
- 1秒杀圣经:10Wqps高并发秒杀,16大架构杀招,帮你秒变架构师_高并发10万
- 2Flutter第十弹 ScrollView滚动组件
- 3java微信小程序调用微信支付apiv3接口(最简洁代码)
- 4docker的安全配置_docker 安全组
- 5nodejs新版本引起的:digital envelope routines::unsupported_build digital envelope routines
- 6Java知识点整理 1 — 基础与集合_java基础八股文复习
- 7基础知识篇:大语言模型核心原理解析_大语言模型技术原理
- 8如何才能让大模型处理更长的文本数据?_如何让大模型处理更长的文本?
- 9Docker定制镜像(Dockerfile)_docker build指定dockerfile
- 10GraphRAG+Ollama 本地部署,保姆教程,踩坑无数,闭坑大法_graphrag本地部署
一文速览Llama 3.1——对其92页paper的全面细致解读:涵盖语言、视觉、语音的架构、原理_llama3.1论文
赞
踩
前言
按我原本的计划,我是依次写这些文章:解读mamba2、解读open-television、我司7方面review微调gemma2,再接下来是TTT、nature审稿微调、序列并行、Flash Attention3..
然TTT还没写完,7.23日,Meta突然发布了llama3.1..
其实,llama3 刚出来时,其长度只有8K对于包括我司在内的大模型开发者是个小小的缺憾,而此次Meta发布llama3.1的意义在于
- 很明显,随着llama的影响力越来越大,Meta想让llama类似Linux一样,成为开发者的行业标准(毕竟,正如Zuckerberg所说,Linux 已成为云计算和运行大多数移动设备的操作系统的行业标准基础)
- 长度终于达到了128K,这个长度使得可以直接通过我司的paper-review数据集去微调了
如此,便有了本文:解读下llama3.1的paper (结果一看92页,好在昨天我司上线了基于大模型的翻译系统,那先翻译一下 快速看下大概 然后慢慢抠,顺带说一句,其实正文就70页,但致谢和参考文献占了不少篇幅),且会尽可能全面细致,毕竟绝大多数的文章只会阐述本文第一部分的内容,一般都不会涉及本文第二部分、第三部分所分别对应的其视觉、语音的架构与原理
更多,见我司官网首页的「大模型项目开发线上营 第二期」
第一部分 Meta推出llama3.1:8B和70B版本都均超越同等尺寸的其他开源模型
7月23日,Meta推出了llama3.1,其405B的版本可以与GPT4正面干(可能是目前唯一一个可以与GPT4全方位分庭抗礼的开源模型),而其8B和70B版本都均超越同等尺寸的其他开源模型

1.1 模型架构、指令微调
1.1.1 模型架构:仅解码器的transformer、直接偏好优化、GQA
为了更好的理解llama3.1,我们先来回顾下我之前介绍过的llama3(来自此文一文速览Llama 3:从Llama 3的模型架构到如何把长度扩展到100万的第一部分)
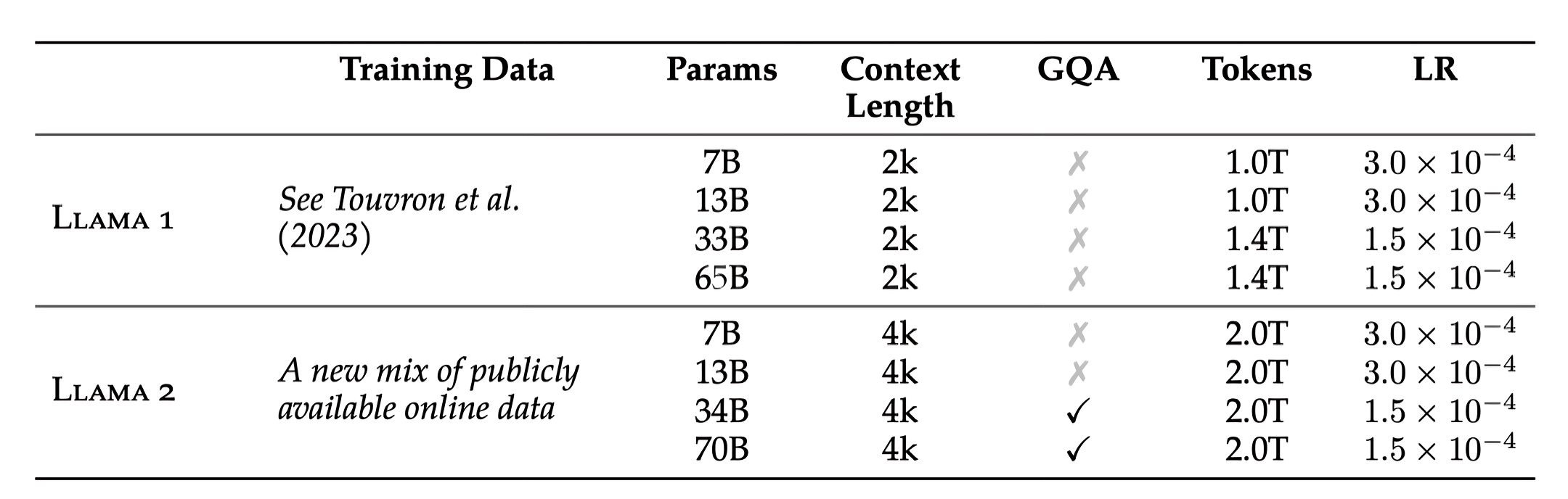
和Llama 2一样,Llama 3 继续采用相对标准的decoder-only transformer架构,但做了如下几个关键的改进
- Llama 3 使用具有 128K tokens的tokenizer
相当于,一方面,分词器由 SentencePiece 换为了 Tiktoken,与 GPT4 保持一致,可以更有效地对语言进行编码
二方面,Token词表从LLAMA 2的32K拓展到了128K
基准测试显示,Tiktoken提高了token效率,与 Llama 2 相比,生成的token最多减少了 15%「正由于llama3具有更大的词表,比llama2的tokenizer具有更大的文本压缩率,所以你会看到在此文《从提升大模型数据质量的三大要素(含审稿GPT第4.6版、第4.8版、第5版)到Reviewer2的实现》中,我司七月审稿项目组发现,在统计同样的paper-review数据集时,llama3统计到的token数更少」- 为了提高推理效率,Llama 3在 8B 和 70B 都采用了分组查询注意力(GQA),根据相关实验可以观察到,尽管与 Llama 2 7B 相比,模型的参数多了 1B,但改进的分词器效率和 GQA 有助于保持与 Llama 2 7B 相同的推理效率
值得指出的是,上一个版本的llama 2的34B和70B才用到了GQA「详见LLaMA的解读与其微调(含LLaMA 2):Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙的第3.2节LLaMA2之分组查询注意力——Grouped-Query Attention」
- 在 8,192 个token的序列上训练模型,且通过掩码操作以确保自注意力不会跨越文档边界
本次的llama3.1 无论哪个尺寸,都和llama3一样,都选择的标准的仅解码器的Transformer模型架构,并进行了细微的改动,而不是混合专家模型

此外

- 在词汇表上
与llama3一样,使用了一个包含128K token的词汇表,这个token词汇表结合了来自 tiktoken tokenizer的100K token和28K额外token(Our token vocabulary combines 100K tokens from the tiktoken tokenizer with 28K additional tokens),以更好地支持非英语语言
与Llama 2 tokenizer相比,llama3或3.1的新tokenizer在一组英语数据上的压缩率从每个token的3.17个字符提高到3.94个字符(Compared to the Llama 2 tokenizer, our new tokenizer improves compression rates on a sample of English data from 3.17 to 3.94 characters per token),这使得模型能够在相同的训练计算量下“读取”更多文本
且使用一种注意力掩码,以防止在同一序列内不同文档之间的自注意力 - 在注意力机制上:使用GQA
与llama3一样,也使用了GQA,且是32个注意力头(相当于32个query头)、8个键值头(8个key/value头,意味着query头数是key/value头的4倍,与下图中间部分所示的query头数是key/value头数的2倍,不一样)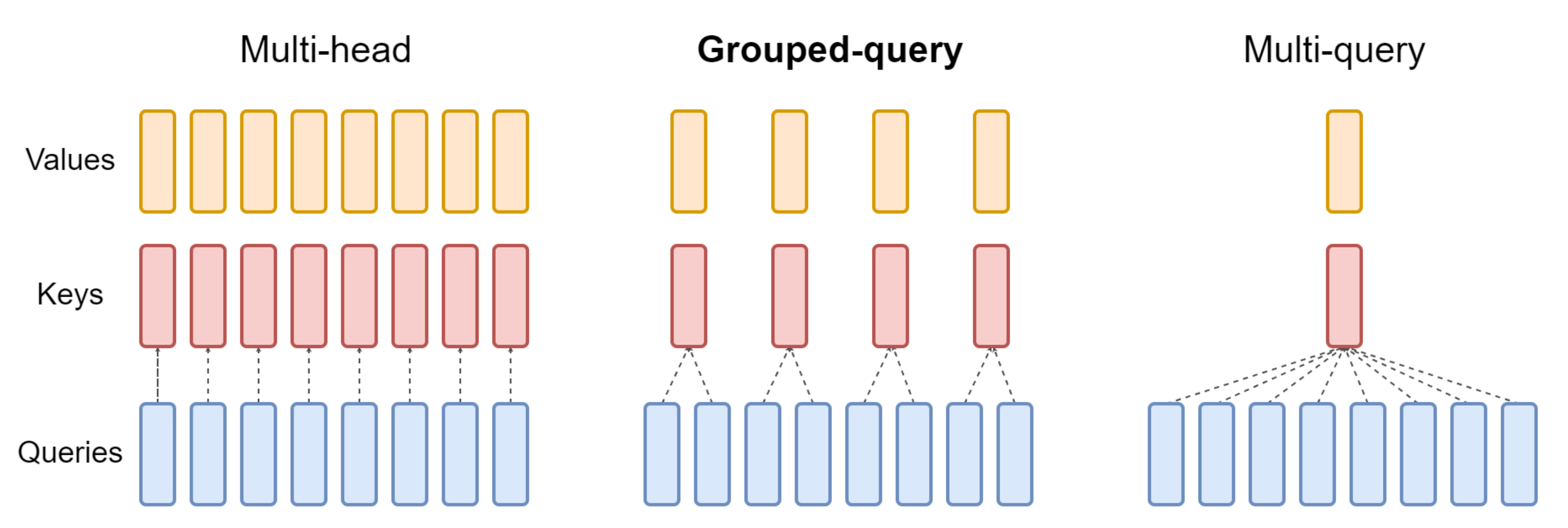
- 在模型长度上:从最初的8K上下文窗口开始,最终达到128K上下文窗口
