
- 1Failed to start docker.service: Unit not found._failed to restart docker.service: unit not found
- 2ARDone SDK 1.8自带 Win32 Demo,使用firmware 1.7.4_error: ‘tv’ undeclared
- 3广州大学机器学习与数据挖掘实验四_python数据挖掘与机器学习课程设计报告
- 4流量劵
- 5探索未来感知:FAST_LIO - 实时 LiDAR-IMU 拟合同步与三维重建
- 6Python程序后台运行的五种方式_python 后台运行
- 7ffmpeg 裁剪视频_ffmpeg裁剪视频
- 8Llama - 量化
- 9SpringCloud Stream消息驱动_spring-cloud-starter-stream-rabbit
- 10python爬虫论文摘要怎么写_毕业论文-基于Python 的网络爬虫.docx
电商数据分析---RFM用户画像_电商的用户画像代码
赞
踩
电商数据分析
一.数据描述
| 订单顺序编号 | 订单号 | 用户名 | 商品编号 | 订单金额 | 付款金额 |
|---|
二.分析角度
1.整体角度----探索每个月有效的订单,以及销售额
2.个人角度----统计第一次购买的数量,以及最新时间购买的人数
3.用户画像----使用RFM模型对用户进行分类
三.数据清洗
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
plt.rcParams['font.family'] = 'Microsoft YaHei'
plt.rcParams['axes.unicode_minus'] = False
- 1
- 2
- 3
- 4
首先设置如上,前两行是让字段整体输出,后两行是使画图显示中文
1.处理缺失值
# 01 空值处理
print(data.isnull().sum())
data['渠道编号'].fillna(data['渠道编号'].mode(), inplace=True)
print("----------------------")
- 1
- 2
- 3
- 4
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4JM0PXUS-1686745656368)(C:\Users\86170\AppData\Roaming\Typora\typora-user-images\image-20230614175754731.png)]](https://img-blog.csdnimg.cn/a7f29bcac76548ffb1481df2e18d2eab.png)
空值字段只有渠道的编号,数量较少,可以采用删除,本次采用使用众数填充的方法处理空值。
2.重复值
# 02 重复值处理
print("数据的重复值个数为", data.duplicated().sum())
- 1
- 2

无重复值。
3.异常值
本次数据主要是2021年的数据,对于其他时间段的数据进行删除,并且检查付款金额字段数据
print("数据异常值数据\n", data[data['付款金额'] < 0]['付款金额'])
data.drop(data[data['付款金额'] < 0]['付款金额'].index, inplace=True)
# 增加下日期列与月份
data['订单日期'] = pd.to_datetime(data['付款时间'], format='%Y-%m-%d').dt.date
data['月份'] = pd.to_datetime(data['订单日期']).dt.strftime('%m')
# 筛选2021年其他的数据
df = data[pd.to_datetime(data['订单日期']).dt.year == 2021]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
增加订单日期列以及月份列,便于后续分析
四.整体分析
1.退款率
data_counts = data.groupby('是否退款').count()['订单号']
plt.pie(data_counts, labels=data_counts.index, autopct='%1.1f%%')
plt.title('退款订单占比')
- 1
- 2
- 3

