
- 1区块链应用实例_区块链应用实践的实例分析
- 2c语言自动阅卷系统概要设计,VC++自动阅卷系统设计与实现(源代码及全套资料).doc...
- 3关于如何自定义spring-boot-starter起步依赖_aliyun-oss-spring-boot-starter
- 4创建 vite+vue3+ts 移动端项目_vue 3.0 搭建移动端项目
- 5Windows下使用海康相机SDK获取图像并在Qt显示_海康mvs
- 6CVE-2018-8120漏洞提权:Windows 7的安全剖析与实战应用
- 7django的继承(extends)和包含(include)_pycharm中django咋用继承
- 8word2vec论文翻译(5000字)
- 9深度学习图绘制工具汇总_convnetdraw
- 10使用pip安装TensorFlow & 相关问题_pip 3.12 可以下载tensorflow2.3.0吗
论文阅读:RAM++ | Open-Set Image Tagging with Multi-Grained Text Supervision
赞
踩

发表时间:2023年11月16
论文地址:https://arxiv.org/pdf/2310.15200
项目地址:https://github.com/xinyu1205/recognize-anything
Recognize Anything Plus Model(RAM++),这是一种有效利用多粒度文本监督的开放集图像标记模型。以前的方法(例如,CLIP)主要利用与图像配对的全局文本监督,导致在识别多个单独的语义标签方面的次优性能。相比之下,RAM++无缝地集成了单个标签监督(tag)和全局文本监督(sentence),所有这些都在一个统一的对齐框架内。这种集成不仅确保了对预定义标签类别的有效识别,而且还增强了对不同开放集类别的泛化能力。此外,RAM++使用大型语言模型(LLM)将语义约束的标签监督转换为更广泛的标签描述监督,从而丰富了开放集视觉描述概念的范围。对各种图像识别基准测试的全面评估表明,RAM++在大多数方面都超过了现有的最先进的(SOTA)开放集图像标记模型。具体来说,对于预定义的常用标签类别,RAM++在open-image和ImageNet上比CLIP有10.2 mAP和15.4 mAP的增强。对于超出预定义范围的开放集类别,RAM++在OpenImages上分别比CLIP和RAM提高了5.0 mAP和6.4 mAP。对于不同的人-对象交互短语,RAM++在HICO基准测试上实现了7.8 mAP和4.7 mAP的改进。
1. Introduction
图像识别仍然是计算机视觉的一个基础研究领域,需要机器根据给定的图像输出各种语义内容。为此,具有文本监督的视觉模型,如CLIP [43],ALIGN [22]和Florence[56]利用来自互联网的大规模图像文本对来学习全面的视觉概念。这些模型在单标签图像分类[10]中显示了显著的开放集识别,促进了它们在具有任意视觉概念[16,49]的不同领域特定数据集上的应用。
尽管取得了这些进展,但这些模型主要依赖于全局文本监督,从而直接对齐全局文本嵌入与相应的全局视觉特征。对于更复杂的多标签识别任务,这种监督是次优的。由于全局文本监督纠缠着多种语义,因此对单个标签语义的影响显著减弱。如图1所示,文字“a dog sits on a couch near a table”包含了“狗”、“沙发”和“桌子”的概念。然而,它的全局嵌入表现出与这些个体语义的部分差异。
现有的技术方案在细类别上存在不足,无法展现出图像中的二级类别信息,导致监督信号存在偏移
相比之下,具有单个标签监督的图像标签模型主要使用有限尺度[13,28]的手动标注图像标签。尽管最近的研究表明,[20,21,59]显著扩大了使用图像-文本对的图像标签的规模,但图像标记模型在识别其预定义的标签系统之外的标签类别方面仍然存在不足。这一限制突出了具有固定类别的标签监督的约束语义泛化能力,因此阻碍了其更广泛的适用性。例如,将“狗”或“饮料”的标签概括为更具体的子类别,如“柯基犬”或“可口可乐”是一个挑战。此外,像“流星雨”这样的众多短语类别进一步提出了这一挑战。
现有的技术方案使用既定的词汇进行训练,限制了其在开放词汇下的检索能力。
为了解决上述局限性,我们的研究提出了一种利用多粒度文本监督的开放集图像标记模型,集成了全局文本监督和单个标签监督。图像标签被自动从文本中解析,提供了更细粒度的监督,以确保对预定义的标签类别的识别。同时,不同的文本监督使模型能够学习更广泛的文本语义,扩展了开放集类别的泛化能力。具体来说,我们在一个统一的对齐框架中合并了图像-标签-文本三联体。多粒度文本监督通过一个有效的对齐解码器[51]与视觉空间特征交互。与其他流行的对齐范式相比,我们的方法显示了优越的、高效的标记性能。
