
- 1【CLIP】多模态预训练模型CLIP论文详解
- 2星光 SaaS 伙伴汉得信息:企业级 SaaS 能力构建,云原生赋能数字化创新_企业级saas集成ai能力要求标准
- 3Java序列化框架的比较(JDK、FastJson、Hessian、Hessian2、Protostuff)_java序列化框架比较
- 4一个API接口对接ChatGPT3.5/4.0,Claude3,文心一言,通义千问,智谱AI等多款AI模型,打造属于自己的AI应用_chatgpt接口
- 5C语言实现顺序表(增,删,改,查)_c语言查表实现
- 6基于CLIP特征的多模态大模型中的视觉短板问题_基于clip模型
- 7硅谷课堂笔记(中)_该内容已被华为云开发者联盟社区收录
- 8SpringCloud Eureka工作原理_springcloudeureka原理
- 9华为OD机试2024年最新题库(Python)C卷+D卷_华为od机试python
- 10探秘 Awesome AIGC:开启人工智能生成内容的新篇章
LLM大模型入门(三)—— 大模型的训练方法_ollama模型训练
赞
踩
参考hugging face的文档介绍:https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism,以下介绍聚焦在pytorch的实现上。
随着现在的模型越来越大,训练数据越来越多时,单卡训练要么太慢,要么无法存下整个模型,导致无法训练。当你拥有多张GPU(单机多卡,多机多卡)时,你就可以通过一些并行训练的方式来解决你的问题。常见的并行方法有以下四种:
数据并行(DP): 每个GPU都加载全量模型参数,将数据分割成多块输入到每个GPU中单独处理,但在计算loss和梯度时会有同步机制。
