
- 1鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:CalendarPicker)_鸿蒙calendar kit
- 2人工智能技术在电子商务中的应用,给消费者带来哪些便利?_.ai技术和电子商务之间有关系吗?对你的生活有什么帮助?结合所学知识阐述
- 3Linux shell编程学习笔记29:shell自带的 脚本调试 选项_bash 调试
- 4【视频异常检测】VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection 论文阅读
- 5jupyter notebook配置指南
- 6NFTScan 正式上线 Mint NFTScan 浏览器和 NFT API 数据服务
- 7从零实现深度学习框架——常见运算的计算图_深度学习算法框图符号
- 8jdk8新特性
- 9探索医疗图像处理的未来:U-KAN,打造强大背景区分与生成模型
- 10【初阶数据结构】理解堆的特性与应用:深入探索完全二叉树的独特魅力
LLM、ChatGPT与多模态必读论文150篇_chatgpt必读论文
赞
踩
为了写本 ChatGPT 笔记,我和10来位博士、业界大佬,在过去半年翻了大量中英文资料/paper,读完 ChatGPT 相关技术的150篇论文,当然还在不断深入。
由此而感慨:
- 读的论文越多,你会发现大部分人对ChatGPT的技术解读都是不够准确或全面的,毕竟很多人没有那个工作需要或研究需要,去深入了解各种细节
- 因为半年内150篇这个任务,让自己有史以来一篇一篇一行一行读,之前看的比较散、不系统,抠的也不细
比如回顾“Attention is all you need”这篇后,对优化博客内的Transformer笔记便有了很多心得。
考虑到为避免上篇文章篇幅太长而影响完读率,故把这些论文的清单抽取出来独立成本文
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
建了技术答疑、交流群!想要进交流群、需要资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

第一部分 OpenAI/Google的基础语言大模型(11篇,总11篇)
-
Improving Language Understanding by Generative Pre-Training
GPT原始论文 -
Language Models are Unsupervised Multitask Learners
GPT2原始论文 -
Training language models to follow instructions with human feedback
InstructGPT原始论文 -
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
19年10月,Google发布T5模型_(transfer text to text transformer),虽也基于transformer,但区别于BERT的编码器架构与GPT的解码器架构,T5是transformer的encoder-decoder架构_,这是解读之一 的
用的750G的训练数据,其训练方法则为:BERT-style的MASK法/replace span(小段替换)/Drop法,以及类似BERT对文本的15%做破坏、且replace span时对3的小段破坏 -
LaMDA: Language Models for Dialog Applications
论文发布于22年1月,显示LaMDA的参数高达137B,用的transformer decoder架构,这是简要解读之一
21年5月,Google对外宣布内部正在研发对话模型LaMDA,基于transformer decoder架构,在微调阶段 使用58K的对话数据,过程类似真人的对话过程,给定一个Query,比如 How old is Rafael Nadal? ,如果人知道答案,那么直接回答35岁即可,如果不知道,则需要去 Research 一下,借助搜索引擎找到答案,然后再回答35岁 -
《Finetuned Language Models Are Zero-Shot Learners》
21年9月,Google提出FLAN大模型,其基于LaMDA-PT做Instruction Fine-Tuning
FLAN is the instruction-tuned version of LaMDA-PT -
Constitutional AI: Harmlessness from AI Feedback
OpenAI之前一副总裁离职搞了个ChatGPT的竞品,ChatGPT用人类偏好训练RM再RL(即RLHF),Claude则基于AI偏好模型训练RM再RL(即RLAIF) -
Improving alignment of dialogue agents via targeted human judgements
DeepMind的_Sparrow_,这个工作发表时间稍晚于instructGPT,其大致的技术思路和框架与 instructGPT 的三阶段基本类似,但Sparrow 中把奖励模型分为两个不同 RM 的思路 -
GPT-4 Technical Report
增加了多模态能力的GPT4的技术报告
第二部分 LLM的关键技术:ICL/CoT/RLHF/词嵌入/位置编码/加速/与KG结合等(38篇,总49篇)
-
Attention Is All You Need
Transformer原始论文 -
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
-
Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers
代码地址,这篇文章则将ICL看作是一种隐式的Fine-tuning,这是对该篇论文的解读之一 -
Noisy Channel Language Model Prompting for Few-Shot Text Classification ~ https://arxiv.org/pdf/2108.04106.pdf
-
MetaICL: Learning to Learn In Context ~ https://arxiv.org/pdf/2110.15943.pdf
-
Meta-learning via Language Model In-context Tuning
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
-
Large Language Models are Zero-Shot Reasoners
来自东京大学和谷歌的工作,关于预训练大型语言模型的推理能力的探究,“Let’s think step by step”的梗即来源于此篇论文 -
Emergent Abilities of Large Language Models
Google 22年8月份发的,探讨大语言模型的涌现能力 -
Multimodal Chain-of-Thought Reasoning in Language Models
23年2月,亚马逊的研究者则在这篇论文里提出了基于多模态思维链技术改进语言模型复杂推理能力的思想 -
TRPO论文
-
Proximal Policy Optimization Algorithms
2017年,OpenAI发布的PPO原始论文,在理解过程中有时会问下GPT4,感叹GPT4的细节能力 虽经常不是很严谨 但细节能力是真6 -
RLHF原始论文
-
Scaling Instruction-Finetuned Language Models
微调PaLM-540B(2022年10月)
从三个方面改变指令微调,一是改变模型参数,提升到了540B,二是增加到了1836个微调任务,三是加上Chain of thought微调的数据 -
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
-
Fine-Tuning Language Models from Human Preferences
这是论文对应的代码:微调GPT2 -
Prefix-Tuning: Optimizing Continuous Prompts for Generation
新增Prefix Tuning论文 -
GPT Understands, Too
p-tuning V1论文 -
Distributed Representations of Sentences and Documents
