
- 1AI助力:7个改变游戏规则的网站构建神器
- 2数据分析:什么是业务?全面解析问题_业务的概念
- 3在STM32单片机上使用傅里叶解析信号_stm32傅里叶变换
- 4Spring Security + Jwt 集成实现登录_springsecurity+jwt 登录接口实现
- 5alibaba.fastjson.JSONObject中JSON转对象,对象中有其他对象属性的parseObject转换_fastjson jsonobject转对象
- 6【深度学习】自注意力机制与Transfomer结构_transformer的自注意力机制可以考虑整个序列的上下文
- 7【golang】Golang手写元组 tuple | golang tuple
- 8【人工智能】Transformers之Pipeline(五):深度估计(depth-estimation)_模型pipeline
- 9机器学习调参指南:提升模型性能的关键步骤_机器学习 如何提高参数在模型中的重要性
- 10原来Kylin的增量构建,大有学问(理解Cube、Cuboid与Segment的关系)_kylin 查询segment
Stable diffusion的SDXL模型,针不错!(含实操)_sdxl refiner模型
赞
踩
与之前的SD1.5大模型不同,这次的SDXL在架构上采用了“两步走”的生图方式:
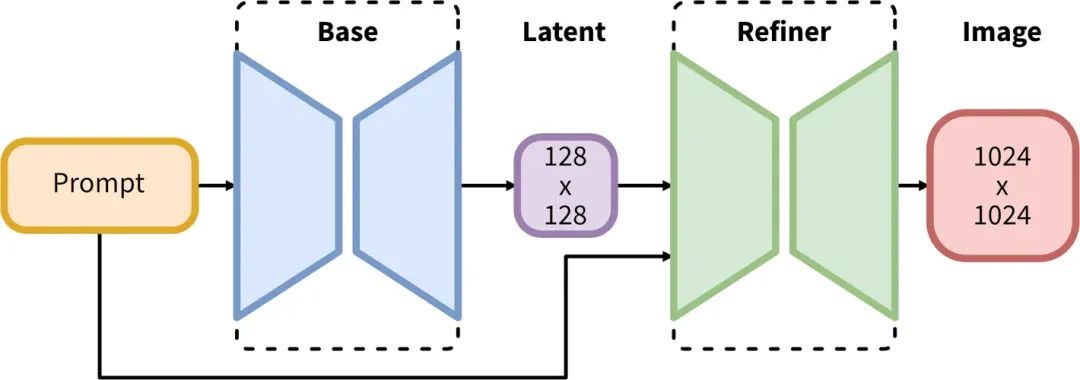
以往SD1.5大模型,生成步骤为 Prompt → Base → Image,比较简单直接;而这次的SDXL大模型则是在中间加了一步 Refiner。Refiner的作用是什么呢?简单来说就是能够自动对图像进行优化,提高图像质量和清晰度,减少人工干预的需要。
简单来说,SDXL这种设计就是先用基础模型(Base)生成一张看起来差不多的图片,然后再使用一个图像精修模型(Refiner)进行打磨,从而让图片生成的质量更高。而在没有这个之前,我们往往需要通过其他手段,如高清修复或面部修复来进行调优。
除了有出图质量更高这个优势,SDXL还有以下优点:
-
支持更高像素的图片(1024 x 1024)
-
对提示词的理解能力更好,比较简短的提示词也能达到不错的效果
-
相比SD1.5模型,在断肢断手多指的情况上有所改善
-
风格更为多样化
当然,每件事物不可能是完美的,所以SDXL也有一些局限性:
1、低像素出图质量不高
由于SDXL都是用1024x1024的图片训练的,这既导致它在这个像素级别上生成的质量比较高。但同时也导致了它在低像素级别(如512x512)生成的质量反而比较低,甚至不如SD1.5等模型。
2、与旧Lora不兼容
过去一些适用于SD1.5, 2.x 的Lora和ControlNet模型,大概率无法使用,得重新找一些带有SDXL的模型
3、对GPU显存的要求更高(这个下面会着重讲到)
4、出图时间也变久了
好了,简单讲完了SDXL大模型以及它的优缺点,接下来就开始实战了!
一、模型的下载
这次模型的下载有点不同,因为我们需要下载三个模型,分别是:sd_xl_base_1.0.safetensors、[1]sd_xl_refiner_1.0.safetensors 和 [2]sdxl_vae.safetensors[3] 。
三个模型的地址分别是:
-
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
-
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main
-
https://huggingface.co/stabilityai/sdxl-vae/tree/main
二、模型的加载
如果你的模型下载好了,就把 sd_xl_base_1.0.safetensors、sd_xl_refiner_1.0.safetensors 丢到根目录的 models\Stable-diffusion,把 sdxl_vae.safetensors 丢到 models\VAE 即可。
需要注意的是 Refiner 模型的加载,看发布日志是 SD1.6.0 的时候才支持,所以如果想使用的话得看你的版本有没有达到。另外就是这里的SD1.6.0指的是内核的版本,并不是模型的版本(不要被各种简写误导了)
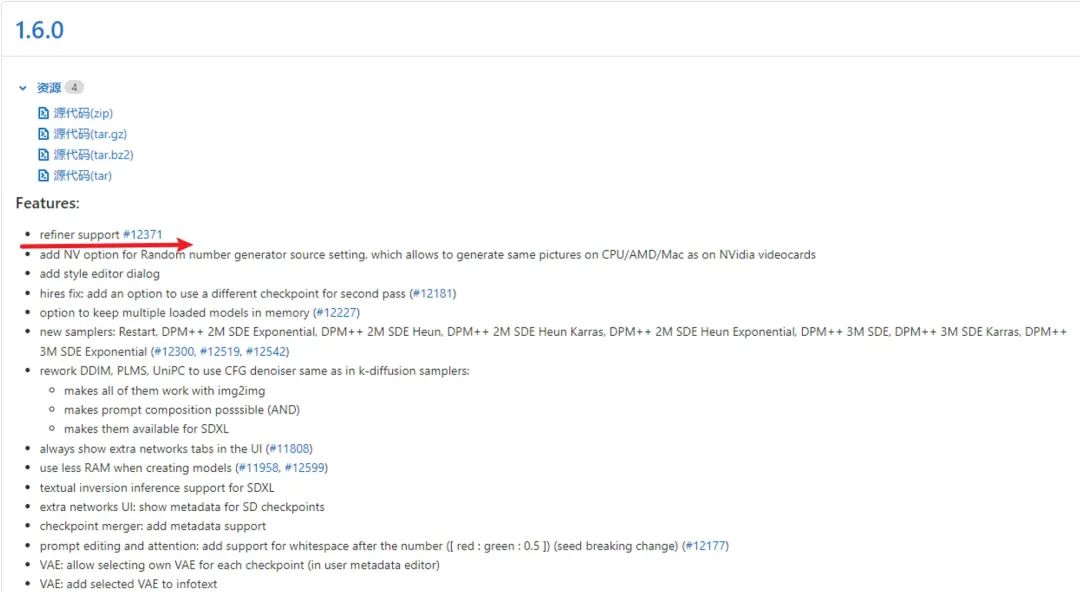
内核的版本指的是这里的版本

