
- 1Spring Boot整合RabbitMQ详细教程_springboot整合rabbitmq
- 2未来已来!体验AI数字人客服系统带来的便利与智慧
- 3【python】tkinter+pyserial实现串口调试助手_串口调试工具 python
- 4数据库MongoDB启动方式(3种) - 方法总结篇_如何启动mongodb
- 5通过虚拟机安装Ubuntu系统到移动硬盘_vmware虚拟机移动到移动硬盘
- 6基于MATLAB的ZF、MMSE、THP线性预编码误码率仿真_zf预编码matlab代码
- 7自然语言处理(NLP)—— 置信度(Confidence)_感知层的置信度
- 8自然语言处理的实体识别:命名实体识别与关系抽取_使用自然语言处理进行人物关系抽取
- 9Python Tkinter教程之Event篇(1)_python tk event
- 10代码随想录day1 Java版
[转]出租车轨迹处理(二):时空分析_怎么根据出租车轨迹数据获取出租车的停驻点呢
赞
踩
接下来就要进行一些简单的分析了。
今天的目标是如何对某一感兴趣区域进行出租车数据的时空分析。
一、轨迹数据预处理
这一步在上一篇文章中已经有了介绍。
步骤无非就是:
1)使用pandas读取数据
- import pandas as pd
- import numpy as np
-
- f=open('D:\动态人口分布实验\交通赛数据_上\\20140803_train.txt')
- data=pd.read_csv(f,names=['ID','lat','lon','passager','time'])
-
2)根据轨迹数据的flag列(代表是否为空车),得到flag列变化的行,视为上、下客的位置。然后丢弃无用的列。
- data['passager_1']=data['passager'].shift(1)
- data['change']=data['passager']-data['passager_1']
- data=data.drop(['passager_1'],axis=1)
- #索引得到change列为1或-1的列
- data=data.loc[(data['change']==1) |(data['change']==-1)]
-
3)将time一列从字符串转为datatime类型,并将该列设为索引。
- import datetime
- data['time']=pd.to_datetime(data['time'])
- data=data.set_index('time')
- #按照索引(时间)排序
- data=data.sort_index()
4) 分别保存上、下车的位置数据(根据flag=1/-1)
- PUP=data.loc[data['change']==1]