与llama2相比,将RoPE基频超参数提高到500,000,这使得llama3.1能够更好地支持更长的上下文「Xiong等人(2023)表明这个值对于上下文长度达到32,768是有效的」
这点其实就是我之前在这篇文章《一文速览Llama 3:从Llama 3的模型架构到如何把长度扩展到100万》第二部分的所介绍过的
至于别的层面,则沿用Llama一代以来的惯用结构:比如RMSNorm、SwiGLU、RoPE、Pre-Norm(关于这些细节,详见此文:LLaMA的解读与其微调(含LLaMA 2):Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙),对此,张俊林老师还特意画了一个图以示说明

而对于Llama 3 405B 使用了一个具有 126 层、16,384 的token表示维度和 128 个注意力头的架构,且他们为了支持 405B 规模模型的大规模生产推理,将模型从 16 位 (BF16) 量化为 8 位 (FP8) 数字,且在多达16K的H100 GPU上进行训练
1.1.2 模型能到128K长度的关键
在预训练的最后阶段,Meta对长序列进行训练,以支持最长可达128K token的上下文窗口
一开始不对长序列进行训练,因为自注意力层中的计算量随着序列长度的平方增长。 后面逐步增加支持的上下文长度,进行预训练,直到模型成功适应增加的上下文长度
且通过测量以下两个方面来评估成功适应:
- 模型在短上下文评估上的表现是否完全恢复
- 模型是否能够完美解决“干草堆中的针”任务,直到该长度
在Llama 3 405B的预训练中,通过六个阶段逐步增加上下文长度,从最初的8K上下文窗口开始,最终达到128K上下文窗口,在这整个长上下文预训练阶段中,总计使用了大约800B的训练token
1.2 指令和chat微调:先奖励建模,然后SFT,最后DPO
在后期训练中,通过在预训练模型的基础上进行几轮对齐来生成最终的聊天模型。每轮都涉及监督微调 (SFT)、拒绝抽样 (RS) 和直接偏好优化DPO(DPO详见:RLHF的替代之DPO原理解析:从RLHF、Claude的RAILF到DPO、Zephyr)
- 比如首先在预训练检查点的基础上使用人类标注的偏好数据训练奖励模型
- 然后,我们通过监督微调SFT对预训练检查点进行微调,并进一步通过直接偏好优化DPO对检查点进行对齐,如下图所示

1.2.1 奖励模型的训练:基于人类标准打出不同评分的数据
首先,在预训练检查点的基础上训练一个涵盖不同能力的奖励模型RM,训练目标与Llama 2相同,只是去掉了损失中的边际项,因为观察到在数据扩展后的改进效果逐渐减弱(We train a reward model (RM) covering different capabilities on top of the pre-trained checkpoint. The training objective is the same as Llama 2 except that we remove the margin term in the loss, as we observe diminishing improvements after data scaling)
- 与Llama 2一样,在过滤掉具有相似响应的样本后,使用所有的偏好数据进行奖励建模,比如为每个prompt从两个不同的模型中抽样两个response(比如一个能力强点的、一个能力相对弱点的,分别回答同一个prompt)
且要求注释者通过将其偏好强度分类为4个级别之一来进行评分,基于他们对所选response与被拒绝response的偏好程度:显著更好、更好、稍微更好或勉强更好 - 此外,除了标准的偏好对(选择的,拒绝的)response外,注释还为某些prompt创建了第三个“edited response”,其中对来自对的选择response进行了进一步编辑以进行改进——即直接编辑所选response或通过反馈提示模型进一步改进其自身response「Following Llama 2, we use all of our preference data for reward modeling after filtering out samples with similar responses. In addition to standard preference pair of (chosen,rejected) response, annotations also create a third “edited response” for some prompts, where the chosen response from the pair is further edited for improvement」
因此,每个偏好排名样本都有两个或三个response,具有明确的排名(edited > chosen > rejected)
在训练过程中,我们将prompt和多个response连接成一行,并随机打乱response
Hence, each preference rankingsample has two or three responses with clear ranking (edited > chosen > rejected). We concatenate the prompt and multiple responses into a single row during training with responses randomly shuffled
这是一种近似于将responses放在单独行中并计算分数的标准场景,但在我们的消融实验中,这种方法提高了训练效率而没有损失准确性
This is an approximation to the standard scenario of putting the responses in separate rows and computing the scores, but in our ablations, this approach improves training efficiency without a loss in accuracy
下表则统计了用于训练奖励模型的偏好数据

1.2.2 通过奖励模型做拒绝采样得到的数据 + 合成数据:做监督微调SFT
有了奖励模型,便可以评价一个<prompt、response>的质量了,比如可以使用奖励模型对人类注释prompt进行拒绝采样(Rejection Sampling)
具体而言,对于一个人工prompt,让模型生成若干个回答,然后采样其中的K个response(通常在 10 到 30 之间),然后让RM针对这多个response逐一进行质量上的打分,最终把得分最高的response保留下来(作为之后SFT数据的一部分,此举也符合 Bai 等人2022的研究),其它的则丢弃
- 在后期的后训练阶段,引入系统提示,以引导RS的响应符合期望的语气、风格或格式,这可能因不同的能力而异
- 为了提高拒绝采样的效率,采用了PagedAttention(Kwon等,2023)
PagedAttention通过动态的键值缓存分配增强了内存效率,它通过根据当前缓存容量动态调度请求来支持任意输出长度
不幸的是,当内存不足时,这会带来换出风险。 为了消除这种换出开销,定义了一个最大输出长度,并且只有在有足够内存容纳该长度的输出时才执行请求。 PagedAttention还使我们能够在所有相应的输出中共享prompt的键值缓存页
总的来说,这在拒绝采样期间导致了超过 2×的吞吐量提升
接下来
- 这部分通过拒绝采样得到的高质量的数据(来自人类注释收集的prompt,且带有拒绝采样的response),再加上针对特定能力的合成数据——比如用于专门增强模型代码、数学、逻辑能力的数据,以及少量人工策划的数据合到一块
- 最后,使用标准的交叉熵损失对预训练语言模型进行SFT(SFT;Wei等,2022a;Sanh等,2022;Wang等,2022b),目标token上计算损失(同时对prompt token进行掩蔽损失)
尽管许多训练目标是模型生成的,且最大的模型在8.5K到9K步的过程中以1e-5的学习率进行微调。同时发现这些超参数设置在不同的轮次和数据混合中表现良好
举个数据合成的例子,为了涵盖更广泛的编程语言,比如为了丰富SFT数据集中PHP代码的数量,可以通过llama 3把数据集中已有的Python代码翻译成PHP代码
最终,如下图所示,便是用于 Llama 3 对齐的内部收集的 SFT 数据。 每个 SFT 示例由一个上下文(即除最后一轮外的所有对话轮次)和一个最终response组成


1.2.3 直接偏好优化DPO
Meta进一步使用直接偏好优化DPO 对得到的SFT模型进行训练「DPO本质上是个二分类,就是从人工标注的<Prompt,Good Response,Bad Response>三元数据里学习,调整模型参数鼓励模型输出Good Response,不输出Bad Response」,以实现人类偏好的对齐
在具体训练中,主要使用最近批次的偏好数据,这些数据是使用前几轮对齐中表现最好的模型收集的。 因此,这样的训练数据更符合每轮优化中策略模型的分布
此外,它们还探索了诸如PPO(Schulman等,2017)等在线算法,但发现DPO在大规模模型上所需的计算量更少,并且表现更好,特别是在像IFEval(Zhou等,2023)这样的指令跟随基准上
对于Llama 3,我们使用的学习率为1e-5,并将 βhyper-parameter设置为0.1。此外,对DPO应用了以下算法修改:
- 在DPO损失中屏蔽格式化token
从选择的和拒绝的response中屏蔽特殊格式化token,包括标题和终止token,以稳定DPO训练
Masking out formatting tokens in DPO loss: We mask out special formatting tokens including header and termination tokens (described in Section 4.1.1) from both chosen and rejected responses in the loss to stabilize DPO training
因为他们观察到,这些token对损失的贡献可能导致模型行为不理想,例如尾部重复或突然生成终止token(We observe that having these tokens contribute to the loss may lead to undesired model behaviors such as tail repetition or abruptly generating termination tokens)
假设这是由于DPO损失的对比性质——在选择的和拒绝的response中存在共同token导致学习目标冲突,因为模型需要同时增加和减少这些token的可能性
We hypothesize that this is due to the contrastive nature of the DPO loss – the presence of common tokens in both chosen and rejected responses leads to a conflicting learning objective as the model needs to increase and reduce the likelihood of these tokens simultaneou - 使用NLL损失进行正则化
在选择的序列上添加了一个额外的负对数似然(NLL)损失项,缩放系数为 0.2,类似于Pang等人(2024)
这有助于通过保持生成的期望格式并防止选择response的对数概率下降——来进一步稳定DPO训练(Pang等人,2024;Pal等人,2024)
1.3 模型并行
1.3.1 4D并行
为了扩展最大模型的训练,Meta使用4D并行性——四种不同类型的并行方法的组合——来分割模型「这种方法有效地将计算分配到多个GPU上,并确保每个GPU的模型参数、优化器状态、梯度和激活能够适应其高带宽内存(HBM)」
其对4D并行性的实现如下图所示

GPU按[TP, CP, PP, DP]的顺序划分为并行组,其中DP代表FSDP
- 16个GPU配置为组大小|TP|=2,|CP|=2,|PP|=2,|DP|=2
GPU在四维并行中的位置表示为一个向量,[D1, D2, D3, D4],其中是第
个并行维度的索引
- GPU0[TP0, CP0, PP0, DP0] 和 GPU1[TP1, CP0, PP0, DP0] 在同一个TP组中
GPU0和GPU2在同一个CP组中
GPU0和GPU4在同一个PP组中
GPU0和GPU8在同一个DP组中
1.3.2 4D并行对张量并行、流水线并行、上下文并行、数据并行的综合
它结合了
- 张量并行性(TP;Krizhevsky等,2012;Shoeybi等,2019;Korthikanti等,2023)
将单个权重张量拆分为多个块,分布在不同的设备上
- 流水线并行性(PP;Huang等,2019;Narayanan等,2021;Lamy-Poirier,2023)
通过层将模型垂直划分为多个阶段,以便不同的设备可以并行处理完整模型流水线的不同阶段
- 上下文并行性(CP;Liu等,2023a)
将输入上下文划分为多个段,从而减少非常长序列长度输入的内存瓶颈 - 以及数据并行性(DP;Rajbhandari等,2020;Ren等,2021;Zhao等,2023b)