Mikolov首次提出 Word2vec
Efficient estimation of word representations in vector space
Mikolov专门讲训练 Word2vec 中的两个trick:hierarchical softmax 和 negative sampling
- 1
- 2
- word2vec Explained- Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method
Yoav Goldberg关于word2vec的论文,对 negative-sampling 的公式推导非常完备
word2vec Parameter Learning Explained
Xin Rong关于word2vec的论文,非常不错
- 1
- 2
-
ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
旋转位置嵌入(RoPE)论文,这是作者本人对它的解读 -
Linearized Relative Positional Encoding
统一了适用于linear transformer的相对位置编码 -
SEARCHING FOR ACTIVATION FUNCTIONS
SwiGLU的原始论文 -
《The Natural Language Decathlon:Multitask Learning as Question Answering》
GPT-1、GPT-2论文的引用文献,Salesforce发表的一篇文章,写出了多任务单模型的根本思想 -
Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916, 2022
-
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
ZeRO是微软deepspeed的核心,这是关于ZeRO的解读之一 -
Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
Megatron-LM 论文原始论文
对相关技术的解读:千亿参数开源大模型 BLOOM 背后的技术 -
Efficient sequence modeling综述
包含sparse transformer、linear transformer(cosformer,transnormer)
RNN(RWKV、S4),Long Conv(TNN、H3) -
Vicuna tackle the memory pressure by utilizing gradient checkpointing and flash attention
Training Deep Nets with Sublinear Memory Cost -
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
-
Unifying Large Language Models and Knowledge Graphs: A Roadmap
LLM与知识图谱的结合实战 -
Fast Transformer Decoding: One Write-Head is All You Need
Muti Query Attention论文,MQA 是 19 年提出的一种新的 Attention 机制,其能够在保证模型效果的同时加快 decoder 生成 token 的速度,这是其解读之一 -
GQA: Training Generalized Multi-Query Transformer Models fromMulti-Head Checkpoints
Grouped-Query Attention论文 -
Flashattention: Fast and memory-efficient exact attention with io-awareness
Flash Attention论文,这是其解读之一
第三部分 Meta等公司发布的类ChatGPT开源模型和各种微调(7篇,总56篇)
-
LLaMA: Open and Efficient Foundation Language Models
2023年2月24日Meta发布了全新的65B参数大语言模型LLaMA,开源,大部分任务的效果好于2020年的GPT-3
这是针对该论文的解读之一 -
SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions
代码地址,解读1、解读2
3月中旬,斯坦福发布Alpaca:只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型
而斯坦福团队微调LLaMA的方法,便是来自华盛顿大学Yizhong Wang等去年底提出的这个Self-Instruct具体而言,论文中提出,首先从自生成指令种子集中的175个人工编写的「指令-输出」对开始,然后,提示text-davinci-003使用种子集作为上下文示例来生成更多指令
而斯坦福版Alpaca,就是花了不到500美元使用OpenAI API生成了5.2万个这样的示例微调LLaMA搞出来的 -
Alpaca: A Strong Open-Source Instruction-Following Model
-
Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022
-
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
-
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
2022年5月,正式提出了GLM框架 -
GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL,代码地址
GLM-130B便是基于的GLM框架的大语言模型
第四部分 具备多模态能力的大语言模型(11篇,总67篇)
-
BEiT: BERT Pre-Training of Image Transformers
-
BEiT-2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
-
Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
这是针对该论文的解读之一
2022年8月,微软提出的多模态预训练模型BEiT-3 -
Language Is Not All You Need: Aligning Perception with Language Models
微软23年3月1日发布的多模态大语言模型Kosmos-1的论文 -
PaLM-E: An Embodied Multimodal Language Model(论文地址)
Google于23年3月6日发布的关于多模态LLM:PaLM-E,可让能听懂人类指令且具备视觉能力的机器人干活 -
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
微软于23年3月8日推出visual ChatGPT(另,3.9日微软德国CTO说,将提供多模态能力的GPT4即将一周后发布)
At the same time, Visual Foundation Models, such as Visual Transformers or Stable Diffusion, although showing great visual understanding and generation capabilities, they are only experts on specific tasks with one round fixed inputs and outputs.To this end, We build a system called {Visual ChatGPT}, incorporating different Visual Foundation Models, to enable the user to interact with ChatGPT by
- sending and receiving not only languages but also images
- providing complex visual questions or visual editing instructions that require the collaboration of multiple AI models with multi-steps.
