
- 1鸿蒙 ark ui 网络请求 我不允许你不会_arkui 网络调试
- 2网关服务限流熔断降级【Gateway+Sentinel】_若依项目基于gatewaysentinel实现网关的熔断降级
- 32022消费人群_市场研报:Z世代/95后/新青年/单身(共108份)_饿了么&阿里研究院:2022年轻人过年新趋势洞察下载
- 4总结Linux 下Redis 操作常用命令(转)
- 5【Python | 辅助软件】py7zr 库解压 7z 文件避坑_py7zr.exceptions.bad7zfile: not a 7z file
- 6RabbitMQ五种模式及使用场景_rabbitmq五种消息模型及应用场景
- 7windows下qt creator 配置编译环境gcc,g++,gdb,cmake_qtcreator配置编译器
- 8sublimeText2 安装 pretty json_只装pertty json 不装package control 可以吗
- 9Windows 搭建自己的大模型-通义千问_windows 部署通义千问
- 10Oracle ORA-28547:connection to server failed,probable Oracle Net admin error_ora-28547: connection to server failed, probable o
最新 | Ask Me Anything 一种提示(Prompt)语言模型的简单策略(斯坦福大学 & 含源码)_llm prompt
赞
踩
来源: AINLPer微信公众号(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2022-09-30
引言
提示(Prompt)的微小变化就会引起大型语言模型(LLM)较大的性能变化,这将会有大量时间花费在提示(prompt)设计上。为此本文提出了ASK ME ANYTHING(AMA)方法,该方法首先产生多个有效且不完美的prompt,然后将它们进行聚合,最后产生高质量的提示(prompt)。

