
- 1小阿轩-云计算·DNS概念以及搭建与部署_云电脑dns
- 2关于论青少年尽早学少儿编程之说_关于少儿编程的金句
- 3高性能的Key-Value数据库:Redis_keyvalue批量查询效率高的数据库
- 4python基础语法总结(超详细)_python基础语法整理汇总
- 5Flutter:选择移动 UI 测试自动化工具_flutter ui自动化
- 6kafka启动命令、查看topic命令、查看消息内容命令
- 7Redis是什么?什么作用?优点和缺点_说一下什么是redis,优缺点是什么
- 8spi通讯协议原理_tle9461 spi通信协议原理
- 9MySQL简单配置GTID_mysql-8.2.0-linux-glibc2.17-x86-64.tar.xz
- 10fiddler手机抓包配置代理后没有网络(手机不能上网)_fiddler配置后手机无法上网
大模型论文解读|腾讯&清华联合打造Eurus:用偏好树推进大语言模型的推理能力大突破_kto算法改进
赞
踩

目录
引言:推动开源大型语言模型(LLMs)在复杂推理任务中的发展
结论:EURUS系列模型的创新点和对开源推理模型发展的推动作用
引言:推动开源大型语言模型(LLMs)在复杂推理任务中的发展
在人工智能领域,开源大型语言模型(LLMs)的发展一直是研究的热点。这些模型在处理自然语言理解和生成任务方面表现出色,但在复杂推理任务上的表现往往不如专有模型。为了缩小这一差距,研究者们不断探索如何提高LLMs在数学、编程和逻辑推理等领域的能力。
最近,一个名为EURUS的新型LLM套件引起了业界的关注。EURUS模型在多个复杂推理基准测试中取得了开源模型中的最佳表现,特别是在大学级别的STEM问题和竞赛级别的编程问题上,EURUS-70B模型的表现甚至与GPT-3.5 Turbo相当。EURUS模型的成功得益于一种新颖的数据集ULTRAINTERACT,它专门为复杂推理任务设计,包含了多种多样的指令和偏好树,这些偏好树包括多种规划策略、多轮与环境和批评者的交互轨迹,以及成对的数据以促进偏好学习。
此外,EURUS模型的训练还采用了新的奖励建模目标,这一目标与ULTRAINTERACT结合使用,产生了一个强大的奖励模型EURUS-RM-7B,它在与人类评注者的相关性方面超越了所有现有模型。EURUS项目的所有模型检查点和ULTRAINTERACT对齐数据都将公开可用,以促进研究的复现和进一步发展。
论文标题:Advancing LLM Reasoning Generalists with Preference Trees
机构:Tsinghua University, University of Illinois Urbana-Champaign, Northeastern University, ModelBest.Inc, Renmin University of China, BUPT, Tencent
论文链接:https://arxiv.org/pdf/2404.02078.pdf
