
- 1使用Jellyfin创建媒体库_jellyfin怎么添加媒体库
- 2如何保护大模型API安全_通过api接口接入商用大模型 安全性低
- 3用python实现画一个彩色风车_python出题,你能画出如下的风车吗?
- 4吴军的谷歌方法论
- 5利用神经网络进行图像生成_神经网络生成图像
- 6Codeforce/Atcoder/Leetcode题目分数/近期比赛网址_lc-rating
- 7YOLOv8添加注意力机制小总结_yolov8注意力机制
- 8Linux查看端口占用的进程号,通过进程号查看path
- 9linux 权限500 0是什么意思,linux用户类型与文件权限介绍
- 10群晖 root_「群晖系统」群晖DSM 6.2获取root权限设置root密码方法
书生·浦语大模型实战训练营第二期第五节--LMDeploy 量化部署 LLM&VLM实战--notebook_书生vlm
赞
踩
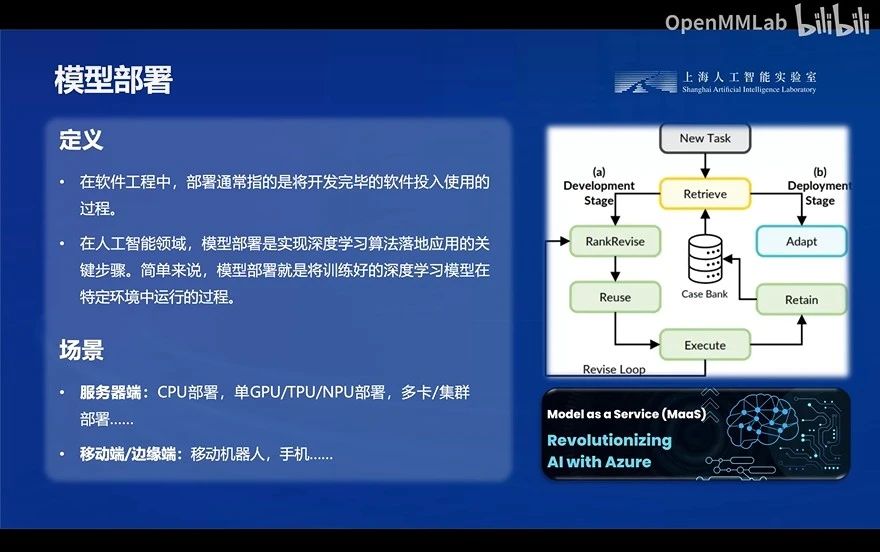
一、模型部署概论
主打的其实就是一句话:大模型落地应用!用于现实中的特定场景!
二、大模型部署面临的挑战
1.计算量巨大
其实就是大模型的参数太多了,看看人家GPT3.0就有1750亿个参数,在用户访问大模型的时候,一个问题丢过去,人家大模型前向推理就需要进行大量计算,生成一个token那就是千万亿级的计算量,难怪说人家GPT每天的耗电量不知道有多少哈哈哈。
而且除了大模型的参数影响,还有BS的设置,一个大模型那不可能是一次就处理一句话啦(批处理量),BS越大,模型前向推理一次的计算量那就是成倍的长啊!
batch size=每次处理的用户对话数量(批处理量)