整体的退款率在13%左右,高于平均水平的退款率可能表明产品质量、履行流程或客户服务存在某些问题。低于平均水平的退款率可能表明该企业提供了优质且令人满意的产品和服务,但也可能意味着该企业未正确处理退款并可能导致客户不满。
2.月份销售额分析
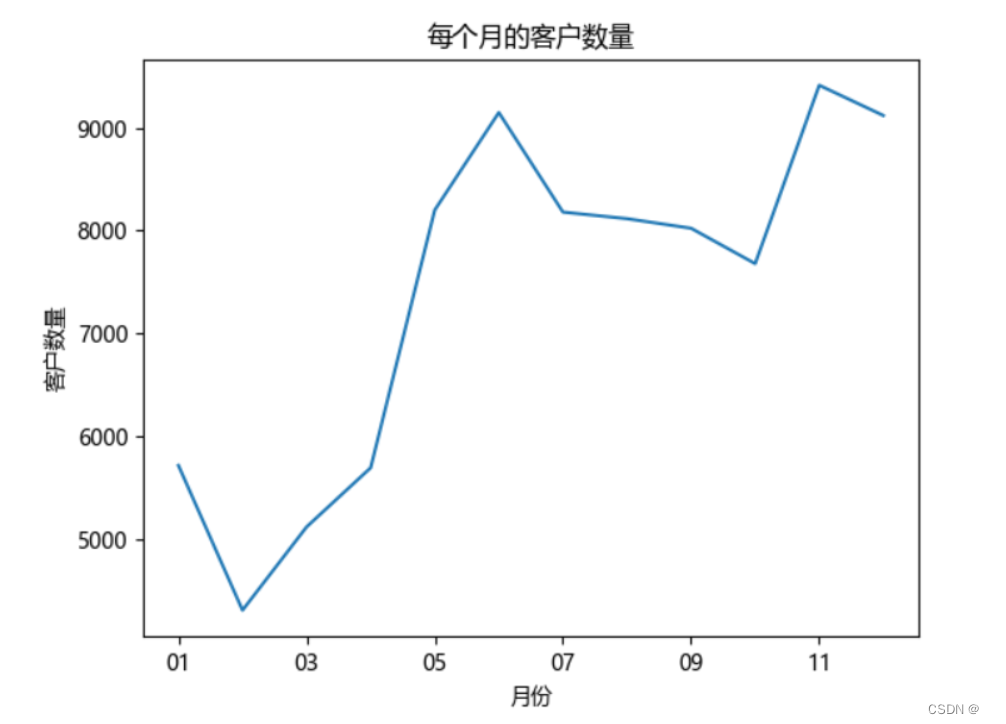
# 每个月的产品销量 data_s.groupby('月份')['订单号'].count().plot() plt.xlabel('月份') plt.ylabel('销量') plt.title("每个月的产品销量") plt.show() # 每个月的销售额 data_s.groupby('月份')['付款金额'].sum().plot() plt.xlabel('月份') plt.ylabel('销售额') plt.title("每个月的销售额") plt.show() # 每个月的消费人数 data_s.groupby(by='月份')['用户名'].apply(lambda x: len(x.drop_duplicates())).plot() plt.xlabel('月份') plt.ylabel('客户数量') plt.title('每个月的客户数量') plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
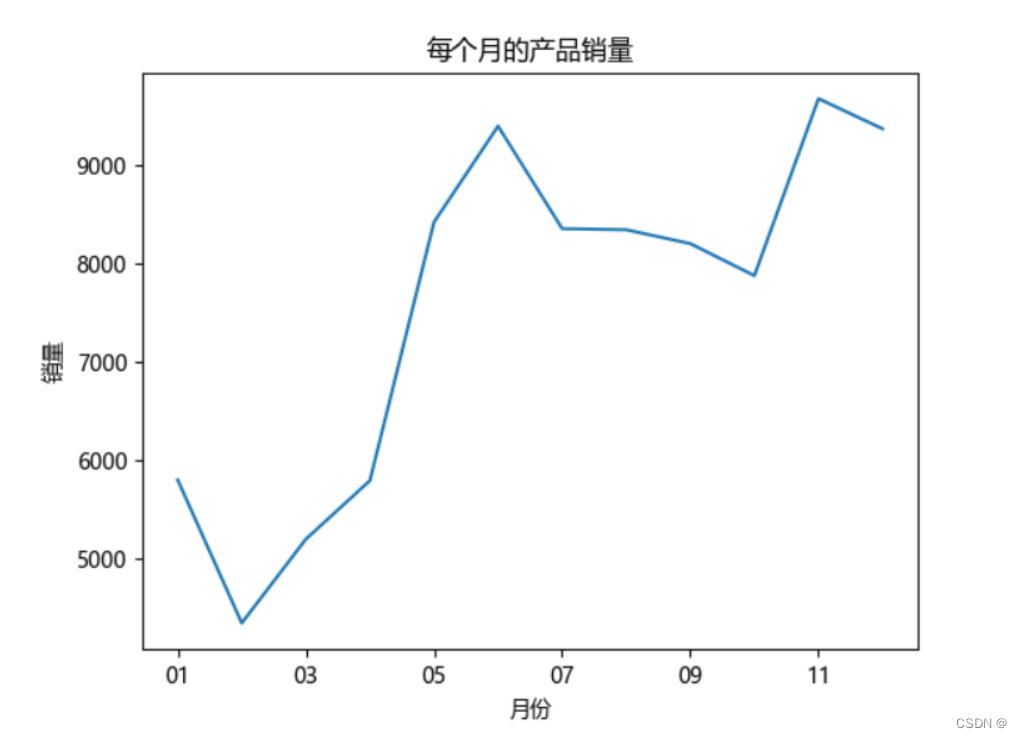
在2021年2月的销量最低,2月降到最低开始增加,其中5月到6月期间增长最快。

