
- 1基于Jmeter的分布式压测环境搭建及简单压测实践
- 2LDA(Latent Dirichlet Allocation)主题模型_latent dirichlet allocation (lda) model
- 3从三个行业看AI大模型的生产力革命,谁处于爆发前夜?
- 4强化学习基础学习系列之model-free/planning/model-base/dyna方法总结_model base 耗时
- 5kafka的全面知识点_kafka为什么不走应用层
- 6Java 反转单链表_java单链表反转
- 7Oracle集合运算
- 8【AR开发-开源框架】使用Sceneform-EQR快速开发AR应用,当前接入了AREngine、ORB-SLAM,可快速地适配不同的安卓设备_ar免费框架
- 9超级详细的电脑通过网线连接树莓派操作步骤,以及无法查询到树莓派ip的解决办法(本人亲自踩坑无数总结而来,学不会来揍我系列)
- 10基于Springboot球馆体育馆运动场地预约系统设计与实现_基于springboot的羽 毛球场预约管理系统 的设计与实现
AI国际顶会ICLR 2024结果揭晓,蚂蚁集团11篇论文入选_icml2024流程
赞
踩
近日,人工智能顶会之一ICLR 2024录用结果揭晓,蚂蚁集团有11篇论文被收录,其中1篇为Oral,3篇为Spotlight,7篇为Poster,蚂蚁集团在AI学术领域的进展受到关注。

(图:蚂蚁集团的《长视频中的多粒度噪声关联学习》被收录为Oral论文)
ICLR组委会今年共收到了7262篇论文投稿,录用率约为31%。其中,1.2%被录用为Oral论文,作者获得10分钟的口头演讲,5%被录用为Spotlight论文,获得4分钟的聚光灯展示;Poster论文则以海报形式展示。论文的重要性按此三类递减。
每年,ICLR Oral论文中一大半的论文会成为“ICLR Best Paper”,同时也代表了新一年的研究方向,今年ICLR评出的Oral论文共85篇,其中包括蚂蚁集团的《Multi-granularity Correspondence Learning from Noisy Instructional Videos》(长视频中的多粒度噪声关联学习)。
短视频已成为大众日常生活的主要娱乐方式,多模态技术也是当前AI的热门领域,由于过高的计算资源开销,现有的视频工作主要集中于片段的理解,而忽视了长视频中的时序依赖。该论文将长视频学习转化为短视频片段间的关联对齐,针对视频与文本间显著存在的噪声关联问题,提出了统一的最优传输对齐方案,显著提升了长视频理解能力并节省了时间开销。
这个方案还具有通用性,提出的噪声关联处理方法可应用于其他模态需要进行内容对齐的模型预训练学习中。
收录为Spotlight的3篇论文分别是《iTransformer: Inverted Transformers Are Effective for Time Series Forecasting》(iTransformer:倒置Transformer对时序预测更加有效),讲述一种新的时间序列预测工作,打破常规模型结构,在复杂时序预测任务中取得了全面领先;《Enhanced Face Recognition using Intra-class Incoherence Constraint》(利用类内不一致性约束增强的人脸识别技术),引入一个新的方法,进一步提高人脸识别的精确度。《Finite-State Autoregressive Entropy Coding for Efficient Learned Lossless Compression》(基于查找表实现的可学习自回归模型用于高效无损压缩算法),提出了一种新的算法,实现了高压缩率、高吞吐率的无损压缩。
自2017年以来,ICLR每年收到的论文数量以30%的速度增长,其它两个人工智能顶会NeurIPS、ICML也是高增长。在上个月举行的NeurlPS上,蚂蚁集团共有20篇论文被收录,覆盖计算机视觉、自然语言处理、图神经网络、图像处理等多个人工智能和机器学习领域的前沿主题。
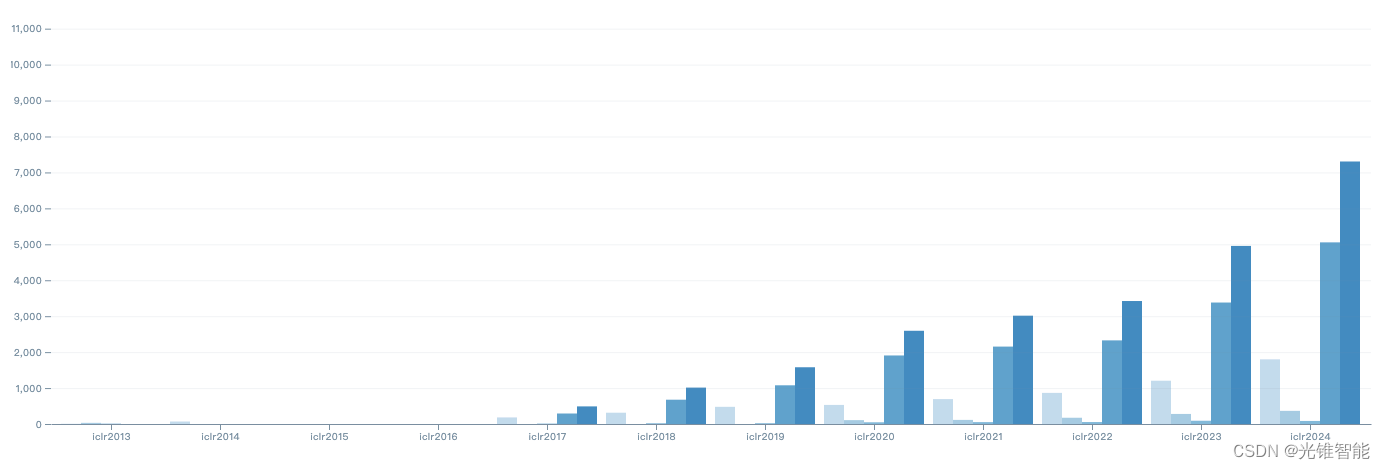
(图:ICLR自2013年成立以来,每年的论文数量情况。2017年开始,论文数量攀升。)
ICLR近年受到业内好评,主要原因是其推行的Open Review评审制度,所有提交的论文都会接受所有同行的评价及提问,任何学者都可匿名或实名地评价论文。而在公开评审结束后,论文作者也能够对论文进行调整和修改。
据了解,过去五年,蚂蚁集团在国际顶级学术期刊和学术会议上发表论文近500篇,其中AI领域的论文300余篇。蚂蚁集团在人工智能领域持续进行技术投入,基于大规模业务场景的需求,布局了包括大模型、知识图谱、运筹优化、图学习、可信AI等在内的技术领域。


