
- 1java切分字符串的两种方法_java字符串拆分
- 2APA技术方案及关键点_apa方案
- 3Transformer时间序列预测-多变量输入-单变量输出+多变量输出,完整代码数据,可直接运行_transformer多输入单输出
- 4MYDB项目启动教程
- 5测试工程师必须要学会性能测试,只会功能测试真的可能被淘汰..._不做性能测试会怎样
- 6基本数据结构底层原理——线性存储和链式存储_什么是线性存储
- 7为什么w要找s做经纪人?------聊聊软件系统中agent的构思与作用_什么是w经纪
- 8win11跳过联网激活步骤
- 9AI绘画干货--SD模型VAE与提示词写法_sd vae模型
- 10【哈士奇赠书活动 - 38期】- 〖构建新型网络形态下的网络空间安全体系〗
YOLOv8添加注意力机制小总结_yolov8注意力机制
赞
踩
注意力机制(Attention Mechanism)源于对人类视觉的研究。 在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。 上述机制通常被称为注意力机制。 人类视网膜不同的部位具有不同程度的信息处理能力,即敏锐度(Acuity),只有视网膜中央凹部位具有最强的敏锐度。
简而言之,注意力机制源于自然界人类视觉的研究。人类的视觉会天然地进行一个抉择,就是选择性地关注所有信息的一个部分,同事就会忽略其他可见的信息。就属于是合理的利用有限的信息处理资源。
注意力机制的分类示意图

1、SE注意力模块
SEnet(Squeeze-and-Excitation Network)考虑了特征通道之间的关系,在特征通道之间的关系,在特征通道之间引入了注意力机制这么个东西。
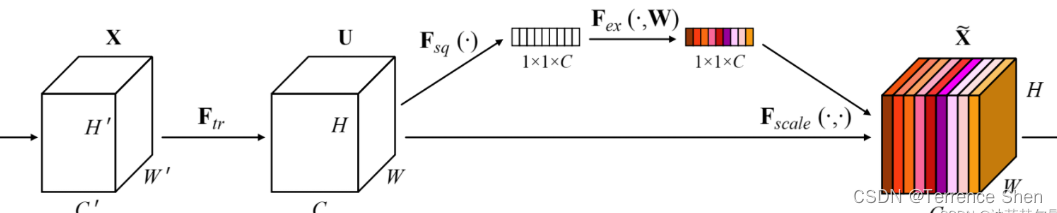
# SE class SE(nn.Module): def __init__(self, c1, ratio=16): super(SE, self).__init__() self.avgpool = nn.AdaptiveAvgPool2d(1) self.l1 = nn.Linear(c1, c1 // ratio, bias=False) self.relu = nn.ReLU(inplace=True) self.l2 = nn.Linear(c1 // ratio, c1, bias=False) self.sig = nn.Sigmoid() def forward(self, x): b, c, _, _ = x.size() y = self.avgpool(x).view(b, c) y = self.l1(y) y = self.relu(y) y = self.l2(y) y = self.sig(y) y = y.view(b, c, 1, 1) return x * y.expand_as(x)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2、CBAM注意力模块
CBAM(Convolutional Block Attention Module ) 集合了特征通道和特征空间两个维度的注意力机制。

CBAM通过学习的方式自动获得每个特征通道的重要程度,和SEnet相似。此外还可以通过类似的学习方式自动获取每个特征空间的重要程度。并且利用得到的重要程度来提升特征并且抑制对当前任务不重要的特征。

CBAM提取特征通道注意力的方式和SEnet类似,如下channel Attention中的代码所示,其在SEnet的基础上增加了max_pool的特征提取方式,其余步骤是一样的。将通道注意力提取后的特征作为空间注意力模块的输入。

