- 1通义灵码-IDEA的使用教程_idea 通义灵码
- 2ollama调用本地模型时出现502_ollama serve报错
- 3npu算力如何计算_麒麟990 5G芯片的NPU如何做到算力暴涨?华为自研达芬奇架构详解...
- 4通过远程桌面连接Windows实例,提示“为安全考虑,已锁定该用户账户,原因是登录尝试或密码更改尝试过多”_为安全考虑,已锁定该用户帐户,原因是登录尝试或密码更改尝试过多。请稍候片刻再重
- 5MySQL入门篇
- 6Yolov5笔记--检测bilibili下载好的视频_yolo检测视频
- 751-LED点阵屏_hc595驱动led点阵
- 8企业数字化转型AI能力中台(总体架构、系统功能)建设方案_ai中台系统架构
- 9封装了一个仿照抖音效果的iOS评论弹窗
- 10Loading class `com.mysql.jdbc.Driver‘. This is deprecated._loading class `com.mysql.jdbc.driver'. this is dep
信息抽取数据集和相关SOTA介绍_webnlg数据集
赞
踩
一、概览
| 模型 | NYT*/NYT | WebNLG*/WebNLG | ACE | ACE05 | ACE04 | SciERC |
|---|---|---|---|---|---|---|
| TPLinker | 91.9/92.0 | 91.9/86.7 | ||||
| TPLinkerPlus:https://github.com/131250208/TPlinker-joint-extraction | The best F1: 0.931/0.934 (on validation set), 0.926/0.926 (on test set) | The best F1: 0.934/0.889 (on validation set), 0.923/0.882 (on test set) | ||||
| PURE | 65.6 | 60.2 | 35.6 | |||
| PFN:A Partition Filter Network for Joint Entity and Relation Extraction,https://arxiv.org/pdf/2108.12202v8.pdf | 92.4 | 93.6 | 80.0 | 66.8 | 62.5 | 38.4 |
| OneRel:Joint Entity and Relation Extraction with One Module in One Step,https://arxiv.org/pdf/2203.05412.pdf | 92.8/92.9 | 94.3/91.0 | ||||
