
- 1springboot中使用rabbitmq_correlationdataext
- 2关于微信小程序uniapp版的推送消息_uniapp微信小程序消息推送
- 3Flink cdc正确打开方式(flink on yarn)
- 4trans系列是sci几区_中五百万都比不过发5篇SCI论文?一起来扒一下SCI那点事
- 5openGauss学习笔记-115 openGauss 数据库管理-设置安全策略-设置密码安全策略_opengauss 修改用户密码
- 6【Flink】Flink 任务实时监控_flink任务监控
- 7Linux 中用户与权限_linux给用户加权限
- 8今天我们来聊一聊孟德尔随机化
- 9Java基础知识整理_java知识点
- 10element-ui的el-table与el-form的使用与表单校验_el-form 对el-checkbox校验
我们的网站被狗爬了!
赞
踩
大家好,我是程序员鱼皮。
世风日下,人心不古。我们的程序员面试刷题网站 《面试鸭》 才刚刚上线了一个多月,就由于过于火爆,被不少同行和小人发起网络攻击。
而且因为我们已经有 4500 多道人工整理的企业高频面试题、100 多个各方向的面试题库、大厂面试官原创的优质题解,所以也招来了不少爬虫。
网站有爬虫是很正常的一件事,说明 “攻击者” 对我们网站内容的认可,而且自己学习用的话偷偷爬一爬咱也能理解。前提是别影响咱系统的正常运行、别被我们的监控系统发现。
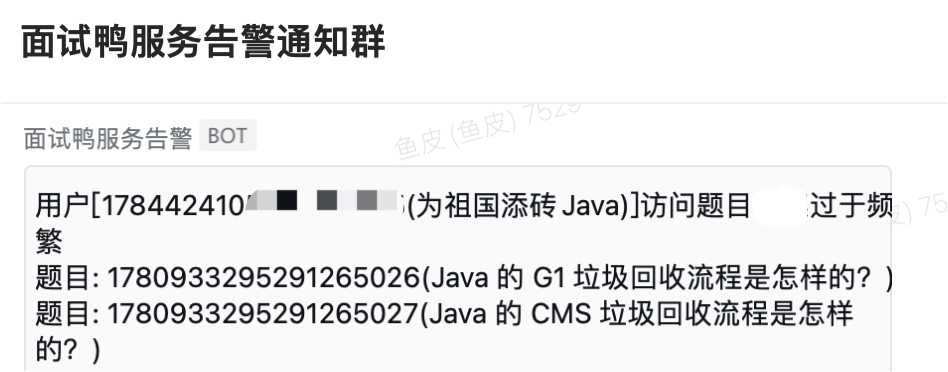
我们确实发现了部分离谱的用户,不到一个小时就把我们几千道题看完了?你特么量子波动速读啊?!

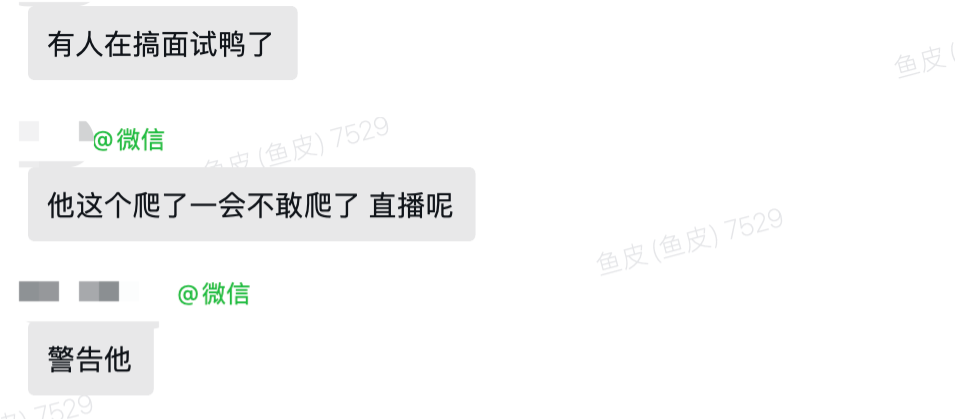
上面这些其实都还好,系统自动就给封号了。但最近我们接到正义的用户反馈,最近有几只程序员博主公开 直播教别人 怎么爬我们的面试鸭网站,这属实是有点过分了吧?
有点儿法律常识的程序员应该都知道,爬虫是有法律风险的行为,可能会涉及到侵犯版权、违反网站的使用条款、侵犯隐私。而且如果请求频率过高,对系统造成了压力,还可能涉及到计算机系统破坏、违反计算机滥用法的法律风险!
所以才有了下面这个表情包:

在未经原站长授权的情况下,教别人去爬取别人的网站,这性质就更不一样了,而且还是直播去教,生怕别人不知道你是谁么? 可邢,太可邢了!

而且最让我生气的是,有些博主教爬虫都不教明白,教爬虫的第一课必然要先让大家了解 爬虫的法律合规性和法律风险 。应该告诉大家相关法律法规、遵守网站的使用协议和版权问题、遵守网站的 robots.txt 文件、确保爬取行为不侵犯他人的知识产权等等,而不是在诱导大家去爬取他人的网站。
这里鱼皮给大家列举下爬虫前的注意事项:
1)遵守网站的使用条款:仔细阅读网站的使用条款和服务协议,确定是否允许抓取和数据使用。有些网站可能明确禁止抓取或设定了抓取的条件,违反这些条款可能会导致法律问题。
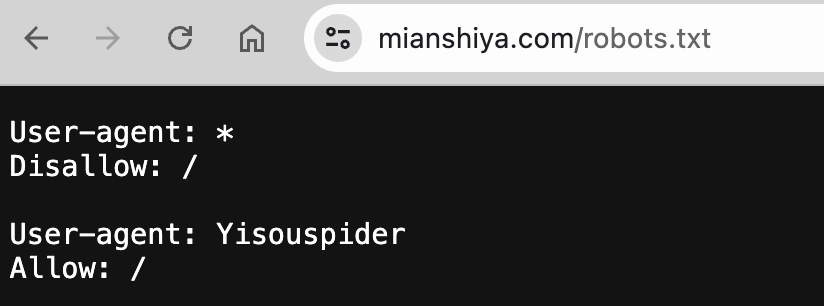
2)遵守 robots.txt 文件:这个文件表示了网站对爬虫抓取的规则,某些页面如果明确标注了禁止抓取,建议不要下手。
比如我们面试鸭的 robots.txt 文件,第一行就是先禁用所有的爬虫,然后再给搜索引擎开放一些抓取。
3)不要抓取付费内容:一般付费内容都是申请了版权 / 著作权的,未经授权的抓取和传播可能涉及侵犯版权、会导致实际的赔偿。而且一般付费内容都是仅付费用户才能查看的,付费用户往往更好追溯到源头,千万别侥幸地以为别人查不到你!
4)控制好爬虫的频率:前面也提到了,如果你的爬虫请求频率过高,影响了网站的正常运行,那么性质就变成 “网络攻击” 了,后果往往更严重。而且一般情况下,网站都有反爬虫的防护措施,请求频率过高要么给你限流、要么直接封 IP、封账号,千万别以为是开玩笑。
总之,技术本身是无罪的,但用不好是真的会进局子的!大家直接在 面试鸭网站 或小程序上就能搜题、看题了,也没必要再专门用爬虫把题目搞下来了~
当然,如果大家要学爬虫的话,也许之后鱼皮可以出个项目。。。哈哈,有空再搞!
更多
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

