
- 1如何培养程序员的领导力?_程序员如何培养自己的管理能力
- 2【1】MongoDB的安装以及连接_mongodb怎么连接
- 3Linux 安装 Gitblit_gitblit linux 安装
- 42022卡塔尔世界杯互动游戏|运营策略_世界杯 运营 活动 游戏
- 5vivado的RTL设计与联合modelsim仿真_vivado可以生成rtl
- 6目前常见的Linux操作系统_linux操作系统分类
- 7京东软件测试岗:不忍直视的三面,幸好做足了准备,月薪18k,已拿offer_京东测开三面
- 8视觉应用线扫相机速度反馈(倍福CX7000PLC应用)
- 9GPT3.5、GPT4、GPT4o的性能对比_gpt3.5和gpt4o
- 10【C语言题解】1、写一个宏来计算结构体中某成员相对于首地址的偏移量;2、写一个宏来交换一个整数二进制的奇偶位
基于爬虫技术的知识图谱可视化实现—— 以河海大学教师信息为例_爬虫爬取的知识构建知识图谱
赞
踩
0 摘要
该系统是基于河海大学教师信息网为数据源进行展开的,主要由爬虫获取教师数据、后端教师数据
持久化、前端数据可视化三个模块组成。主要功能有:展示校内各教师相互间的关系、各学院教师主页点击量TOP10、教师年龄分布情况、主要学院综合实力排名等。第三章开始为系统具体实现部分
1 引言
随着移动通信网络和大数据技术的发展,未来网络将不是单一存在或仅使用单一技术,而是多种技术的共存互补,共同发展。在这种网络异构化、密集化的发展趋向下,如何高效精准的获取高价值信息成为了一个巨大的挑战。放眼当下,以往通过人工采集数据的方式在数据量动辄呈指数倍增长的今天已不再适用,不仅任务量大,重复率高,还耗费时间与人力开销;另一方面,对于获取到的数据,如何更加简洁、具有说服力地呈现给客户同样是亟待解决的问题;此外,获取到的数据之间往往存在非常强的耦合性,如何更加直观的表示他们之间的关系也是研究人员不得不正视的问题。
基于此,本文旨在通过一种结合网络爬虫、Echarts数据可视化技术实现关键数据的知识图谱展示(以河海大学教师信息网为例)。
2 相关技术
2.1 网络爬虫
网络爬虫也被称为Web蜘蛛技术,有时也被称为Web机器人。爬虫技术主要用于搜索引擎,通过全球互联网网络有效获取相关网站信息,并沿着网站链接进一步收集相应网站系统上的信息。它是一个强大的自动信息采集程序,一个整体的搜索引擎系统,是系统的基本组成部分。
爬虫技术主要涵盖信息存储、信息处理、数据采集和其他基本功能。在传统模式下,爬虫技术通常需要合理设置可能是一个或多个页面的目标索引页面。在收集和提取过程中,如果发现新页,则必须将该页合并到索引序列中,直到满足目标条件,才能停止对信息的索引。整个系统信息索引过程比较复杂和麻烦。其中包括:。首先,对收集到的目标内容进行全面过滤,以排除不起作用的信息。然后,自动搜索各种新链接,以查找适当的目标序列。第三,始终搜索指向网站的链接,直到满足基本条件。在对系统进行索引后,应及时维护收集到的信息,同时根据设置的标准对收集到的信息实施二次过滤,以显示与对象相近、与系统关系密切的信息数据。分析。为所有索引信息创建适当的目标索引,以便在以后的阶段对类似主题内容进行有效的查询和引用,并全面优化索引信息的效率。网页阅读器技术价值的主要功能是提高在线系统信息采集的易用性和便利性,便于人类操作,自动提取各种准确、完美的信息数据,优化用户体验。

