
热门标签
热门文章
- 1Python编程实例-音频数据可视化_python音频可视化
- 2Python前沿技术:机器学习与人工智能
- 3Java基础总结各个模块重要知识
- 4基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(一)_基于opencv的视频动漫人脸识别
- 5Kafka的优点和缺点,以及适用场景_kafka的优势
- 6OrbbecSDK_ros关于imu数据的发布_orbbec pos sdk
- 7利用Python实现分布式机器学习【框架、方法与实战案例】【文末送书】
- 8Flowable——表单详解_flowable 表单
- 9Python中logging模块_python logging backupcount
- 107.3 爬虫基础
当前位置: article > 正文
亿级流量系统架构之如何设计全链路99.99%高可用架构_亿级流量系统架构设计与实战
作者:秋刀鱼在做梦 | 2024-07-17 10:50:17
赞
踩
亿级流量系统架构设计与实战
我们采用冷热数据分离:
- 冷数据基于HBase+Elasticsearch+纯内存自研的查询引擎,解决了海量历史数据的高性能毫秒级的查询
- 热数据基于缓存集群+MySQL集群做到了当日数据的几十毫秒级别的查询性能。
最终,整套查询架构抗住每秒10万的并发查询请求,都没问题。
本文作为这个架构演进系列的最后一篇文章,我们来聊聊高可用这个话题。所谓的高可用是啥意思呢?
简单来说,就是如此复杂的架构中,任何一个环节都可能会故障,比如MQ集群可能会挂掉、KV集群可能会挂掉、MySQL集群可能会挂掉。那你怎么才能保证说,你这套复杂架构中任何一个环节挂掉了,整套系统可以继续运行?
这就是所谓的全链路99.99%高可用架构,因为我们的平台产品是付费级别的,付费级别,必须要为客户做到最好,可用性是务必要保证的!
我们先来看看目前为止的架构是长啥样子的。
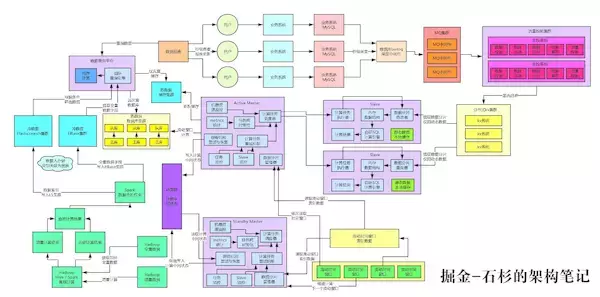
二、MQ集群高可用方案
异步转同步 + 限流算法 + 限制性丢弃流量
MQ集群故障其实是有概率的,而且挺正常的,因为之前就有的大型互联网公司,MQ集群故障之后,导致全平台几个小时都无法交易,严重的会造成几个小时公司就有数千万的损失。我们之前也遇到过MQ集群故障的场景,但是并不是这个系统里。
大家想一下,如果这个链路中,万一MQ集群故障了,会发生什么?
看看右上角那个地方,数据库binlog采集中间件就无法写入数据到MQ集群了啊,然后后面的流控集群也无法消费和存储数据到KV集群了。这套架构将会彻底失效,无法运行。
这个是我们想要的效果吗?那肯定不是的,如果是这样的效果,这个架构的可用性保障也太差了。
因此在这里,我们针对MQ集群的故障,设计的高可用保障方案是:异步转同步 + 限流算法 + 限制性丢弃流量。
简单来说,数据库binlog采集环节一旦发现了MQ集群故障,也就是尝试多次都无法写入数据到MQ集群,此时就
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/秋刀鱼在做梦/article/detail/839522
推荐阅读

相关标签

