
热门标签
热门文章
- 1Python中的分布式系统设计与开发_python 分布式
- 2C 和 C++ 中信号处理简单介绍
- 3Transformer 模型_transformer神经网络 序列
- 4决策树和随机森林的python实现_criterion python
- 5hugging face模型下载方法_hugging face 下载
- 6探索Python日志管理的优雅之道:Loguru库入门指南_loguru 设置级别
- 7从huggingface下载模型像本地加载但是UnicodeDecodeError_huggingface unicodedecodeerror
- 8Git安装步骤(乌龟壳和Git命令)和常用命令_git 乌龟壳
- 9还需要什么ProcessOn、PlantUML,IDEA自己就可以把项目一键生成UML类图~
- 10一文速学-XGBoost模型算法原理以及实现+Python项目实战_xgboost金融领域模型实战_xgboost回归模型
当前位置: article > 正文
【经验分享】ShardingSphere+Springboot-04:自定义分片算法(COMPLEX/STANDARD)
作者:神奇cpp | 2024-08-10 17:21:00
赞
踩
【经验分享】ShardingSphere+Springboot-04:自定义分片算法(COMPLEX/STANDARD)
3.4 CLASS_BASED 自定义类分片算法
3.4.1 复杂分片自定义算法(strategy=COMPLEX )
通过配置分片策略类型和算法类名,实现自定义扩展。 掌握自定义类算法就算法完全掌握了分片算法的精髓,可以根据业务需求灵活配置分片规则。
类型:CLASS_BASED
可配置属性:
| 属性名称 | 数据类型 | 说明 |
|---|---|---|
| strategy | String | 分片策略类型,支持 STANDARD、COMPLEX 或 HINT(不区分大小写) |
| algorithmClassName | String | 分片算法全限定名 |
官方文档给出了一个参考案例如下,没有太多的说明,这尝试用自定义分片算法重新实现[3.3.1]中的行表达式分表规则
package org.apache.shardingsphere.sharding.fixture; import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue; import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue; import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm; import java.util.Collection; public final class ClassBasedStandardShardingAlgorithmFixture implements StandardShardingAlgorithm<Integer> { @Override public String doSharding(final Collection<String> availableTargetNames, final PreciseShardingValue<Integer> shardingValue) { for (String each : availableTargetNames) { if (each.endsWith(String.valueOf(shardingValue.getValue() % 4))) { return each; } } return null; } @Override public Collection<String> doSharding(final Collection<String> availableTargetNames, final RangeShardingValue<Integer> shardingValue) { return availableTargetNames; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

实现目标:根据用户类型user_type和部门dep_id进行复杂分库分表
编写分片算法类:
-
根据分片策略类型( STANDARD、COMPLEX 或 HINT)实现对应的算法接口,这里需要用到的复杂算法的接口
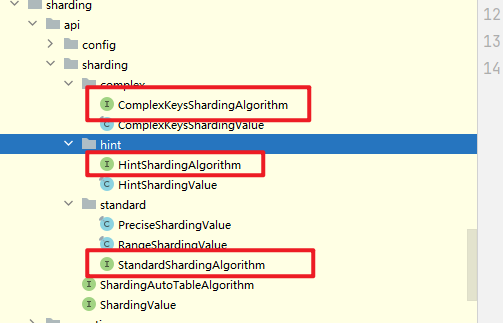
-
实现必须的方法,这里核心关注doSharding方法,编写思路记录如下
- 获取列名和分片值的映射(必备的,获取了才能根据分片键值计算数据源嘛
- (可选)获取逻辑表名、范围值映射
- 获取分片键值,并计算得到真实数据源
完整算法类:
package com.zhc.shard.algo; import lombok.extern.slf4j.Slf4j; import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingAlgorithm; import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingValue; import java.util.*; /** * @Author zhuhuacong * @Date: 2024/08/09/ 11:07 * @description */ @Slf4j public class UserTypeDepIdAlgorithm implements ComplexKeysShardingAlgorithm<String> { // 定义列名常量 private static final String col1 = "user_type"; private static final String col2 = "dep_id"; /** * 实现分片逻辑 * 当分片条件存在时,根据给定的分片键计算出特定的数据源 * 如果无法计算出合适的分片结果,则抛出异常 * * @param collection 数据源集合(这里是分表策略,所以这里是真实表集合 * @param complexKeysShardingValue 分片条件对象 * @return 分片后的数据源名称列表 * @throws RuntimeException 当无法得到合适的分片结果时 */ @Override public Collection<String> doSharding(Collection collection, ComplexKeysShardingValue complexKeysShardingValue) { // 获取逻辑表名 String logicTableName = complexKeysShardingValue.getLogicTableName(); // 获取列名和分片值的映射 Map columnNameAndShardingValuesMap = complexKeysShardingValue.getColumnNameAndShardingValuesMap(); // 获取列名和范围值的映射(未用到) Map columnNameAndRangeValuesMap = complexKeysShardingValue.getColumnNameAndRangeValuesMap(); // 获取分片键值 List c1UserType = (List) columnNameAndShardingValuesMap.get(col1); List c2DepId = (List) columnNameAndShardingValuesMap.get(col2); // 如果任一分片键存在,则进行分片计算 if (Optional.ofNullable(c1UserType).isPresent() || Optional.ofNullable(c2DepId).isPresent()) { // 【算法核心】 根据分片键值计算数据源索引 long userType = c1UserType.get(0) != null ? Long.parseLong(c1UserType.get(0).toString()) : 0; long depId = c2DepId.get(0) != null ? Long.parseLong(c2DepId.get(0).toString()) : 