2.1.1 技术原理
网络爬虫技术下,可以按照最初的URL目标序列,对网络中各种信息以及相关链接进行有选择地探索访问,顺利得到所需信息数据。在应用网络爬虫技术实施信息抓取过程中,需要按照关联性算法和分析措施对那些和目标不符的信息户数实施有效过滤,筛选出有用信息和链接,保留和目标相符的链接存储至待下载列表内,同时其能够按照相关搜索原则和搜索策略在整个序列内对下一目标抓取链接进行合理选择,重复相关操作,直到满足基础条件便可以停止筛选和提取,比如在URL目标列表变空状态下。网络爬虫一般组成结构如图2所示。

2.1.2 关键技术
爬虫技术涵盖在线数据挖掘、自然语言处理、机器学习、数据检索等多个研究领域。相关的理论基础包括概率统计、人工智能、信息检索等专业理论。此外,爬虫技术还涵盖了各种新的Web技术,例如典型的超链接分析技术,涵盖了目标数据的说明和URL搜索策略。现在,Web爬虫的爬行目标描述可以分解为域概念、目标数据表格和网站属性。其中,网站属性包括相关的内容属性和链接结构属性。基于目标页面的属性,Web索引为对象目录添加索引、保存和创建。相应的精液采样表应包含以下形式:在第一次的姿势中,第一次的精液样本必须是预先设定好的。第二,指定目标评价目录的对应中文样本,如各网站的评价目录和Yahoo的对应评价结构等。第三个目标是根据用户行为合理确定目标样本。例如,在用户浏览阶段收集的样本会被从用户日志中获取的样本和使用的模型完全标记。根据Web索引的目标数据模式,最重要的项目是网站上的各种信息。所收集的相应数据必须符合相应模型的要求。同时,具有良好的可转换性,可以映射到目标数据模式中。
通过域索引和本体的创建,可以从语义的角度正确分析各属性的含义。网络爬虫的主要目的是使用更少的资源,在有限的时间内获取相关信息。网络爬虫的搜索策略可以分为URL排序策略和网站分析算法。这些都是实现相关目标的重要问题。基本上,Web爬虫的搜索策略可以分为两种形式:第一种是一般化的策略,通过启发式搜索和自动分类搜索来操作。爬虫对象的定义和URL对应的搜索策略之间有特定的内部关系。第一个索引对象的定义和概括性说明直接决定了搜索策略的制定方法。相应的搜索策略直接决定Web索引功能,并决定搜索引擎的相应服务状态。
2.2 Echarts数据可视化
2.2.1 数据可视化
主要研究数据的可视化表示,并通过图形、图形、计算机可视化和用户界面组织、表示和显示数据。经过几个世纪的发展,数据在军事、航空、物理、天文、生物等领域变得突出。
当人们从外界获取信息时,超过80%的信息是通过视觉系统获得的。以图表或图表形式查看数据最重要的好处是可以直观地显示数据之间的相互关系和趋势,以及数据访问和理解质量的显著提高。特别是自2011年互联网进入大数据时代以来,人们需要从生物质中获取有效的信息。数据可视化显示技术可以有效地帮助分析来自不同纬度和来源的海量信息以及实时决策。目前常用的数据可视化技术包括Excel、Tableau、Python等。
2.2.2 Echarts技术
Echarts是一个基于JavaScript的开源表可视化存储库,可以在其中显示可视化、交互式和个人数据。它最初是由百度集团发现的,后来移交给阿帕奇基金会。这是2021年Apache最重要的项目。回声位置提供了一种非常丰富的视觉图表类型。传统的图表包括线性图、列、煎饼图和分散点图。其他图表包括用于数据统计的图表、用于地理数据可视化显示的地图、热图和折线图、说明关系数据的地图、树木和旭日图、漏斗图以及用于BI(商业智能)的桌面。完全有可能满足网站上数据可视化显示的要求。
2.3 知识图谱
自2012年谷歌推出知识图谱概念以来,该概念在业界得到了广泛关注,近年来在许多领域得到了广泛应用。知识图谱可以汇集大量的信息、数据和知识链接,方便信息资源的计算、理解和评估,更有效地表达和管理组织,利用现有的海量异构动态大数据。让网络更智能可能更适合人类的认知思维。
目前,随着智能信息服务应用的发展,知识地图被广泛应用于智能搜索、智能答疑、个性化推荐等领域。特别是在智能搜索中,用户的搜索不仅仅局限于简单的关键字匹配,但根据搜索情况和用户的意图来实现概念搜索。同时,用户的搜索结果具有层次性和结构化。例如,当用户搜索梵高时,该引擎以与图像等描述性信息相对应的知识地图的形式提供详细的专业信息、艺术生涯信息和来自不同时代的代表性作品。知识地图使计算机能够理解人类语言如何进行交流,并更智能地响应用户的需求。同时,通过知识图谱将互联网上的信息、数据和互联关系聚合为知识,方便了信息资源的计算、理解和评价,形成了基于语义的web知识基础。

2.4 正则表达式
正则表达式由美国数学家Stephen Kleene于1956年提出,主要用于描述正则集代数。它是提供给计算机操作和检验所要抽取的字符串数据的一种强大的工具,是一串由特定意义的字符组成的字符串,表示某种匹配的规则。正则表达式能够应用在Linux、Unix、Windows等多种操作系统中,几乎所有的语言PHP、C#、C++、Java等都支持它。一个正则表达式是由普通字符(例如字符a到z)以及特殊字符(称为元字符)组成的文字模式,描述了待搜索字符串的匹配模式。元字符指那些在正则表达式中具有特殊意义的专用字符,用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。正则表达式的形式为/匹配模式/,其中位于定界符之间的部分就是将要在目标对象中进行匹配的模式。用户只要把希望查找匹配对象的模式内容放入定界符”/”之间即可以。
3 系统实现
3.1 系统架构
本系统是基于河海大学教师信息网为数据源进行展开的,主要由爬虫获取教师数据、后端教师数据持久化、前端数据可视化三个模块组成,系统架构图如图4所示。
其中爬虫获取数据是整个系统实现的关键,该过程是整个系统得以正常运转的基石。通过网络爬虫技术获取教师信息,经过数据清洗、去重等一些列数据预处理后,得到后续工作所依赖的有价值数据,省去了大量的人工成本与时间精力。
后端教师数据的持久化同样是整个系统中不可或缺的一环。数据存如数据库后开放人员便可开始对已有数据进行合理分析,以供后续工作的使用。
最后,数据可视化技术则可以有效地帮助人们分析高纬度多来源的海量数据信息,并辅助人们做出一些即时的决策。
本系统是将收集到的教师数据进行整合分析后,统一汇总成图表形式的直观系统,它可以帮助我们有效分析各种数据之间的比较、联系、构成以及分布情况,清晰有效地理解传达与沟通信息,大大增加了用户与数据之间的互动程度。

3.2 数据持久化层
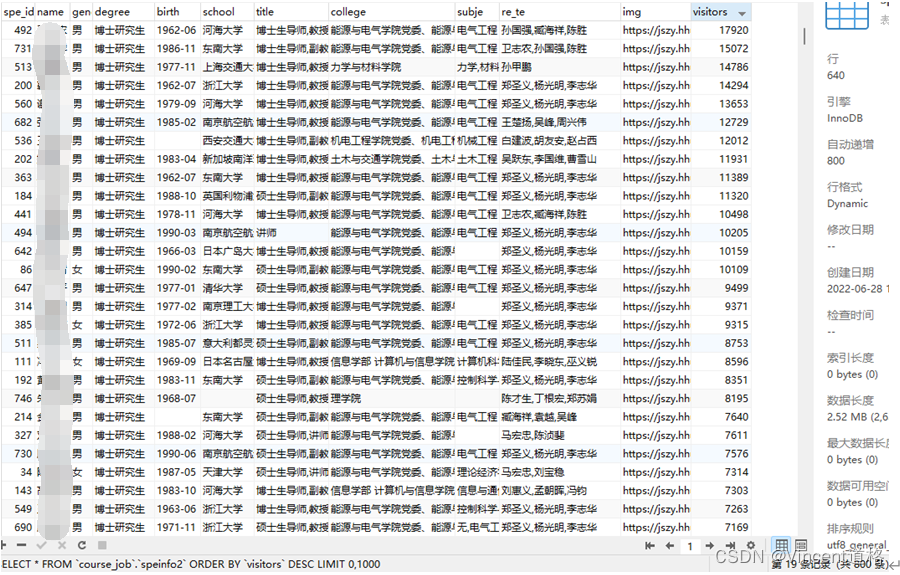
由教师信息网的教师详情页中可以选择出对于本系统而言比较重要的一些字段,它们分别是:教师id,教师姓名,性别,出生年月,学历,毕业院校,职称,学院,研究方向,个人照片,相关教师以及访问人数。其中最重要也与本系统相关性最强的字段是相关教师,它表示与某位教师在教授课程、研究领域以及项目合作等方面有较强关联的教师,它也是后续知识图谱能够成功实现的重要保障。其余字段具体信息参看表1