此外,考虑到标签监督的视觉概念不足,我们通过大型语言模型(LLMs)[1,37]将标签监督转换为更广泛的标签描述监督。llm被用来为每个标签类别自动生成多个可视化描述。这些描述随后通过一种新的自动重新加权机制集成到标签嵌入中,增强了与相应图像特征的相关性。这种方法丰富了图像标记模型的视觉概念的范围,增强了其在推理过程中引入视觉描述以进行开放集识别的能力。例如,“柯基犬”的标签可以扩展到一个更具描述性的“一只有短腿的小狗……”,这有助于确定它在图像中的存在。
因此,在我们提出的方法(RAM)的基础上,我们引入了 Recognize Anything Plus
Model(RAM++),这是一种开放集的图像标签模型,具有识别不同标签类别的特殊能力。如图2所示,在各种基准测试中,RAM++超过了现有的SOTA开集图像标记模型(CLIP [43]和RAM [59])。值得注意的是,RAM++在预定义的开放图像[25]和ImageNet [10]的常用类别上显示对于CLIP的10.2 mAP和15.4 mAP增强。此外,RAM++在开放集不常见的开放图像类别上也比CLIP和RAM实现了5.0 mAP和6.4 mAP的改进。对于不同的人-对象交互短语,RAM++在HICO [6]上对CLIP和RAM分别实现了7.8 mAP和4.7 mAP的改进。
论文主要贡献可以总结如下:
- 将图像-标签-文本三联体集成在一个统一的对齐框架中,在预定义的标签类别上实现了优越的性能,并增强了对开放集类别的识别能力。
- 第一次将LLM的知识纳入图像标记训练阶段,允许模型集成视觉描述概念,以便在推理过程中进行开放集类别识别。
- 对OPENImage、ImageNet、HICO基准测试的评估表明,RAM++在大多数方面都超过了现有的SOTA开放集图像标记模型。综合实验为强调多粒度文本监督的有效性提供了证据。
2. Related Works
Tag Supervision. 图像标记,也被称为多标签识别,涉及到为一个图像分配多个标签。传统的方法主要依赖于有限的手动注释的数据集[8,13,28],导致泛化能力较差。DualCoop [50]和MKT [17]使用预先训练好的视觉语言模型来提高开放集的能力,但它们受到训练数据集的规模的限制。Tag2Text [21]和RAM [59]获得了基于图像-文本对的大规模图像标签,展示了对预定义类别的高级zero-shot功能。尽管如此,所有这些模型都依赖于具有封闭集语义范围的标签监督,这限制了它们识别更多样化范围的开放集标签类别的能力。我们的RAM++无缝地集成了不同的文本监督和标签监督,有效地增强了开放集的标记能力。
多标签训练,也就是图片多分类
Text Supervision. 具有文本监督的视觉模型可以通过对齐视觉语言特征来识别开放集类别。像CLIP [43]和ALIGN [22]这样的先驱模型,它们收集了数百万个图像-文本对,在单标签图像分类[10]中表现出了显著的性能。然而,它们对全局文本监督的依赖在个体语义[59]的多标签任务中提出了挑战。虽然其他研究(如ALBEF [26]和BLIP [27])采用了深度视觉-语言特征融合,但我们的分析表明,它们在广泛类别标记任务中的效率和能力的局限性。与之相比,RAM++在一个统一的对齐框架内对齐多个文本和单个标签,显示出优越的高效标记性能
文本监督,也就是图文对齐训练
Description Supervision 之前的几项工作证明了利用基于文本的类别描述来提高图像识别性能的有效性。然而,所有这些之前的研究都依赖于外部的自然语言数据库,如手工[18,19,44]、维基百科[12,39]或WordNet [4,14,49,54]。由于LLMs [3,37]展示了强大的知识压缩能力,最近的工作结合了LLM在剪辑推理阶段的知识,以提高性能[9,29,36,41,45]和可解释性[35]。与这些方法不同的是,我们的工作率先将LLM知识集成到图像标记的训练过程中,这对于提高标记模型的开放集能力是自然而有效的。
描述监督,也就是将tag对应的LLM知识集成到训练过程中
3. Approaches
3.1. Overview Framework
RAM++,是一个基于多粒度文本监督的开放集图像标记模型,包括细节描述文本监督和tag描述监督。如图3所示,RAM++的体系结构包括图像编码器、文本编码器和对齐解码器。训练数据是图像-标签-文本三联体,包括图像-文本对和从文本中解析出的image标记。在训练过程中,模型的输入由包含batch间可变的文本和固定标签描述的图像组成。然后模型输出对应于每个图像标签/文本对的对齐概率分数,通过对齐损失[46]进行优化。