0; long shardingId = ((userType + depId) % 2); String tableName = logicTableName + "_" + shardingId; log.info("userType:{};shardingId:{};余数{};真是表名{}", userType, depId, shardingId , tableName); // 返回计算后的数据源名称 return Collections.singletonList(tableName); } // 如果无法得到合适的分片结果,则记录日志并抛出异常 log.info("没有得到合适的分片结果=:表名{},参数:{}", collection, columnNameAndShardingValuesMap); throw new RuntimeException("没有得到合适的分片结果"); } @Override public Properties getProps() { return null; } @Override public void init(Properties properties) { } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
进行测试:
分表策略运行正确

3.4.2 STANDARD 标准分片自定义算法
快速实现,表结构还是参考前面的打卡表。要求根据早中晚三个时段的打卡时间进行分表,分别存入
stu_clock_am、stu_clock_noon、stu_clock_eve;
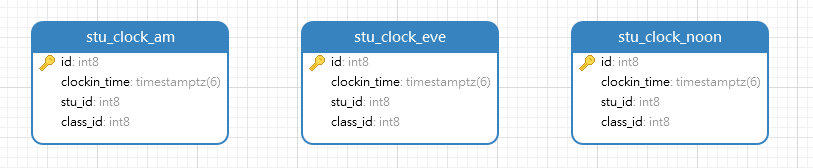
yaml配置如下
spring: shardingsphere: rules: sharding: tables: # 打卡表 stu_clock: actual-data-nodes: dsmain.stu_clock_am,dsmain.stu_clock_noon,dsmain.stu_clock_eve key-generate-strategy: column: id key-generator-name: snowflake table-strategy: standard: sharding-column: clockin_time sharding-algorithm-name: stu_clock_class_algo # 配置分片算法 sharding-algorithms: stu_clock_class_algo: type: CLASS_BASED props: #分片策略类型,支持 STANDARD、COMPLEX 或 HINT(不区分大小写) strategy: STANDARD # 分片算法全限定名 algorithmClassName: com.zhc.shard.algo.StuClockClassAlgorithm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
算法代码:
package com.zhc.shard.algo; import cn.hutool.core.date.DateUtil; import com.google.common.collect.Range; import lombok.extern.slf4j.Slf4j; import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue; import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue; import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm; import java.time.LocalDateTime; import java.util.Collection; import java.util.Collections; import java.util.Date; import java.util.Properties; /** * @Author zhuhuacong * @Date: 2024/08/09/ 14:56 * @description StuClockClassAlgorithm */ @Slf4j public class StuClockClassAlgorithm implements StandardShardingAlgorithm<Date> { @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Date> shardingValue) { String logicTableName = shardingValue.getLogicTableName(); Date date = shardingValue.getValue(); LocalDateTime localDateTime = DateUtil.toLocalDateTime(date); int hour = localDateTime.getHour(); log.info("logicTableName: {} value: {} hour {}", logicTableName, date, hour); String actualTableName =null; if (hour > 15){ actualTableName = logicTableName + "_eve"; } else if (hour > 10 ){ actualTableName = logicTableName + "_noon"; } else { actualTableName = logicTableName + "_am"; } if (availableTargetNames.contains(actualTableName)){ return actualTableName; } // 如果无法得到合适的分片结果,则记录日志并抛出异常 log.info("没有得到合适的分片结果:表名{},参数:{}", shardingValue, shardingValue); throw new RuntimeException("没有得到合适的分片结果"); } @Override public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Date> shardingValue) { return availableTargetNames; } @Override public Properties getProps() { return null; } @Override public void init(Properties properties) { } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
结果测试,
生成随机打卡时间,观察是否正确入库
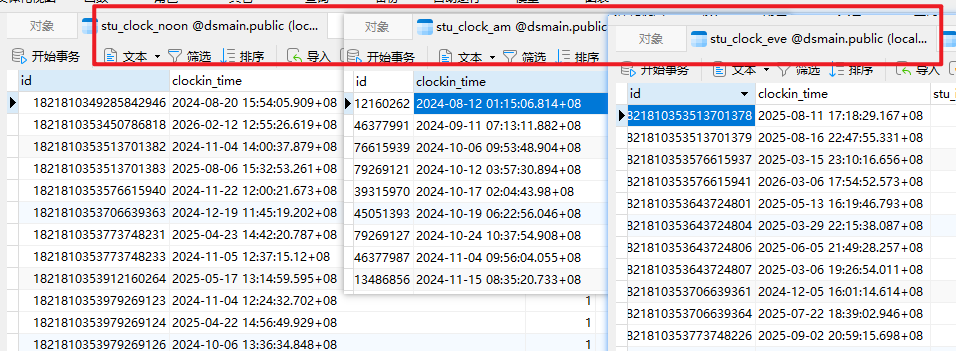
结果符合预期
## 进阶⭐️ 自定义算法+范围查询优化
可以发现,StandardShardingAlgorithm接口还有一个同样叫doSharding的接口,
/**
* Sharding.
*
* @param availableTargetNames available data sources or table names
* @param shardingValue sharding value
* @return sharding results for data sources or table names
*/
Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<T> shardingValue);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
传入的参数是一个带有范围(上下界限)shardingValue,一个是可用的真实表集合availableTargetNames,返回参数就是需要查询的目标表列表。
只要根据实际业务逻辑实现方法体内容即可。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/神奇cpp/article/detail/959570
推荐阅读
相关标签

