
- 1TCP请求如何获取客户端真实源IP地址_tcp连接怎么获取对方ip
- 2(一)HDFS总体架构_hdfs的总体架构,并对每部分进行认知描述
- 3springsecurity+oauth2.0 分布式认证授权-order资源服务器的配置4_enableresourceserver
- 4Java程序员必备的50道Kafka面试题及解析,面试再也不怕问Kafka了_java kafka高级面试题
- 5图解 MySQL 索引:B-树、B+树_mysql b+树
- 6java豆瓣查书api_如何通过豆瓣API获取图书和电影列表
- 7哈希(Hash)与加密(Encrypt)的基本原理、区别及工程应用_encrypt和hex
- 8XSS 攻击_xss攻击代码
- 9数据结构:队列的详解_数据结构队列详细讲解
- 10把docker从c盘安装到d盘_docker安装到d盘
【AI基础】大模型部署工具之ollama的安装部署以及api调用
赞
踩
ollama是大模型部署方案,对应docker,本质也是基于docker的容器化技术。
从前面的文章可以看到,部署大模型做的准备工作是比较繁琐的,包括各个环节的版本对应。ollama提供了一个很好的解决方案。
ollama主要针对主流的LLaMA架构的开源大模型设计,并且已被LangChain、Taskweaver等在内的多个热门项目高度集成。同时ollama提供了openAI兼容的api,可以最大限度的减少理解和开发成本。
