
- 1aws rds监控慢sql_如何使用Web控制台和AWS CLI停止AWS RDS SQL Server
- 2(附源码)spring boot物联网智能管理平台 毕业设计 211120_springboot 物联网相关技术有那些
- 3python常用字符串拼接方法_python字符串连接输出字符串
- 4多个comfyui之间如何共享模型,节省存储空间_comfyui共用模型
- 5AI、AGI、AIGC与AIGC、NLP、LLM,ChatGPT区分
- 6MySql中的CAST_mysql cast
- 7yolo v5 onnxruntime与opencv cv2加载部署推理、实时摄像头检测_onnxruntime yolo 多路摄像头识别
- 8git 的注册与常用的方式_agit网站注册
- 9AIGC从入门到入坑01(初学者适用版)_aigc百问百答适合新手入门
- 10我的软件测试面试经历,7轮高强度面试顺利入职_软件测试怎么面试高级别
【Flink】Flink时间语义详解
赞
踩
简介
在流处理中,时间是一个非常核心的概念,是整个系统的基石。我们经常会遇到这样的需求:给定一个时间窗口,比如一个小时,统计时间窗口内的数据指标。那如何界定哪些数据将进入这个窗口呢?在窗口的定义之前,首先需要确定一个作业使用什么样的时间语义。
本文首先介绍 Flink 的三种时间语义(Event Time、Processing Time 和 Ingestion Time),然后详细介绍 Flink-watermark 机制。
三种时间语义
事件时间(Event Time)
事件时间是数据生成的时间,是数据流中每个元素或者每个事件自带的时间属性,一般是事件发生的时间,在实际项目中作为前端的一个属性嵌入。在理想情况下,数据应当按照事件时间顺序到达集群节点,但是由于从产生一条数据到数据抵达集群有过多的中间步骤,一个较早发生的事件可能较晚到达,使用事件时间意味着会产生数据乱序。
为了避免数据乱序问题,我们第一个能想到的解决方案就是等待,我们可以等待所有的数据都到达之后再进行窗口计算,如果一个窗口可以等待所有的数据抵达再触发计算,那么结果的一致性和正确性都能够得到保证,此时使用事件时间不用担心乱序问题。
但是这个解决方案也有一个问题,就是我们不知道什么时候所有的数据都抵达了,在实际项目中也不可能永久等待下去。为了解决这个问题引入了水位线(WaterMark),水位线是一个 Flink 系统中抽象的、基于事件时间的逻辑时钟,这个时钟不会自己流动,它随着事件的到来进行推动。 用来衡量当前系统事件时间的进展,我将会后面详细介绍。
如果想要使用水位线,在程序中必须指定如下内容:
- 如何从一条数据中提取出事件时间;
- 基于事件时间如何生成水位线;
小结一下,使用 Event Time 的优势是结果的可预测性,缺点是缓存较大,增加了延迟,且调试和定位问题更复杂。
处理时间(Processing Time)
处理时间执行处理操作的机器的系统时间,使用处理时间不需要依赖水位线,也无需缓存,实现也十分简单,是延迟最小的一种时间语义。由于计算是需要时间的,受限于集群中软硬件的限制,第 N 个算子和第 N+1 个算子的处理时间是不同的,尽管他们有相同的事件时间,这也意味着处理时间具有不确定性,结果不可预测。就窗口场景下,不同的运行环境窗口计算结果不同。
注入时间(Ingestion Time)
注入时间是数据进入 Source 算子的时间,任何一个算子的处理速度快慢可能影响到下游算子的处理时间,但是注入时间仅依赖于数据进入 Source 算子的时间,因此不会受制于不同算子的计算时间。
使用注入时间是一种折中方案,不同于事件时间,不需要使用水位线机制,也意味着他不需要太多的缓存,延迟也较低。相比处理时间,它避免了不同算子处理速度的影响。
设置时间语义
1.11 版本
在公司中通常使用 1.09 或者 1.11 版本,针对这两个版本,设置时间语义的方式如下:
// 设置事件时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 设置处理时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
// 设置注入时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
- 1
- 2
- 3
- 4
- 5
- 6
1.11 版本后
1.12 版本开始,1.11 版本时间语义的设置方法被废弃,1.12 版本开始默认的时间语义就是事件时间,所以 setStreamTimeCharacteristic() 方法被废弃,如果需要使用 setAutoWatermarkInterval() 方法设置自动水印发射的时间间隔,如果间隔设为 0 则认为使用处理时间。从 setStreamTimeCharacteristic() 的源码看,它的底层也是使用了 setAutoWatermarkInterval() 方法,源码分析如下:
// --------------- StreamExecutionEnvironment ------------ // 默认间隔时间200毫秒 private long autoWatermarkInterval = 200; // 默认的时间语义就是事件时间 private TimeCharacteristic timeCharacteristic = DEFAULT_TIME_CHARACTERISTIC; private static final TimeCharacteristic DEFAULT_TIME_CHARACTERISTIC = TimeCharacteristic.EventTime; public void setStreamTimeCharacteristic(TimeCharacteristic characteristic) { // 前置检查 this.timeCharacteristic = Preconditions.checkNotNull(characteristic); // 如果使用处理时间语义,则水位线发送间隔设置为0, if (characteristic == TimeCharacteristic.ProcessingTime) { getConfig().setAutoWatermarkInterval(0); } else { getConfig().setAutoWatermarkInterval(200); } } // -------------------------------------------------------

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
总结
为了让大家更好的理解三种时间语义,我画了一个图,希望能帮到大家。
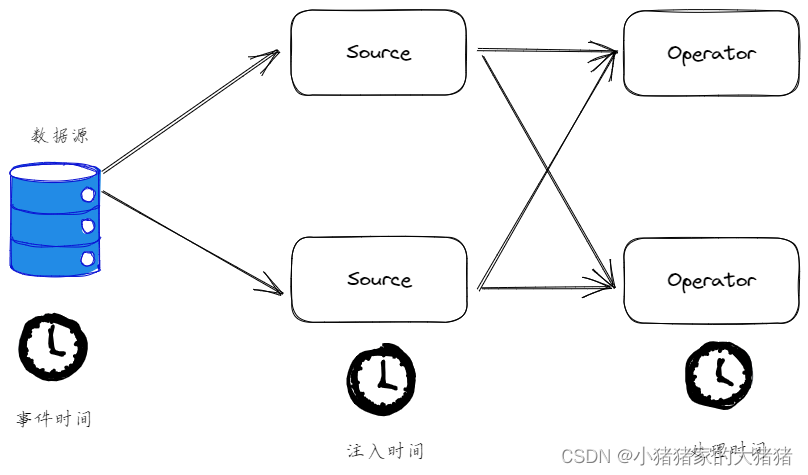
水位线和事件时间
我们知道,流处理从事件产生,到流经 source,再到 operator,中间是有一个过程和时间的,虽然大部分情况下,流到 operator 的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指 Flink 接收到的事件的先后顺序不是严格按照事件的 Event Time 顺序排列的,为了衡量一个系统的事件时间水平引入了水位线机制。稍稍总结一下水位线的引入原因:
- 分布式系统的网络传输的不确定性;
- 数据是乱序的;
- 支持事件时间的流处理器需要一种测量事件时间进度的方法,用以正确的处理窗口等操作;
水位线的物理意义有两点:
- 水位线本质是一个基于数据生成的、单调递增的时间戳;
- 水位线 W(t)表示当前数据流中的所有 t 时刻前的数据都已经到了。