模型张量并行(TP): 每个tensor被分割成多块(根据场景按行或者列分割)存储在不同的GPU上,每个GPU单独计算,最后同步汇总到一块,类似于transformer中的多头,假如每个头的计算都在一张单独的gpu上,计算完后将所有gpu的结果concat到一起再分发到每张gpu上。
流水线并行(PP): 将模型按照层拆分,不同的层存储在不同的gpu上,类似于流水线的形式,数据先进入到前面的层,输出结果传到其他GPU上进入到后面的层。反传同理。
ZeRO: 属于数据并行的范畴,但又很不一样,在ZeRO中会将模型参数、优化器参数、梯度等分片到不同的GPU上,ZeRO的方法可以配合张量并行或者流水线并行一起使用,但在配合TP或者PP时,通常只启用优化器参数的分片,其他的分片可能会带来不好的效果。此外ZeRO-offload还可以将一些计算量小且使用低频的参数放置在CPU上,比如优化器参数和参数更新的计算,或者混合精度训练时,fp32的参数,这些都可以放在CPU上,在不明显影响计算效果的同时,节约GPU显存。
数据并行
数据并行最常见的是DP(Data Parallel)和DDP(Distributed Data Parallel),DP和DDP的不同在于:
1)DP是基于多线程实现的,DDP是基于多进程实现的,每个GPU受单独的进程控制,不受GIL锁的限制。
2)DP只能在单机上使用,DDP单机和多机都可以使用。
3)DDP相比于DP训练速度要快,但并不绝对,有些场景下当GPU的通讯效率低时可能会更慢。
4)DP存在多次数据交换,DDP只存在一次梯度交换,且是通过GPU之间相互交换的方式融合所有的数据。
ZeRO数据并行
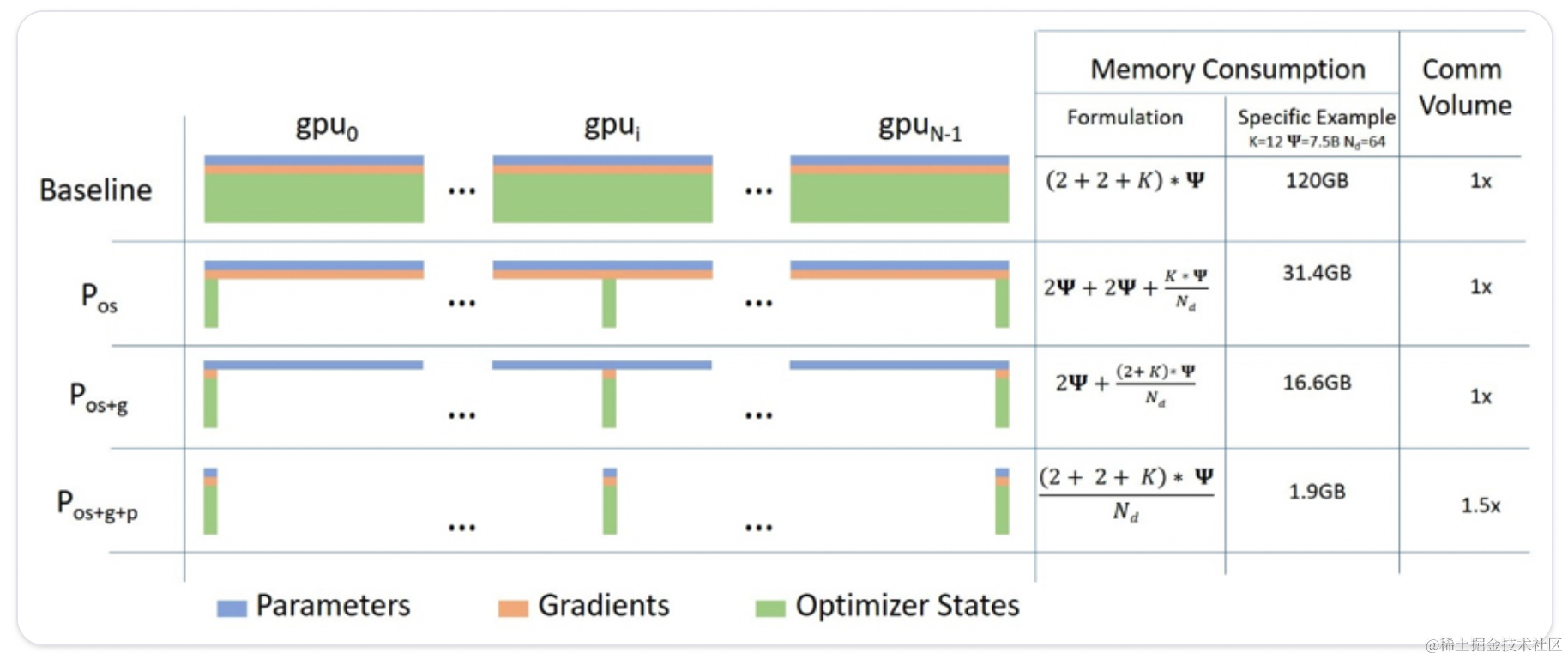
