
- 1Stable Diffusion WebUI API http://127.0.0.1:7860/docs空白_stable diffusion127.0.0.1
- 2Web前端设计基础测试_javascript功能强大,主要表现在
- 3uni-app 使用 tailwindcss_uniapp tailwindcss
- 4shiro1.2.4升级报错 org/owasp/encoder/Encode或者是org.owasp.encoder.Encode
- 5AI 预测蛋白质结构「GitHub 热点速览 v.21.29」
- 6如何解决移动硬盘在mac上只读不写 macbook无法显示移动硬盘_macbook插入移动硬盘是只读怎么拷贝出去
- 7[C/C++]函数重载,三连问,你会吗?_previously defined here
- 8【CNN】LeNet——卷积神经网络的开山鼻祖_最初的卷积神经网络模型
- 9MySql优化——索引优化与查询优化(2) 关联查询优化_mysql 连表查询数量优化
- 10Go 之 工具库 samber/lo_go 类似 lodash的
ChatGLM论文解读
赞
踩
GLM
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
论文地址
1. 背景介绍
1)主流预训练框架
| 模型 | 介绍 | 结构特点 | 训练目标 |
|---|---|---|---|
| autoregressive | 自回归模型,代表GPT,本质上是一个从左到右的语言模型,常用于无条件生成任务(unconditional generation) | 单向,无法利用到下文的信息 | 从左到右的文本生成 |
| autoencoding | 通过某个降噪目标(如掩码语言模型)训练的语言编码器,如BERT、ALBERT、DeBERTa。擅长自然语言理解任务(natural language understanding tasks),常被用来生成句子的上下文表示。 | 双向,可以同时感知上文和下文,因此在自然语言理解任务上表现很好,但是不适合生成任务 | 对文本进行随机掩码,然后预测被掩码的词 |
| encoder-decoder | 完整的Transformer结构,包含一个编码器和一个解码器,以T5、BART为代表,常用于有条件的生成任务 (conditional generation) | 器中注意力是双向,解码器中是单向的,因此可同时应用于自然语言理解任务和生成任务。但T5为了达到和RoBERTa相似的性能,往往需要更多的参数量 | 接收一段文本,从左到右的生成另一段文本 |
2)GLM目标
通用语言模型,基于自回归空白填充的预训练框架,结合了自编码和自回归预训练的优点,能够在自然语言理解、有条件生成和无条件生成任务中取得显著的性能提升。
主要的设计点在span shuffling 和 2D positional encoding。并将 NLU 任务重构为模仿人类语言的完型填空题。通过改变缺失跨度的数量和长度,自回归空白填充目标可以为有条件和无条件生成任务预训练语言模型。
2.GLM设计
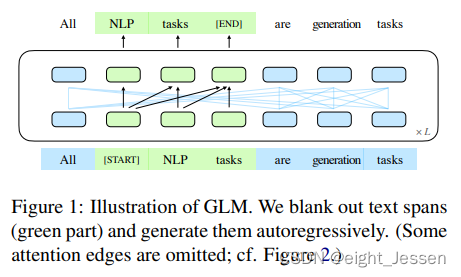
1)训练目标
自回归空白填空
对于给定的文本输入
x
=
[
x
1
,
x
2
,
.
.
.
,
x
]
n
x=[x_1, x_2,...,x]_n
x=[x1,x2,...,x]n ,采样span
{
s
1
,
s
2
,
.
.
.
,
s
m
}
\{s_1, s_2, ...,s_m\}
{s1,s2,...,sm} ,每个span
s
i
s_i
si对应一系列连续的token
{
s
i
,
1
,
.
.
.
,
s
i
,
l
i
}
\{s_{i,1},...,s_{i,l_i}\}
{si,1,...,si,li}。将每个span替换成,形成新的损坏文本
x
c
o
r
r
u
p
t
x_{corrupt}
xcorrupt,模型通过自回归的方式预测空白格。为了完全捕捉不同span之间的相互依赖性,随机排列span的顺序,类似于permutation language model[8]。
Z
m
Z_m
Zm表示长度为m的索引句子的所有可能扰乱集合,
s
z
<
i
s_{z<i}
sz<i表示
[
s
z
1
,
.
.
.