| PL-Marker:Packed Levitated Marker for Entity and Relation Extraction,https://arxiv.org/pdf/2109.06067v5.pdf | bert base:69,albxxl:73 | bert base:66.7,albxxl:69.7 | bert base:53.2 |
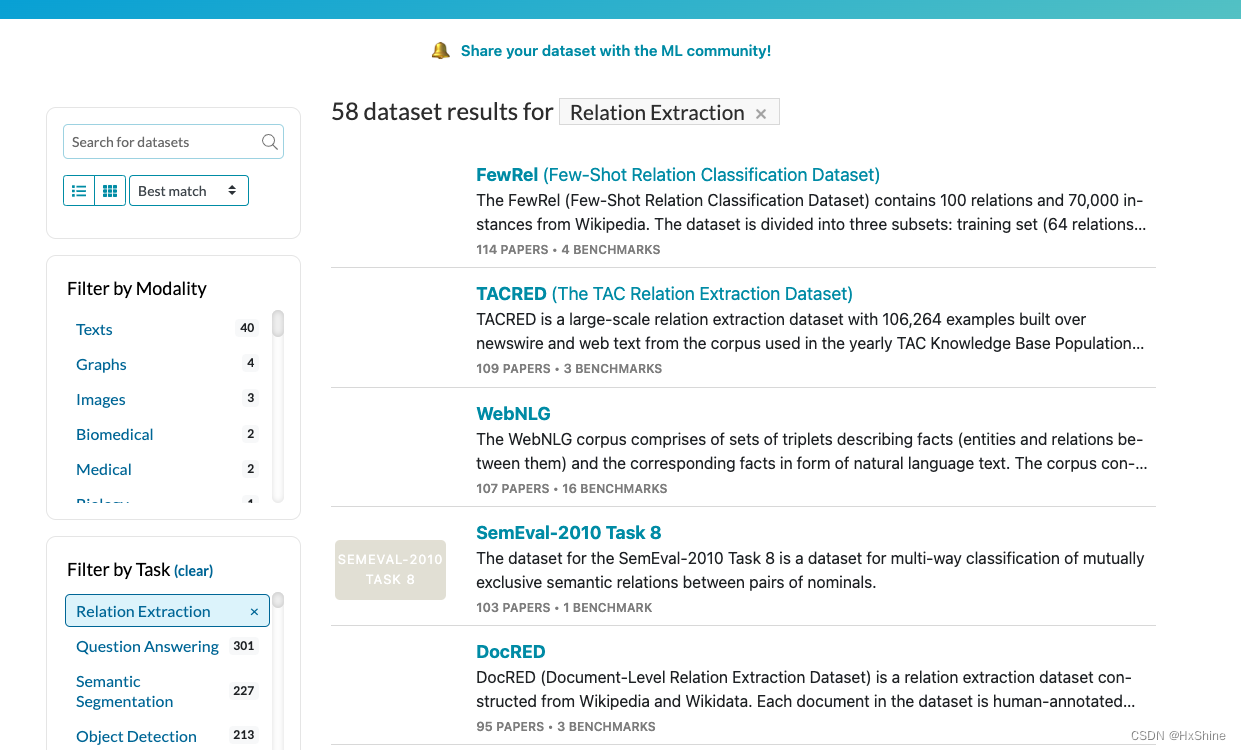
二、paperswithcode 所有关系抽取相关数据集
https://paperswithcode.com/datasets?task=relation-extraction
三、数据集介绍和SOTA
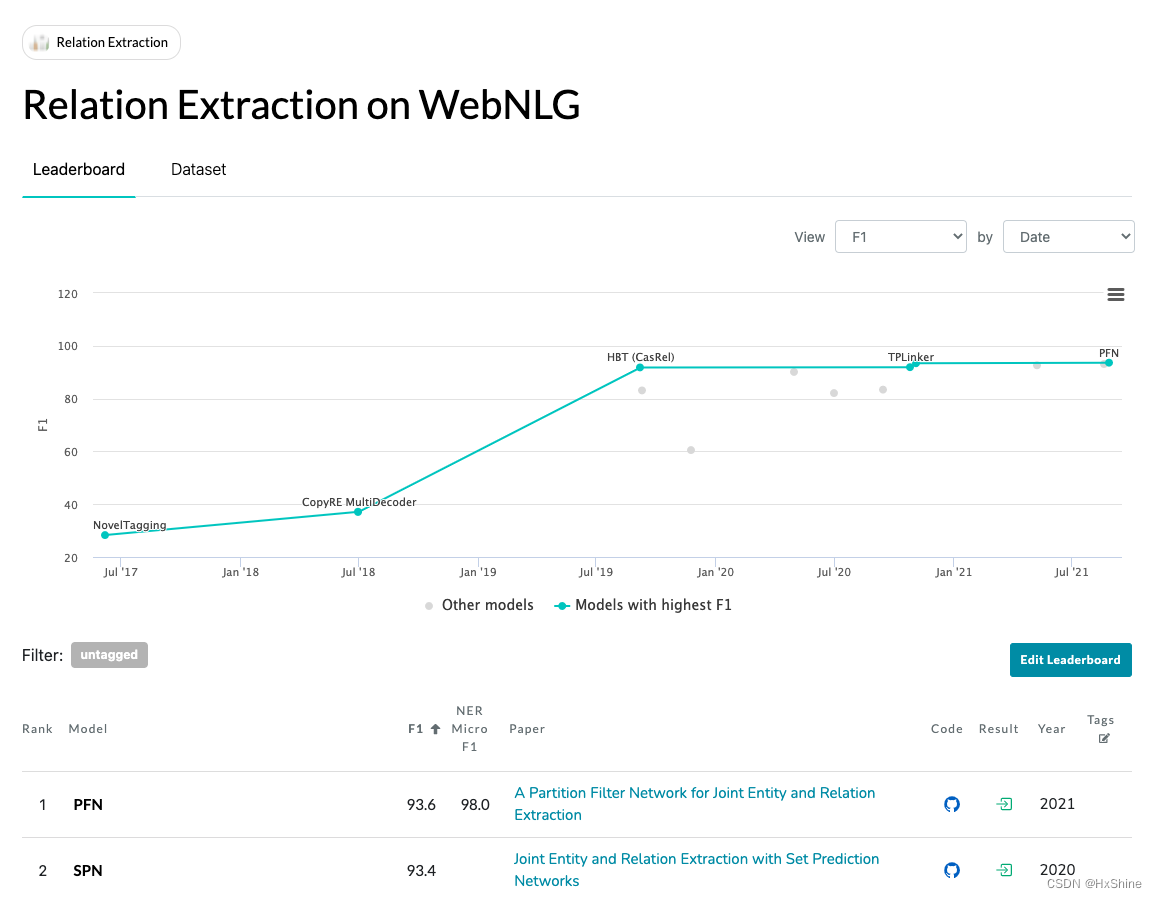
3.1 WebNLG
https://paperswithcode.com/sota/relation-extraction-on-webnlg
Introduced by Gardent et al. in Creating Training Corpora for NLG Micro-Planners
The WebNLG corpus comprises of sets of triplets describing facts (entities and relations between them) and the corresponding facts in form of natural language text. The corpus contains sets with up to 7 triplets each along with one or more reference texts for each set. The test set is split into two parts: seen, containing inputs created for entities and relations belonging to DBpedia categories that were seen in the training data, and unseen, containing inputs extracted for entities and relations belonging to 5 unseen categories.
