果,而Local负载均衡效果不佳
-
externalName:在上面讲解ExternalName的时候说了,用来指定外网域名
-
clusterIP:指定一个节点中访问service的IP地址,指定之后clusterIPs也会有一个值,并且正是该值
-
clusterIPs:指定一组节点中访问service的IP地址,那我们访问该组中的任何一个IP都会访问到该service
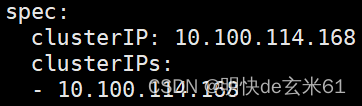
-
sessionAffinity:默认值是None,如果是ClusterIP,name还可以配置sessionAffinityConfig中的超时时间,也就是在多长时间内session亲和策略依然有效,也就是会达到尽可能把相同机器的访问流量达到同一个节点上
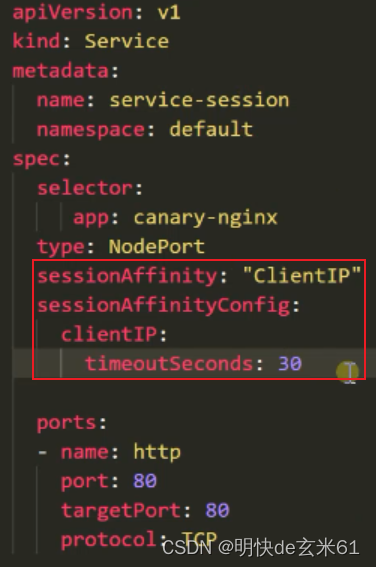
143、k8s网络-Service中Pod指定自己主机名
之前我们说过无头服务,那种条件还是比较苛刻的,针对非无头服务,那我们如何在k8s资源内部通过类型域名的方式访问pod和service呢?
- 针对service来说:
- 同名称空间:
ping service名称即可 - 不同名称空间:
ping service名称.名称空间名称即可
- 同名称空间:
- 针对Pod来说(下面会举例说明):
- 同名称空间:
ping pod-host-name.service名称即可 - 不同名称空间:
ping pod的hostname.service名称.名称空间名称即可
- 同名称空间:
针对Pod来说举例,对应yaml如下,我们注意pod中spec.hostname和spec.subdomain的写法,其中spec.hostname可以随意写,而spec.subdomain必须和service中metadata.name一致,测试pod的访问的时候就可以进入一个可以执行ping命令的资源,然后测试pod(busybox1)的命令是:ping busybox1.service-name
apiVersion: v1 kind: Service metadata: name: service-name namespace: default spec: selector: app: busybox type: ClusterIP ports: - name: test # 实际上不需要指定端口号 port: 1234 targetPort: 1234 --- apiVersion: v1 kind: Pod metadata: name: "busybox1" namespace: default labels: app: "busybox" spec: hostname: "busybox1" # 注意点1:随便起一个名称 subdomain: "service-name" # 注意点2:必须和上面service名称相同 containers: - name: "busybox1" image: "busybox" command: - sleep - "3600" --- apiVersion: v1 kind: Pod metadata: name: "busybox2" namespace: default labels: app: "busybox" spec: hostname: "busybox2" # 随便起一个名称 subdomain: "service-name" # 必须和上面service名称相同 containers: - name: "busybox2" image: "busybox" command: - sleep - "3600"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47