- providing feedback and asking for corrected results.
We design a series of prompts to inject the visual model information into ChatGPT, considering models of multiple inputs/outputs and models that require visual feedback
-
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
minigpt-4的介绍页面、GitHub -
Flamingo: a visual language model for few-shot learning
-
Tensor programs v: Tuning large neural networks via zero-shot hyperparameter transfer. arXiv preprint arXiv:2203.03466, 2022
-
Language models are unsupervised multitask learners. 2019
-
Improving language understanding by generative pre-training. 2018
第五部分 AI绘画与多模态能力背后的核心技术(21篇,总88篇)
-
End-to-End Object Detection with Transformers
DETR by 2020年5月,这是针对DETR的解读之一 -
AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
发表于2020年10月的Vision Transformer原始论文,代表Transformer正式杀入CV界 -
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows,发表于21年3月
解读戳这 -
Swin Transformer V2: Scaling Up Capacity and Resolution
解读戳这里 -
Auto-Encoding Variational Bayes
苏剑林关于VAE的解读之一,这是另外一个作者:基于苏这个VAE的解读对扩散模型的理解
WGAN -
Denoising Diffusion Probabilistic Models
2020年6月提出DDPM,即众人口中常说的diffusion model
这是苏剑林关于DDPM的相对通俗的系列解读,这是另一份解读:What are Diffusion Models?(该解读的中文笔记) -
Diffusion Models Beat GANs on Image Synthesis
使用classifier guidance的方法,引导模型进行采样和生成 -
High-Resolution Image Synthesis with Latent Diffusion Models
2022年8月发布的Stable Diffusion基于Latent Diffusion Models,专门用于文图生成任务
这些是相关解读:图解stable diffusion(翻译版之一)、这是另一解读,这里有篇AI绘画发展史的总结Stable Diffusion和之前的Diffusion扩散化模型相比, 重点是做了一件事, 那就是把模型的计算空间,从像素空间经过数学变换,在尽可能保留细节信息的情况下降维到一个称之为潜空间(Latent Space)的低维空间里,然后再进行繁重的模型训练和图像生成计算
-
Aligning Text-to-Image Models using Human Feedback,这是解读之一
ChatGPT的主要成功要归结于采用RLHF来精调LLM,近日谷歌AI团队将类似的思路用于文生图大模型:基于人类反馈(Human Feedback)来精调Stable Diffusion模型来提升生成效果
目前的文生图模型虽然已经能够取得比较好的图像生成效果,但是很多时候往往难以生成与输入文本精确匹配的图像,特别是在组合图像生成方面。为此,谷歌最新的论文提出了基于人类反馈的三步精调方法来改善这个问题 -
CLIP: Connecting Text and Images - OpenAI
这是针对CLIP论文的解读之一