使用完全分片数据并行性(FSDP;Rajbhandari等,2020;Ren等,2021;Zhao等,2023b),它在实现数据并行性的同时对模型、优化器和梯度进行分片,能够在多个GPU上并行处理数据,并在每个训练步骤后进行同步
更多细节,请参见:大模型并行训练指南:通俗理解Megatron-DeepSpeed之模型并行与数据并行
第二部分 带有视觉能力的llama3:在图像和视频数据上的训练
据llama3.1 paper第54页所示,他们还进行了一系列实验,通过一个由两个主要阶段组成的组合方法,将视觉识别能力融入Llama 3(不过,论文中说这个多模态的llama3 还在开发中,后面才会发布,所以本文更多侧重对其架构、原理的讲解)
首先,通过在大量图像-文本对上引入和训练一组交叉注意力层,将预训练的图像编码器(Xu等,2023)和预训练的语言模型组合起来(Alayrac等,2022)
这导致了下图所示的模型(涉及五个阶段的训练:1 语言模型预训练,2 多模态编码器预训练,3 视觉适配器训练,4 模型微调,5 语音适配器训练)

其次,引入了时间聚合层和额外的视频交叉注意力层,这些层在大量的视频-文本对上运行,以学习模型识别和处理视频中的时间信息
基础模型开发的组合方法有几个优点:
- 它使我们能够并行开发视觉和语言建模能力
- 它避免了视觉和语言数据联合预训练的复杂性,这些复杂性源于视觉数据的tokenization、来自不同模态的token的背景困惑度差异以及模态之间的争用
- 它保证了文本任务的模型性能不受视觉识别能力引入的影响
- 交叉注意力架构确保我们不必在推理过程中将全分辨率图像通过越来越多的LLM骨干(特别是每个transformer层中的前馈网络),从而提高了效率
2.1 图像与视频数据
2.1.1 图像训练数据
图像编码器和适配器是在图像-文本对上训练的,通过一个复杂的数据处理管道构建这个数据集,该管道包括四个主要阶段:
- 质量过滤
过程中,实施了质量过滤器,通过启发式方法(如由Radford et al., 2021生成的低对齐分数)去除非英语字幕和低质量字幕,比如移除所有低于某个CLIP评分的图像-文本对 - 感知去重
对大规模训练数据集进行去重有利于模型性能,因为可以减少在冗余数据上花费的训练计算量(Esser等,2024;Lee等,2021;Abbas等,2023) 和记忆化(Carlini等,2023;Somepalli等,2023)
因此,出于效率和隐私原因对训练数据进行去重。为此,使用内部版本的最先进的SSCD复制检测模型(Pizzi等,2022)来大规模去重图像
对于所有图像,首先使用SSCD模型计算一个512维的表示,使用这些嵌入来对数据集中所有图像执行最近邻(NN)搜索,使用余弦相似度度量。将高于某个相似度阈值的示例定义为
重复项
接着,使用连通分量算法对这些重复项进行分组,并且每个连通分量仅保留一个图像-文本对。
过程中,通过以下方式提高去重管道的效率:(1)使用k-means聚类对数据进行预聚类,(2)使用FAISS(Johnson等,2019)进行NN搜索和聚类 - 重采样
我们通过类似于Xu等人(2023);Mahajan等人(2018);Mikolov等人(2013)的重采样方
法确保图像-文本对的多样性
首先,通过解析高质量的文本来源构建一个n-gram词汇表
接下来,计算数据集中每个词汇n-gram的频率
然后我们按如下方式重采样数据:如果标题中的任何n-gram在词汇表中出现的次数少于 T次,我们保留相应的图像-文本对
否则,以概率独立采样标题中的每个n-gram:
,其中
表示n-gram
如果任何n-gram被采样,保留图像-文本对(we keep the image-text pair if any of the n-grams was sampled)
这种重采样有助于提高在低频类别和细粒度识别任务中的表现 - 光学字符识别
通过提取图像中写入的文本并将其与标题连接来进一步改进我们的图像-文本数据。 书写文本是使用专有的光学字符识别(OCR)管道提取的
他们观察到,将OCR数据添加到训练数据中极大地改善了需要OCR能力的任务,例如文档理解
2.1.3 视频数据
对于视频预训练,使用了一个大型的视频-文本对数据集,且通过多阶段过程来策划我们的数据集
- 使用基于规则的启发式方法过滤和清理相关文本,例如确保最小长度和修正大小写
- 然后,运行语言识别模型以过滤掉非英语文本
运行OCR检测模型以过滤掉带有过多叠加文本的视频 - 为了确保视频-文本对之间的合理对齐,使用CLIP(Radford等,2021,至于CLIP的详细介绍,详见此文:AI绘画原理解析:从CLIP、BLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion的第一部分)风格的图像-文本和视频-文本对比模型
具体而言,我们首先使用视频中的单帧计算图像-文本相似度,并过滤掉低相似度对,然后随后过滤掉视频-文本对齐度低的对
其中一些数据包含静态或低运动视频;使用基于运动评分的过滤(Girdhar等,2023)来过滤掉这些数据。 我们不对视频的视觉质量应用任何过滤,例如美学评分或分辨率过滤。
数据集包含平均时长为21秒的视频,中位时长为16秒,超过 99%的视频时长不到一分钟。 空间分辨率在320p和4K视频之间显著变化,其中超过 70%的视频短边大于720像素。 视频具有不同的纵横比,几乎所有视频的纵横比都在 1:2和 2:1之间,中位数为 1:1
2.2 模型架构与其预训练
视觉识别模型由三个主要组件组成: (1)图像编码器, (2)图像适配器,和 (3)视频适配器
2.2.1 图像编码器
图像编码器是一个标准的视觉变换器(ViT;Dosovitskiy等人2020),训练用于对齐图像和文本(Xu等人,2023),具体而言
- 使用了ViT-H/14变体的图像编码器,它有630M——6.3亿参数,在25亿图像-文本对上训练了五个epoch

- 图像编码器在分辨率为 224 × 224的图像上进行了预训练
图像被分割成 16 × 16个块,每个块的大小为14x14(即The image encoder is pre-trained on images with resolution 224 × 224; images were split up into 16 × 16 patches of equal size(i.e., a patch size of 14x14 pixels),注意,此处和ViT原始论文中的设置不一样,因为此处的块大小为14× 14像素——a patch size of 14x14 pixels,相当于横着有16个像素块,竖着也有16个像素块)顺带多说一下,原始的ViT论文中,是14*14 14*14 14*14 14*14 14*14 14*14 14*14 14*14 14*14 14*14 14*14 14*14 14*14 14*14 14*14 14*14 ...