Initially, the dataset was used for the WebNLG natural language generation challenge which consists of mapping the sets of triplets to text, including referring expression generation, aggregation, lexicalization, surface realization, and sentence segmentation. The corpus is also used for a reverse task of triplets extraction.
Versioning history of the dataset can be found here.
3.2 ACE 2005
https://paperswithcode.com/sota/relation-extraction-on-ace-2005
ACE 2005 Multilingual Training Corpus contains the complete set of English, Arabic and Chinese training data for the 2005 Automatic Content Extraction (ACE) technology evaluation. The corpus consists of data of various types annotated for entities, relations and events by the Linguistic Data Consortium (LDC) with support from the ACE Program and additional assistance from LDC.
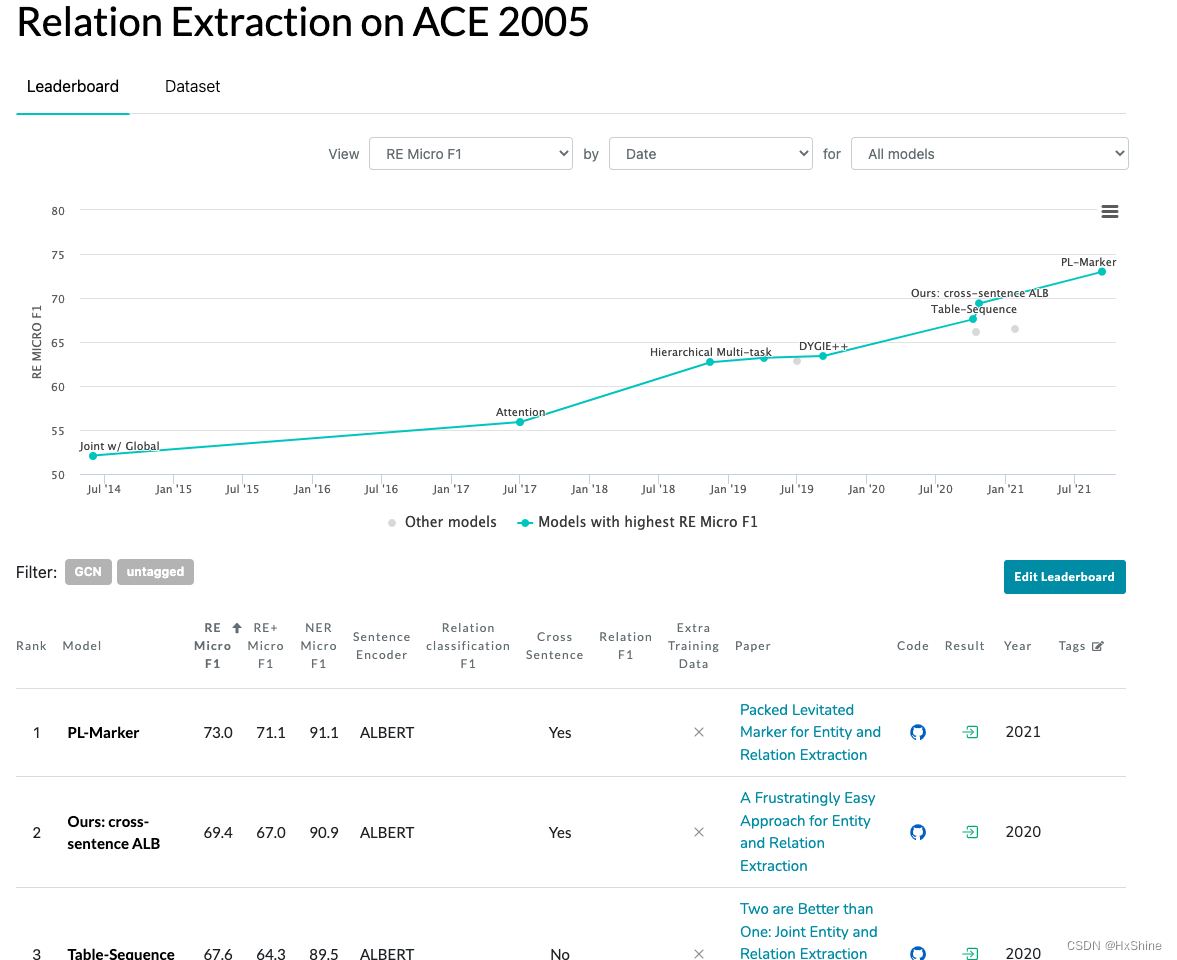
3.3 ACE 2004
https://paperswithcode.com/sota/relation-extraction-on-ace-2004
ACE 2004 Multilingual Training Corpus contains the complete set of English, Arabic and Chinese training data for the 2004 Automatic Content Extraction (ACE) technology evaluation. The corpus consists of data of various types annotated for entities and