
- 1Spark应用案例:推荐系统
- 2ChatGPT重磅福利:语音对话功能正式免费,它有这些好玩的用法_苹果开通chatgpt4
- 3线性代数|机器学习-P23梯度下降
- 4NVMe系统内存结构 - 命令聚合与仲裁_五选二轮转仲裁
- 5史上最强Windows震撼登场:Copilot全面接入,日常AI伴侣正式到来!
- 6持续集成与Devops关系_持续集成关系
- 7手把手教你在VSCODE下写C/C++代码(内附如何连接远端服务器教程)_vscode怎么写c++程序
- 8Java 多线程与高并发,高级java面试题及答案整理_高并发面试题java
- 9VSCode+Latex 环境配置_latex添加到环境变量中 win11 vscode
- 10Ubuntu下安装和配置Redis_ubuntu redis
利用python爬虫可视化分析当当网的图书数据_python爬取当当网数据并可视化分析
赞
踩
导语
这周末就分享个小爬虫吧。利用Python爬取并简单地可视化分析当当网的图书数据。
开发工具
**Python版本:**3.6.4
相关模块:
requests模块;
bs4模块;
wordcloud模块;
jieba模块;
pillow模块;
pyecharts模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
数据爬取
任务:
根据给定的关键字,爬取与该关键字相关的所有图书数据。
实现:
以关键字为python为例,我们要爬取的图书数据的网页页面是这样子的:
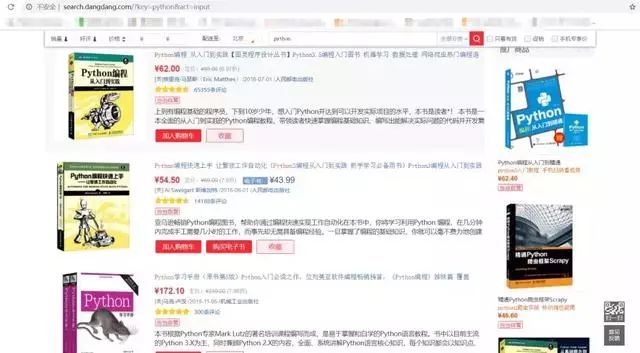
更多Python相关视频、资料加群778463939免费获取
其中,网页的链接格式为:
http://search.dangdang.com/?key={keyword}&act=input&page_index={page_index}’
因此请求所有与关键词相关的链接:
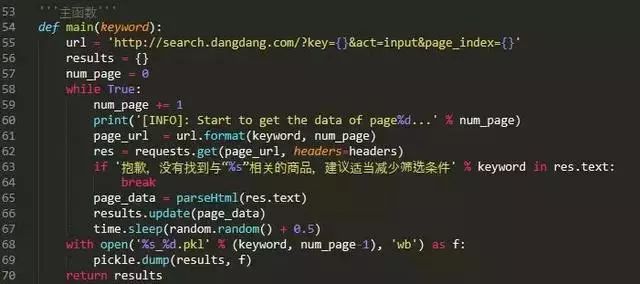
然后利用BeautifulSoup分别解析返回的网页数据,提取我们自己需要的数据即可:

运行效果:
在cmd窗口运行"ddSpider.py"文件即可。
效果如下:

数据分析
好的,现在就简单地可视化分析一波我们爬取到的61页python相关的图书数据吧~
让我们先看看图书的价格分布吧:

有没有人想知道最贵的一本python相关的书的单价是多少呀?答案是:28390RMB
书名是:
Python in Computers Programming
QAQ买不起买不起。
再来看看图书的评分分布呗:
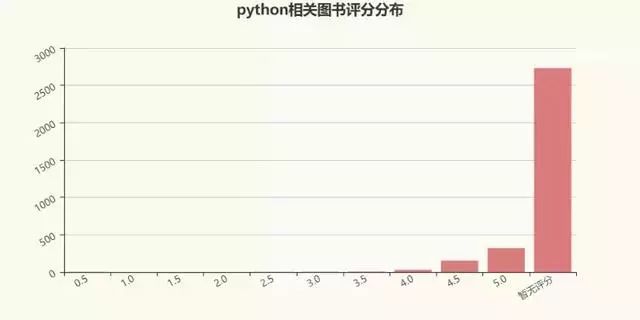
看来大多数python相关的图书都没人买过诶~大概是买不起吧T_T。
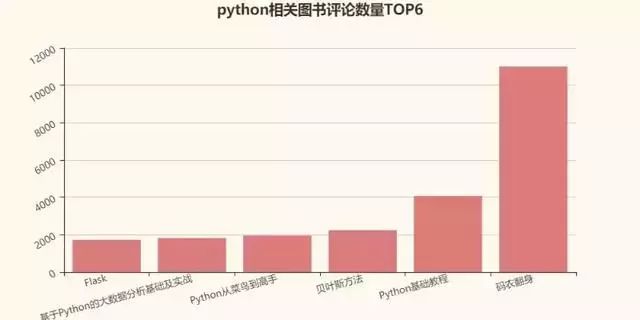
再来评论数量?

那么评论数量TOP6的图书有哪些呢?
老规矩,画两个词云作结吧,把所有python相关的图书的简介做成词云如何?

番外篇
这篇文章真的结束了吗?
这篇文章真的结束了吗?
这篇文章真的结束了吗?
难道没有人好奇我文章的封面怎么做的吗?
好吧,我写文章的时候没人看到,所以即使真的有人好奇也没法说?
其实很简单,就是下了961张python相关图书的图书封面,然后拼在一起了。
源代码如下:
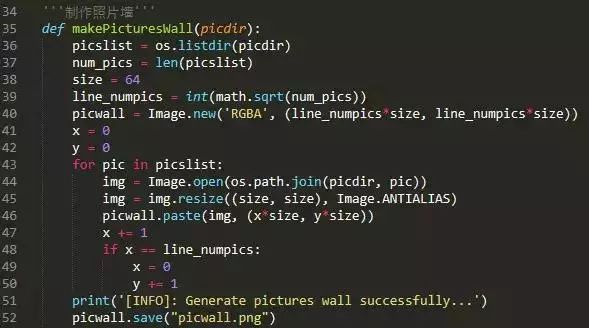
效果如下:


