
- 1移动互联网时代的信息安全与防护
- 2AI国际顶会ICLR 2024结果揭晓,蚂蚁集团11篇论文入选_icml2024流程
- 308_ZYNQ7020_新建驱动文件、编译_正点原子zynq7020电机驱动器
- 4带你玩转Python爬虫(爬取电影资源篇)_python简单爬取指定电影资源
- 5如何完美解决升级 IntelliJ IDEA 最新版之后遇到 Git 记住密码功能失效的问题_idea git记住密码失效
- 6Unity迷宫中吃金币_unity3d吃金币计数
- 7Llama 3 开源了「GitHub 热点速览」
- 8git 如何修改已提交的 commit 备注_eclipse修改git提交备注
- 9WebGL:基于web的交互式2D/3D图形引擎_基于 webgl2.0 设计二三维一体化的前端地图引擎
- 10计算机视觉动作识别——YOWO用于实时时空动作定位与识别的算法解析_单阶段目标跟踪算法yowo
LLMs: 强化学习从人类反馈中学习Reinforcement learning from human feedback (RLHF)
赞
踩
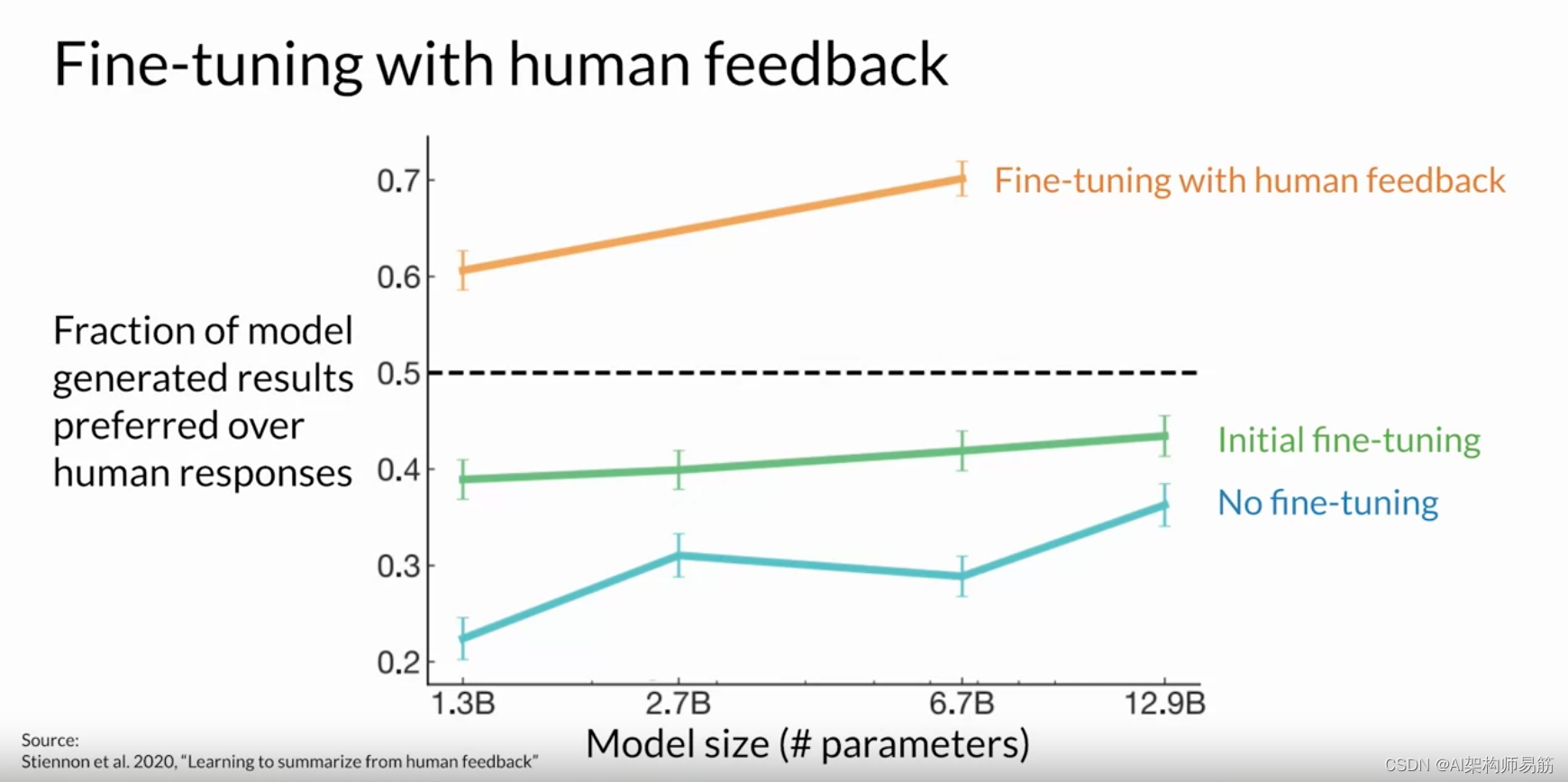
让我们考虑一下文本摘要的任务, 即使用模型生成一段简短的文本,捕捉 较长的文章中最重要的观点。 您的目标是通过向模型 展示人工生成的摘要示例,使用微调来提高模型的总结能力。 2020年,OpenAI的研究人员发表了一篇论文,探讨了使用 人工反馈进行微调来训练模型撰写文本文章的简短摘要。 在这里,你可以看到,与 预训练模型、 指令微调模型甚至参考人类基线相比,根据人类反馈进行微调的模型产生的响应效果更好。
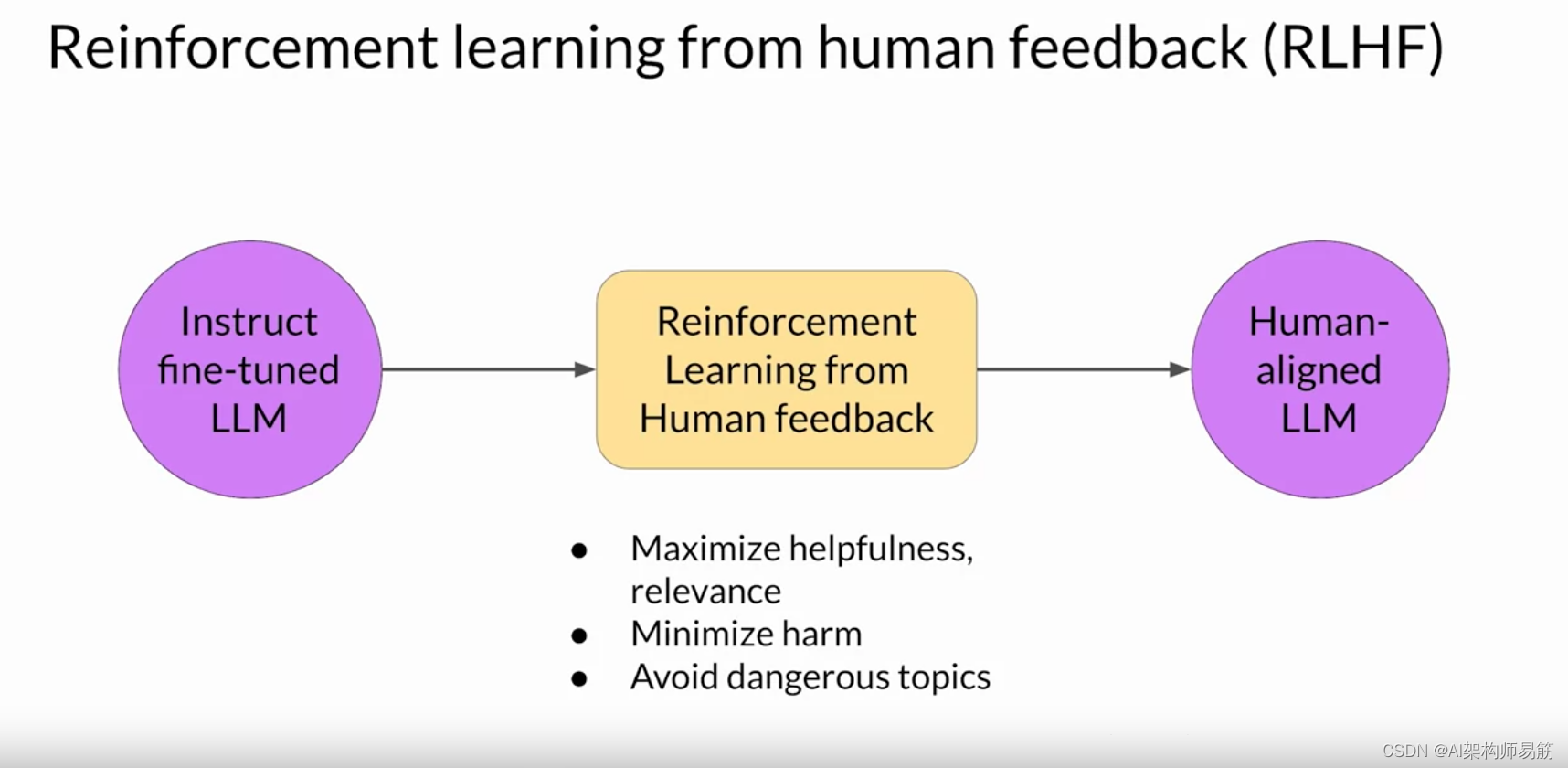
一种使用人类反馈对大型语言模型进行微调的流行技术 称为从人类反馈中进行强化学习,Reinforcement learning from human feedback (RLHF)。
顾名思义,RLHF使用强化学习( 简称RL)使用人类反馈数据对LLM进行微调, 从而生成更符合人类偏好的模型。 您可以使用 RLHF 来确保模型生成的输出能够 最大限度地提高输入提示的实用性和相关性。 也许最重要的是,RLHF可以帮助最大限度地减少可能的伤害。 你可以训练你的模型,让它给出承认其局限性的注意事项,并 避免使用有害的语言和话题。
RLHF的一个可能令人兴奋的应用是LLM的个性化, 在这种应用中,模型通过持续的反馈过程来学习每个用户的偏好。 这可能会带来令人兴奋的新技术,例如个性化的学习 计划或个性化的人工智能助手。
但是,为了了解这些未来的应用是如何 实现的,让我们首先仔细研究一下RLHF的工作原理。 如果你不熟悉强化学习, 这里有一些最重要的概念的高级概述。
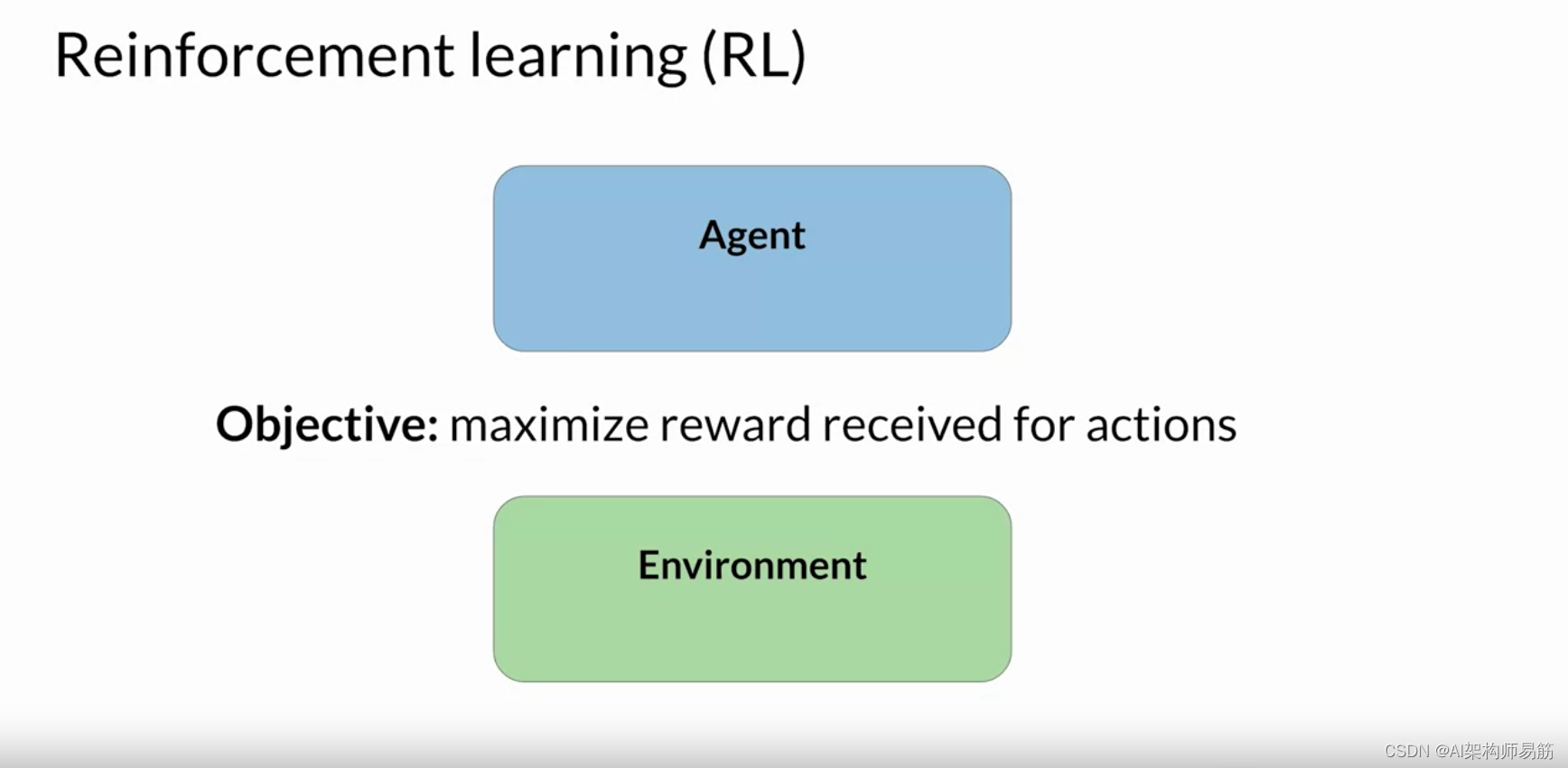
强化学习是一种机器学习,在这种学习中,代理人 通过在环境中采取行动来学习做出 与特定目标相关的决策,目的是最大限度地提高累积奖励的某些概念。
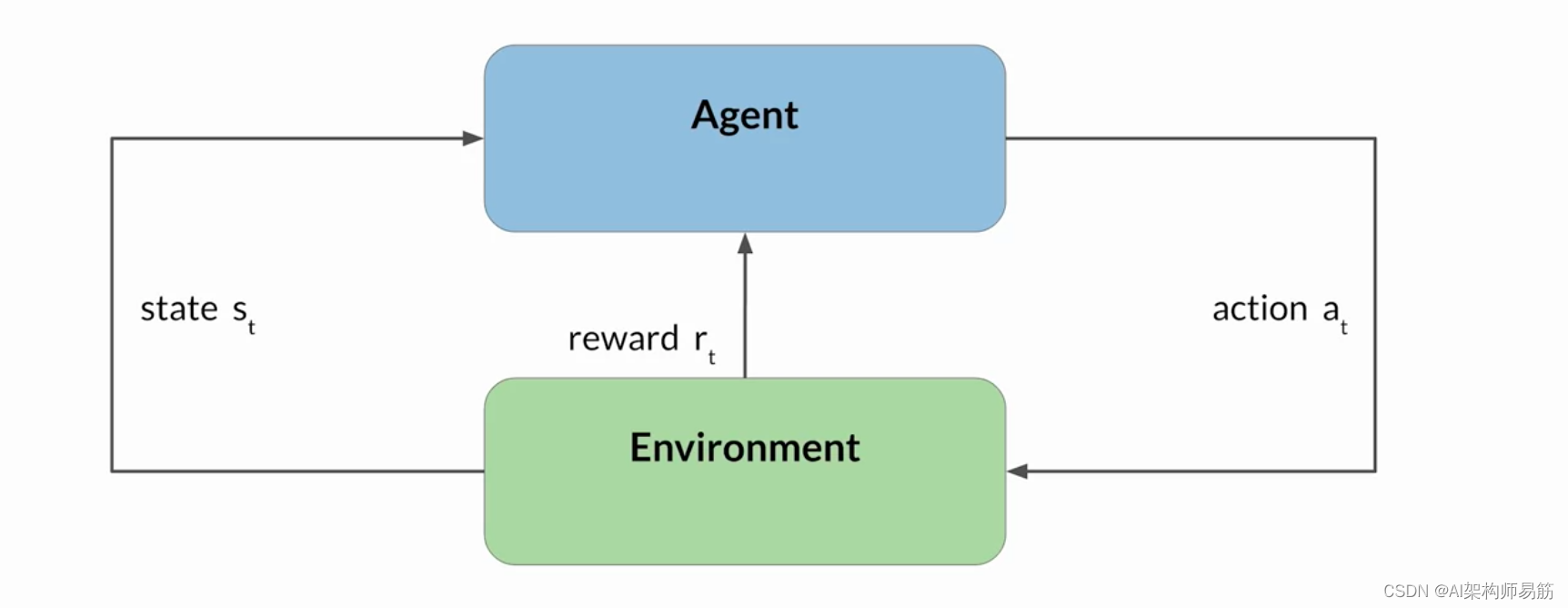
在这个框架中,代理人通过 采取行动、观察由此产生的环境变化以及 根据其行动结果获得奖励或处罚,不断从其经验中吸取教训。 通过迭代此过程,代理商会逐渐完善其策略或 政策,以做出更好的决策并增加成功的机会。
说明这些想法的一个有用例子是训练模型来玩井字游戏。 让我们来看看。 在此示例中,代理是充当 Tic-Tac-Toe 玩家的模型或策略。 它的目标是赢得比赛。 环境是三乘三的游戏板, 任何时候的状态都是棋盘的当前配置。 