,
s
z
<
i
]
[s_{z_1}, ..., s_{z<i}]
[sz1,...,sz<i]
训练目标就是:
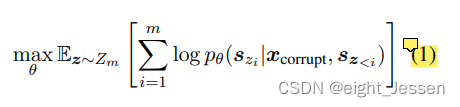
对于每个span,从左到右生成单词
s
i
s_i
si,span 分解为:

2) Mask构造
- 对于一个输入的文本 x x x,将其划分成两部分,一部分就是损坏文本 x c o r r u p t x_{corrupt} xcorrupt,记为Part A;另一部分就是mask起来的span组成,并且回进行扰乱。记为Part B。
- Part A的token可以跟同Part里面相互关联,但是不能跟PartB关联,Part B的token可以关联的和Part B前面的内容,但不能关联Part B任何后续的token。Part B里面每个span都以[S]作为输入,并附加[E]作为输出
- 2D位置编码,每个token有两个位置编码
- 第一个是表示在损坏句子中的位置,对于被掩盖的跨度,它是相应 [MASK] 标记的位置。
- 第二个位置编码表示跨度内的位置。对于Part A 中的token,它们的第二个位置 id 为 0。对于Part B 中的token,它们的范围从 1 到span的长度。
- 通过可学习的嵌入表将两个位置 id 投影到两个向量上,这两个向量都添加到输入标记嵌入中。
- 优点是模型对Mask里单词的长度不敏感。
- 这种方式下,Part A就是双向的encoder,Part B就是单向的decoder
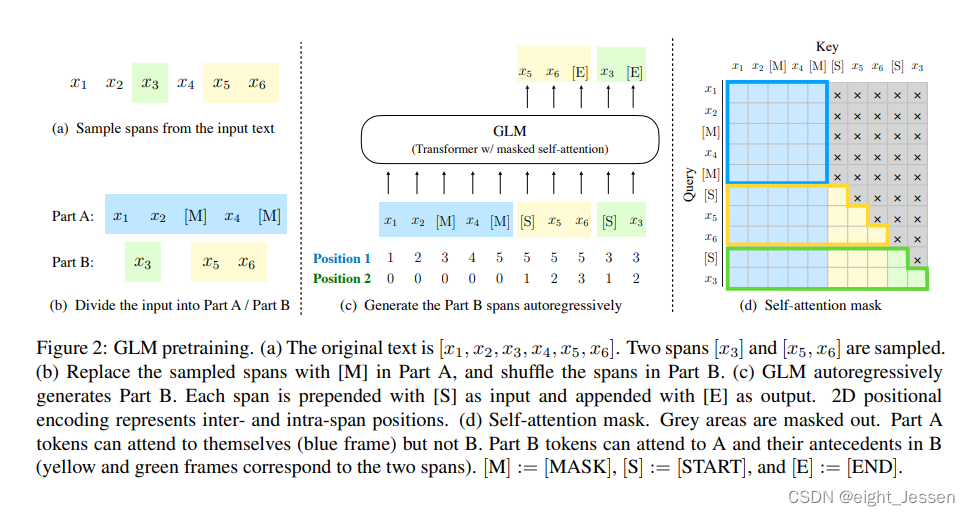
3) 模型结构
使用transformer的编码器,并做了一些改进:
- 修改LN和ResNet顺序,可以避免数值错误
- 对于token的预测输出用的是单个的线性层
- 将激活函数由ReLU改为GeLUs
4) 微调GLM适应NLU任务
分类任务

给定一个标注样本
(
x
,
y
)
(x,y)
(x,y),我们将输入文本
x
x
x通过模板转化为有一个[MASK]字符填空问题。标签
y
y
y也映射到了填空问题的答案
v
(
y
)
v(y)
v(y) 。模型预测不同答案的概率对应了预测不同类别的概率。
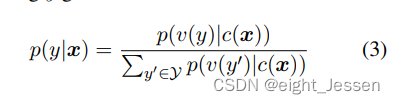
文本生成
针对文本生成任务,直接将GLM作为一个自回归模型的应用。比如: 给定的上下文构成输入的Part A,在结尾附上一个[MASK]字符,模型用自回归的方式去生成Part B的内容。
3 模型对比
| Bert | XLNet | T5 | UniLM |
|---|---|---|---|
| Bert不能很好地捕捉masked tokend之间的依赖。不能很好处理连续的多个token。测试时需要枚举可能的长度。 | 基于自回归目标训练。但是需要知道预测token的长度。在测试阶段需要枚举结果的长度。使用双流注意力机制解决了信息泄漏的问题,改变了transfomer的结构,增加了耗时; | encoder-decoder Transformer结构。在编码和解码阶段使用不同的位置编码,使用sentinel tokens来识别不同的mask跨度,造成模型能力的浪费和预训练微调的不一致。GLM使用单个的transformer编码器学习单向和双向的注意力,参数少。 | 自编码框架下通过改变双向、单向、cross-attention的 mask来实现统一预训练目标;由于总是用[MASK]标记替换masked span,对masked span和上下文依赖的建模能力不足。对于微调下游任务来说,自编码会比自回归更加低效。 |