CLIP由OpenAI在2021年1月发布,超大规模模型预训练提取视觉特征,图片和文本之间的对比学习(简单粗暴理解就是发微博/朋友圈时,人喜欢发一段文字然后再配一张或几张图,CLIP便是学习这种对应关系) -
Zero-Shot Text-to-Image Generation
DALL·E原始论文 -
Hierarchical Text-Conditional Image Generation with CLIP Latents
这是解读之一
DALL·E 2论文2022年4月发布(至于第一代发布于2021年初),通过CLIP + Diffusion models,达到文本生成图像新高度 -
BLIP (from Salesforce) released with the paper BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
-
BLIP-2 (from Salesforce) released with the paper BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
-
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
23年5月发布的InstructBLIP论文,这是其解读之一 -
LAVIS: A Library for Language-Vision Intelligence
Salesforce开源一站式视觉语言学习框架LAVIS,这是其GitHub地址:https://github.com/salesforce/LAVIS -
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
对各种多模态模型的评测,这是其解读之一 -
Segment Anything
23年4.6日,Meta发布史上首个图像分割基础模型SAM,将NLP领域的prompt范式引进CV,让模型可以通过prompt一键抠图。网友直呼:CV不存在了! -
A Comprehensive Survey on Segment Anything Model for Vision and Beyond
对分割一切模型SAM的首篇全面综述:28页、200+篇参考文献,这是其中文介绍链接 -
Fast Segment Anything
中科院版的分割一切,这是FastSAM的解读之一 -
MobileSAM
比SAM小60倍,比FastSAM快4倍,速度和效果双赢
第六部分 预训练模型的发展演变史(3篇,总91篇)
-
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT:https://arxiv.org/pdf/2302.09419
预训练基础模型的演变史 -
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
-
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
作者来自CMU的刘鹏飞,这是相关资源另一篇类似的,Pre-Trained Models: Past, Present and Future
21年1月初在CCF启智会支持下,文继荣、唐杰和黄民烈三位老师召集了以预训练模型为主题的闭门研讨会,此后22位老师和同学经过近半年准备,共同形成了这篇43页的综述和观点文章 Pre-Trained Models: Past, Present and Future
第七部分 垂域版类ChatGPT(比如医疗GPT)和其它(10篇,总101篇)
-
Large Language Models Encode Clinical Knowledge
挺有意思的,从palm - flan palm(指令微调palm模型) - instruction prompt-tuned Flan-PaLM(提示指令调优flan-palm模型)的过程中,通过instruction prompt-tuned Flan-PaLM得到医疗问答模型med-palm,而提出了instruction prompt tuning的方法
如下图所示,在Instruction prompt tuning中,微调的参数主要是"soft prompt vectors",也就是软提示向量。这些向量通常被添加到输入的开始部分,作为一种"prompt"来引导模型的输出(这句话比较关键),这些soft prompt vectors在训练过程中通过反向传播进行学习和调整,模型的其余部分(包括词嵌入参数和其他参数)通常保持冻结,不进行调整