如上图所示,Baseline是指每张GPU都存储所有的参数,包括模型权重、梯度、优化器状态,除此之外其实还有激活层、临时存储,不可用的内存碎片等。
Pos:优化器状态分片
Pos+g:优化器状态和梯度分片
Pos+g+p:优化器状态、梯度和权重参数分片。
ZeRO相比于DP来说,主要在于各种参数分布在不同的GPU上,当在运行计算时,每个GPU会去同步完整的参数去计算。假如给定一个3层的模型,每层有3个参数:
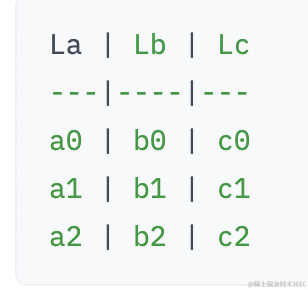
给定3个GPU去分片存储不同的权重块:

给定输入当到达La层时,在GPU0上只有a0参数,此时GPU0会从GPU1和GPU2上同步a1和a2组合成完整的参数进行计算,计算完后就释放参数,对于GPU1和GPU2同理。所以这里和张量并行是不太一样的,这里会同步全量的参数。
流水线并行
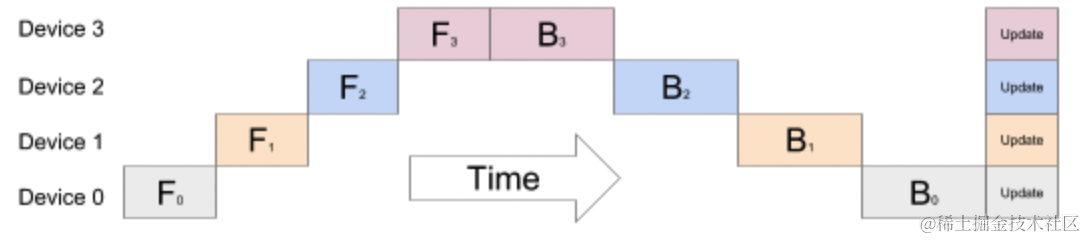
流水线并行是将模型按层拆分存储到不同的GPU上,假定给定一个8层的模型和2个GPU,如下所示:前4层在GPU0上,后4层在GPU1上,在前向计算过程中先在GPU0上计算,然后将GPU0上的输出同步到GPU1上计算。反向传播同理。

流水线并行的方式存在一个问题,后面层需要等前面的计算完才能开始计算,会导致GPU在一段时间是闲置的,如下图所示:
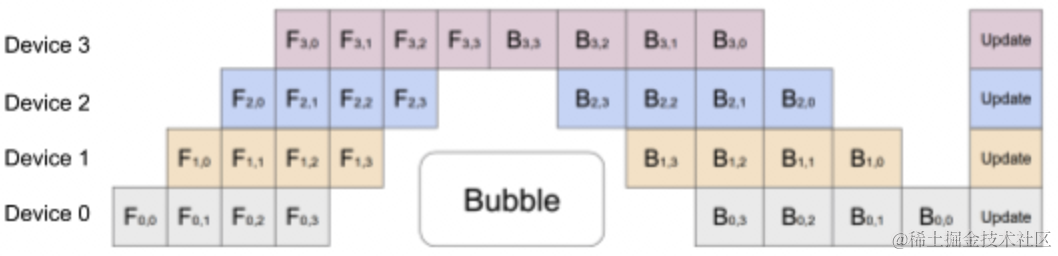
为了让GPU的闲置时间减少,在流水线并行的思路上引入数据并行,将原来的mini batch分割成更小的macro batch,让整个训练如下图所示:
张量并行