一、下载安装ollama
1.1 安装
官方地址:https://ollama.com/
开源地址:https://github.com/ollama/ollama
下载后双击安装:

一路下一步即可。
1.2 检验
ollama安装后默认已经启动,我们可以通过访问其提供的api服务来进行检验。
参考官方文档:ollama的api · ollama/ollama · GitHub
这里运行ollama的机器为windows系统, ip为192.168.3.154。
1.2.1 通过localhost检验
运行命令:
> curl http://localhost:11434/api/generate -d "{\"model\": \"qwen2\",\"prompt\": \"who are you?\",\"stream\":false}"查看结果:
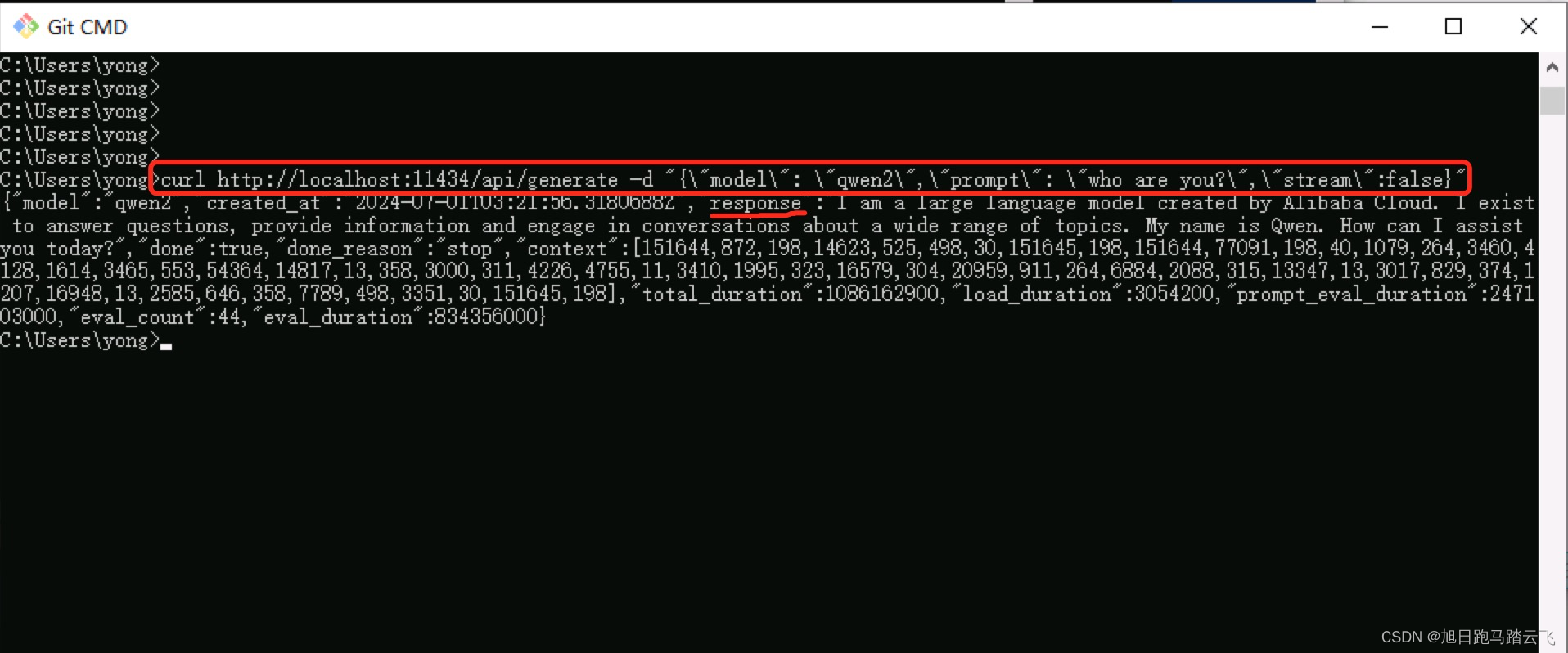
这里注意两点:
1、不要使用PowerShell(里面的curl参数不一样),使用 cmd 或者 git Cmd 。
2、注意参数的引号,通过斜杠 \ 来转义。
1.2.2 通过IP地址检验
运行命令:
> curl http://192.168.3.154:11434/api/generate -d "{\"model\": \"qwen2\",\"prompt\": \"who are you?\",\"stream\":false}"查看结果:

提示连接不上:"curl: (7) Failed to connect to 192.168.3.154 port 11434 after 2021 ms: Couldn't connect to server"。
这是因为ollama安装后默认只能本地访问,接下来配置远程访问api。
1.3 配置
这里配置主要是因为两个需求:远程可以访问ollama的api接口服务以及自定义大模型存放路径。
ollama默认把大模型保存在路径 用户目录/.ollama/models 下:

基于各种原因,我们可能不希望使用这个默认路径,可以通过环境变量的配置来更改大模型保存的目录。
添加环境变量 OLLAMA_HOST 以及 OLLAMA_MODELS:
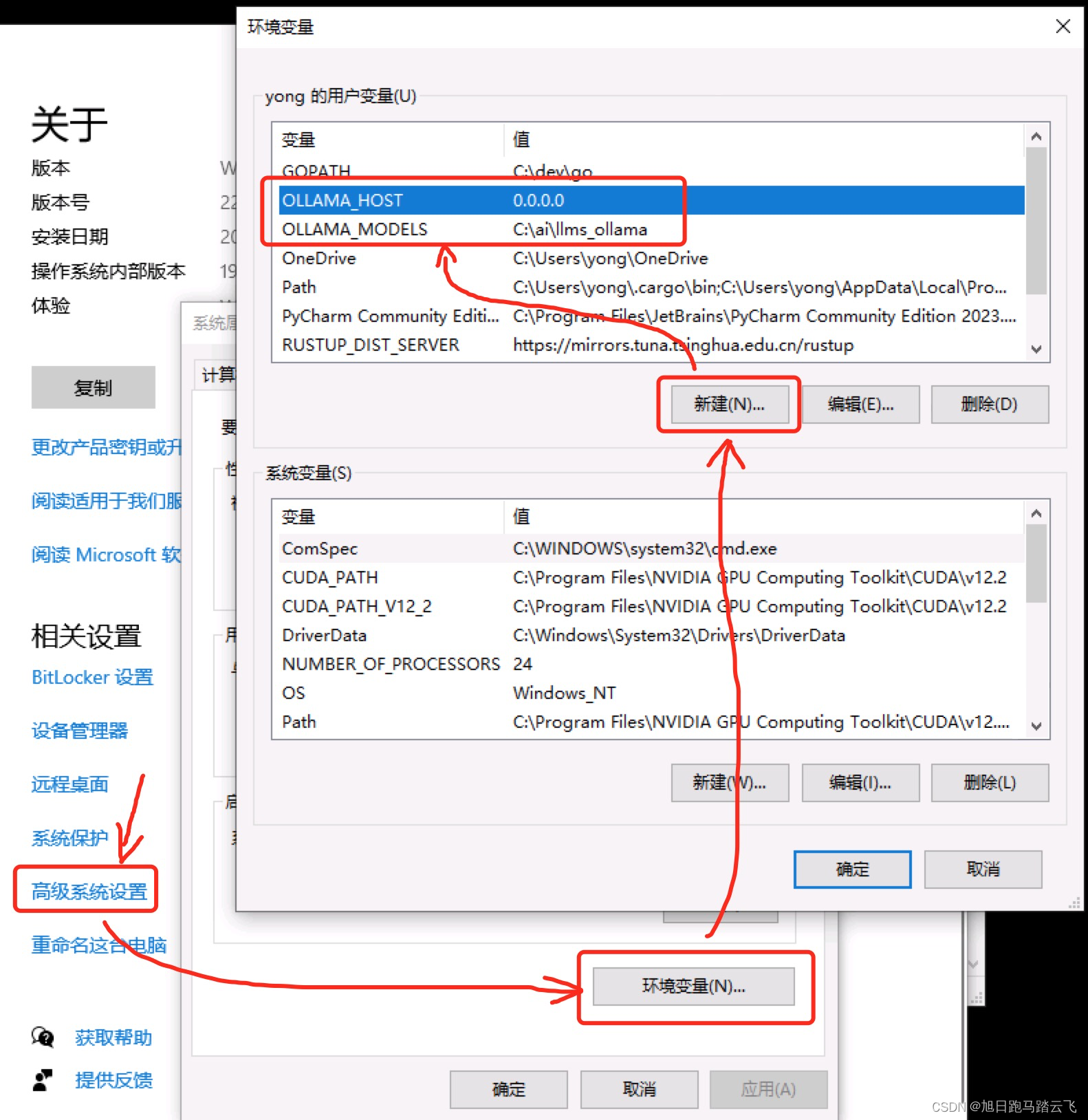
- - OLLAMA_HOST,0.0.0.0, 配置后可以远程访问;
- - OLLAMA_MODELS, c:\ai\llms_ollama,配置后ollama拉取的大模型会存放在此路径;
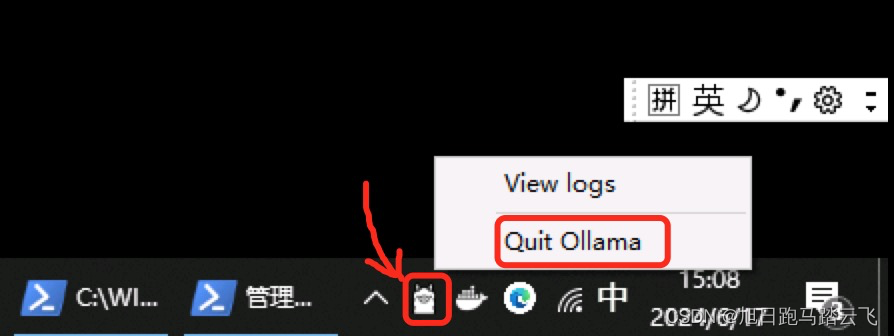
这里有重要的一步,需要重启ollama,使配置生效。
在任务栏的ollama图标上点击右键,选择“Quit Ollama”退出ollama:
然后重新打开ollama:

1.4 重新检验
这里通过IP地址重新进行检验。
1.4.1 windows系统
运行命令:
> curl http://192.168.3.154:11434/api/generate -d "{\"model\": \"qwen2\",\"prompt\": \"who are you?\",\"stream\":false}"返回结果:
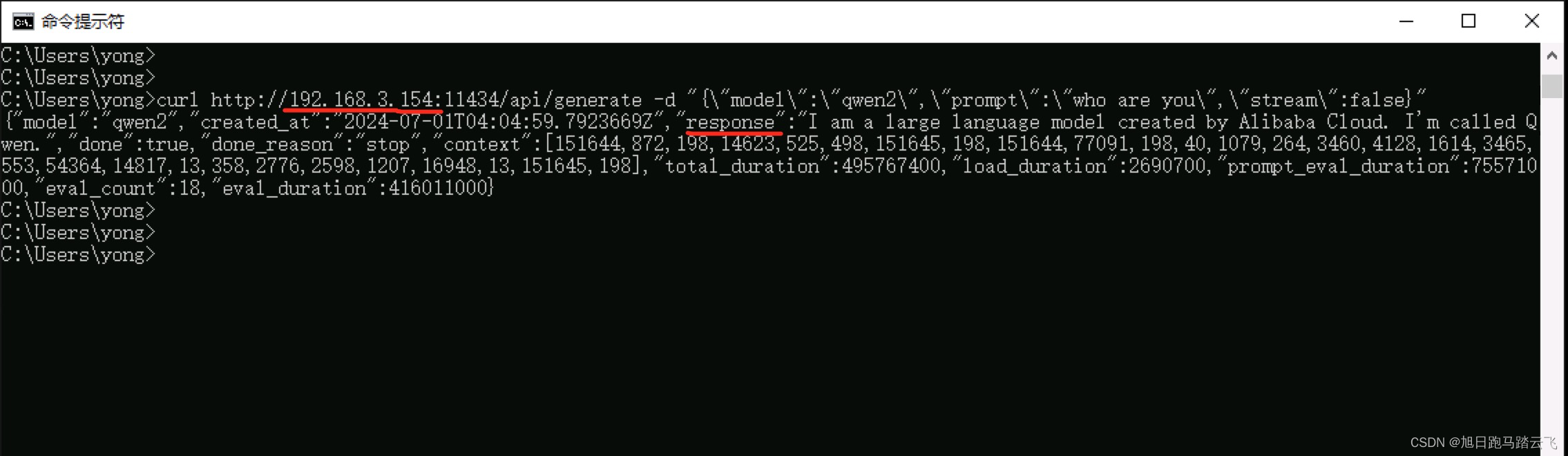
1.4.2 linux系统和mac系统
生成Completion:
> curl http://192.168.3.154:11434/api/generate -d '{"model": "qwen2","prompt": "who are you?","stream":false}'返回结果:

这里注意参数的格式,和windows系统不一样,引号在这里直接使用不需要转义。
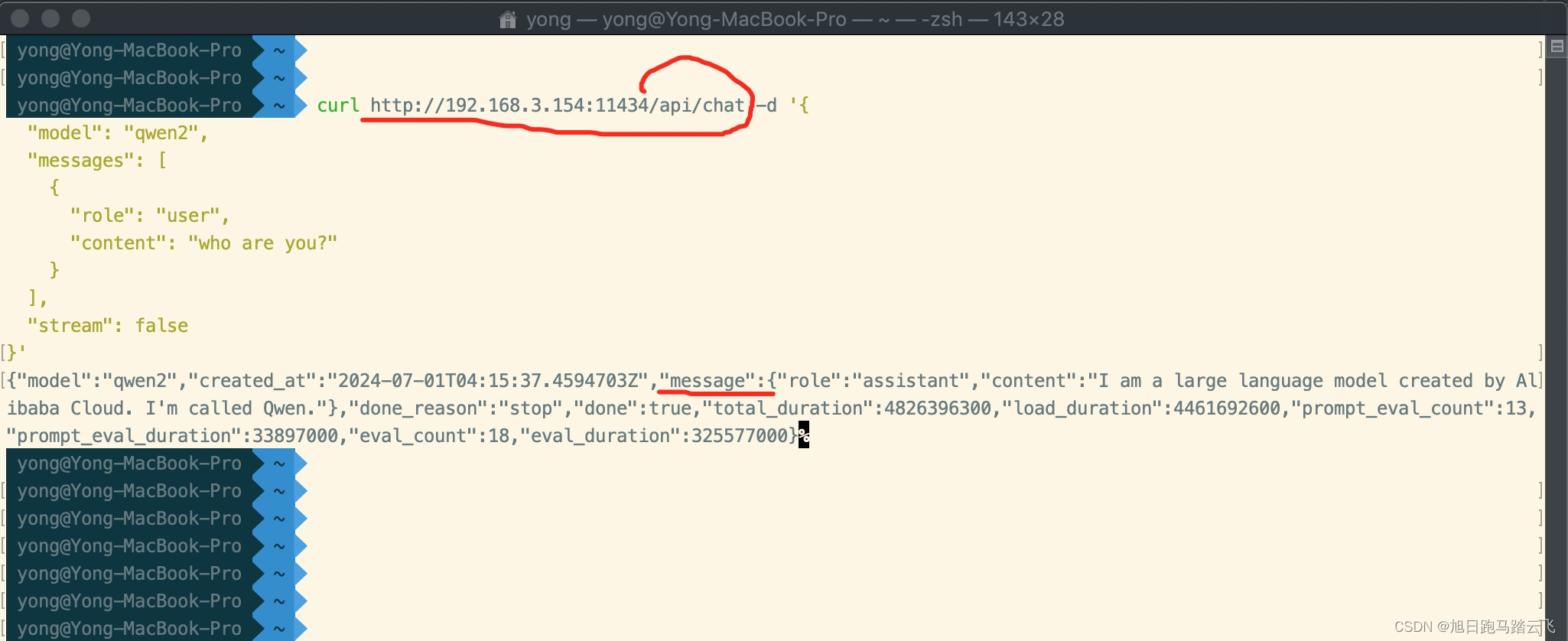
生成Chat Completion:
- > curl http://192.168.3.154:11434/api/chat -d '{
- "model": "qwen2",
- "messages": [
- {
- "role": "user",