项目地址:https://github.com/OpenBMB/Eurus
关注公众号【AI论文解读】后台回复“论文解读” 获取论文PDF!
EURUS模型介绍
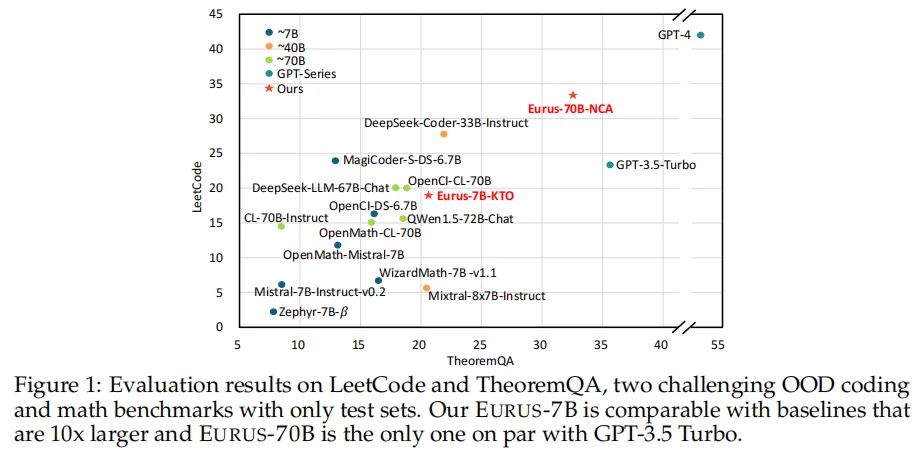
EURUS模型代表了当前开源大型语言模型(LLMs)在复杂推理任务上的最新进展。这一系列模型是从Mistral-7B和CodeLlama-70B两个基础模型微调而来,针对数学、代码生成和逻辑推理等多个领域的复杂问题进行了优化。EURUS模型在一系列包含12个测试的五项任务的综合基准测试中,展现出了超越GPT-3.5 Turbo的推理能力,尤其是在LeetCode和TheoremQA这两个挑战性基准测试中,EURUS-70B模型的通过率分别达到了33.3%和32.6%,大幅领先于现有的开源模型。EURUS模型之所以能够取得如此卓越的性能,很大程度上得益于ULTRAINTERACT数据集的使用。这个专为复杂推理任务设计的大规模、高质量对齐数据集,为EURUS模型的训练提供了强大的支持。
ULTRAINTERACT数据集的创新
ULTRAINTERACT数据集通过其独特的树状结构对齐数据,为复杂推理任务的模型训练提供了创新性的支持。这一数据集的设计思路和特点,为推理优化的LLMs模型,如EURUS系列,提供了有效的训练材料。
1. ULTRAINTERACT数据集的构成和特点
ULTRAINTERACT数据集包含了86K条指令和220K对动作对,每对包含一个指令、一个正确响应和一个错误响应。这些数据采用偏好树的形式组织,每个指令作为根节点,每个动作作为节点,构成了一个多层次的树状结构。这种设计不仅包含了多样化的规划策略和多轮与环境及批评模型的交互轨迹,还有助于偏好学习的实施。通过这种结构,ULTRAINTERACT能够为模型提供丰富的、结构化的学习材料,特别是在处理需要复杂规划和多步骤推理的任务时。

2. 多轮交互轨迹和偏好学习的设计
ULTRAINTERACT数据集的一个关键特点是其对多轮交互轨迹的收集。这些轨迹记录了模型在与环境及批评模型交互过程中的行为,包括模型采取的动作、环境的反馈以及批评模型的建议。这种设计不仅有助于模型学习如何从反馈中改进,还能通过多轮的交互来细化和优化解决方案。此外,通过配对正确和错误的动作,ULTRAINTERACT进一步支持了偏好学习的实施。这种基于偏好树的结构,使得模型能够在每一轮交互中学习到更加精确和具体的偏好信息,从而在复杂的推理任务中表现更佳。
总的来说,EURUS模型的卓越性能和ULTRAINTERACT数据集的创新设计,共同展现了在复杂推理任务上优化LLMs的巨大潜力。通过精心设计的数据集和微调策略,EURUS模型在多个领域的推理任务中取得了前所未有的成绩,为未来LLMs在更广泛应用领域的发展奠定了坚实的基础。
EURUS在多个推理任务中的表现分析
1. 在LeetCode和TheoremQA等挑战性基准测试中的表现