- PUP.to_csv('D:\深度学习估算人口\\0816PUP.csv')
- DOP=data.loc[data['change']==-1]
- DOP.to_csv('D:\深度学习估算人口\\0816DOP.csv')
二、得到特定区域出租车数据
结合shp数据处理数据,对大牛来说,最好的方法首先从arcgis中生成感兴趣区域的shp文件,然后从python中使用gdal等库来处理。不然就是用arcgis中的arcpy。
但可惜我不是大牛,我只好采用笨办法曲线救国。
1)arcgis中导入出租车上、下客的csv文件=
按照x、y坐标显示。相当于把点转为了shp格式。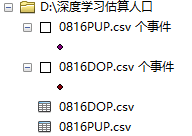
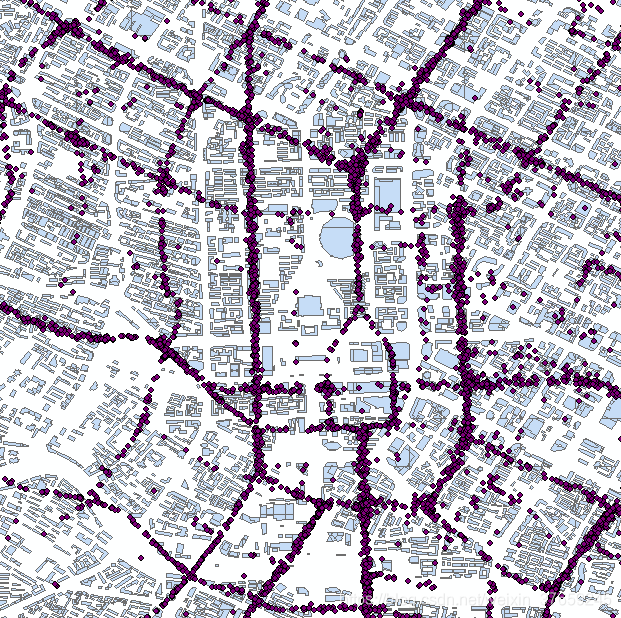
2)新建shpfile,选取感兴趣区
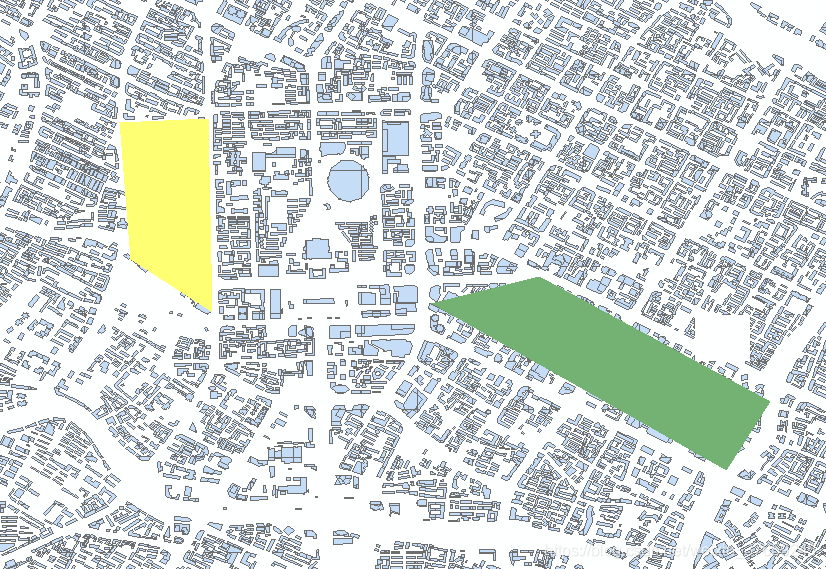
3)使用感兴趣区的shp裁剪上、下客point
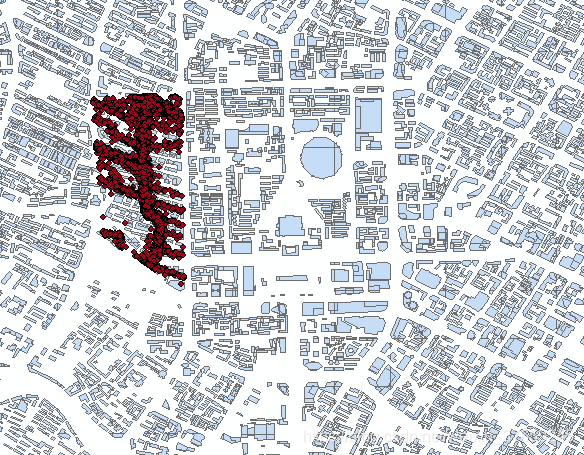
4)对裁剪后的point导出csv格式属性表
5) python中导入csv,继续进行处理
三、时空数据挖掘
1) 预处理
- ## 下车文件读取
- fff=open('D:\深度学习估算人口\\成都体育中心0816DOP.txt')
- gym_DOP=pd.read_csv(fff)
- gym_DOP=gym_DOP.drop(["OBJECTID","ID","lat","lon","passager"],axis=1)
- gym_DOP['time']=pd.to_datetime(gym_DOP['time'])
- gym_DOP=gym_DOP.set_index('time')
-
- ## 上车文件读取
- ffff=open('D:\深度学习估算人口\\成都体育中心0816PUP.txt')
- gym_PUP=pd.read_csv(ffff)
- gym_PUP=gym_PUP.drop(["OBJECTID","ID","lat","lon","passager"],axis=1)
- gym_PUP['time']=pd.to_datetime(gym_PUP['time'])
- gym_PUP=gym_PUP.set_index('time')
-
2)按小时统计
人数可直接通过上、下车的标注列【change】来计算。
但由于下车人数的标注【change】为-1,故要新建一列,设为abs(change),然后再统计人数。上车人数的【change】是1,可以直接按照change列统计,但是为了统一起见(强迫症起见),还是同样新建num列处理了一下。