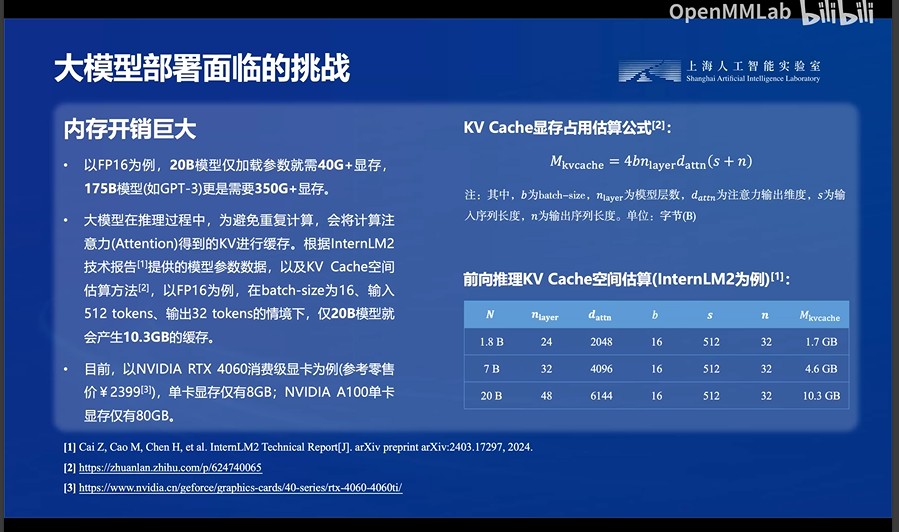
2.内存开销巨大
GPU的显存根本耗不起,A100才80G显存,你自己看看下面这大模型加载的时候都需要这么大的显存,还部署个毛。而且还有KV的缓存,顶不住啊顶不住!得多少张A100一起玩啊!
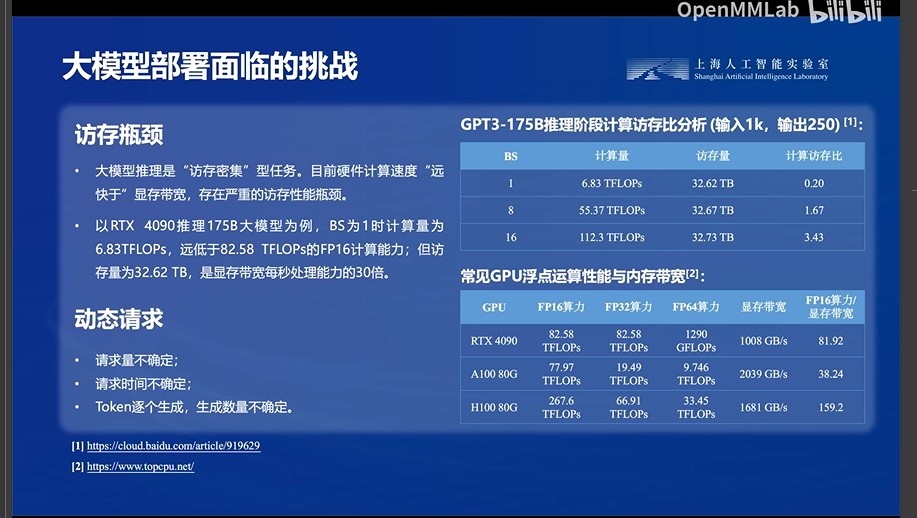
3.访存瓶颈和动态请求问题
3.1 访存瓶颈:其实感觉就是以RTX4090跑一个GPT3的175B参数,BS=1的模型来说,其计算能力是够用的,但是显存带宽跟不上,导致无法发挥4090的全部计算能力,时间基本都花在数据交换上,GPU一直在摸鱼(毕竟大模型是访存密集的任务,访问不了还算个屁)---无法充分发挥GPU得计算能力!
但是可以看到的是,大模型自身的计算量在增加时,其访存量不怎么变化,所以是不是模型自身的计算量上去了,基本就能平衡这个访存量,充分发挥GPU的算力不要再摸鱼了?但是你要考虑一下模型计算量这么大,现在的GPU哪里跑得动?显存根本不够啊
3.2 动态请求里面:对于深度学习来说,输入的tensor最好是固定的哈,这样才能充分发挥一下GPU的性能,不然有的长有的短,那短的需求要等长的那哥们搞完才轮到它,下面有poe的解释:

三、大模型部署方法(其实就是针对以上大模型部署的问题提出的解决方法啦)
1 模型剪枝(Pruning):移除模型中不必要的组件(如参数),保证模型性能下降最小的同时,减小存储需求,提高计算效率。分为以下两类:
A:非结构化剪枝:移除个别参数,不考虑整体网络结构(眼睛就盯着那个逼参数低于阈值的就给我滚蛋,万一破坏了整个结构也无所谓),精细化一个个去筛掉,不错杀好人,不漏杀坏人,就是有可能整个结构都是坏人全给你杀光了,影响整个结构!(大明王朝-海瑞!)
B:结构化剪枝:根据预定规则去整个整个的移除连接或者分层结构,同时保持整体结构的完整(保证整体模型结构的完整前提下,一块一块的剪掉,可以降低模型复杂性,缺点就是可能会误剪一些好的参数,和漏掉一些坏参数),不像上面那家伙,精细化一个个去剪掉

2.知识蒸馏:核心还是因为模型有冗余参数,也就是这个模型理论上是可以以更少的参数来达到同等的效果
但是你不可能直接训练一个少参数的模型就想让它达到像这个多参数模型一样的效果哈哈哈;
所以就提出一种,先训练一个大的教师模型,再让这个大教师模型去训练一些小的学生模型,来达到一个知识迁移的效果,以此达到一种,少参数(学生)但是拥有多参数模型(教师)的能力的小模型。

3.量化:将传统的浮点数转换为整数或者其它形式,减轻模型的存储和计算负担
但其实对于大模型来说,这个减轻计算负担的意思跟普通的计算机理论理解不一样:为啥它能提高计算效率,核心还是因为前面刚刚提到的GPU训练大模型时的访存瓶颈的问题,计算能力远大于访存能力,而这个量化一定程度是将大模型的访存量降低(Float32-Float16-Float8,这模型的访存量直接成倍的降),这样不就是减少了GPU访问大模型参数的时间咯,总体来看就是减少了推理时间咯

四、专业的模型部署解决方案开发-LMDeploy(就是专业的团队开发出来的解决以上模型部署问题的方案咯)

LMDeploy涵盖了LLM任务的全套轻量化、部署和服务解决方案。

LMDeploy就是一个专注于模型部署过程中的各种问题啦,专业的人干专业得事情!
这三个核心功能:部署方便、推理速度快!(也就是解决了模型的三个大问题的结果咯:计算量大/内存需求大/访存瓶颈
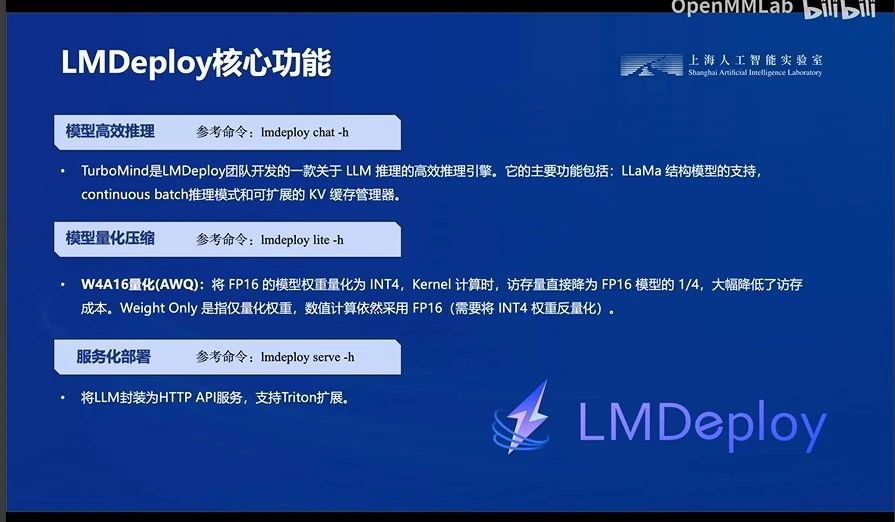
性能表现也非常的牛逼


下面就是动手实战开工啦!
实战的训练项目详见下一篇博客咯!