“以ViT_base_patch16为例,一张224 x 224的图片先分割成 16 x 16 的 patch ,很显然会因此而存在 个 patch(这个patch数如果泛化到一般情况就是图片长宽除以patch的长宽,即且图片的长宽由原来的224 x 224 变成:14 x 14(因为224/16 = 14)
个 patch(这个patch数如果泛化到一般情况就是图片长宽除以patch的长宽,即且图片的长宽由原来的224 x 224 变成:14 x 14(因为224/16 = 14)
你可能还没意识到这个操作的价值,这相当于把图片需要处理的像素单元从5万多直接降到了14x14 = 196个像素块,如果一个像素块当做一个token,那针对196个像素块/token去做self-attention不就轻松多了么(顺带提一句,其实在ViT之前,已经有人做了类似的工作,比如ICLR 2020的一篇paper便是针对CIFAR-10中的图片抽 的像素块)”
至于ViT的细节,详见此文《图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer》的第4部分 - 正如之前的工作如ViP-Llava (Cai等,2024年)所示,我们观察到通过对比文本对齐目标训练的图像编码器无法保留细粒度的定位信息
为了解决这个问题,采用了多层特征提取,除了提供最终层特征外,还提供了第4层、第8层、第16层、第24层和第31层的特征
此外,在交叉注意力层预训练之前进一步插入了8个门控自注意力层(总共40 transformer block),以学习对齐特定的特征
因此,图像编码器最终总共有 850M参数和附加层
通过多层特征,图像编码器为每个结果的16× 16 = 256个patch生成一个7680维的表示(计算过程是:224✖️224/14✖️14 = 256)
且发现,在后续训练阶段不冻结图像编码器的参数可以提高性能,特别是在文本识别等领域
2.2.2 图像适配器:在图像token与语言token之间插入交叉注意力
在图像编码器生成的视觉token表示和语言模型生成的语言token表示之间引入了交叉注意层(Alayrac等,2022,即We introduce cross-attention layers between the visual token representations produced by the image encoder and the token representations produced by the language model)
而交叉注意层在核心语言模型中的每第4个自注意层之后应用(The cross-attention layers are applied after every fourth self-attention layer in the core language)。 与语言模型本身一样,交叉注意层使用广义查询注意(GQA)以提高效率
交叉注意层为模型引入了大量额外的可训练参数:对于Llama 3 405B,交叉注意层有 ≈100B参数,且在两个阶段对图像适配器进行预训练:
- 初始预训练
在上述描述的约6B 图像-文本对的数据集上对图像适配器进行预训练
出于计算效率的原因,将所有图像调整为最多4个 336× 336 像素的图块,过程中,排列图块以支持不同的纵横比,例如,672× 672, 672× 336, 和1344× 336
且使用 16,384 的全局批量大小和余弦学习率调度,初始学习率为 10 × 10−4,权重衰减为 0.01。其中,初始学习率是基于小规模实验确定的。 然而,这些发现并没有很好地推广到非常长的训练计划中,并且在损失值变得停滞时,在训练过程中多次降低了学习率 - 退火
继续在上述描述的退火数据集中的约500M 图像上训练图像适配器
相当于在基础预训练之后,我们进一步提高图像分辨率,并在退火数据集上继续训练相同的权重——以提高在需要高分辨率图像的任务上的性能,例如信息图理解
最终,优化器通过热身重新初始化到学习率 2 × 10−5,并再次遵循余弦调度
2.2.3 视频适配器:从已有的图像预训练和退火权重开始
模型最多可以输入64帧(从完整视频中均匀采样),每帧都由图像编码器处理。通过两个组件对视频中的时间结构进行建模——添加视频聚合器和交叉注意层:
- 编码的视频帧由时间聚合器聚合,32个连续帧合并为一个
- 在每第4个图像交叉注意层之前添加额外的视频交叉注意层(additional video cross attention layers are added before every fourth image cross attention layer)
时间聚合器实现为感知器重采样器(Jaegle et al., 2021; Alayrac et al., 2022),且在预训练时每个视频使用16帧(聚合为1帧),但在监督微调期间将输入帧数增加到64帧。 对于Llama 3 7B和70B,视频聚合器和交叉注意层分别有0.6B和4.6B参数
最后,值得一提的是,在将视觉识别组件添加到Llama 3之后,模型包含自注意层、交叉注意层——包含图像交叉注意层和视频交叉注意层,和一个ViT图像编码器。 为了训练较小的8B和70B参数模型的适配器,发现数据和张量并行的组合是最有效的
在这些规模下,模型或流水线并行并不会提高效率,因为模型参数的聚集会主导计算。 然而,在训练405B参数模型的适配器时,确实还使用了流水线并行(除了数据和张量并行),不过在405B这种规模下训练除了上文「1.3节 模型并行」中概述的挑战外,还引入了三个新的挑战:模型异质性、数据异质性和数值不稳定性
- 模型计算是异质性的,因为在某些token上执行的计算比其他token更多。 特别是,图像token由图像编码器和交叉注意层处理,而文本token仅由语言主干处理
这种异质性导致了流水线并行调度中的瓶颈,最终通过确保每个流水线阶段包含五层来解决这个问题:即语言主干中的四个自注意力层和一个交叉注意力层(回想一下,我们在每四个自注意力层之后引入一个交叉注意力层)
此外,在所有流水线阶段复制图像编码器。 因为在配对的图像-文本数据上进行训练,这使我们能够在计算的图像和文本部分之间进行负载平衡 - 数据异质性
数据是异质的,因为平均而言,图像比关联的文本有更多的token:一个图像有2,308个token,而关联的文本平均只有192个token
因此,交叉注意力层的计算比自注意力层的计算需要更多的时间和内存