3.3 爬虫获取数据
本模块既是整个系统的关键模块又是难度、任务量最大的模块。工欲善其事,必先利其器,在正式开发之前应该完成相应开发环境的配置工作。
3.3.1 环境配置
- 通过pip安装selenium。selenium是最广泛使用的开源 Web UI(用户界面)自动化测试套件之一。Selenium 支持的语言包括C#,Java,Perl,PHP,Python 和 Ruby。Selenium在爬虫界有着所见即所得的美誉,也正因此,学校教师官网的反爬机制在selenium技术的帮助下得以轻松化解。

- 下载浏览器驱动器,ChromeDriver.exe [https://chromedriver.storage.googleapis.com/index.html]。正如上文所言,selenium是一种自动化测试套件,针对不同的浏览器,需要安装不同的驱动才能正常工作。此处安装ChromeDriver.exe需要与当前使用的Chrome浏览器版本相同或相近。


- pip下载pymysql。Pymysql是python用于连接Mysql服务器的库,之后通过爬虫获取到的数据要写入数据库中,方便后续对数据进行查询操作

3.3.2 业务流程
由于学校教师信息网使用了反爬机制,re等传统的爬虫方法不再管用,而此时selenium便成了不二之选。使用selenium进行爬虫的业务流程主要分为以下几步:
- 请求教师信息页URL
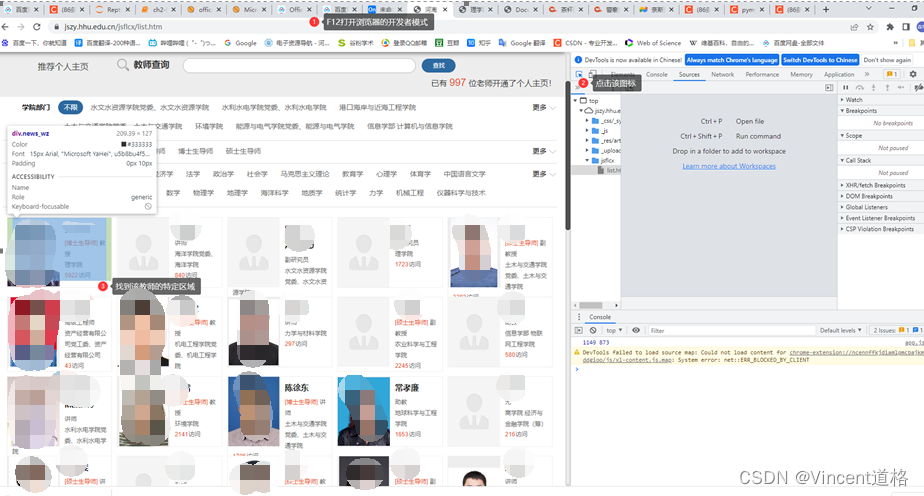
- 通过F12打开浏览器的开发者模式,再如图7所示找到某特定教师的超链接地址并进行点击。
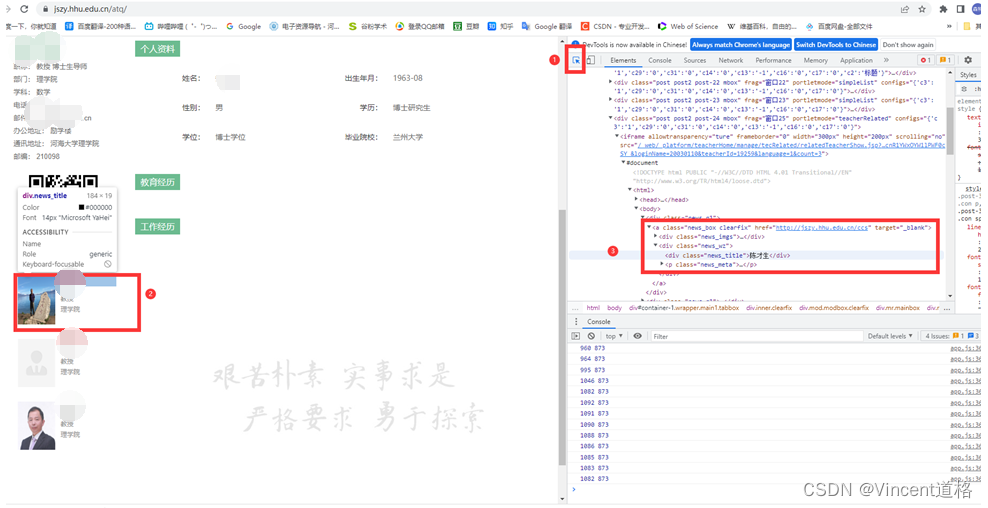