还有一个需要注意的是貌似升级版本容易有一些不兼容的问题,而且在使用SDXL大模型时也不一定就得用Refiner,单纯使用基础模型(base)也是OK的,只不过效果会差点,所以建议升级前也做一下调研工作。
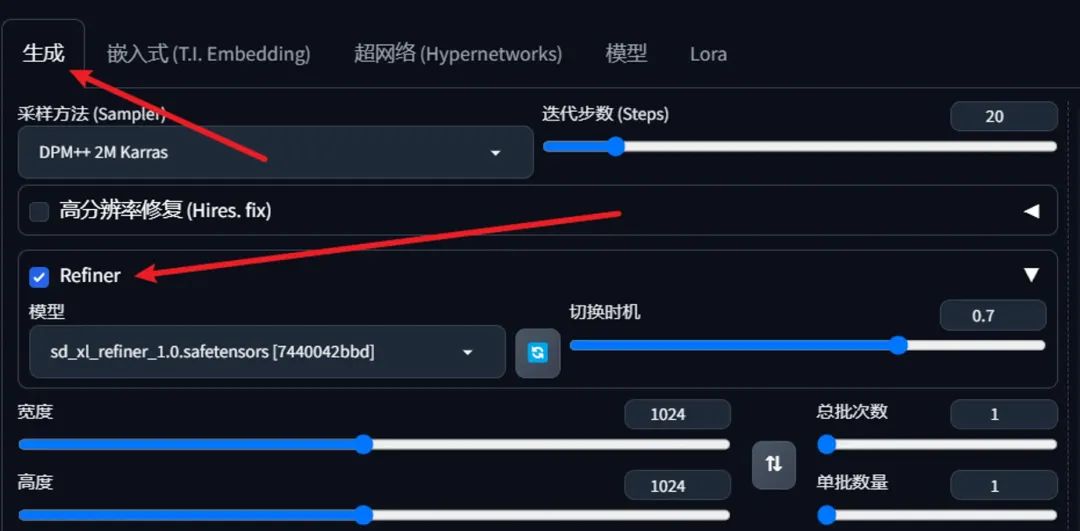
最后Refiner的位置可能没那么显眼,在生成选项卡里面
三、显存的大小
由于SDXL的模型和出图尺寸比之前的SD1.5大得多,所以也间接导致了它在出图方面所需要的显存和时间也变大了。
那到底需要多少显存呢?网上有一个说法是:跑SDXL最低显存是8G。经过我的测试,这个数据具有一定参考性,在进行一些优化的情况下,8G的显存的确能跑;但如果你什么优化都不做的话,8G的显存是不够的。
我自己的显卡是4060Ti 16G,内存32G,在这个配置的基础上我做了几个小测试(都是1024 x 1024的尺寸)
提示词:
a beatuiful real female play guitar
3.1 不开任何优化 + 不使用Refiner
第一个测试是在不开任何优化的情况下出图,结果还是出人意料的,居然爆显存了


3.2 不开任何优化 + 使用Refiner
第二个测试是在第1个的基础上,加了Refiner,但出乎意料的是,并没有爆显存,但从下方的显存使用看,也几乎达到了极限。为什么加了Refiner就没有爆显存我也不太清楚,希望有大佬留言科普下。

这里也简单说明最下方的A、R、Sys 三个指标:
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