动作空间包括玩家可以 根据当前棋盘状态选择的所有可能位置。 代理通过遵循名为 RL 策略的策略来做出决策。 现在,当代理采取行动时,它会根据行动 走向胜利的有效性来收集奖励。 强化学习的目标是让代理人学习在 给定环境下的最佳策略,从而最大限度地提高他们的回报。 这个学习过程是迭代的,涉及反复试验。
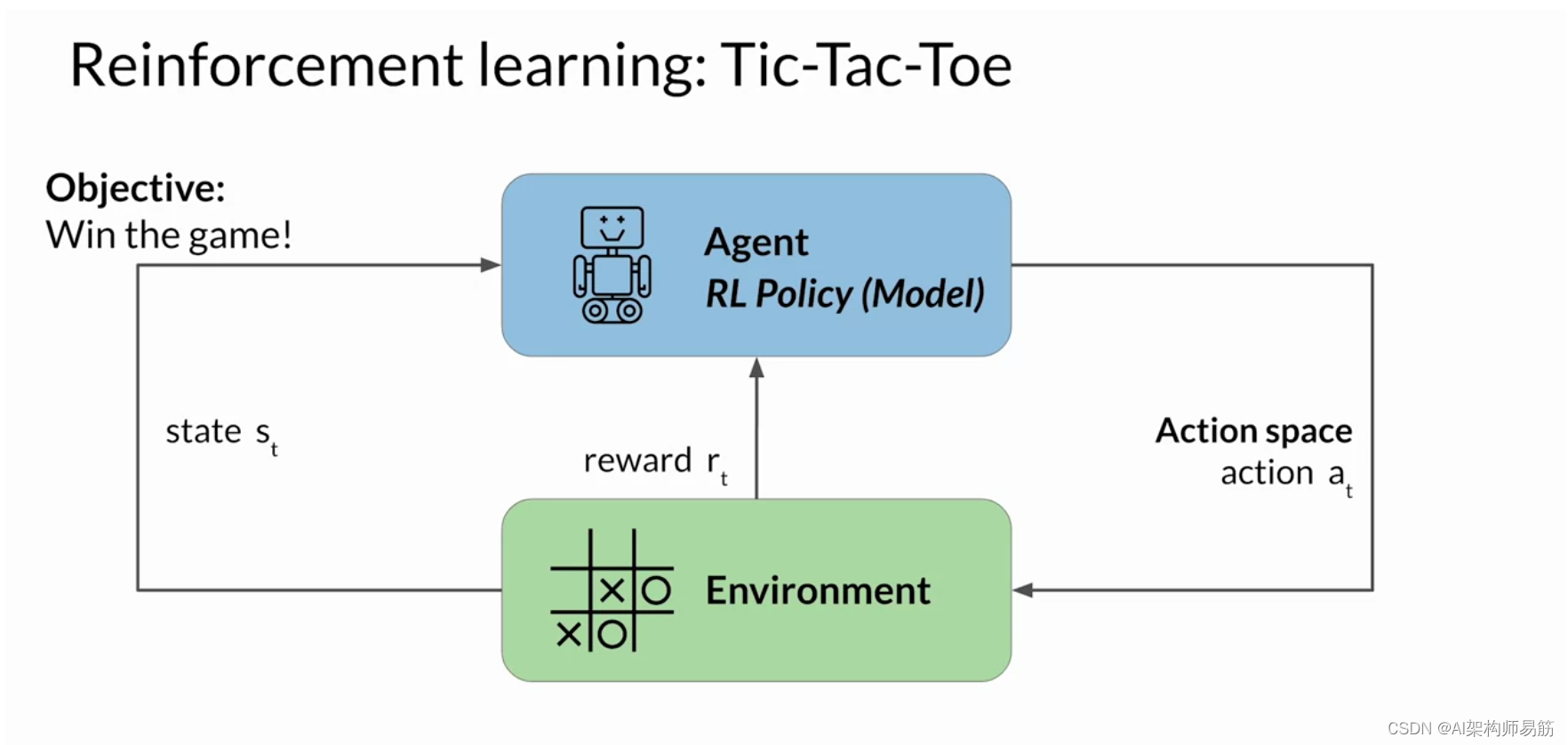
最初,代理会随机执行一个导致新状态的操作。 从这个状态开始 ,代理继续通过进一步的行动探索后续的状态。 一系列动作和相应的状态形成一个布局, 通常称为部署。 随着代理积累经验,它会逐渐发现能够产生 最高长期奖励的动作,最终在游戏中取得成功。
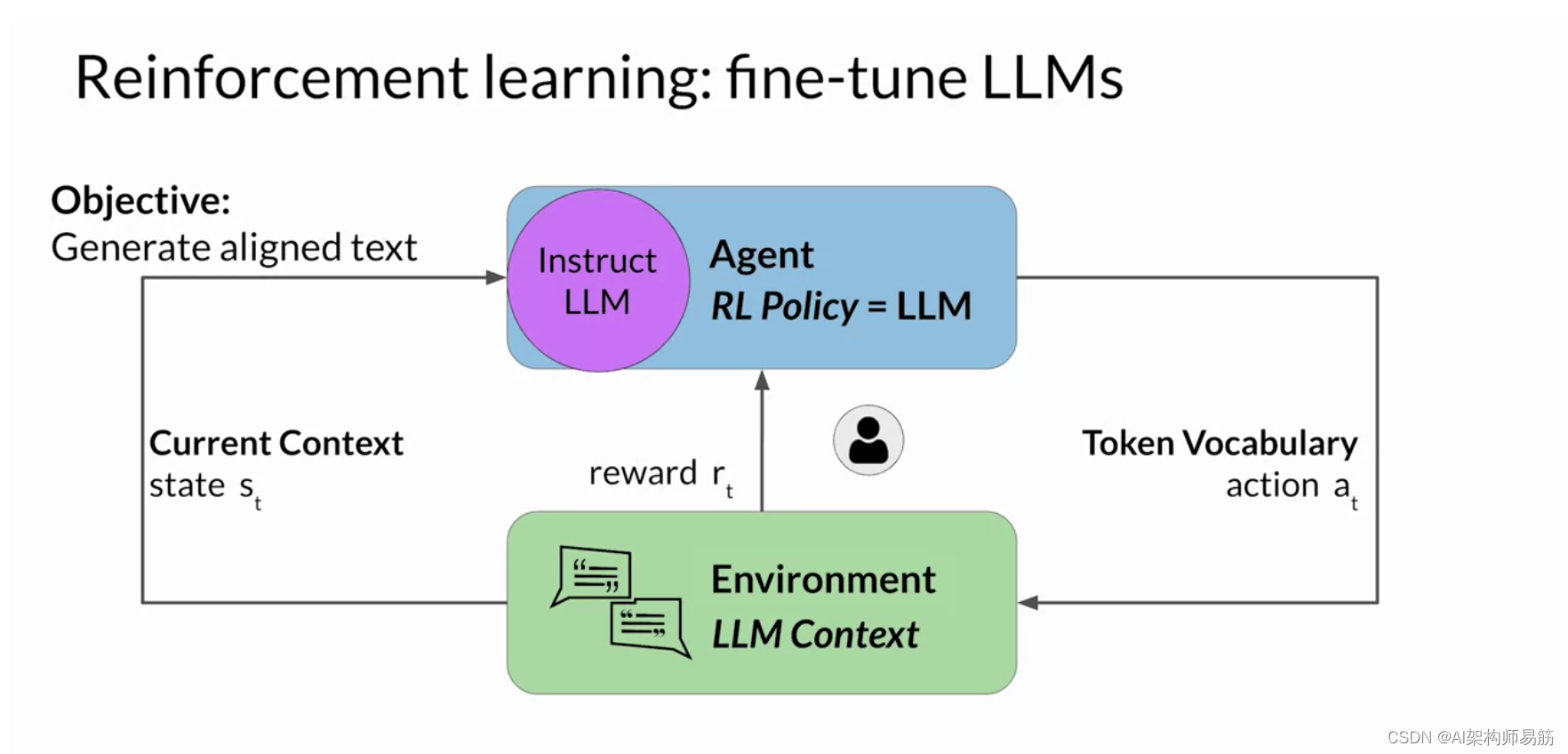
现在让我们来看看如何将 Tic-Tac-Toe 示例扩展 到使用 RLHF 微调大型语言模型的情况。 在这种情况下,代理人指导行动的政策是Instruct LLM ,其目标是生成被认为 符合人类偏好的文本。 例如,这可能意味着该文本有用、准确且无毒。 环境是模型的上下文窗口 ,在这个空间中可以通过提示输入文本。 模型在采取行动之前考虑的状态是当前上下文。 这意味着当前包含在上下文窗口中的任何文本。 这里的操作是生成文本的行为。 这可以是单个单词、一个句子或更长的格式文本, 具体取决于用户指定的任务。 动作空间是token词汇,意思是 模型可以选择生成完成的所有可能的标记。

Instruct LLM如何决定生成序列中的下一个代币,取决于 其在训练期间所学语言的统计表示。 在任何给定时刻,模型将采取的行动,即 它接下来要选择哪个标记,都取决于上下文中的提示文本和 词汇空间上的概率分布。 奖励是根据完成情况与人类 偏好的密切程度来分配的。
鉴于人类对语言的反应各不相同, 确定奖励比井字游戏示例更为复杂。 你可以做到这一点的一种方法是让人类根据 某种对齐度量标准来评估模型的所有完成情况, 例如确定生成的文本是有毒还是无毒。 此反馈可以表示为标量值,可以是零或一。
然后迭代更新 LLM 权重,以最大限度地提高 从人类分类器获得的奖励, 从而使模型能够生成无毒的补全。
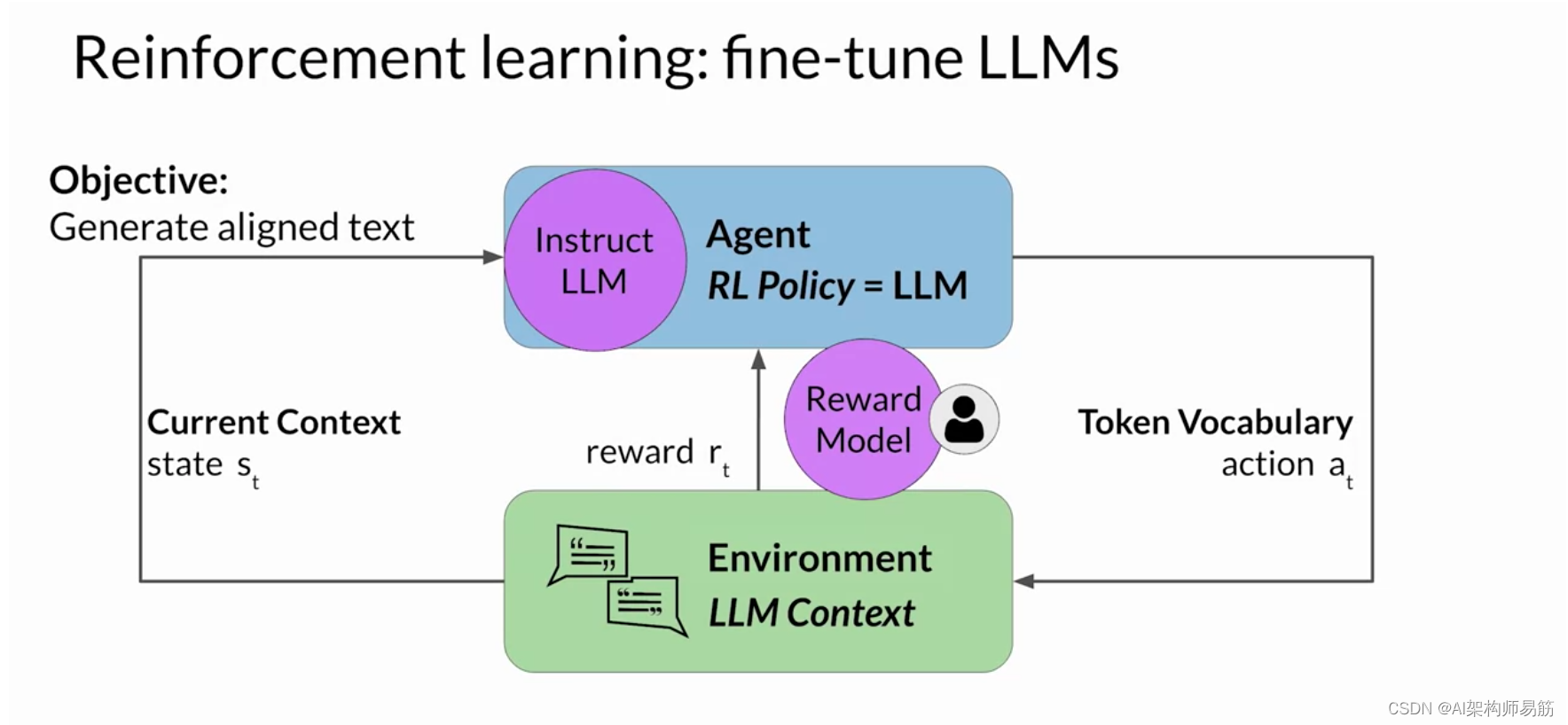
但是,获取人工反馈可能既耗时又昂贵。 作为一种实用且可扩展的替代方案,您可以使用一种 称为奖励模型的附加模型来对Instruct LLM的输出进行分类并评估与人类偏好的一致程度。 你将从少量的人类示例开始, 通过传统的监督学习方法训练二级模型。 训练完成后,你将使用奖励模型来评估 LLM 的输出并 分配奖励值,该值反过来又被用来更新 LLM 的权重并 训练一个新的人类对齐版本。
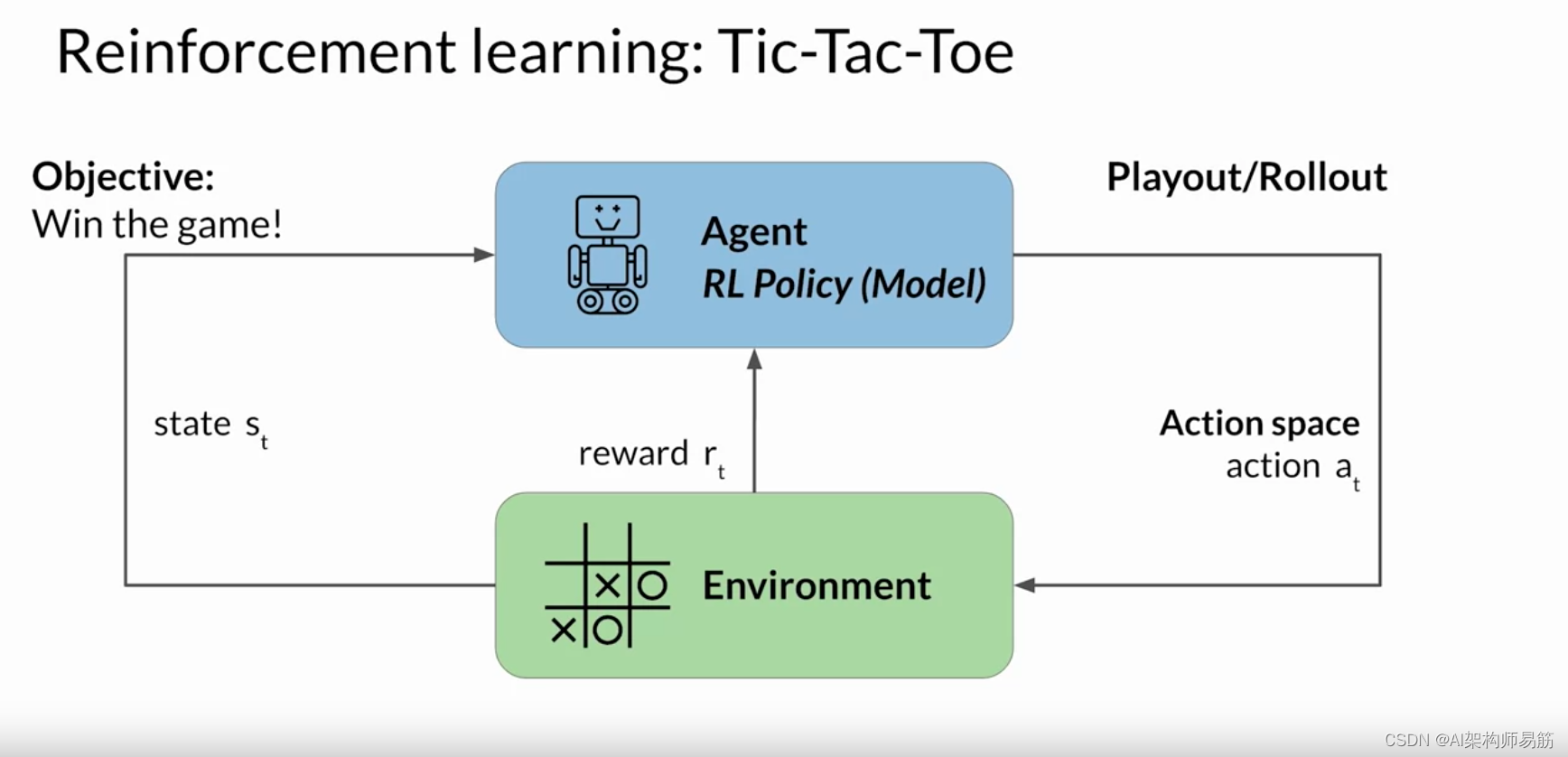
