
- 1Failed to obtain JDBC Connection; nested exception is com.mysql.cj.jdbc.exceptions._failed to obtain jdbc connection; nested exception
- 2mysql三种安装方式 你知道了哪种_processing dependency: mysql-community-libs(x86-64
- 3Android音量设置流程(android8.0)_android setstreamvolume
- 4收藏必备!ChatGPT助你快速阅读AI论文的全流程解析_gpt如何进行论文阅读
- 5Hdfs存储负载均衡_datanode卷选择策略平衡阀值
- 6阿里Lazada25届实习生春25届实习生春招来啦!!!_lazada春招
- 7C语言典型例题31
- 8hbase可视化:hbaseGUI的安装与使用_hbase gui,2024年最新你连原理都还没弄明白
- 9ubuntu24.04安装破解navicat,并使用navicat连接本地mysql服务_ubuntu navicat
- 10银河麒麟V10(内核Linux)设置有线连接IP地址以及查看_麒麟系统查看本机ip命令
怎样做情感分析_课程情感算法分析怎么写
赞
踩
本文结构:
- 什么是情感分析?
- 怎么分析,技术上如何实现?
cs224d Day 4: 项目1-情感分析
今天的内容是课程的第一个项目,和其他的公开课相比,这个课程的项目非常合我心意,因为项目非常实用,情感分析也是现在工业的主流方向之一,迫不及待想要赶紧开始做项目了。
什么是情感分析?
就是要识别出用户对一件事一个物或一个人的看法、态度,比如一个电影的评论,一个商品的评价,一次体验的感想等等。根据对带有情感色彩的主观性文本进行分析,识别出用户的态度,是喜欢,讨厌,还是中立。在实际生活中有很多应用,例如通过对 Twitter 用户的情感分析,来预测股票走势、预测电影票房、选举结果等,还可以用来了解用户对公司、产品的喜好,分析结果可以被用来改善产品和服务,还可以发现竞争对手的优劣势等等。
怎么分析,技术上如何实现?
首先这是个分类问题。
最开始的方案是在文中找到具有各种感情色彩属性的词,统计每个属性的词的个数,哪个类多,这段话就属于哪个属性。但是这存在一个问题,例如 don’t like ,一个属于否定,一个属于肯定,统计之后变成 0 了,而实际上应该是否定的态度。再有一种情况是,前面几句是否定,后面又是肯定,那整段到底是中立还是肯定呢,为了解决这样的问题,就需要考虑上下文的环境。
2013年谷歌发了两篇论文,介绍了 Continuous Bag of Words (CBOW) 和 Skip-gram 这两个模型,也就是 Word2Vec 方法,这两种模型都是先将每个单词转化成一个随机的 N 维向量,训练之后得到每个单词的最优表示向量,区别是,CBOW 是根据上下文来预测当前词语,Skip-gram 刚好相反,是根据当前词语来预测上下文。
Word2Vec 方法不仅可以捕捉上下文语境,同时还压缩了数据规模,让训练更快更高效。通过这个模型得到的词向量已经可以捕捉到上下文的信息。比如,可以利用基本代数公式来发现单词之间的关系(比如,“国王”-“男人”+“女人”=“王后”)。用这些自带上下文信息的词向量来预测未知数据的情感状况的话,就可以更准确。
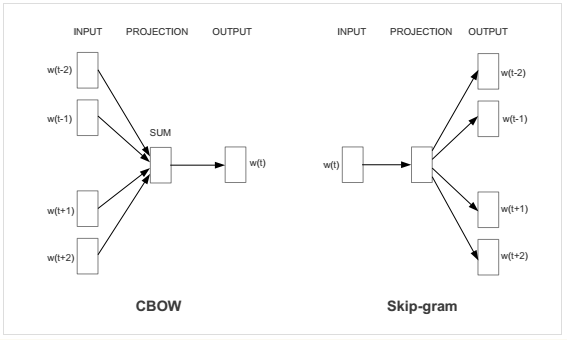
今天的小项目,就是用 word2vec 去解决情感分析问题的。先来简单介绍一下大体思路,然后进入代码版块。
思路分为两部分,第一步,就是先用 word2vec 和 SGD 训练出每个单词的最优表示向量。第二步,用 Softmax Regression 对训练数据集的每个句子进行训练,得到分类器的参数,用这个参数就可以预测新的数据集的情感分类。其中训练数据集的每个句子,都对应一个0-1之间的浮点得分,将这个得分化为 0-4 整数型 5 个级别,分别属于 5 种感情类别,讨厌,有点讨厌,中立,有点喜欢,喜欢。然后将每个句子的词转化成之前训练过的词向