就机制而言十分的简单,Flink 会按照一定的规则生成水位线并插入到数据流中,这是一种特殊的数据结构,有对应的特殊处理方式。这条 Watermark 就等于当前所有到达数据中的 maxEventTime - 延迟时长,就窗口场景而言,Watermark 是由数据携带的,一旦数据携带的 Watermark 比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。由于 Watermark 是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发,这也称之为断流。
我画了一张图方便大家理解
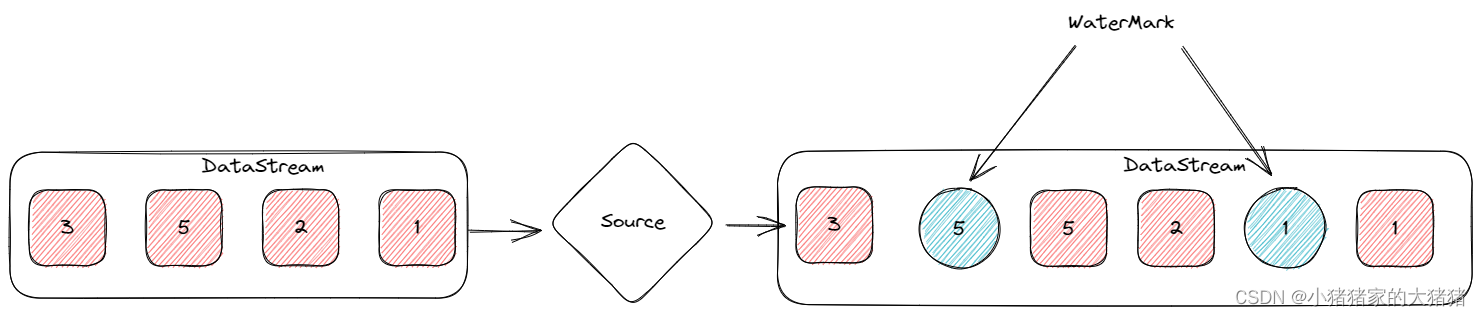
除此之外,WaterMark 还需要注意如下几点:
- Watermark 与事件的时间戳紧密相关。一个时间戳为 T 的 Watermark 假设后续到达的事件时间戳都大于 T。
- 假如 Flink 算子接收到一个违背上述规则的事件,该事件将被认定为迟到数据。Flink 提供了一些其他机制来处理迟到数据。
- Watermark 时间戳必须单调递增,以保证时间不会倒流。
- Watermark 机制允许用户来控制准确度和延迟。Watermark 设置得与事件时间戳相距紧凑,会产生不少迟到数据,影响计算结果的准确度,整个应用的延迟很低;Watermark 设置得非常宽松,准确度能够得到提升,但应用的延迟较高,因为 Flink 必须等待更长的时间才进行计算。
水位线的传播
在实际计算过程中,Flink 的算子一般分布在多个并行的分区(或者称为实例)上,Flink 需要将 Watermark 在并行环境下向前传播。如下图所示,由于上游各分区的处理速度不同,到达当前算子的 Watermark 也会有先后快慢之分,每个算子子任务会维护来自上游不同分区的 Watermark 信息,这是一个列表,列表内对应上游算子各分区的 Watermark 时间戳等信息。每当一个上游传递过来一个水位线,实例会判断该水位线是否大于列表中记录的数值,如果大于则更新水位线。接着实例会遍历整个水位线列表找出最小值作为实例的事件时间,最后,实例会将更新的 Event Time 作为 Watermark 发送给下游所有算子子任务。
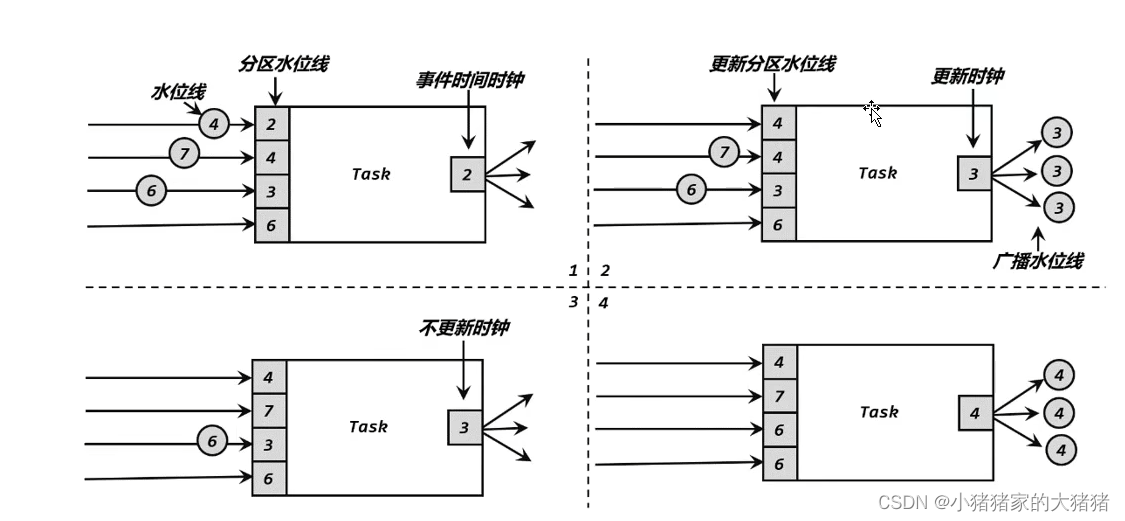
总结一下就是:
- 上游的水位线会广播到所有的下游任务上;
- 多个上游任务传递水位线时下游任务使用其中最小的水位线,下游任务会为所有的上游任务创建一个分区标志位,保存其传递的水位线。
这样的设计机制满足了并行环境下 Watermark 在各算子中的传播问题,但是假如某个上游分区的 Watermark 一直不更新,Partition Watermark 列表其他地方都在正常更新,唯独个别分区的时间停留在很早的某个时间,这会导致算子的 Event Time 时钟不更新,相应的时间窗口计算也不会被触发。这种问题的解决办法就是设置断流阈值,设置断流阈值,超时将 Source-SubTask 置于 IDLE,这样后续分区水位线传递将会忽略该 SubTask。此外,在 union 等多数据流处理时,Flink 也使用上述 Watermark 更新机制,这也可能导致断流问题,解决方案同上。
时间事件的提取和水位线的生成
Source 算子
我们可以在 Source 阶段,通过自定义 SourceFunction 或 RichSourceFunction,在 SourceContext 里重写 collectWithTimestamp() 和 emitWatermark() 两个方法,前者给数据流中的每个元素 T 赋值一个时间戳作为事件时间;后者针对数据流中的每一个元素 T 发出一个时间戳。源码如下:
// 生成事件时间
void collectWithTimestamp(T element, long timestamp);
// 生成水位线
void emitWatermark(Watermark mark);
- 1
- 2
- 3
- 4
非 Source 算子