- "content": "who are you?"
- }
- ],
- "stream": false
- }'
返回结果:
二、部署运行大模型
接下来就是实际来部署一个大模型,这里以llama3为例。
2.1 获取大模型部署命令
在ollama官网搜索llama3大模型:https://ollama.com/library

选择第一个llama3进入大模型详情页:
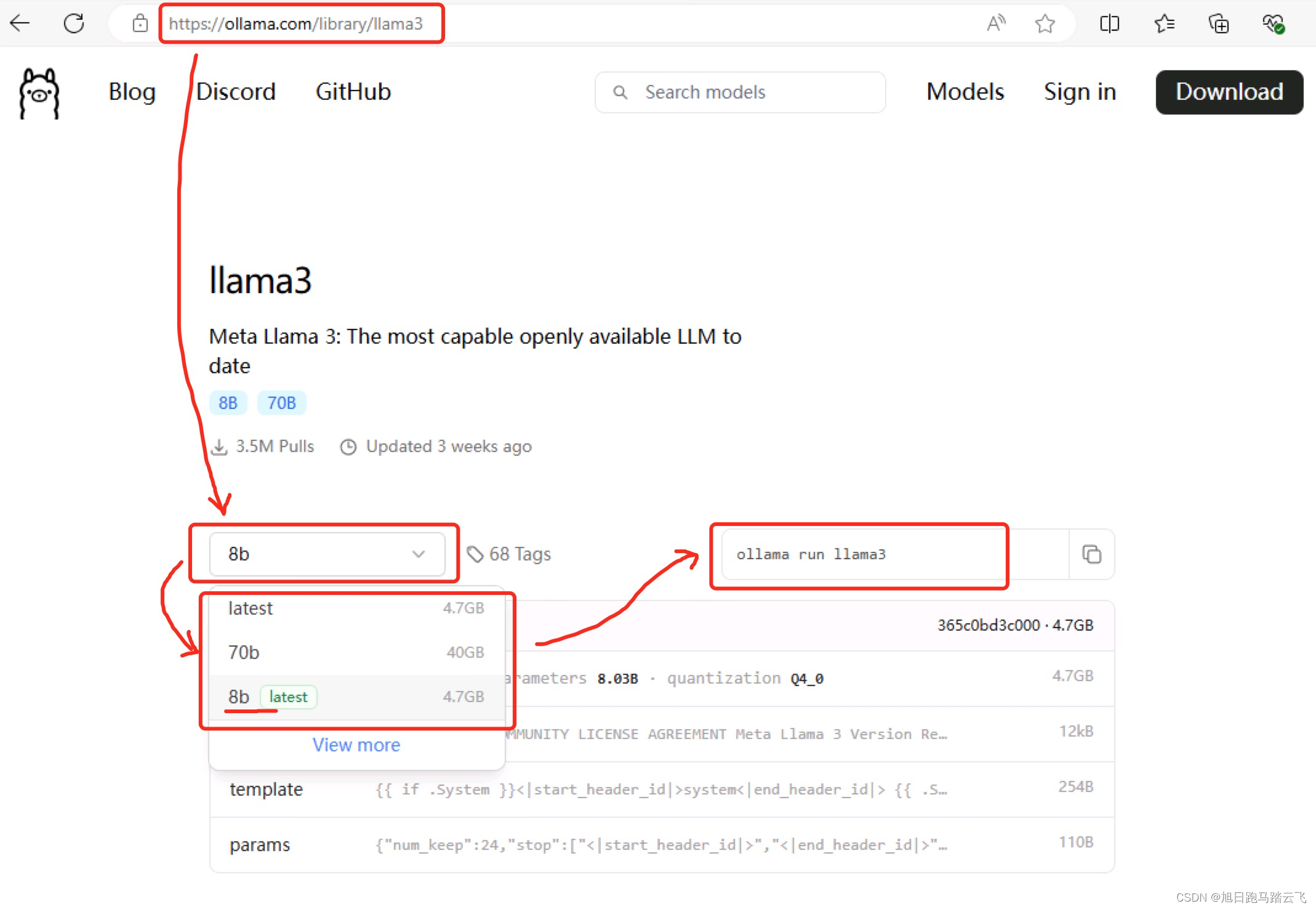
在上图可以看到默认有三个标签可以选择:最新版、8B和70B,这里我们选择 8B的,所以我们需要运行 ollama run llama3。如果我们需要部署70B的,则需要运行 ollama run llama3:70b。
2.2 部署大模型
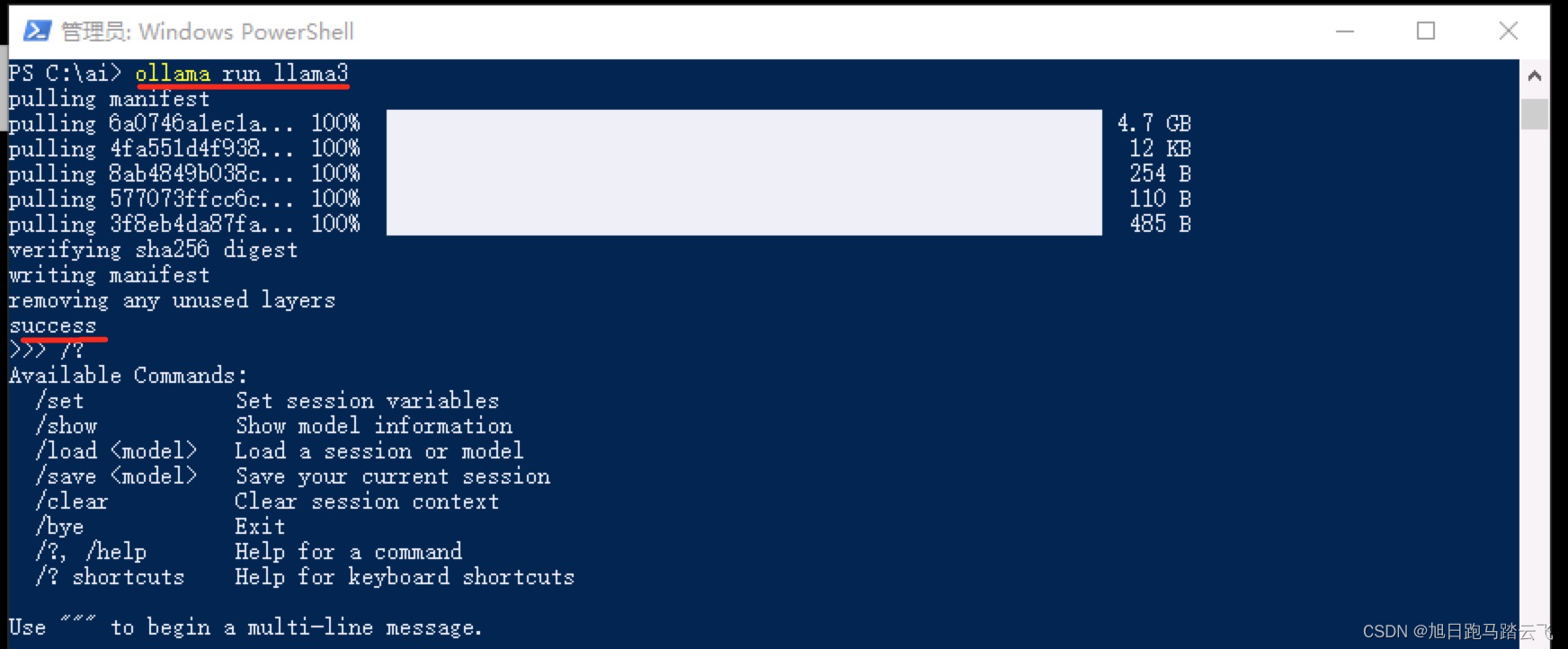
我们可以直接运行 ollama run llama3,如果llama3没有下载过则会下载,否则直接运行。也可以先下载然后运行:
- > ollama pull llama3
- > ollama run llama3
可以看到,使用方式跟docker是一样的,大模型对应了docker中的镜像。
下载完后会提示成功:
2.3 和大模型交互
接下来可以直接跟llama3对话,在三个箭头➡️后输入问题,llama3会给出回应:

可以看到ollama成功部署了大模型,并成功运行。
