
- 1HTML2022年圣诞节专属你的圣诞树来了_好看的圣诞节html
- 2ROS 导航实现(A*,DWA)_ros配置文件dwa
- 3【ROS2】开发环境搭建——安装VSCode及插件_ros2 vscode
- 4美团面试都面不过?我又不是去送外卖的!美团Java面试经历总结【一面、二面、三面】_美团java社招多久通知二面
- 5【C#】制作TCP服务器_c# tcp服务器
- 6如何实现rviz中的机械臂和实际的机械臂同步----ROS机械臂学习笔记(三)_如何在rviz中通过订阅其他节点发布法话题让机械臂模型动起来
- 7【大数据技术之Flink】一文读懂Flink,流计算_flink 使用离线数据更正计算结果
- 8Spring Boot进阶(06):【超详细】Windows10搭建RabbitMQ Server服务端,让你轻松实现消息队列管理!_windows rabbitmq 管理平台
- 9ESP32 CAM+ VSCODE+ESP IDF环境搭建 python pip版本问题_espidf python -m pip
- 10解决Matplotlib运行时报错:AttributeError: module ‘backend_interagg’ has no attribute ‘FigureCanvas’的问题_matplotlib报错 attributeerror
End-to-End Content and Plan Selection for Data-to-Text Generation 论文笔记
赞
踩
摘要
学习使用神经网络从结构化数据生成流畅的自然语言已成为NLG的常用方法。 当结构化数据的形式在示例之间变化时,该问题可能是具有挑战性的。 本文介绍了序列到序列模型的几种扩展的调查,以考虑潜在内容选择过程,特别是拷贝注意力机制和覆盖解码的变体。 我们进一步提出了一种基于多种集成的训练方法,以鼓励模型在训练期间学习不同的句子模板。 对这些技术的实证评估表明,生成的文本质量在五个自动度量标准以及人工评估中都有所提高。
介绍
最近使用神经网络进行端到端学习的发展使得方法能够从复杂的结构化输入(如图像和表格)生成文本输出。这些方法还可以创建以多个键值属性对为条件的文本生成模型。由于模型必须选择适合于话语的内容,开发适合所有选定信息的句子布局,并最终生成包含内容的流畅语言,因此条件生成流畅文本会带来多重挑战。端到端方法已经应用于日益复杂的数据,以同时学习句子规划和表面实现,但往往受限于有限的数据可用性。最近创建的数据集如E2E NLG数据集(Novikova等,2017)为进一步推进文本生成方法提供了机会。在这项工作中,我们专注于从意义表示(MR)生成语言,如图1所示。该任务需要学习从MR到话语的语义对齐,其中MR可以包括可变数量的属性。
最近,端到端生成主要通过序列到序列(S2S)模型(Sutskever等人,2014; Bahdanau等人,2014)处理,其编码一些信息并将其解码为期望的格式。 摘要和其他任务的扩展已经开发出一种机制,用于将输入中的单词复制到生成的文本中(Vinyals等,2015; See等,2017)。
我们从具有复制机制的强S2S模型开始,并且包括可以帮助控制生成的文本的长度以及模型使用多少输入的方法(Tu等人,2016; Wu等人,2016)。 最后,我们还将Transformer架构的结果(Vaswani等,2017)作为替代S2S变体。 我们展示了这些扩展可以改进文本生成和内容选择。
我们进一步提出了一种基于多种集成技术的训练方法(GuzmanRivera等,2012)。 在该技术中,训练多个模型以在训练模型本身的过程中划分训练数据,从而导致遵循不同的句子模板的模型的生成。我们证明了这种方法提高了生成文本的质量,但也提高了训练过程对训练数据中异常值的鲁棒性。
实验在E2E NLG挑战上进行。 我们表明,这种技术的应用通过多个强大的S2S基线模型提高了五种不同自动化指标(BLEU,NIST,METEOR,ROUGE和CIDEr)生成文本的质量(Dusek和Jurcicek,2016; Vaswani等, 2017; Su等,2018; Freitag和Roy,2018)。 在提交挑战的60份提交文件中,我们的方法在METEOR,ROUGE和CIDEr评分中排名第一,在BLEU中排名第三,在NIST中排名第六。
相关工作
传统的自然语言生成方法将句子计划的生成与表面实现分开。 首先,输入被映射到表示输出语句的布局的格式,例如,足够的预定义模板。 然后,表面实现将中间结构转换为文本(Stent等,2004)。 这些表示通常模拟话语关系的层次结构(Walker et al,2007)。 早期的数据驱动方法使用基于短语的语言模型进行生成(Oh和Rudnicky,2000; Mairesse和Young,2014),或旨在预测语义相似模板的最佳拟合群(Kondadadi等,2013)。 最近的工作将学习计划和实现的两个步骤结合起来使用端到端训练模型(例如Wen等,2015)。 有几种方法从抽象意义表示(AMR)开始研究,而Peng等(2017)将S2S模型应用于该问题。
然而,Ferreira等人(2017年)表明,在小型数据集中,S2S模型的表现优于基于短语的机器翻译模型。 为了解决这个问题,Konstas等人(2017)提出了一种半监督训练方法,该方法可以利用训练集之外的英语句子来训练模型的部分。 我们通过使用复制注意来解决问题,使模型能够从源复制单词,这有助于生成词汇和稀有单词。 我们注意到,包括我们的方法在内的端到端训练模型通常不会明确地对句子规划阶段进行建模,因此不能直接与之前的句子规划工作相比较。 这尤其限制了依赖于分层结构的复杂参数结构的生成。
对于从简单键值对中生成文本的任务,如在E2E任务中,Juraska等人(2018)描述了基于词重叠的启发式,其在句子计划中的意义表示和开放时隙之间提供无监督的时隙对齐。 该方法允许模型以较小的词汇表操作,并且与意义表示中的实际值无关。 为了解释模板中的句法结构,Su等人(2018)描述了一种分层解码策略,其在不同步骤生成不同的词性,填充先前生成的令牌之间的时隙。 相比之下,我们的模型使用copy attention来填充学习模板内的潜在槽。 Juraska等人(2018)也描述了一种数据选择过程,其中他们使用启发式方法根据一组规则将数据集过滤到最自然的探测示例。 我们的工作旨在无监督的数据分割,以便一个模型学习最自然的巧妙句子规划。
学习内容选择
我们使用解决文本摘要相关问题的方法扩展了vanilla S2S系统。 特别地,我们实现类似于Nallapati等人(2016)(Abstractive text summarization using sequence-to-sequence rnns and beyond)和See等人(2017)(Get to the point: Summarization with pointergenerator networks)所引入的指针生成器网络,其可以通过在生成过程期间从输入复制记号来生成内容。
Copy Model
复制模型为每个解码步骤t引入二进制变量zt,其用作从源复制和生成单词之间的切换。 我们按照Gulcehre等人(2016)描述的程序对联合概率进行建模:


其中每个术语都以x和y [t-1]为条件。 p(yt | zt = 0)是由先前描述的S2S模型生成的分布,并且p(yt | zt = 1)是使用具有单独参数的相同注意机制计算的x上的分布。
在我们的问题中,MR中的所有值都应该出现在生成的文本中,并且通常是语言模型不会生成的单词。 这允许我们使用Gulcehre等人(2016)的假设,即在源和目标中都出现的每个单词都被复制,这避免了必须在z上边缘化。 然后,yt和zt的对数似然在训练期间最大化。 这种方法的另一个优点是,它可以通过学习将这些单词复制到正确的位置来处理以前看不见的输入。
Coverage and Length Penalty
我们观察到使用带有和不带复制机制的vanilla S2S模型生成的文本通常会忽略其输入中的某些值。 为了减轻这种影响,我们在推理期间使用两个惩罚项; 长度和覆盖率罚款。 我们仅在推理期间使用覆盖惩罚,我们使用Wu等人(2016)定义的惩罚项cp为:

这里,β是控制罚分强度的参数。 当太多生成的单词关注相同的输入时,该惩罚项增加。 我们通常不想重复餐厅的名称或它所服务的食物类型。 因此,我们只想在实际生成餐馆名称时注意一下餐馆名称。 我们还使用Wu等人(2016)的长度惩罚lp,定义为:

我们模型的最终推理时间限制是阻止重复句子的开始。 自动指标不会惩罚句子之间强烈的并行性,但重复句子开始会中断文本流并使其看起来不自然。 我们发现,由于每个模型在生成期间都遵循严格的潜在模板,因此生成的文本通常会以相同的单词开始每个句子。 因此,我们通过在波束搜索期间修剪波束来鼓励句法变化,这些波束搜索以相同的二元组开始两个句子。 Paulus等(2017)通过在整个生成的文本中阻止重复的三元组,对摘要使用类似的限制。 由于自动评估不会惩罚重复句子,因此我们仅在为人类评估生成文本时启用此限制。
学习潜在句子模板
每个生成的文本都遵循潜句模板来描述其MR中的属性。 模型必须将每个属性与其在句子模板中的位置相关联。 然而,S2S模型可以用有限的数据来学习输入和目标之间的错误关联,Ferreira等人(2017)也证明了这一点。 此外,考虑到我们可能会看到生成的类似输入的文本:“有一个叫做鹰的昂贵的英国餐厅。”和“鹰是一个昂贵的英国餐厅。”。 两者都包含相同的信息,但具有不同的结构。 同时训练两种风格的模型可能难以生成单个输出句子。 为了解决这个问题并学习一组不同的生成方式,我们训练混合模型,其中每个序列仍然由单个模型生成。 该方法旨在强制每个模型学习不同的句子模板。
混合物旨在在模型之间分割训练数据,使得每个模型仅训练数据的子集,并且可以学习不同的模板结构。因此,一个模型不必同时适合所有底层模板结构。此外,它隐含地删除了混合物中除了一部分以外的所有异常训练样例。 让f1 , ...,fK是混合物中的K个模型。这些模型可以完全不相交或共享其参数的子集(例如,字嵌入,编码器或编码器和解码器两者)。 根据Guzman-Rivera等人(2012),我们引入了一个未观察到的随机变量w~Cat(1 / K),为每个输入分配每个模型的权重。 令pθ(y | x,w)表示具有给定分段w的输入x的输出y的概率。 每个点的可能性被定义为个体可能性的混合,
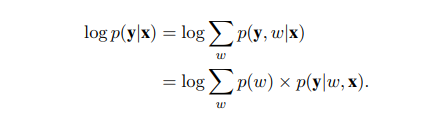
通过将w约束为0或1,整个数据集上的优化问题成为模型分配到数据点和模型参数的联合优化。
为了最大化目标,Guzman-Rivera等人(2012)提出了一种多选择损失(MCL)来划分训练数据,类似于硬EM算法或k-Means聚类。 使用MCL,在每个训练时期之后,将每个训练点分配给以最小损失预测它的模型。 在该分割之后,仅使用其分配到的数据点来训练每个模型以获得另一个时期。重复此过程直到点分配收敛。 Kondadadi等人(2013)的相关工作表明,模型计算模板集群。
我们在图2中描述了单个前向通道的过程,其中模型fi具有最小的损耗Li并因此被更新。 图3演示了K = 2的示例,其中两个模型根据两个不同的句子布局生成文本。 我们发现在推理过程中对多个模型进行平均预测是一种常用于传统集成方法的技术,但不会提高性能。 我们进一步确认Lee等人(2017)的研究结果,他们指出这些模型在生成文本时高估了他们的信心。 由于我们的目标是训练学习最佳潜在模板而不是生成多样化预测的模型,因此我们仅使用整体中的模型生成文本,并且在验证集上具有最佳的复杂度。


实验
我们评估LSTM和Transformer架构的性能。 我们还试验了两种注意力配方。 第一种是在编码器和解码器的隐藏状态之间使用点积(Luong等,2015)。 第二种是使用隐藏状态作为输入的多层感知器(Bahdanau等,2014)。 我们将它们分别称为dot和MLP。 由于dot attention不需要额外的参数,我们假设它在有限的数据环境中表现良好。


结论
在本文中,我们展示了针对数据到文本问题的端到端模型的三个贡献。 我们调查了现有的S2S建模方法和扩展,以改进NLG问题中的内容选择模块。我们进一步表明,应用多样化的集成来模拟数据中不同的潜在生成样式可以为噪声数据带来更强大的学习过程。 最后,对所研究方法的实证评估表明,它们可以导致多个自动评估指标的改进。 在未来的工作中,我们的目标是扩展所显示的方法,以解决更复杂输入的生成问题,以及挑战数据到文档生成等领域。