我们也可以使用 assignTimestampsAndWatermarks() 来分配时间戳和水位线。该方法主要依赖于 WatermarkStrategy 接口,通过 WatermarkStrategy 我们可以为每个元素抽取时间戳并生成 Watermark。基本的使用方法如下:
DataStream<MyType> withTimestampsAndWatermarks = stream
.assignTimestampsAndWatermarks(
WatermarkStrategy
.forGenerator(...)
.withTimestampAssigner(...)
);
- 1
- 2
- 3
- 4
- 5
- 6
可以看到 WatermarkStrategy.ForGenerator (...). WithTimestampAssigner (...) 链式调用了两个方法,forGenerator () 方法用来生成 Watermark,本质是返回了一个 WatermarkGenerator ,它的源码如下:
public interface WatermarkGenerator<T> {
// 数据流中的每个元素流入后都会调用onEvent()方法
// Punctunated方式下,一般根据数据流中的元素是否有特殊标记来判断是否需要生成Watermark
// Periodic方式下,一般用于记录各元素的Event Time时间戳
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
// 每隔固定周期调用onPeriodicEmit()方法
// 一般主要用于Periodic方式
// 固定周期用 ExecutionConfig#setAutoWatermarkInterval() 方法设置
void onPeriodicEmit(WatermarkOutput output);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
withTimestampAssigner () 方法用来为数据流的每个元素设置时间戳。WatermarkGenerator 提供了两种方式,onPeriodicEmit() 方法实现周期性的生成水位线,默认周期是 200 毫秒。可以使用 ExecutionConfig.setAutoWatermarkInterval() 方法进行设置。
Flink 本身已经帮我们封装好了这样的代码,常见的两个实现是 BoundedOutOfOrdernessWatermarks 和 AscendingTimestampsWatermarks。
基本的使用方式如下:
DataStream.assignTimestampsAndWatermarks(WatermarkStrategy
.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner((SerializableTimestampAssigner<Event>)
(element, recordTimestamp) -> element.timeStamp))
- 1
- 2
- 3
- 4
Watermark 的设定
在 Flink 中 watermark 由开发人员指定延迟,对待具体的业务场景,我们可能需要反复尝试,不断迭代和调整时间戳和 Watermark 策略.
往期回顾
- 【Flink】详解JobGraph
- 【Flink】详解StreamGraph
- 【Flink】浅谈Flink架构和调度
- 【Flink】详解Flink的八种分区
- 【Flink】浅谈Flink背压问题(1)
- 【分布式】浅谈CAP、BASE理论(1)
文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,相关的知识点也可进行分享,希望大家都能有所收获!!