而CBAM提取空间注意力的方式是: 经过ChannelAttention后, 最终将经过通道重要性选择后的特征图送入特征空间注意力模块,和通道注意力模块相似,空间注意力是以通道为单位进行最大池化合平均池化,并将两者的结果进行concat,之后再进行一个卷积降成 1wh的特征空间权重,在讲该权重和输入特征进行点积,从而实现空间注意力机制。
# CBAM class ChannelAttention(nn.Module): # Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet def __init__(self, channels: int) -> None: super().__init__() self.pool = nn.AdaptiveAvgPool2d(1) self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True) self.act = nn.Sigmoid() def forward(self, x: torch.Tensor) -> torch.Tensor: return x * self.act(self.fc(self.pool(x))) class SpatialAttention(nn.Module): # Spatial-attention module def __init__(self, kernel_size=7): super().__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.act = nn.Sigmoid() def forward(self, x): return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1))) class CBAM(nn.Module): # Convolutional Block Attention Module def __init__(self, c1, kernel_size=7): # ch_in, kernels super().__init__() self.channel_attention = ChannelAttention(c1) self.spatial_attention = SpatialAttention(kernel_size) def forward(self, x): return self.spatial_attention(self.channel_attention(x))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
3、 ECA注意力模块
先前的方法大多致力于开发更复杂的注意力模块,以实现更好的性能,这不可避免地增加了模型的复杂性。为了克服性能和复杂性之间的矛盾,作者提出了一种有效的通道关注(ECA)模块,该模块只增加了少量的参数,却能获得明显的性能增益。

# ECA class ECA(nn.Module): def __init__(self, k_size=3): super(ECA, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): y = self.avg_pool(x) y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1) y = self.sigmoid(y) return x * y.expand_as(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4、CA注意力模块
先前的轻量网络的注意力机制大多数采用了SE模块,仅仅考虑了通道之间的信息,忽略了位置信息。尽管后来的CBAM和BAM尝试在降低通道数后通过聚氨基来提取位置注意力信息,但卷积只能提取局部信息,缺乏长距离关系提取的能力。 为此,论文提出了新的高效注意力机制 coordinate attention(CA),能够将横向和纵向的位置信息编码到channel attention中, 使得移动网络能够关注大范围的位置信息有不会带来过多的计算量。

# CA class h_sigmoid(nn.Module): def __init__(self, inplace=True): super(h_sigmoid, self).__init__() self.relu = nn.ReLU6(inplace=inplace) def forward(self, x): return self.relu(x + 3) / 6 class h_swish(nn.Module): def __init__(self, inplace=True): super(h_swish, self).__init__() self.sigmoid = h_sigmoid(inplace=inplace) def forward(self, x): return x * self.sigmoid(x) class CoordAtt(nn.Module): def __init__(self, inp, oup, reduction=32): super(CoordAtt, self).__init__() self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) self.pool_w = nn.AdaptiveAvgPool2d((1, None)) mip = max(8, inp // reduction) self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0) self.bn1 = nn.BatchNorm2d(mip) self.act = h_swish() self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0) self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0) def forward(self, x): identity = x n, c, h, w = x.size() x_h = self.pool_h(x) x_w = self.pool_w(x).permute(0, 1, 3, 2) y = torch.cat([x_h, x_w], dim=2) y = self.conv1(y) y = self.bn1(y) y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2) x_w = x_w.permute(0, 1, 3, 2) a_h = self.conv_h(x_h).sigmoid() a_w = self.conv_w(x_w).sigmoid() out = identity * a_w * a_h return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
5、 注意力机制的添加方式
5.1 、检测 分割 关键点任务
大致的修改方法:
在YOLOv8中添加注意力机制主要分为以下5步,以在yolov8.yaml中添加SE注意力机制为例:
1、在ultralytics/models/v8 文件夹下新建一个yolov8-SE.yaml 文件;
2、 将文中上面提供的SE注意力代码添加到 ultralytics/nn/modules.py 中;
3、 将SE这个类的名字加入到 ultralytics/nn/tasks.py中;
4、修改yolov8-SE.yaml , 将SE注意力机制加入到需要的位置上去;
5、 修改 ultralytics/yolo/cfg/default.yaml 文件中的 ‘–model’ 默认参数,或者直接使用指令,随后就可以开始训练网络模型了。
详细的修改方法如下所示:
- 第1步、在ultralytics/models/v8 文件夹下新建一个yolov8-SE.yaml
文件,将yolov8.yaml文件内容拷贝粘贴到新建的这个文件当中来等待第4步对它进行改造; - 第2步、 将文中上面提供的SE注意力代码添加到 ultralytics/nn/modules.py 中(文件末尾即可);
# SE class SE(nn.Module): def __init__(self, c1, ratio=16): super(SE, self).__init__() self.avgpool = nn.AdaptiveAvgPool2d(1) self.l1 = nn.Linear(c1, c1 // ratio, bias=False) self.relu = nn.ReLU(inplace=True) self.l2 = nn.Linear(c1 // ratio, c1, bias=False) self.sig = nn.Sigmoid() def forward(self, x): b, c, _, _ = x.size() y = self.avgpool(x).view(b, c) y = self.l1(y) y = self.relu(y) y = self.l2(y) y = self.sig(y) y = y.view(b, c, 1, 1) return x * y.expand_as(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 第3步:首先将SE模块import一下, 然后将SE这个类的名字加入到
ultralytics/nn/tasks.py中,如下图所示的位置处;