最终通过在图像编码器中引入序列并行化来解决这个问题(本博客内后续会详细介绍什么是序列并行),以便每个GPU处理大致相同数量的token。 由于平均文本大小相对较短,还使用了大得多的微批量大小(8而不是1) - 数值不稳定性
在将图像编码器添加到模型后,发现使用 bf16 进行梯度累积会导致数值不稳定性
对于此点,最可能的解释是图像token通过所有交叉注意力层引入语言主干。 这意味着图像标记表示中的数值偏差对整体计算有着巨大的影响,因为错误是累积的
最终通过在 FP32 中执行梯度累积来解决这个问题
2.3 预训练之后的微调
2.3.1 图像和视频分别对应的:监督微调数据与监督微调实际流程
首先,依次看下图像、视频层面的SFT数据
对于图像,利用不同数据集的混合进行监督微调
- 学术数据集
使用模板或通过LLM重写将现有的高度过滤的学术数据集转换为问答对。 LLM重写的目的是通过不同的指令来增强数据,并提高答案的语言质量 - 人工标注
通过人工标注收集多模态对话数据,涵盖广泛的任务(开放式问答、字幕、实际用例等)和领域(例如,自然图像和结构化图像)
标注人员会被提供图像并要求撰写对话。为了确保多样性,对大规模数据集进行聚类,并在不同的聚类中均匀抽样图
此外,我们通过扩展种子并使用k-最近邻算法为一些特定领域获取了额外的图像邻居,注释者还会获得现有模型的中间检查点,以便进行模型循环式注释,从而可以利用模型生成的内容作为起点,然后由注释者进行额外的人类编辑
这是一个迭代过程,其中模型检查点会定期更新为在最新数据上训练的性能更好的版本。 这增加了人工注释的数量和效率,同时也提高了它们的质量 - 合成数据
他们探索了使用图像的文本表示和文本输入LLM生成合成多模态数据的不同方法
其高层次的想法是利用文本输入LLM的推理能力在文本领域生成问答对,并用相应的图像替换文本表示以生成合成多模态数据
示例包括将问答数据集中的文本渲染为图像或将表格数据渲染为表格和图表的合成图像。 此外,使用现有图像的标题和OCR提取内容生成与图像相关的额外对话或问答数据
至于视频层面的数据,类似于图像适配器,使用带有预先注释的学术数据集,并将其转换为适当的文本指令和目标响应。 目标被转换为开放式响应或多项选择题选项,以更适合的方式呈现。 我们要求人工为视频注释问题及相应的答案。 要求注释者专注于那些无法通过单帧图像回答的问题,以引导注释者提出需要时间理解的问题
接下来,看下图像和视频的监督微调SFT方法
对于图像SFT
从预训练的图像适配器初始化,但将预训练语言模型的权重与指令调优语言模型的权重进行热交换。 语言模型的权重保持冻结状态以维持仅文本的性能,即,只更新视觉编码器和图像适配器的权重
我们微调模型的方法类似于Wortsman等人(2022年)的做法
- 首先,我们使用多个随机数据子集、学习率和权重衰减值进行超参数搜索
- 接下来,我们根据模型的性能对其进行排名
- 最后,我们对排名前K的模型的权重进行平均,以获得最终模型。 K的值通过评估平均模型并选择性能最高的实例来确定
可以观察到,平均模型相比于通过网格搜索找到的最佳单个模型,始终能产生更好的结果。 此外,这种策略减少了对超参数的敏感性
对于视频SFT,使用预训练权重初始化视频聚合器和交叉注意力层
模型中的其余参数、图像权重和LLM,都是从相应模型的微调阶段初始化的。 类似于视频预训练,我们随后仅在视频SFT数据上微调视频参数。 在这个阶段,将视频长度增加到64帧,并使用32的聚合因子来获得两个有效帧。 块的分辨率也增加了,以与相应的图像超参数保持一致
2.3.2 偏好数据以及对应的奖励建模
为了构建用于奖励建模和直接偏好优化的多模态成对偏好数据集,Meta的研究着们做了如下动作
- 人工标注
人工标注的偏好数据包括对两个不同模型输出的比较,标记为“选择”和“拒绝”,并有7级评分
而用于生成response的模型是从最近最好的模型池中即时抽样的,每个模型具有不同的特性
且每周更新一次模型池。 除了偏好标签外,还要求标注者提供可选的人类编辑,以纠正“选择”response中的不准确之处,因为视觉任务对不准确的容忍度较低(Besides preference labels, we also request annotators to provide optional human edits to correct inaccuracies in “chosen” responses because vision tasks have a low tolerance for inaccuracies)
当然了,人类编辑是一个可选步骤,因为在实践中存在数量和质量之间的权衡 - 合成数据
还可以通过使用仅文本的LLM来编辑和故意引入错误来生成合成偏好对,以用于监督微调数据集
比如将对话数据作为输入,并使用LLM引入细微但有意义的错误(例如,改变对象,改变属性,在计算中添加错误等)。这些编辑后的response被用作负面的“拒绝”样本,并与“选择”的原始监督微调数据配对 - 拒绝采样
此外,为了创建更多 on-policy负面样本,可以利用拒绝采样的迭代过程来收集额外的偏好数据
比如将在以下部分更详细地讨论对拒绝采样的使用。 从高层次来看,拒绝采样用于从模型中迭代采样高质量的生成。 因此,作为副产品,所有未被选中的生成结果可以用作负面拒绝样本,并用作额外的偏好数据对
有了偏好数据,那么接下来便可以进行奖励建模了
比如在视觉SFT模型和语言RM的基础上训练一个视觉奖励模型(RM),其中
- 视觉编码器和交叉注意力层从视觉SFT模型初始化,并在训练过程中解冻
- 而自注意力层从语言RM初始化并保持冻结状态
他们观察到,冻结语言RM部分通常会导致更好的准确性,特别是在需要RM根据其知识或语言质量进行判断的任务上
且采用与语言RM相同的训练目标,但在批次平均的奖励对数平方上添加了一个加权正则化项,以防止奖励分数漂移
如上面说过的,在训练视觉RM时,类似语言偏好数据,也是创建两个或三个具有明确排名的对(edited > chosen > rejected),此外,我们还通过扰乱与图像信息相关的单词或短语(例如数字或视觉文本)来合成增强负面响应,从而鼓励视觉RM基于实际图像内容进行判断
2.3.3 直接偏好优化——DPO:基于偏好数据直接调优
类似于语言模型,使用第上面描述的偏好数据,通过直接偏好优化(DPO;Rafailov等人(2023))进一步训练视觉适配器
为了应对后训练轮次中的分布偏移,只保留最近的人类偏好注释批次,同时丢弃足够偏离策略的批次(例如,如果基础预训练模型发生变化)「To combat the distribution shift during post-training rounds, we only keep recent batches of human preference annotations while dropping batches that are sufficiently off-policy (e.g., if the base pre-trained model is change」