与销量成正比,趋势与销量一致
# 用直方图和核密度看下‘订单金额’的数据分布
plt.figure(figsize=(8, 4), dpi=200)
plt.hist(data_s['订单金额'], bins=50,
color='g', label='订单金额',
histtype='bar', density=True,
edgecolor='white', alpha=0.4)
plt.title('订单金额分布', fontdict={'fontsize': 6, 'color': 'r'})
plt.xlabel('订单金额')
plt.ylabel('密度')
plt.show()
print(f"订单金额的数据偏度为{data_s['订单金额'].skew()}")
print(f"订单金额的数据偏度为{data_s['订单金额'].kurtosis()}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
订单金额的整体分布
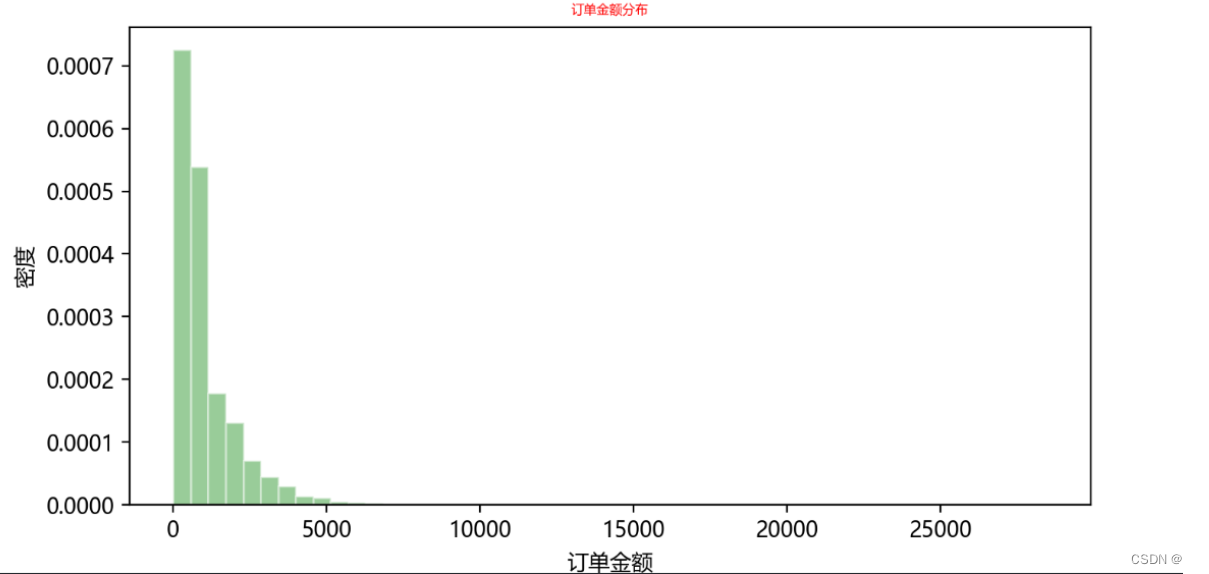

订单金额数据属于右偏分布。
3.渠道平台分析
data_counts=data_s.groupby('渠道编号')['订单金额'].sum()
plt.pie(data_counts, labels=data_counts.index, autopct='%1.1f%%')
plt.title('渠道金额占比')
plt.show()
data_counts=data_s.groupby('平台类型')['订单金额'].sum()
plt.pie(data_counts, labels=data_counts.index, autopct='%1.1f%%')
plt.title('平台金额占比')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

从图中看出,大部分的销售金额来自于APP以及微信公众号,以后可以在这两个方面悬窗加大投入。
五.个人角度
1.人数分析
data_s.groupby('用户名')['订单日期'].min().value_counts().plot()
plt.xlabel("订单日期")
plt.ylabel("人数")
plt.title('第一次购买用户分析')
plt.show()
data_s.groupby('用户名')['订单日期'].max().value_counts().plot()
plt.xlabel("订单日期")
plt.ylabel("人数")
plt.title('最新次购买用户分析')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11


从图中看出1月到6月新用户数量在不断的增长,后半年趋于稳定,在复购率上面,全年在不断的增加。
六.用户画像
RFM是一种营销分析工具,它的全称是“Recency(最近购买时间)、Frequency(购买频率)、Monetary(单次购买金额)”,即最近购买时间、购买频率和单次购买金额。这三个指标被广泛用于客户价值分析和客户细分,可以帮助企业更好地了解自己的客户和他们的需求,以便更好地制定营销策略和提高客户满意度。通过RFM分析,企业可以识别出自己的高价值客户、潜在客户和低价值客户,并针对不同客户制定不同的营销策略。
data_end_date = pd.Timestamp('2022-01-01').date() rfm = data_s.groupby('用户名').agg({ '订单日期': lambda x: (data_end_date - x.max()).days, '订单号': 'count', '付款金额': 'sum' }) rfm.rename(columns={'订单号': 'F', '订单日期': 'R', '付款金额': 'M'}, inplace=True) # 定义RFM指标 使用平均值 R_score = round(rfm['R'].mean(), 2) F_sore = round(rfm['F'].mean(), 2) M_sore = round(rfm['M'].mean(), 2) rule_dict = { (True, True, True): '重要价值客户', (True, False, True): '重要发展客户', (True, True, False): '重要保持客户', (True, False, False): '重要挽留客户', (False, True, True): '一般价值客户', (False, False, True): '一般发展客户', (False, True, False): '一般保持客户', (False, False, False): '一般挽留客户' } rfm['客户分类'] = [rule_dict[(r > R_score, f > F_sore, m > M_sore)] for r, f, m in zip(rfm['R'], rfm['F'], rfm['M'])] return rfm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
计算RFM三个指标的值,我们定义data_end_date,计算数据集中的订单日期到data_end_date的时间差作为R指标
F为频数,M为消费金额,部份数据如下:


可以看出对于该店铺的重要价值客户相对较少,应该制定相应的策略提高客户忠诚度。