在评估模型完成情况时,权重的确切更新 方式取决于用于优化策略的算法。 不久你将更深入地探讨这些问题。 最后,请注意,在语言建模的背景下, 动作和状态的顺序被称为推出, 而不是经典强化学习中使用的术语 playout。
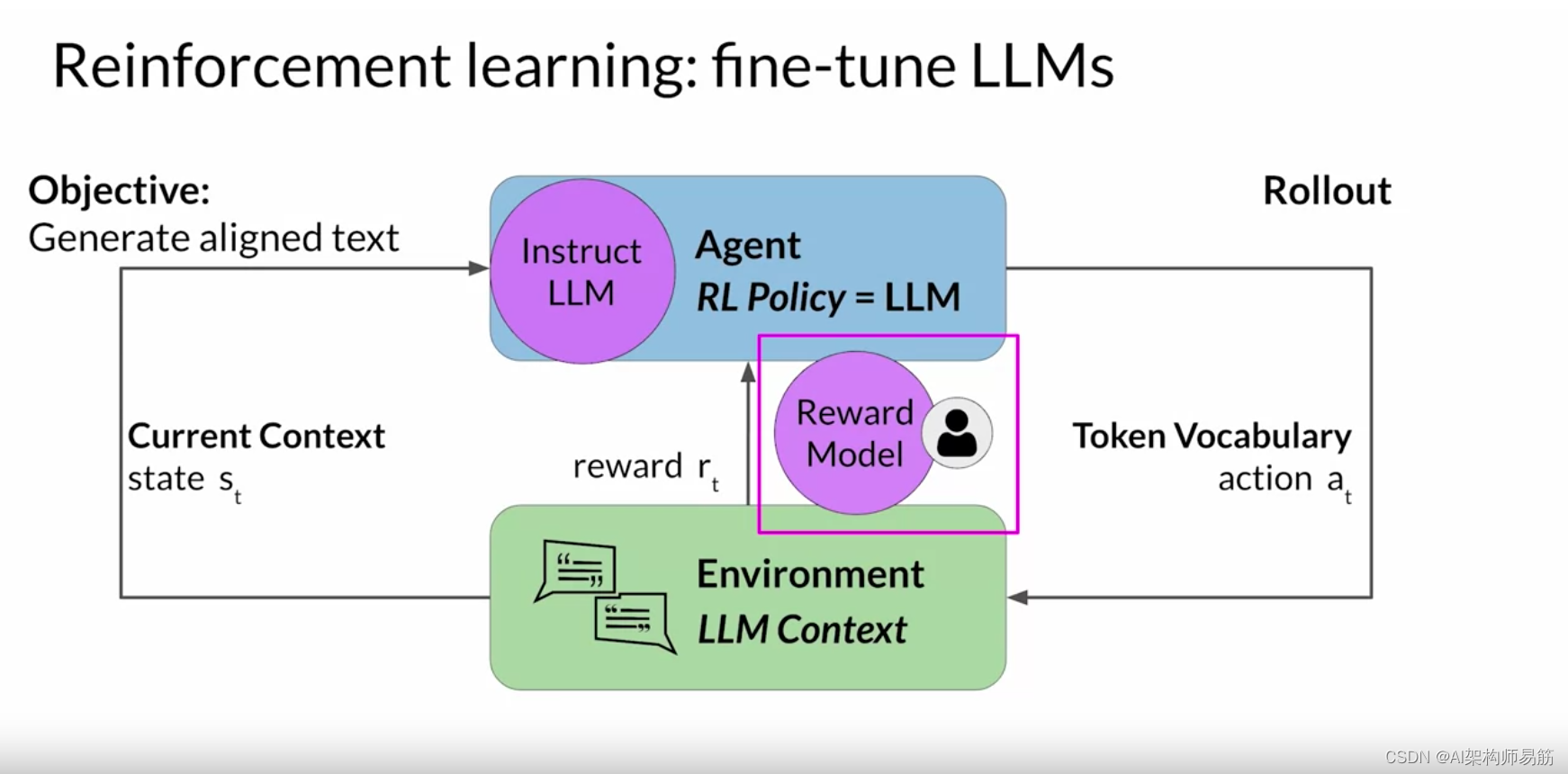
奖励模型是强化学习过程的核心组成部分。它对从人类反馈中学到的所有偏好进行编码,并且 在模型如何通过多次迭代更新权重方面起着核心作用。 在下一个视频中,您将看到该模型是如何训练的,以及在 强化学习过程中如何使用它对模型的输出进行分类。 让我们继续看看。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/NY6K0/reinforcement-learning-from-human-feedback-rlhf