relations and was created by Linguistic Data Consortium with support from the ACE Program, with additional assistance from the DARPA TIDES (Translingual Information Detection, Extraction and Summarization) Program. The objective of the ACE program is to develop automatic content extraction technology to support automatic processing of human language in text form. In September 2004, sites were evaluated on system performance in six areas: Entity Detection and Recognition (EDR), Entity Mention Detection (EMD), EDR Co-reference, Relation Detection and Recognition (RDR), Relation Mention Detection (RMD), and RDR given reference entities. All tasks were evaluated in three languages: English, Chinese and Arabic.
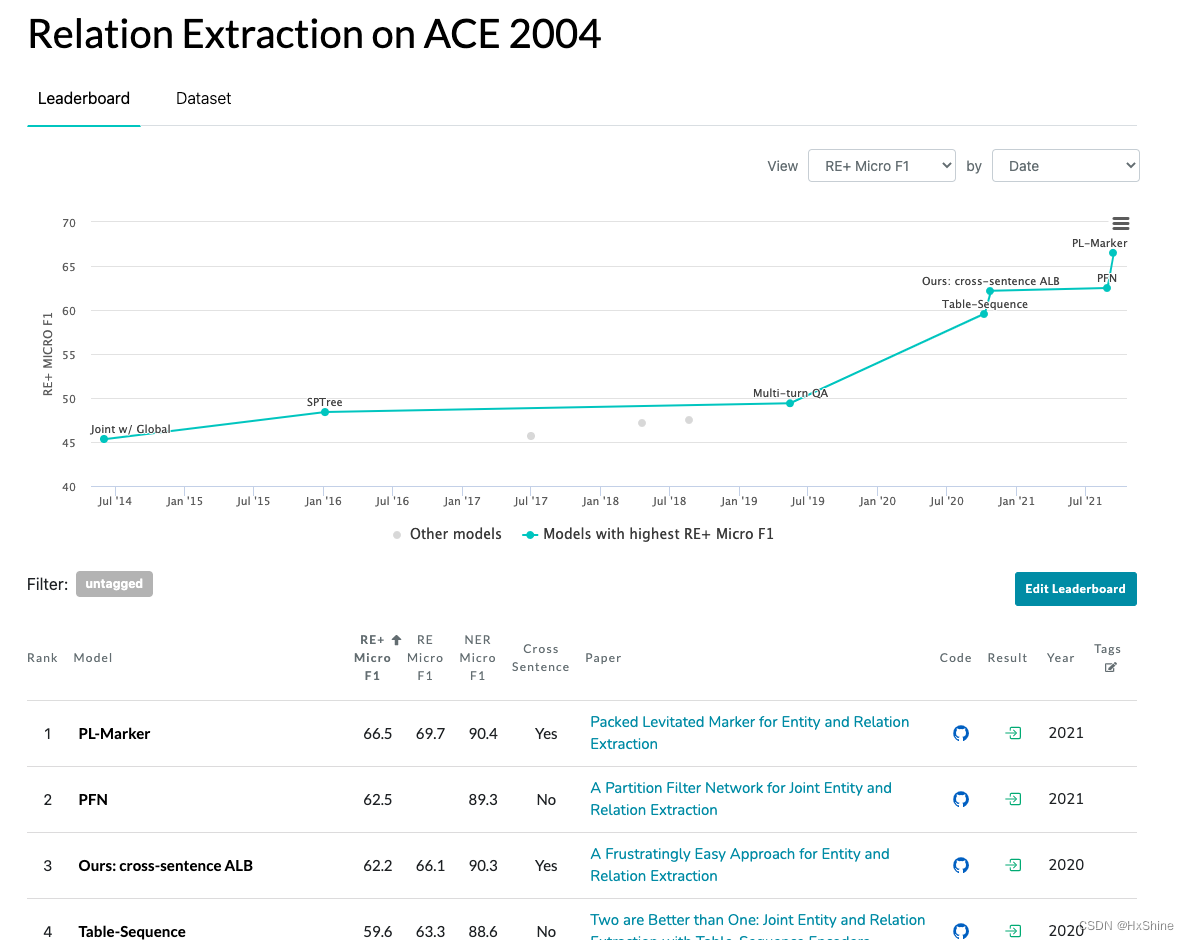
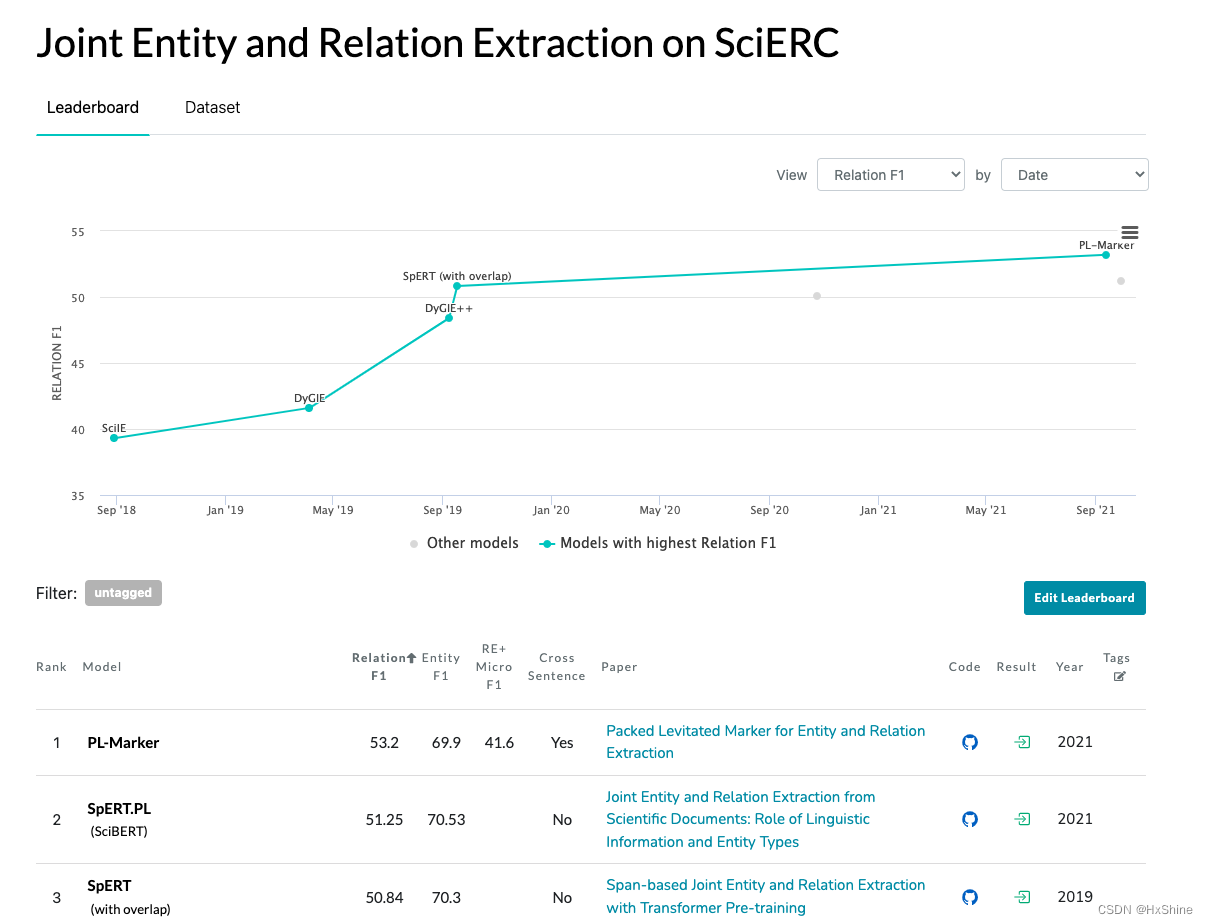
3.5 SciERC
https://paperswithcode.com/dataset/scierc

SciERC dataset is a collection of 500 scientific abstract annotated with scientific entities, their relations, and coreference clusters. The abstracts are taken from 12 AI conference/workshop proceedings in four AI communities, from the Semantic Scholar Corpus. SciERC extends previous datasets in scientific articles SemEval 2017 Task 10 and SemEval 2018 