
上海WAIC大会现场“大闹天宫”:模型够猛,产品够酷,公司够强
赞
踩
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
今年上海世界人工智能大会,谁最受关注?
展区现场,有个挤得水泄不通的互动——
像孙猴子一样在全世界大闹天宫的AI大模型,而且真的和《大闹天宫》联动!
只需一张真人正面图片,就能get天庭打工人寸照;在测出属于你的《大闹天宫》版MBTI的同时,玉帝老儿还会赏咱个天上的官儿当当,何不美哉?

这个对大多数人来说见了就挪不动腿的AI互动体验背后,背后还是一支越来越出圈的国产大模型团队。
它不仅手握多模态能力,还在WAIC上亮出了手里最新的万亿MoE大模型。

平时低调,亮相不多,但总是一鸣惊人。
阶跃星辰,微软前全球副总裁,微软亚洲互联网工程院前首席科学家姜大昕创立,出道不早,但后发先至,目前已是公认的大模型第一梯队玩家,位列大模型创业“六小强”。
而且这一次WAIC期间,阶跃星辰展示的大模型能力,不只是和孙悟空携手闹天空那么简单。
万亿MoE+多模态大模型
阶跃目前推出的模型均为Step系列。
新模型发布之前,小结一下过去的成员:今年3月,阶跃共发布3款模型,即Step-1千亿参数语言大模型、Step-1V千亿参数多模态大模型、Step-2万亿参数MoE语言大模型(预览版)。
在这次WAIC,Step家族增加3名新成员。
Step-2万亿参数语言大模型正式版
Step-1.5V千亿参数多模态大模型
Step-1X图像生成大模型
第一个是MoE结构的万亿参数大语言模型,后面二者则是多模态模型。
大语言模型:Step-2正式版
3月底的全球开发者先锋大会开幕式上,阶跃展示了万亿参数MoE语言大模型Step-2的预览版。
不是我说,阶跃是懂什么叫“浅尝辄止”的,只有预览版,让人心痒痒。
好在阶跃团队坚信Scaling Law,因此不断训练更大模型。
这次,Step-2正式版终于正式亮相。
Step-2拥有万亿参数,采用MoE架构,官方介绍,Step-2在数理逻辑、编程、中文知识、英文知识、指令跟随等方面体感全面逼近GPT-4。
背后有阶跃团队花了大心思的巧思在。
首先是创新算法架构。
一般而言,主流训练MoE模型有两种方式,不然就基于已有模型通过upcycle(向上复用)开始训练,不然就从头开始训练。
Upcycle方式所需算力相对更低、训练效率更高,但随随便便就到这种方式的天花板了。
比如基于拷贝复制得到的MoE模型,非常容易出现专家同质化严重的情况。
而选择从头开始训练MoE模型的话,能够探得更高的模型上限,但作为代价,训练难度也会增大。

俗话说得好,勇敢阶跃,不怕困难(doge)。
在设计Step-2的MoE架构时,阶跃星辰迎难而上,完全自主研发,从头开始训练。
过程中,通过部分专家共享参数、异构化专家设计等创新MoE架构设计,Step-2这个混合专家模型中的每个专家都得到了充分训练。
故而,Step-2总参数量达到万亿级别,每次训练或推理所激活的参数量也超过了市面上的大部分Dense模型。
此外,Step-2的训练过程中,阶跃的系统团队突破了6D并行、极致显存管理、完全自动化运维等关键技术,支撑起了整个模型的高效训练。
多模态大模型:追求多模理解和生成的统一
姜大昕曾经坚定表示过,团队追求的是多模理解和生成的统一,“Step系列大模型将为多模理解和生成的统一奠定坚实基础。”
于是,在多模理解方面秀肌肉的Step-1.5V多模态大模型,以及在多模生成方面小有所成的Step-1X图像生成大模型,这次也对外发布。
Step-1.5V多模态大模型从Step-1V千亿参数多模态大模型迭代而来。
Step-1V大模型已经可以精准描述和理解图像中的文字、数据、图表等信息,并根据图像信息实现内容创作、逻辑推理、数据分析等多项任务。
而视频中的内容,它也可以轻松理解。
对比前作,Step-1.5V多模态大模型有明显跃升。
感知能力:创新的图文混排训练方法,让Step-1.5V能理解复杂图表、流程图、准确感知物理空间复杂的几何位置,还能够处理高分辨率和极限长宽比的图像。
推理能力:根据图像内容进行各类高级推理任务,如解答数学题、编写代码、创作诗歌等。
视频理解能力:它不仅能够准确识别视频中的物体、人物和环境,还能够理解视频的整体氛围和人物情绪。
另一个新发布的Step-1X图像生成大模型,有600M、2B、8B三种参数量,分别适合对于速度敏感、日常主力(平衡效果和速度)、追求更高效更极致这三种场景。
通过全链路自研的DiT模型架构,Step-1X有更好的文本prompt和生成图片的语义对齐能力,以及指令跟随能力。
还有个不得不提的点:
Step-1X针对中国元素进行了深度优化,有关中国元素、文化的内容都能轻松拿下,生成的效果也更符合国人审美。