EURUS模型在LeetCode和TheoremQA这两个挑战性基准测试中展现出了卓越的表现。具体来说,在LeetCode测试中,EURUS-70B模型取得了33.3%的pass@1准确率,而在TheoremQA测试中,该模型的准确率为32.6%。这些成绩显著超过了现有的开源模型,领先幅度超过13.3%。这些测试是设计来评估模型在数学、编程和逻辑推理问题上的能力,EURUS在这些领域的强劲表现可归功于其训练数据集ULTRAINTERACT,这是一个专门为复杂推理任务设计的大规模、高质量的对齐数据集。
2. EURUS模型与其他开源模型的对比
EURUS模型在一系列复杂推理基准测试中,包括但不限于数学、代码生成和逻辑推理问题,均取得了开源模型中的最佳整体表现。EURUS-70B模型在大学级别的STEM问题TheoremQA和竞赛级别的编程问题LeetCode Contest中,显著超越了所有开源模型,与GPT-3.5 Turbo的表现相当。EURUS模型的成功,部分得益于其在ULTRAINTERACT数据集上的训练,该数据集包含了多种多样的指令,涵盖了数学、编程和逻辑推理问题。
偏好学习在推理任务中的应用和影响
1. 探讨DPO、KTO和NCA三种偏好学习算法的效果
在推理任务中,EURUS模型采用了三种不同的偏好学习算法:DPO、KTO和NCA。实验结果显示,使用ULTRAINTERACT数据集进行偏好学习,KTO和NCA算法能够一致地提升模型在所有五个数学基准测试和多轮评估中的表现。然而,DPO算法在大多数基准测试中降低了模型的性能。特别是在70B模型上,DPO训练失败,导致奖励值下降至负无穷。这一现象在后续分析中得到了探讨。
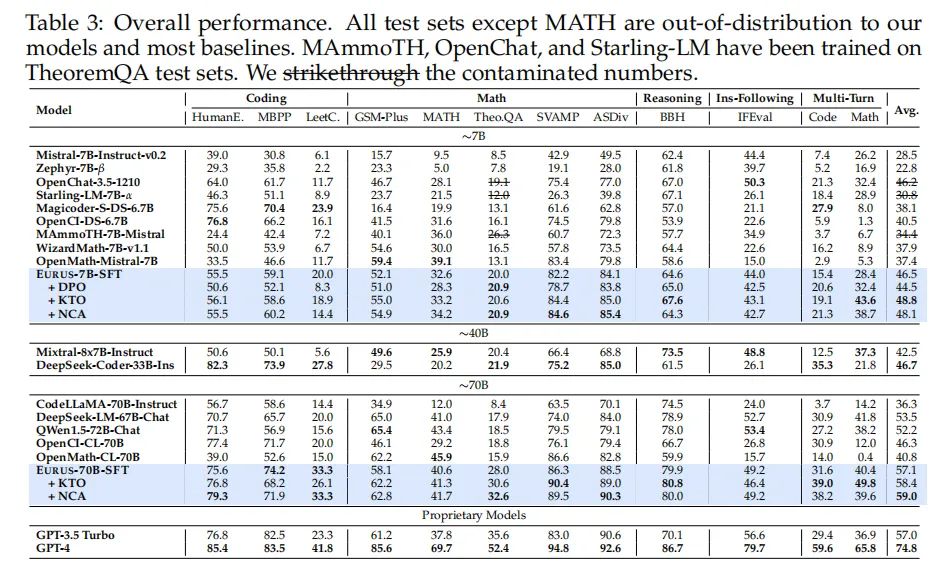
2. 新的奖励建模目标的提出及其对推理能力的促进
EURUS团队提出了一种新的奖励建模目标,以增强传统的Bradley-Terry目标。这一新目标显式地鼓励训练过程中提高选定解决方案的绝对奖励值,并降低被拒绝数据的奖励值。此外,ULTRAINTERACT数据集的引入导致了EURUS-RM-7B奖励模型的诞生,该模型在AutoJ和MT-Bench等奖励建模基准测试中,与人类评注者的相关性超过了所有现有模型,包括GPT-4。EURUS-RM-7B在推理任务上展现了尤为强大的偏好建模性能。
EURUS-RM-7B奖励模型的评估
在探索大型语言模型(LLMs)的推理优化方面,EURUS-RM-7B奖励模型展现出了显著的成效。本章节将对EURUS-RM-7B模型在不同基准测试中的表现进行评估,并探讨其通过重排提升LLMs推理性能的实证结果。
1. 在RewardBench、AutoJ和MT-Bench基准测试中的表现
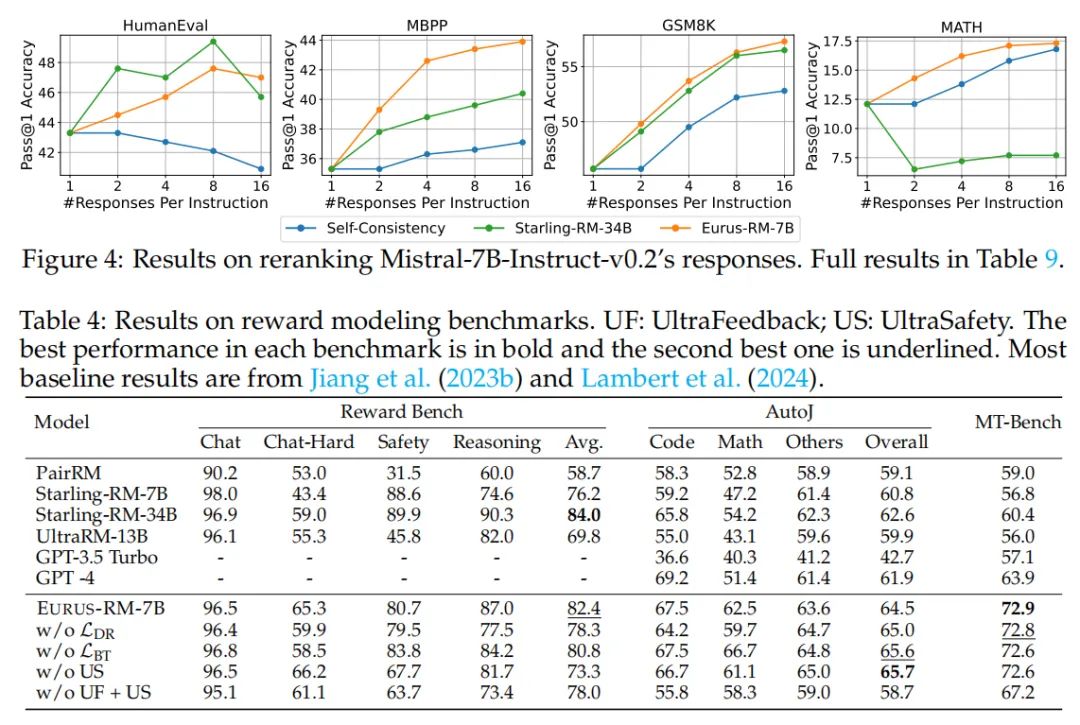