张量并行是将一个完整的tensor分割成多块存储到不同的GPU上,流水线并行解决不了一个GPU无法存储一个模型layer的情况,而张量并行可以解决这类问题。详见Megatron-LM的论文。
在transformer架构中主要是有线性层和GeLU一类的激活函数组成,对模型的权重按照行或者列分块时,线性矩阵运算如下:按照列拆分权重时,输入不需要拆分,最终通过concat组合结果;按行拆分权重时,输入也需要拆分,最终通过相加组合结果。从这里的特性也可以知道,假定一个函数为GeLU(XA)B,对于激活函数里面的A按列拆分可以在单个GPU中完成激活计算,此时对应的B可以按行计算,以上所有操作都可以只在各自的GPU中完成,较少通信操作,最后才同步合并结果。
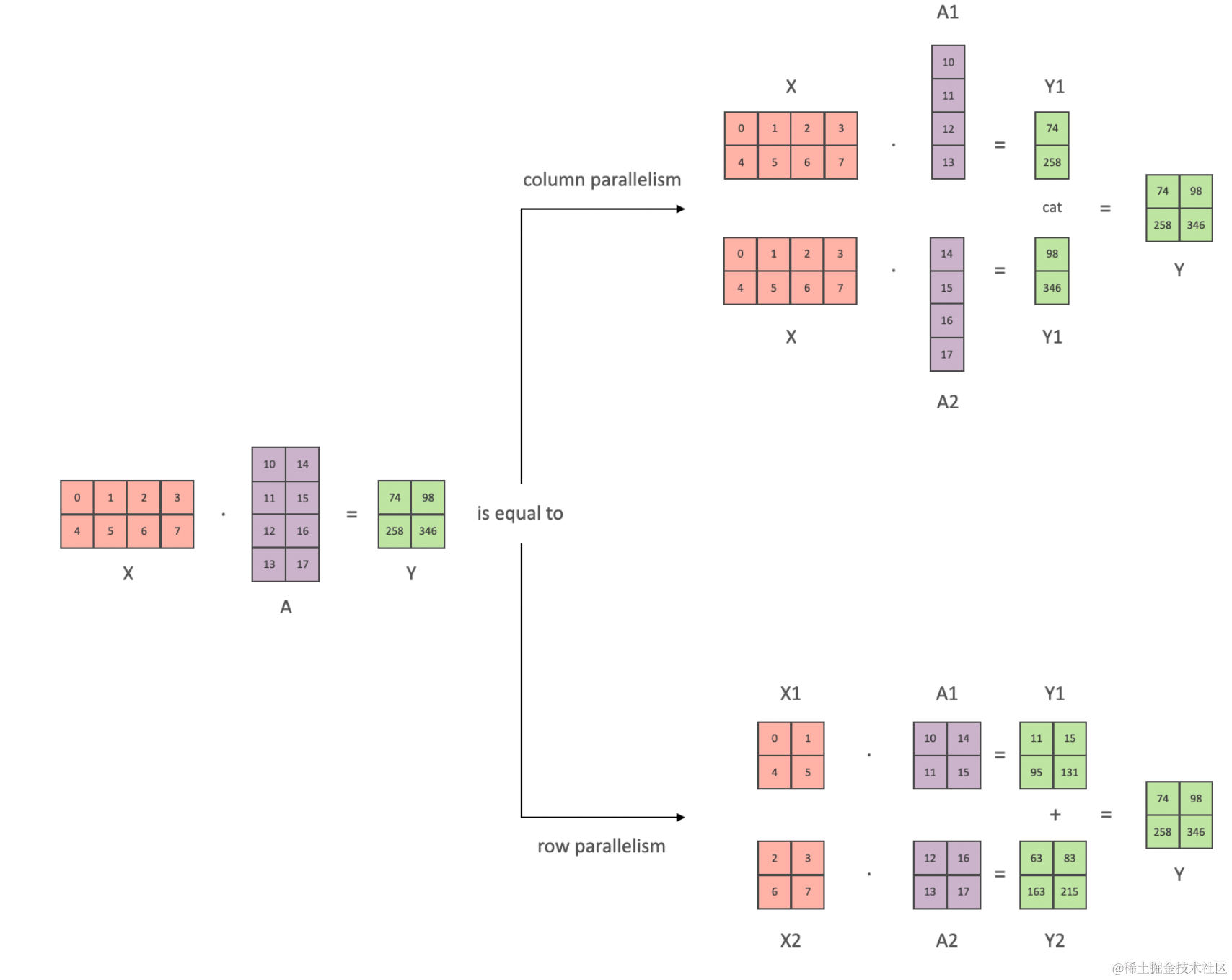
适用场景
单GPU
当模型可以存储在单GPU上:正常训练;
当模型不能存储在单GPU上:可以使用ZeRO-Offload CPU等方法,让CPU去承载部分参数。
单机多GPU
当模型可以存储在单GPU上:DDP(推荐),ZeRO(可能会提效);
当模型不能存储在单GPU上:PP,ZeRO,TP。但最大层无法放在单GPU上时,就只能使用TP、ZeRO。
多机多GPU
当节点间通讯比较快时:ZeRO,PP+TP+DP;
当节点间通讯比较慢时:DP+TP+PP+ZeRO-1(ZeRO-1是指只对优化器参数做分片)。
如何系统的去学习AI大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/空白诗007/article/detail/1012003
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