- 点击该超链接后,selenium需要将聚焦切换到弹出的新窗口,新窗口中包含了我们所需的有效信息,分别进行爬取。此处以相关教师为例,与2中描述的操作类似,参考图8定位到相关教师在该HTML中的位置后,利用Xpath进行爬取。
- 待某一教师信息的所需信息爬取完成后,关闭该页面,selenium聚焦回到初始页面。
- 直到该页所有教师信息爬取完毕后点击下一页。
- 直到所有页的全部教师信息爬取完毕后完成数据爬取。
- 将爬取到的生数据进行简单的数据预处理,如删除脏数据、重复数据,保证之后数据分析的真实可靠。
- 将数据预处理后的数据写入数据库,方便后续的查询操作。
- 将每一位教师的关联关系映射为json文件,为知识图谱可视化提供数据支持。
上述流程可简化如图11所示。

3.3.3 关键代码
- 获取相关教师信息。相关教师的区域在该HTML中是以Iframe的形式展现的,因此需要selnium先切换到iframe上,再对其中的内容进行遍历获取。

- 获取研究方向。由于详情页中研究方向需要移动鼠标至“科学研究”一栏才能显示,此处需要用ActionChains进行鼠标控制,定位后才可对研究方向进行获取。

- 其他内容获取。

- 正则表达式过滤外籍教师。由于学校教师信息页对外国教师页面的维护有待提高,不是没有可用信息就是无法打开。因此,本次的校园教师爬取不包括外籍教师。先获取即将点开的教师姓名,若是首字母以英文开头则直接跳过,不再点开收集数据。

- 将每一位教师的相关关系映射为json文件。后续使用的Echarts-NPM需要的数据源为json格式,此处自定义映射关系字典,其中包含最重要的两个属性:”sourceID”以及”targetID”,分别表示数据源和相关数据。通过遍历数据库中每个老师的“相关教师”字段,再进行按逗号分隔后,便可得到单个的相关教师。