这里不得不感叹pandas对时间序列处理的强大之处。一个简单的resample('H) 函数就可以直接按照Hour统计。这方面的一些具体参数可以参考《使用python进行数据分析》一书。
- # 下车人数按小时统计
- gym_DOP['num']=abs(gym_DOP['change'])
- gym_DOP=gym_DOP.resample('H').sum()
- #上车人数按小时统计
- gym_PUP['num']=abs(gym_PUP['change'])
- gym_PUP=gym_PUP.resample('H').sum()
3)作图显示上、下车趋势
直接使用pandas自带的作图函数plot()。
发现这个函数不是太方便设置标注,如下:
- ##上车人数
-
- N=gym_PUP['num'].plot(title='passagers')
- fig=N.get_figure()
- fig.set_size_inches(20,9)
- # 下车人数
- N=gym_DOP['num'].plot(title='passagers')
- fig=N.get_figure()
- fig.set_size_inches(20,9)
-
-
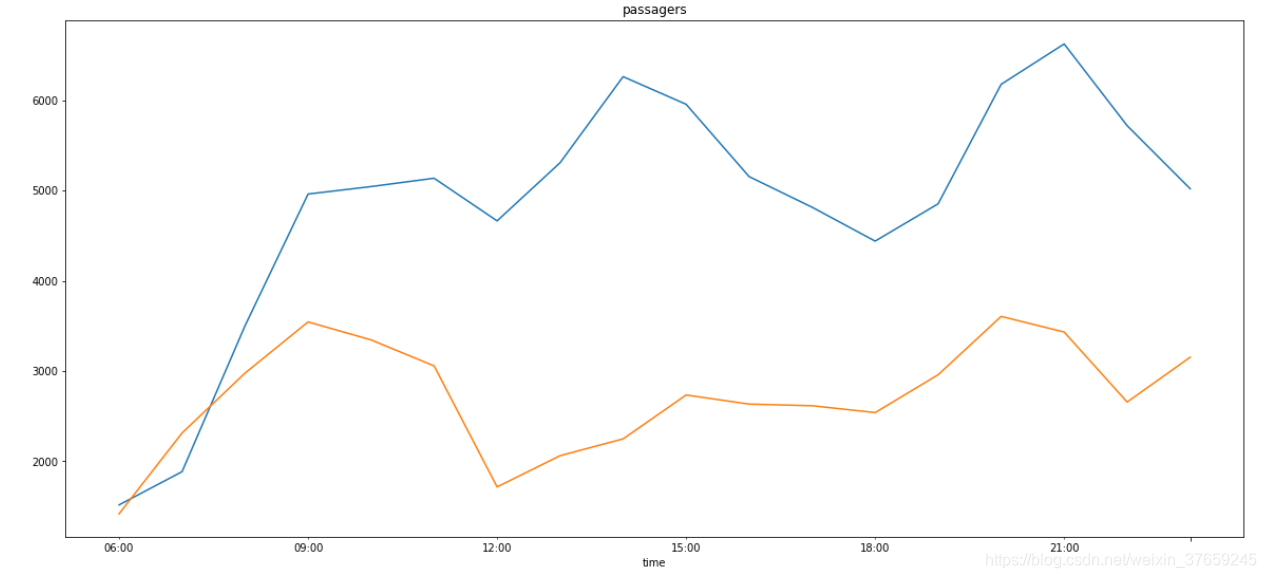
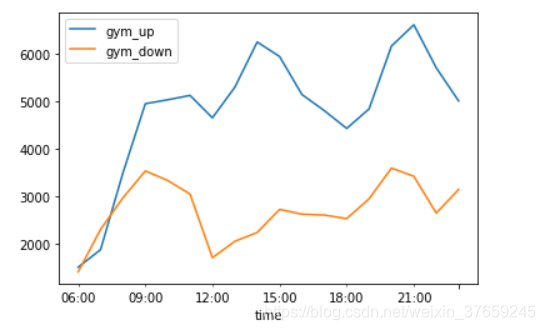
所以使用pandas的concat函数整合两个文件中的上、下车人数,然后一起作图显示。
- all_data_col = pd.concat((gym_PUP['num'],gym_DOP['num']),axis = 1)
- all_data_col.columns=['gym_up','gym_down']
- all_data_col.plot()
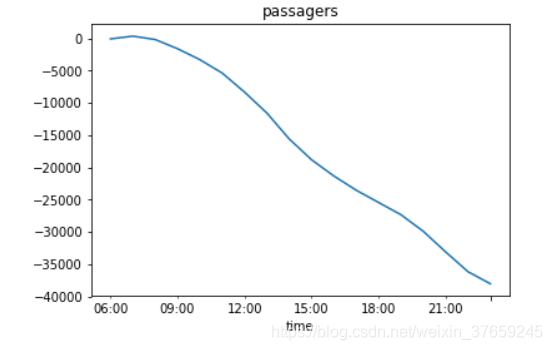
4)统计累计净流量
在一天24小时内,从早到晚的“净流量”(即截止第t小时,流入的总数减去流出的总数)是很有意义的一个特征。
这时候就需要借助强大的pandas.num.cumsum()函数了。新建一列代表【净流量】,然后作图表示。
- gym_PUP['flow']=gym_DOP.num.cumsum()-gym_PUP.num.cumsum()
- FF=gym_PUP['flow'].plot(title='passagers')
- fig=N.get_figure()
- fig.set_size_inches(20,9)
-
---------------------
作者:菜鸡的自我拯救
来源:CSDN
原文:https://blog.csdn.net/weixin_37659245/article/details/89486425