对外亮相第一天起,阶跃星辰就摆明姿态,攀登AGI巅峰之路“万亿参数”和“多模融合”缺一不可。
这次一股脑儿推出的三款新模型,就是其在既定路线上向前探索的有力证明。
不可或缺的AI应用与生态布局
阶跃星辰不是WAIC上唯一推陈出新的大模型玩家。
在现场有一种强烈的感受,相比去年WAIC,展区的大模型厂商出现了更多创业公司的身影,尤为不同的是,无论是展商、论坛还是观众,对AI大模型应用的关注和讨论都占去不小篇幅。
类似“模应一体”“杀手级应用”“AI应用生态”这般的话题,频频被提起。
姜大昕此前有过一个生动的比喻:模型和产品的关系,就像灵魂和皮囊。
当你具体到某个应用的时候一定要通用模型跟它深度绑定,应用才能做到极致。
反过来也是一样,我不觉得一个光做应用的公司,没有一个模型跟它深度绑定的话,它能做到极致。
这就凸显出阶跃星辰在模型与产品之间的伏线千里之妙。
以自家Step系列模型为基座,阶跃星辰的产品共有两类,自有产品和合作产品。
自有产品方面,有聊天类应用跃问,定位个人效率助手,web端和App端可用;AI开放世界平台冒泡鸭,提供海量智能体,主打一个休闲娱乐。
两款toC产品,均已全面开放使用。
这里重点介绍一下跃问,它拥有联网搜索、代码分析增强(POT)等能力,能够提供信息查询、语言学习、创意写作、图文解读等服务。
和其它家聊天类应用相比,它有一个最大的优势:多模态内容理解能力。
它能够帮助用户识别真实世界的万事万物:
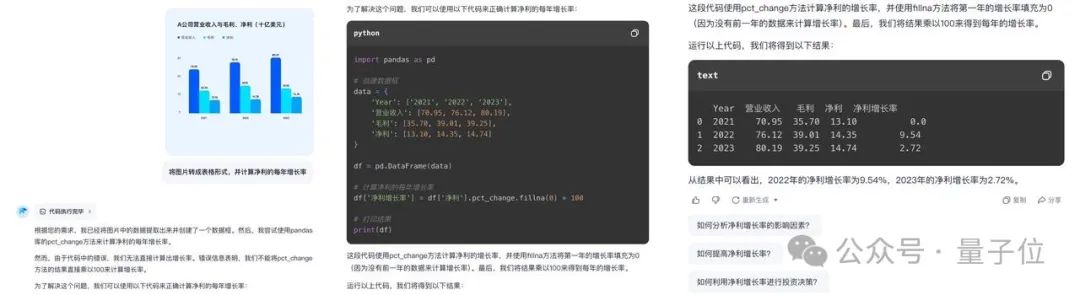
能够理解和分析复杂的金融图表:
还能理解热梗图片中的深意:

甚至能够根据欧洲杯赛程表,梳理生成“一图读懂”:

合作产品方面,最亮眼的就是此次吸粉无数的《大闹天宫》AI互动体验。

动画电影《大闹天宫》制作于1961年,是上美影的灵魂代表作,60年来,更成为几代人钟爱的回忆。

半个多世纪以来,基于这个国民IP的创新层出不穷,还能玩出什么新花样?
围绕《大闹天宫》,阶跃团队与上影集团利用AIGC和大模型技术,联合推出了AI互动体验产品,让大家能与电影情境深度融合。
玩法也很简单:
上传一张个人照片,然后开始走Step系列大模型生成的剧情。

模型算法会识别照片特征,提取后结合《大闹天宫》的画风和角色,完成风格迁徙,生成新的肖像。

剧情发展过程中,用户能选择,也能和系统对话交谈。

等等,这还没完!
根据刚才做出的选择和回答,大模型还会进一步分析用户的MBTI人格,最后得出结论:
如果你在天庭当打工人,最适合什么差事?
(没办法咯,孙悟空大闹天宫前也老老实实做了段时间弼马温)

量子位测出来,是enfp的赤脚大仙。
都说光脚的不怕穿鞋的,本大仙今天就原地罢工吧(不是)。
据说只有1%的人能测出来齐天大圣,不是我,我慕了。
没在现场但想玩一把的朋友们,可点击文末阅读原文,也欢迎大家把测出来的MBTI和神仙职位在评论区分享~

上述产品不只是阶跃星辰利用自家大模型能力对外输出的全部。
据了解,在内容、金融、网络文学、知识服务、影视等领域,阶跃星辰都和行业头部展开合作,多维探索面向C端用户的创新应用。
国产大模型创业第一梯队新格局
对于所有的大模型玩家来说,从ChatGPT诞世的那一天起,全球范围内的竞争就愈发激烈,再也没有停歇过。
尤其是WAIC现场,这样的信号传递得非常明显。
谷歌、Meta、BAT、华为、讯飞、深度求索、AI四小龙……老牌AI布局者,在AI 2.0时代的实力依然不可小觑。
背后原因是AI 2.0实质上是随着研究深入,对判别式AI与生成式AI的人为划分,而深度学习的核心三驾马车,即对算法、算力、数据的掌握和运用,依然是重中之重。

但古今中外,一个时代有一个时代的公司,每个时代都会有代表性的公司出现。
AI 2.0时代的大模型初创公司,确实已经出现了对技术和产业的发展至关重要的锐力。
WAIC展区,就有这样的玩家出现,而且经过第一阶段的竞速和洗牌,大模型创业的上半场基本已经结束。
在上半场中,能够脱颖而出的创业玩家,首先通过自研基础大模型,证明了自己的技术研发实力;其次还通过产品和应用,开启了商业模式试水,构建起了技术-产品-数据-商用的初步飞轮;最后,还获得了创投和资本市场的认证,完成了独角兽级别的巨额融资,有粮草和底气可以开启下一阶段比拼。
实际上,上半场也是创业玩家的分水岭,能够在此时此刻把公司推至独角兽级别,是角逐下半场的门票体现。
也就是说,没有门票,基本就告别下半场了,更别说AGI了。
因为随着第一阶段竞速,市场的作用开始展现,不论是技术人才、研发资源、创投资本,都在急剧收敛,形成马太效应——留在桌上的玩家会获得更多的资源挑战更大的目标,下了桌的玩家,原先有的也要被拿回。
互联网时代、移动互联网时代、AI1.0时代的轨迹,再次重复上演。
而现在,在AI2.0上半场拿到门票的创业玩家,格局初现,六小强锐不可当——
智谱华章、月之暗面、MiniMax、零一万物、百川智能、阶跃星辰……越来越多被放在一起谈论。
而阶跃星辰,是其中后发的一个,但正在展现出谋定而后动的后发优势。
而且它是为数不多,在国内同时拥有多模态大模型能力和万亿MoE大模型的玩家,这代表了面向下半场的某种潜在竞争力和加速度来源。
— 完 —
点这里
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