可以发现,与始终冻结参考模型相比,每k步以指数移动平均(EMA)方式更新参考模型有助于模型从数据中学习更多,从而在人类评估中表现更好。 总体而言,我们观察到视觉DPO模型在每次微调迭代的人类评估中始终表现优于其SFT起点
最终,加上了视觉能力的llama3,其在图像理解层面的性能在与相关模型PK时,得到的结果如下

第三部分 给llama3.1 加上语音能力——语音模型的架构与其原理
为了将语音能力整合到Llama 3中,可以类似于我们用于视觉识别的方法(当然,截止到24年7月下旬,和视觉llama3.1一样,语言llama3.1 也暂未发布)
在输入端,结合了编码器和适配器来处理语音信号。利用系统提示(文本形式)来启用Llama 3在语音理解中的不同操作模式。 如果没有提供系统提示,模型将作为通用的口语对话模型,能够有效地以与Llama 3文本版本一致的方式响应用户的语音
且对话历史被引入作为提示前缀,以改善多轮对话体验。 我们还尝试了启用Llama 3用于自动语音识别(ASR)和自动语音翻译(AST)的系统提示
最终,Llama 3的语音接口支持多达34种语言,且还允许文本和语音的交替输入,使模型能够解决高级音频理解任务
最后,他们还尝试了一种语音生成方法,在这种方法中,实现了一个流式文本到语音(TTS)系统,该系统在语言模型解码过程中实时生成语音波形
具体实现时,基于专有的TTS系统设计了Llama 3的语音生成器,并且没有对语言模型进行语音生成的微调。 相反,我们通过在推理时利用Llama 3的嵌入来专注于提高语音合成的延迟、准确性和自然性(Instead, we focus on improving speech synthesis latency, accuracy, and naturalness by leveraging Llama 3 embeddings at inference time)
在具体展开之前,我们先来回顾下包含视觉、语音能力的llama3的整体训练架构,如之前所述,其包含五个阶段的训练:1 语言模型预训练,2 多模态编码器预训练,3 视觉适配器训练,4 模型微调,5 语音适配器训练
其中,语音的架构如下图所示

3.1 语音理解层面的数据、架构及其训练
3.1.1 语音理解的数据:语音识别、语音翻译、口语对话
训练数据可以分为两类。 预训练数据包括大量未标注的语音,用于以自监督的方式初始化语音编码器。 监督微调数据包括语音识别、语音翻译和口语对话数据;这些数据用于在与大型语言模型集成时解锁特定能力
- 预训练数据。为了预训练语音编码器,策划了一个包含约1500万小时语音录音的数据集,涵盖大量语言。 我们使用语音活动检测(VAD)模型过滤音频数据,并选择VAD阈值高于0.7的音频样本进行预训练
在语音预训练数据中,还注重确保没有个人身份信息(PII)。比如使用Presidio Analyzer来识别这些PII - 语音识别和翻译数据。我们的ASR训练数据包含230K小时的手动转录语音记录,涵盖34种语言
我们的AST训练数据包含90K小时的双向翻译:从33种语言到英语以及从英语到33种语言。 这些数据包含使用NLLB工具包(NLLB Team等,2022)生成的监督和合成数据。 使用合成AST数据使我们能够提高低资源语言的模型质量。另,数据中的语音片段最长为60秒 - 口语对话数据。为了微调用于口语对话的语音适配器,Meta合成生成响应——通过要求语言模型响应这些提示的转录内容来生成语音提示(Fathullah等,2024年)
比如使用包含60K小时语音的ASR数据集的子集以这种方式生成合成数据
此外,通过在用于微调Llama 3的数据子集上运行Voicebox TTS系统(Le等,2024年)生成25K小时的合成数据,使用了几种启发式方法来选择与语音分布相匹配的微调数据子集。 这些启发式方法包括关注相对简短、结构简单且没有非文本符号的prompt
3.1.2 语音理解模型的架构
在输入端,语音模块由两个连续的模块组成:语音编码器和适配器
- 语音模块的输出直接作为token表示输入到语言模型中,从而实现语音和文本标记之间的直接交互
- 此外,我们引入了两个新的特殊token来封闭语音表示的序列
- 且语音模块与视觉模块有很大不同,后者通过交叉注意力层将多模态信息输入到语言模型中。 相比之下,语音模块生成的嵌入可以无缝集成到文本token中,使语音接口能够利用Llama 3语言模型的所有功能
对于语音编码器
语音编码器是一个具有10亿参数的Conformer(Gulati等,2020)模型。 模型的输入由80维的梅尔频谱图特征组成,这些特征首先由一个步幅为4的堆叠层处理,然后通过线性投影将帧长度减少到40毫秒
处理后的特征由一个包含24个Conformer层的编码器处理。 每个Conformer层具有1536的潜在维度,由两个4096维度的Macron-net风格前馈网络、一个核大小为7的卷积模块和一个具有24个注意力头的旋转注意力模块(Su等,2024)组成
对于语音适配器
语音适配器包含大约1亿个参数。 它由一个卷积层、一个旋转Transformer层和一个线性层组成。 卷积层的核大小为3,步幅为2,旨在将语音帧长度减少到80毫秒。 这使得模型能够为语言模型提供更粗粒度的特征
Transformer层具有3072的潜在维度和一个4096维度的前馈网络,在卷积下采样后进一步处理带有上下文的语音信息。 最后,线性层将输出维度映射到与语言模型嵌入层匹配
3.1.3 语音理解模型的训练
语音模块的训练分为两个阶段进行
第一阶段,语音预训练,利用未标注的数据训练一个语音编码器,该编码器在不同语言和声学条件下表现出强大的泛化能力
在第二阶段,监督微调,适配器和预训练的编码器与语言模型集成,并与其共同训练,而LLM保持冻结状态。 这使得模型能够响应语音输入。 这个阶段使用与语音理解能力相对应的标注数据
多语言ASR和AST建模通常会导致语言混淆/干扰,从而导致性能下降
- 一种流行的缓解方法是在源端和目标端都加入语言识别(LID)信息。 这可以在预定的方向上提高性能,但可能会带来通用性损失