说白了,medpalm 就是在模型(flan palm)的输入层加了个提示向量,然后反向传播去微调这个提示向量…而这个提示向量的作用就是引导模型输出
下图是论文中展示的提示示例(一些垂域版的类ChatGPT,比如chatdoctor 也是这种数据格式)
故本质还是一个prompt learning,但为了让模型的输出更好 去微调prompt
所以合起来成了:instruction prompt tuning
相当于:fine tuning instruction prompt有点像:不用人工费力设计prompt,自动出prompt的感觉
总之,在训练方法上
通过对比40个样例下,模型的输出与参考QA,然后以此去fine tuning prompt,以激发模型更好的回答
之后 通过7大医学数据集评估
全程下来 并不涉及flan palm模型原本参数的更改,很6了
-
Towards Expert-Level Medical Question Answering with Large Language Models
继上篇论文提出medpalm之后,5月16日,Google Research和DeepMind发布了Med-PaLM 2,相比第一代最显著的改进是基座模型换成了Google的最新大模型PaLM2(据说有着340b参数,用于训练的token数达3.6万亿)重点提一下它的其中两个显著特点
自我一致性(Self-consistency)自我一致性(SC)是Wang等人提出的一种策略,通过从模型中采样多个解释和答案来提高多项选择基准测试上的性能。最终答案是得票最多(或相对多数)的答案。对于像医学这样复杂的推理路径域来说,正确答案可能有多种潜在的路径。边缘化推理路径可以得出最准确的答案。自我一致性提示策略对Lewkowycz等人[44]的工作产生了特别强的改进。在这项工作中,我们使用与Singhal等人相同的CoT提示进行11次采样的自我一致性集成精炼(Ensemble refifinement) 在思维链和自我一致性的基础上,我们开发了一种简单的提示策略,称为集成精炼(ER)。ER建立在其他技术的基础上,这些技术涉及在产生最终答案之前使LLM对其自己的生成进行条件设置,包括思维链提示和自我精炼
ER涉及一个两阶段过程:首先,给定一个(少样本)思维链提示和一个问题,模型通过温度采样随机产生多个可能的生成。在这种情况下,每个生成都涉及对多项选择问题的解释和答案。然后,模型在原始提示、问题和前一步骤的连接生成的条件下,被提示产生精炼的解释和答案。这可以解释为自我一致性的推广,其中LLM正在聚合第一阶段的答案,而不仅仅是简单的投票,使LLM能够考虑它生成的解释的优点和缺点。
在这里,为了提高性能,我们多次执行第二阶段,然后最终对这些生成的答案进行多数票投票,以确定最终答案。集成精炼如下图所示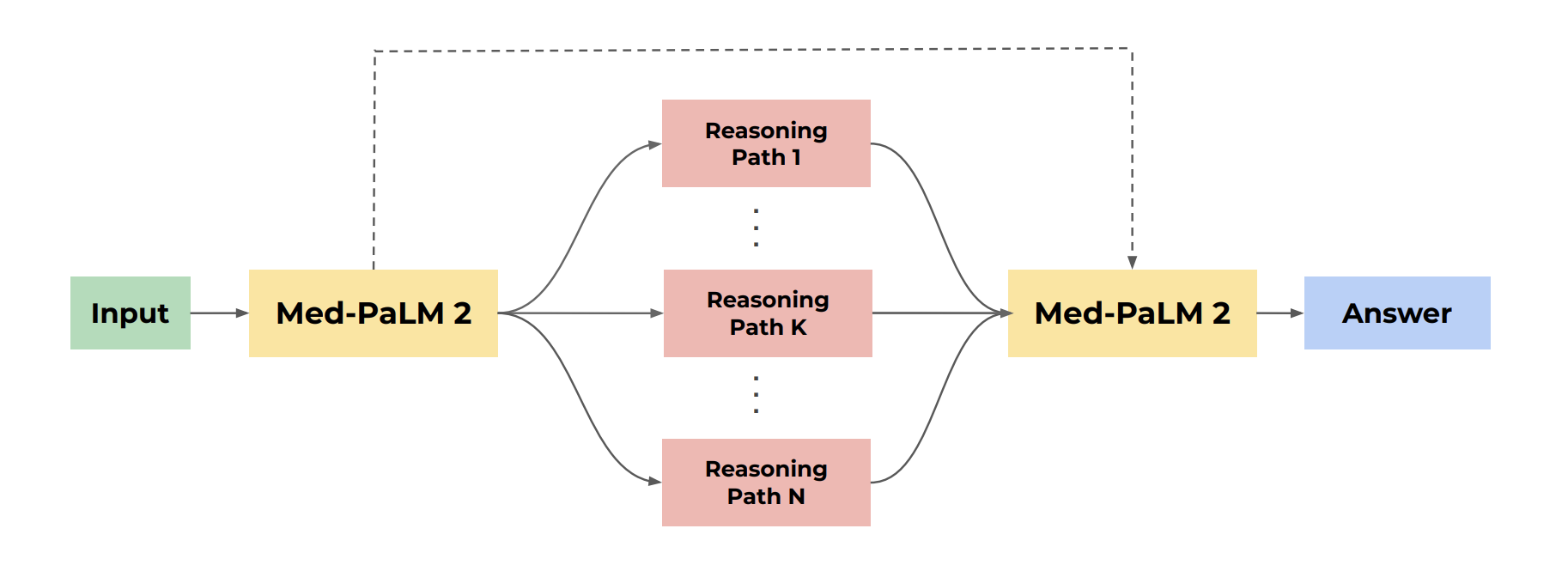
-
ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge
医疗ChatDoctor论文 -
BloombergGPT: A Large Language Model for Finance
金融BloombergGPT论文,这是其解读之一 -
Deep Residual Learning for Image Recognition
ResNet论文,短短9页,Google学术被引现15万多
这是李沐针对ResNet的解读,另 这是李沐针对一些paper的解读列表 -
WHAT LEARNING ALGORITHM IS IN-CONTEXT LEARNING? INVESTIGATIONS WITH LINEAR MODELS
-
Transformer-XL: Attentive language models beyond a fixed-length context
-
An empirical analysis of compute-optimal large language model training
-
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
-
COLT5: Faster Long-Range Transformers with Conditional Computation
-
Offsite-Tuning: Transfer Learning without Full Model