EURUS-RM-7B在多个基准测试中表现出色,尤其在RewardBench、AutoJ和MT-Bench中的成绩引人注目。在RewardBench测试中,EURUS-RM-7B在“Chat-Hard”分割中超越了所有基线模型,并在“Reasoning”分割中也展现了极具竞争力的表现。在AutoJ测试的不同分割中,EURUS-RM-7B几乎在所有任务上都超过了现有模型,唯一的例外是GPT-4在编码任务上的结果。此外,EURUS-RM-7B在MT-Bench测试中也取得了与人类评注员更好的相关性。
EURUS-RM-7B的这些成绩证明了其在奖励模型中的优越性,尤其是在推理任务上的偏好建模性能方面。通过优化LDR(直接奖励差异)来提高奖励模型在困难问题和推理上的表现,而BT(Bradley-Terry)建模则有助于奖励模型在一般聊天方面的能力,尽管其对推理的影响可能有所不同。
2. 通过重排提升LLMs推理性能的实证结果
EURUS-RM-7B通过重排Mistral-7B-Instruct-v0.2的响应,显著提高了LLMs在多个任务上的推理性能。在HumanEval、MBPP、GSM8K和MATH等任务中,EURUS-RM-7B一致提高了pass@1准确率,并且表现优于体量是其5倍的Starling-RM-34B基线模型。EURUS-RM-7B的重排性能随着每条指令的响应数量增加而提升,除了在HumanEval中略有下降。相比之下,Starling-RM-34B在HumanEval上遭受了严重的性能下降,并且在MATH任务上一致降低了模型准确率。
结论:EURUS系列模型的创新点和对开源推理模型发展的推动作用
EURUS系列模型在开源推理模型的发展中扮演了重要的角色,它们的创新点和对整个领域的推动作用体现在以下几个方面:
1. 优化的大型语言模型: EURUS模型是从Mistral-7B和CodeLlama-70B微调而来的大型语言模型(LLMs),专门针对复杂推理任务进行了优化。这些模型在多个包括数学、代码生成和逻辑推理在内的多样化基准测试中取得了最先进的结果,特别是在LeetCode和TheoremQA这两个具有挑战性的基准测试中,EURUS-70B的表现甚至超过了GPT-3.5 Turbo,显示出在开源模型中的领先地位。
2. ULTRAINTERACT数据集:EURUS模型的训练依赖于新策划的大规模、高质量的对齐数据集ULTRAINTERACT,该数据集专为提升LLMs的推理能力而设计。ULTRAINTERACT包含了多样化的指令集,涵盖了数学、编码和逻辑推理问题,并为每个指令构建了包含多种规划策略、多轮与环境和批评模型的交互轨迹、以及成对数据以促进偏好学习的偏好树。这种结构化的数据集为推理任务的偏好学习提供了丰富的资源,并通过实验显示了其在提升模型性能方面的有效性。
3. 偏好学习的深入探索: EURUS系列模型的开发过程中,研究团队深入探索了偏好学习在推理任务中的应用。他们发现一些已建立的偏好学习算法可能不适用于推理任务。基于这一发现,团队提出了一种新的奖励建模目标,与ULTRAINTERACT数据集一起,导致了一个强大的奖励模型EURUS-RM-7B的诞生,该模型在AutoJ和MT-Bench等基准测试中与人类评注者的相关性更强。

