
热门标签
热门文章
- 1内网对抗-隧道技术篇&防火墙组策略&HTTP反向&SSH转发&出网穿透&CrossC2&解决方案
- 2基于四叉树构建金字塔数据_“四叉树结构”规则,以“均匀分块+金字塔分层”的方式实现在产企业实景三维地形可
- 32020年学习Java语言主攻哪个方向最有前景?_编程主攻方向有哪些
- 4【游戏引擎之路】登神长阶(七)——x86汇编学习:凡做难事,必有所得
- 5chatgpt赋能python:Python拆分CSV:快速轻松地处理大规模数据_csv数据量太大怎么拆分
- 6Gitee码云 remote: Incorrect username or password ( access token )_gitee incorrect username or password (access token
- 7Mybatis-plus 集成 PostgreSQL 数据库自增序列问题记录_mybatis plus pg id自增
- 8Docker快速入门二:Docker配置国内镜像源、常用命令_docker更换国内源命令
- 9mac python下载安装教程,python在mac上怎么下载_mac下载python
- 10AI时代提问比答案更重要-向大模型学习提问的四个招式_大模型提问技巧
当前位置: article > 正文
总结:大模型指令对齐训练原理
作者:秋刀鱼在做梦 | 2024-07-12 01:26:02
赞
踩
大模型指令对齐
原文地址:大模型指令对齐训练原理
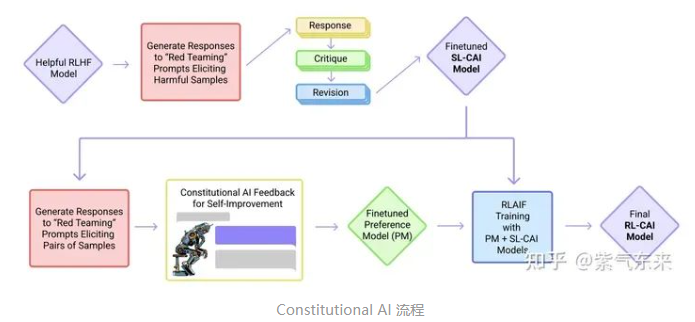
- RLHF
- SFT
- RM
- PPO
- AIHF-based
- RLAIF
- 核心在于通过AI 模型监督其他 AI 模型,即在SFT阶段,从初始模型中采样,然后生成自我批评和修正,然后根据修正后的反应微调原始模型。在 RL 阶段,从微调模型中采样,使用一个模型来评估生成的样本,并从这个 AI 偏好数据集训练一个偏好模型。然后使用偏好模型作为奖励信号对 RL 进行训练
- RLAIF


推荐阅读

相关标签