4、修改yolov8-SE.yaml , 将SE注意力机制加入到需要的位置上去;
常见的位置有C2f模块的后面 , Neck脖子部分中, 也可以在主干部分的SPPF前面添加一层; (如下图所展示的样子),那么随后,后面的每一层的编号也就改变了,加1,记得concat那里输入的参数from就需要随机应变;

比如后面的detec检测头的输入也会随之改变:

5、 修改 ultralytics/yolo/cfg/default.yaml 文件中的 ‘–model’ 默认参数,在’–model’后面加上刚创建好的yolov8-SE.yaml文件的路径,或者直接使用指令,随后就可以开始训练网络模型了。

或者使用如下指令:
yolo detect train data=coco128.yaml model=D:\Pycharm_Projects\ultralytics\ultralytics\models\v8\yolov8-SE.yaml epochs=200 imgsz=640
- 1
- 2
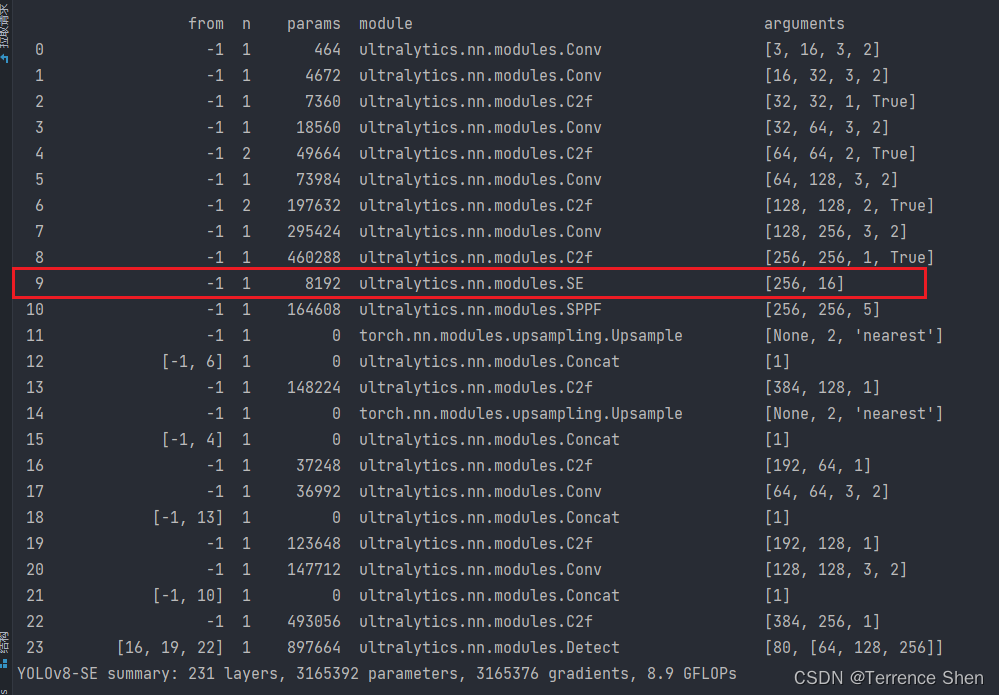
完整的yaml文件如下:
# Ultralytics YOLO 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/煮酒与君饮/article/detail/873802Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