关注 AINLPer公众号,最新干货第一时间送达
背景介绍
大型语言模型(LLM)让我们更接近任务无关机器学习的目标。LLM 不是为新任务训练模型,而是开箱即用地应用于新任务。在上下文学习的范式中,通过自然语言任务规范或提示(prompt)来控制LLM。其中提示(prompt)由模板定义,该模板包含用于描述和表示任务输入和输出的占位符。
最近的工作评估了LLM在一系列任务中的提示(prompt)性能,实验发现,提示(prompt)的微小变化会导致较大的性能变化。并且提示(prompt)性能还取决于所选LLM系列和模型大小。为了提高可靠性,大量的工作致力于精心设计一个完美的提示(prompt)。例如,就有专家建议用户手动探索大型搜索空间的策略,以便在逐个任务的基础上优化提示(prompt)。
相反,本文考虑聚合多个有效但不完美的提示(prompt)的预测,以提高在各种的模型和任务上的提示(prompt)性能。 给定一个任务输入,每个提示(prompt)都会对输入的真实标签进行投票,这些投票被聚合以产生最终预测。
遇到的问题
在追求聚合的高质量提示(prompt)过程中,我们面临以下挑战:
高质量的提示(Effective prompts):高质量的提示是聚合效果提升的首要条件。在两个SuperGLUE任务(CB, RTE)中,我们采用了原始提示,这些提示产生了近乎随机的性能。以相同的格式生成多个提示并在提示之间进行多数投票预测的影响较小(CB为+4%),甚至可能损害平均提示性能(RTE为-2%)。许多改进提示(prompt)的建议关注单一任务类型,并基于单一模型系列和/或大小进行评估。为此,我们需要一个跨任务和模型工作的提示结构。
可扩展的集合(Scalable collection) :在确定有效的提示格式之后,我们需要获得这些格式的多个提示----这些提示主要是为输入的真实标签收集投票。任务的原始格式变化很大,之前的工作以特定于任务的方式手动将输入示例重写为新格式,这是具有挑战性的扩展。我们需要一种可伸缩的策略来重新格式化任务输入。
提示聚合(Prompt aggregation) :使用上面的提示(对于CB和RTE),我们看到准确性的平均变化为9.5%,并且错误的Jaccard指数比识别提示错误高出69%。之前提示工作中,多数投票(MV)是主要无监督聚合策略,但它没有考虑这两种特性,因此不可靠。我们需要一种策略来解释不同的准确性和依赖性。
AMA模型方法介绍
问题解决
1、识别提示的属性,这些属性可以提升跨任务、模型类型和模型大小的效率。我们研究了先前工作分类的标准提示格式,发现支持开放式回答(“约翰去哪儿了?”)的提示比将模型输出限制为特定tokens 的提示更有效。例如,将[Brown等人,2020]中最初的限制性格式中的三个SuperGLUE任务(CB、RTE、WSC)转换为开放式格式可以提高72%的性能。给定一个任务输入,我们发现根据输入形成问题、提示LLM回答问题的简单结构,可以适用于相当普遍的情况并在不同的基准测试任务中提升性能。
2、提出了一种可伸缩地将任务输入重新格式化为(1)中发现的有效格式的策略。通过在固定的两步管道中递归地使用LLM本身,将任务输入转换为有效的开放式问答格式。我们首先使用question()提示符,它包含如何将语句转换为各种(例如,yes-no,完形填空)问题的任务无关示例,然后使用answer()提示符演示回答问题的方法(例如,简明或冗长的回答)。应用提示链-答案(问题(x)) ----给出输入 x 2 x^2 x2的最终预测。该链可以在输入之间重复使用,并组合不同的功能提示对来产生多样性。我们将不同的功能提示链应用于输入,为输入的真实标签收集多次投票。
3、使用弱监督(WS)来可靠地聚合预测。实验发现,由不同链的预测所产生的误差可以是高度变化和相关的。虽然多数投票(MV)可能在某些提示集上表现良好,但在上述情况下表现不佳。AMA通过识别提示之间的依赖关系并使用WS来解释这些情况,WS是在没有任何标记数据的情况下建模和组合噪声预测的过程。这里,本文首次将WS广泛应用于提示,表明它提高了使用现成的LLM并且无需进一步训练。
AMA模型方法
总结以上问题解决方法,本文提出了 ASK ME ANYTHING PROMPTING (AMA),这是一种简单的方法,它不仅使开源 LLM 的参数减少30倍,而且超过了 GPT3-175B 的Few-Shot性能。
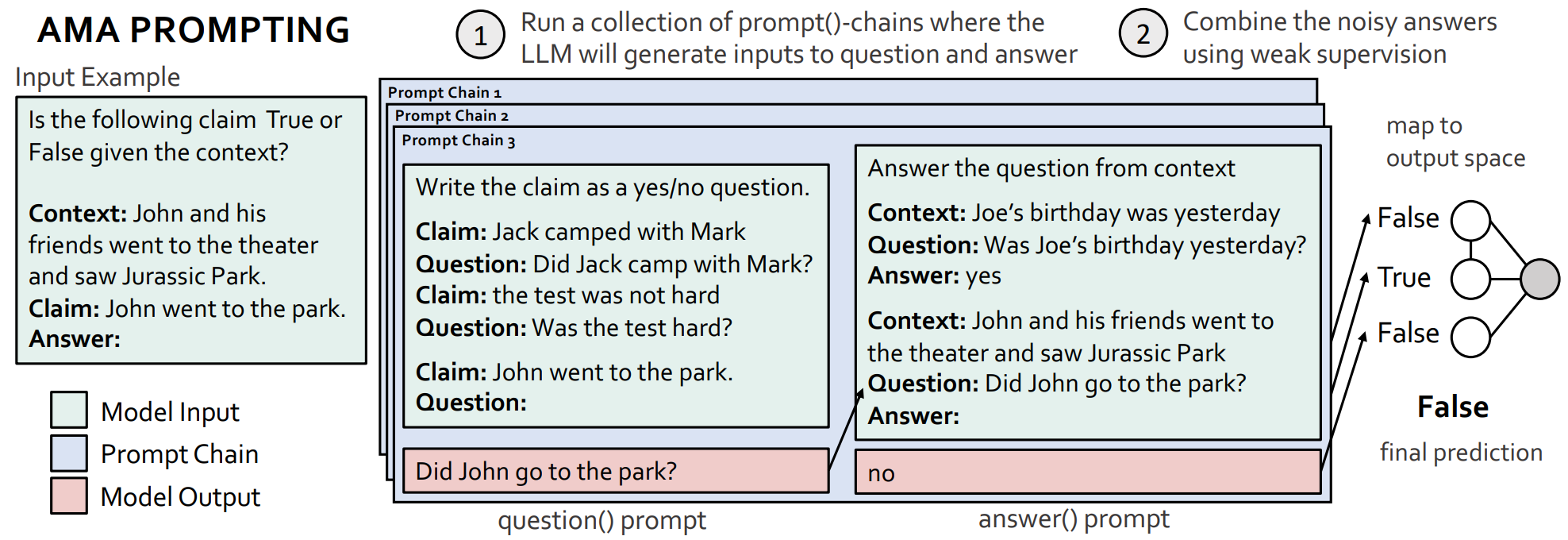
其中如上图所示:AMA首先递归地使用LLM将任务和提示重新格式化为有效的格式,然后使用弱监督聚合跨提示的预测。重新格式化是使用提示链来执行的,提示链由在不同的任务输入上操作的功能性(固定的、可重用的)提示组成。在这里,给定输入示例,提示链包括一个question()提示符,LLM通过这个提示符将输入声明转换为一个问题,以及一个answer()提示符,LLM通过这个提示符回答它生成的问题。不同的提示链(即不同的上下文问题和答案演示)导致对输入的真实标签的不同预测。
实验结果
1、下表1中比较开源GPT-J-6B和Few-Shot(k∈[32…70])GPT3- 175B的基准测试结果。可以发现,在20个基准测试中,有15个开源6B参数模型超过了GPT3-175B模型的平均Few-Shot性能。在20个任务中,AMA比6B参数模型的少次数(k = 3)性能平均提高了41%。

2、跨模型大小的分析和基准评估。 我们报告了 AMA 对少样本 (k = 3) 性能的绝对提升,平均超过 7 个任务,置信区间为 95%(左)。 按 7 项任务的平均 AMA 提升排序(右)。

3、Sanh等人实验结果T0的性能与prompt-source中10种不同提示格式的多数投票(MV)和弱监督(WS)相比。当使用prompt-source时,MV和WS的平均提升分别为3.6分和6.1分。

推荐阅读
[1] 一文了解EMNLP国际顶会 && 历年EMNLP论文下载 && 含EMNLP2022
[2]【历年NeurIPS论文下载】一文带你看懂NeurIPS国际顶会(内含NeurIPS2022)
[3]【微软研究院 && 含源码】相比黑盒模型,可解释模型同样可以获得理想的性能
[4]【IJCAI2022&&知识图谱】联邦环境下,基于元学习的图谱知识外推(阿里&浙大&含源码)
[5]【NLP论文分享&&语言表示】有望颠覆Transformer的图循环神经网络(GNN)
[6]【NeurIPS && 图谱问答】知识图谱(KG) Mutil-Hop推理的锥形嵌入方法(中科院–含源码)
[7]【NLP论文分享 && QA问答】动态关联GNN建立直接关联,优化multi-hop推理(含源码)