三、在LangChain中使用Ollama
3.1 通过jupyter来运行
3.1.1 安装jupyter
参考 【AI工具】jupyter notebook和jupyterlab对比和安装-CSDN博客 安装jupyterlab。
3.1.2 新建一个notebook

在新的文件中输入如下代码:
- # 引入ollama
- from langchain_community.chat_models import ChatOllama
-
- # 加载llama3模型
- ollama_llm = ChatOllama(model="llama3")
-
- # 构造Message
- from langchain_core.messages import HumanMessage
-
- messages = [
- HumanMessage(
- content="你好,请你介绍一下你自己",
- )
- ]
-
- # 发送Message
- chat_model_response = ollama_llm.invoke(messages)
-
- # 输入Message
- chat_model_response

 这里有个细节,代码一共是五个输入块,这是为了在出错时,可以快速定位是哪一块出了问题。
这里有个细节,代码一共是五个输入块,这是为了在出错时,可以快速定位是哪一块出了问题。
3.1.3 运行
现在把鼠标定位在第一行,点击工具栏的运行按钮,一步一步的运行,运行5步后,输出了AI的自我介绍:

这样在LangChain中通过ollama,直接调用了大模型。
可以再问一次二的问题:

3.2 直接通过python运行
3.2.1 安装LangChain环境
参考 :【AI基础】第四步:保姆喂饭级-langchain+chatglm2-6b+m3e-base_m3e-base
3.2.2 新建python文件
输入代码:
- # 引入ollama
- from langchain_community.chat_models import ChatOllama
- # 加载llama3模型
- ollama_llm = ChatOllama(model="llama3")
- # 构造Message
- from langchain_core.messages import HumanMessage
- messages = [
- HumanMessage(
- content="你好,请你介绍一下你自己",
- )
- ]
- # 发送Message
- chat_model_response = ollama_llm.invoke(messages)
- # 输入Message
- chat_model_response
3.2.3 运行
执行命令运行:
> python dev_ollama.py
运行成功。