3.3.4 数据展示
- 教师数据信息表,除去外籍教师,重复教师后,总计收集到800位教师的部分信息。
- 教师相关关系

3.4 前端可视化
本模块在有了之前工作的铺垫下,工作量有了较为可观的减小。ECharts是一个使用 JavaScript 实现的开源可视化库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari等),底层依赖矢量图形库 ZRender,提供直观,交互丰富,可高度个性化定制的数据可视化图表通过Echarts技术实现数据可视化一般分为以下五步:
- 下载并引入echarts.js文件
- 在HTML页面中准备好具有大小的DOM容器
- 初始化echarts实例对象
- 指定配置项和数据(option)
- 将配置项设置赋值给echarts实例对象
3.4.1 教师关系图
上述两步工作得到Json文件中包含两个对象:“nodes”和“edges”,它们分别表示教师实体与该教师所具有的关系。
其中,“nodes”中有800个元素,每个元素表示一位特定教师,在元素中又包含元素名、随机生成的元素颜色、随机生成的x,y标签(范围在[-1000,1000])、随机生成的元素大小值以及标识该元素的id;
“edges”中则包含多达2000个元素,每个元素表示两两教师间的关系映射。每个元素中最为重要的是sourceID,targetID,它们分别表示关系源与关系终点。

将上述的Json文件作为前端Echarts的数据源,引入echarts.js,dataTool.js两个辅助文件,设置好关系图的各配置项后,将Json文件中的数据映射到Echarts端即可生成可视化的知识图谱。

需要注意的是,图20中圆表示某位教师,其大小与该名教师与其他相关教师的数量成正比,即,与某位教师相关的教师越多,则该名教师的圆越大。


3.4.2 主要学院教师点击量
本次统计选取教师人数大于等于四十的学院,一共有六个,分别是信息学部,能电院,农科院,理学院,土木院,水文院。对每个入围学院,又进行了按照访问量的降序排列,选出该学院前二十名教师,最终以箱线图的形式进行展示。


3.4.3 系统集成后效果展示
因篇幅有限,剩余的可视化模块不再进行赘述,实现思路大同小异并且难度远不如上述两个可视化模块。

4. 结论
本文实现了基于爬虫技术的知识图谱可视化,系统的阐述了网络爬虫技术(本质上就是使用正则表达式对Web页面进行信息抽取的过程)、Echarts可视化技术、知识图谱以及正则表达式。爬虫与知识图谱可视化的结合在大数据时代的未来将会成为计算机领域的热门研究问题知识图谱的重要性不仅在于它是一个拥有强大语义处理能力与开放互联能力的知识库,并且它还是一把开启智能机器大脑的钥匙,能够打开Web 3.0 时代的知识宝库,为相关学科领域开启新的发展方向。在未来的几年时间内,知识图谱仍将是大数据智能的前沿研究问题。
参考文献
[1]奚增辉,王卫斌,陆嘉铭,瞿海妮.应用主题爬虫的电力网络舆情数据采集[J].西安工程大学学报,2022,36(02):72-78.DOI:10.13338/j.issn.1674-649x.2022.02.010.
[2]刘正华,周杰枫,窦崎.基于网络爬虫的智能挖掘技术研究[J].电子技术与软件工程,2022(08):13-16.
[3]彭曙光,王梦梅,赵麒博,申刘宝,彭玉杰,陆雪艳.面向ECharts的疫情信息可视化系统[J].福建电脑,2022,38(04):80-83.DOI:10.16707/j.cnki.fjpc.2022.04.021.
[4]许梦雅.基于Echarts技术的企业数据可视化的设计与开发[J].现代信息科技,2022,6(06):90-92+96.DOI:10.19850/j.cnki.2096-4706.2022.06.022.
[4]刘国英,李建平.ECharts在短波监测数据可视化中的应用[J].中国无线电,2022(02):59-60.
[5]谷奉锦,贺楚闳,潘庆亚,王晔,朱晓荣.基于知识图谱的5G网络故障分析方法[J/OL].无线电通信技术:1-14[2022-06-29].http://kns.cnki.net/kcms/detail/13.1099.TN.20220616.1133.002.html
[6]刘峤,李杨,段宏,刘瑶,秦志光.知识图谱构建技术综述[J].计算机研究与发展,2016,53(03):582-600.
[7]胡军伟,秦奕青,张伟.正则表达式在Web信息抽取中的应用[J].北京信息科技大学学报(自然科学版),2011,26(06):86-89.DOI:10.16508/j.cnki.11-5866/n.2011.06.014.