Task 7 by extending entity types, relation types, relation coverage, and adding cross-sentence relations using coreference links.
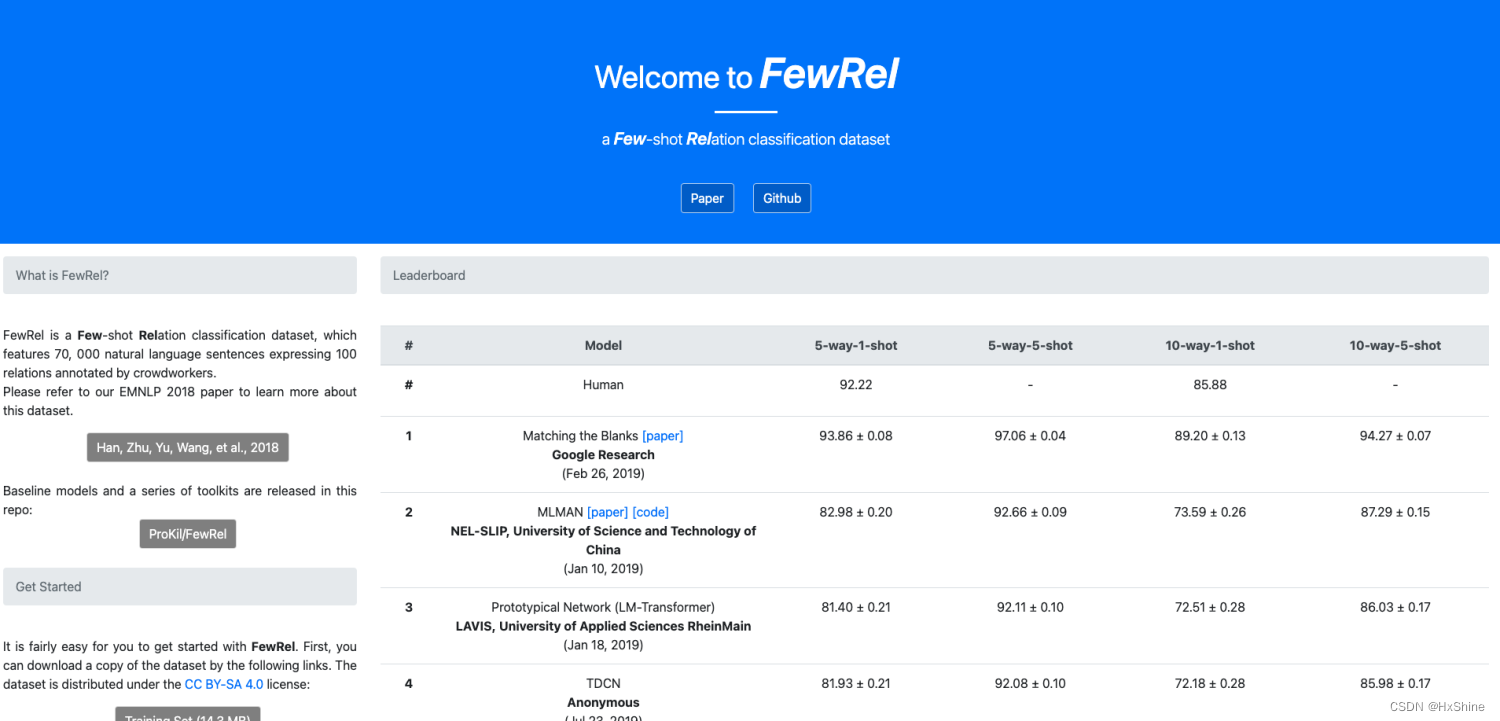
3.6 FewRel
http://www.zhuhao.me/fewrel/
FewRel is a Few-shot Relation classification dataset, which features 70, 000 natural language sentences expressing 100 relations annotated by crowdworkers.
Please refer to our EMNLP 2018 paper to learn more about this dataset.
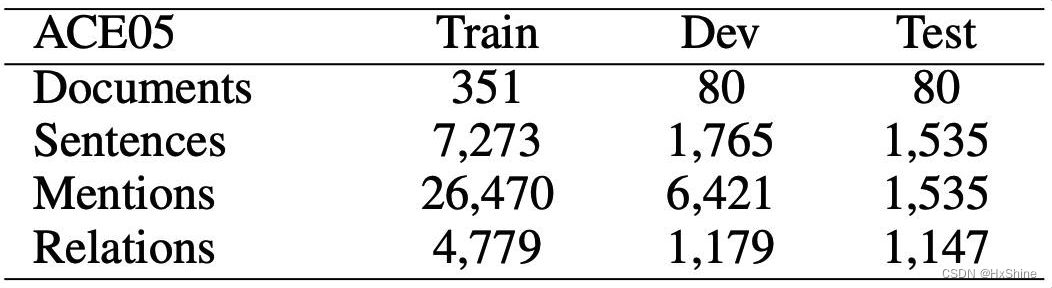
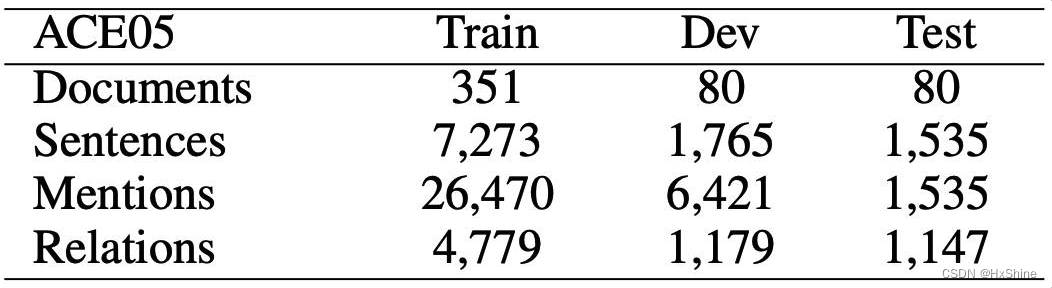
四、数据集统计结果
4.1 NYT/WebNLG数据分析
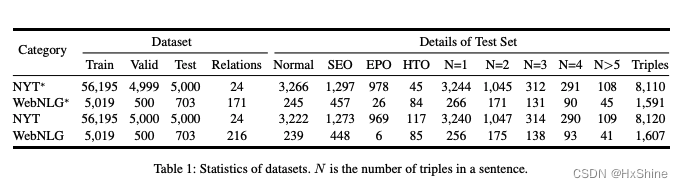
4.2 ACE05数据分析