例如,如果一个翻译系统在源端和目标端都需要LID,那么模型在训练中未见过的方向上可能不会表现出良好的零样本性能。 因此,目前的挑战是设计一个系统,在某种程度上允许LID信息,但保持模型足够通用,以便我们可以让模型在未见过的方向上进行语音翻译 - 为了解决这个问题,我们设计了只包含目标端LID信息的系统提示。 这些提示中的语音输入(源端)没有语言识别信息,这也可能使其能够处理代码切换的语音
对于ASR,我们使用以下系统提示:请用{language}重复我说的话:,其中 {language}来自34种语言之一(英语、法语等)
对于语音翻译,系统提示是:请将以下句子翻译成{language}:。 这种设计已被证明在提示语言模型以所需语言响应方面是有效的。且在训练和推理过程中使用了相同的系统提示
对于语音预训练
使用自监督的BEST-RQ算法(Chiu等,2022)来预训练语音编码器,对输入的梅尔频谱图应用长度为32帧、概率为2.5%的掩码
如果语音话语超过60秒,会随机裁剪6000帧,对应60秒的语音。 我们通过堆叠4个连续帧来量化梅尔频谱图特征,将320维向量投影到16维空间,并在包含8,192个向量的码书中执行基于余弦相似度度量的最近邻搜索。 为了稳定预训练,使用了16个不同的码书。 投影矩阵和码书是随机初始化的,并且在模型训练过程中不会更新。 为了提高效率,多重软最大损失仅在被掩盖的帧上使用。 编码器训练了500K步,全球批量大小为2,048个话语
对于监督微调
在监督微调阶段,预训练的语音编码器和随机初始化的适配器与Llama 3进一步联合优化。 在此过
程中,语言模型保持不变。 训练数据是ASR、AST和口语对话数据的混合,其中
- Llama 3 8B 的语音模型经过 650K 次更新训练,使用 512 个语句的全局批量大小和初始学习率 10−4
- Llama 3 70B 的语音模型经过 600K次更新训练,使用 768 个语句的全局批量大小和初始学习率 4 × 10−5
3.2 语音生成层面的数据、架构及其训练
3.2.1 语音生成的数据
语音生成数据集主要包括用于训练文本规范化(TN)模型和韵律模型(PM)的数据。 两种训练数据都增加了Llama 3嵌入的附加输入特征,以提供上下文信息。
- 文本规范化数据。我们的TN训练数据集包括55K个样本,涵盖了需要非平凡规范化的各种符号类(例如,数字、日期、时间)。 每个样本是一对书面形式的文本和相应的规范化口语形式的文本,并推断出执行规范化的手工制作的TN规则序列
- 韵律模型数据。PM训练数据包括从一个50K小时的TTS数据集中提取的语言和韵律特征,这些数据集是由专业配音演员在录音棚环境中录制的成对的转录和音频。
- Llama 3 嵌入
Llama 3 嵌入被作为第16个解码器层的输出,专门使用 Llama 3 8B 模型,并提取给定文本的嵌入(即书面形式的输入文本用于 TN 或音频转录用于 PM),就像它们是由 Llama 3 模型在没有用户提示的情况下生成的一样
在给定样本中,Llama 3 token序列中的每个块都明确地与 TN 或 PM 的原生输入序列中的相应块对齐,即TN 特定的文本token(由 unicode 类别划分)或分别为音素速率特征。 这允许使用Llama 3 token和嵌入的流输入来训练 TN 和 PM 模块
3.2.2 语音生成模型的架构
据llama3.1的技术报告所说,语音生成的两个关键组件中使用了Llama 3 8B嵌入:文本规范化和韵律建模
TN模块通过上下文转换书面文本为口语形式,确保语义正确性。 PM模块通过使用这些嵌入预测韵律特征,增强自然性和表现力。 它们共同实现了准确且自然的语音生成
- 文本规范化。作为生成语音语义正确性的决定因素,文本规范化(TN)模块执行从书面形式文本到最终由下游组件口头表达的相应口语形式的上下文感知转换
例如,书面形式文本 123根据语义上下文可以读作基数(一百二十三)或逐位拼读(一二三)。 TN系统由一个流式LSTM序列标注模型组成,该模型预测用于转换输入文本的手工制作的TN规则序列(Kang等,2024)
该神经模型还通过交叉注意力机制接收Llama 3嵌入,以利用其中编码的上下文信息,从而实现最小文本标记前瞻和流式输入/输出 - 韵律建模。 为了增强合成语音的自然性和表现力,Meta集成了一个仅解码器的基于Transformer的韵律模型(PM)(Radford等,2021),该模型将Llama 3嵌入作为额外输入
这种集成利用了Llama 3的语言能力,利用其文本输出和中间嵌入在token rate(Devlin等,2018;Dong等,2019;Raffel等,2020;Guo等,2023)来增强韵律特征的预测,从而减少模型所需的前瞻
PM集成了多个输入组件以生成全面的韵律预测:从上面详细描述的文本规范化前端派生的语言特征、token和嵌入
PM预测了三个关键的韵律特征:每个音素的对数时长、对数F0(基频)平均值和音素时长内的对数功率平均值。 该模型包括一个单向Transformer和六个注意力头。 每个模块包括交叉注意力层和两个具有864隐藏维度的全连接层
PM的一个独特特征是其双重交叉注意力机制,其中一层专用于语言输入,另一层专用于Llama嵌入。 这种设置有效地管理了不同的输入速率,而无需显式对齐
3.2.3 语音生成模型的训练
为了支持实时处理,韵律模型采用了一种前瞻机制,该机制考虑了固定数量的未来音素和可变数量的未来token。这确保了在处理传入文本时的一致前瞻,这对于低延迟语音合成应用至关重要
对于训练
Meta开发了一种利用因果掩蔽的动态对齐策略,以促进语音合成中的流式处理。 该策略结合了固定数量的未来音素和可变数量的未来标记的前瞻机制,与文本规范化过程中的分块过程一致。对于每个音素,标记前瞻包括由块大小定义的最大标记数,从而导致 Llama 嵌入的前瞻是可变的,但音素的前瞻是固定的
Llama 3 嵌入来自 Llama 3 8B 模型,在训练韵律模型期间保持冻结状态。输入的音素速率特征包括语言和说话者/风格可控性元素。 模型训练在批量大小为 1,024 个话语的情况下进行,每个话语的最大长度为 500 个音素。 我们使用 AdamW 优化器,学习率为 9 × 10−4,在 100 万次更新中进行训练,前 3,000 次更新进行学习率预热,随后采用余弦调度
对于推理
在推理过程中,采用相同的前瞻机制和因果掩码策略,以确保训练和实时处理之间的一致性。 PM 以流式方式处理传入文本,逐个音素更新音素速率特征,逐块更新标记速率特征。 新的块输入仅在该块的第一个音素当前时更新,保持训练期间的对齐和前瞻。
为了预测韵律目标,我们采用了一种延迟模式方法(Kharitonov 等,2021),这增强了模型捕捉和再现长距离韵律依赖的能力。 这种方法有助于合成语音的自然性和表现力,确保低延迟和高质量输出