3.2. Multi-Grained Text Alignment
Unified Image-Tag-Text Alignment Paradigm 对于图像-标签-文本三联体,RAM++采用了一个共享的对齐解码器来同时对齐图像-文本和图像标签。为了清晰起见,图3将这个框架分成了两个部分。左边的部分说明了图像-文本对齐的过程,其中来自当前训练批处理的文本通过文本编码器来提取全局文本嵌入。这些文本嵌入随后通过对齐解码器中的交叉注意层与图像特征对齐,其中文本嵌入作为查询,图像特征作为键和值。相反,右边的部分强调图像标记的过程,其中图像特征使用相同的文本编码器和对齐解码器交互。
该对齐解码器是一个两层的注意解码器[30,51],每一层包括一个交叉注意层和一个前馈层。这种轻量级的设计确保了涉及广泛类别的图像标记的效率。重要的是,它消除了没有自我注意层的标签嵌入之间的相互影响,从而允许模型在不影响性能的情况下识别任何数量的标签类别。
Alignment Paradigm Comparison. 在图4中,我们将我们的图像-标签-文本对齐(ITTA)与其他流行的对齐范式进行了比较:CLIP[43]和对齐[22]采用的图像-文本对比学习(ITC),以及ALBEF [26]和BLIP [27]采用的图像-文本匹配(ITM)。ITC通过点积同时高效地对齐多个图像和文本的全局特征,但它依赖于具有浅层交互的全局文本监督,这给需要局部识别多个单独标签的图像标记带来了挑战。另一方面,ITM与深度对齐解码器进行深度视觉-语言特征融合。然而,它只执行一个图像-文本对,当在训练和推理中将图像与多个文本或标签对齐时,会导致显著的计算成本。
CLIP的图像-文本对齐学习,ITC,可以高效的对多个数据进行点乘式的监督训练;BLIP 的图像-文本匹配学习,ITM虽然可以深度对齐文本,产生更详细的文本描述,但只能进行一对一的计算,在多batch下计算成本较高
图6显示了带有ITC的CLIP和带有ITM的BLIP在性能次优的图像标记任务中都没有出现缺陷。
因此,我们的ITTA通过合并全局文本监督(句子监督)和单个标签监督(tag监督)来解决这些缺点,从而确保了对预定义和开放集类别的健壮标记性能。其他,采用有效的对齐解码器利用图像的空间特征,而不是图像的全局特征,考虑到标签经常对应于不同的图像区域。因此,ITTA在性能和效率之间建立了一种平衡,能够高效地将图像与数千个标签类别对齐。关于不同对齐范例之间的推理时间的比较,请参见图7。
RAM++的ITTA架构通过合并全局文本监督(句子监督,类似BLIP)和单个标签监督(tag监督,类似CLIP)来解决精度与性能的问题
3.3. LLM-Based Tag Description
另一种创新的方法是基于LLM的标签描述,它涉及到利用LLM的知识将语义约束的标签监督转换为扩展的语义标签描述,从而丰富了可以描述的开放集视觉概念的范围。
LLM Prompt Design 为了获得标签系统中每个标签类别的描述,必须及时设计llm。我们预计,由llm生成的标签描述主要表现出两个特征: (i)尽可能多样化,以覆盖更广泛的场景;(ii)尽可能与图像特征相关,以确保高相关性。
从[41]中汲取灵感,我们为每个标签类别总共设计了5个LLM提示,如下: (1)“简明地描述一个(n) {}是什么样子的”;(2)“你如何简明地识别一个(n){}?””;(3)“简洁的是什么样子?””;(4)“(n){}的识别特征”;(5)“请提供{}的视觉特征的简明描述”。原文:
(1) “Describe concisely what a(n) {} looks like”;
(2) “How can you identify a(n) {} concisely?”;
(3) “What does a(n) {} look like concisely?”;
(4) “What are the identified characteristics of a(n) {}”;
(5) “Please provide a concise description of the visual characteristics of {}”.
Tag Description Generation 基于设计的LLM提示,我们通过调用LLM API自动为每个标签类别生成描述。具体来说,我们采用了“GPT-3.5-turbo”模型[1],并设置了max tokens =77,这与文本编码器的标记器长度相同。为了促进LLM响应的多样性,我们将温度设置为=值0.99。因此,我们为每个LLM提示获得了10个独特的响应,每个类别总共积累了50个标签描述。
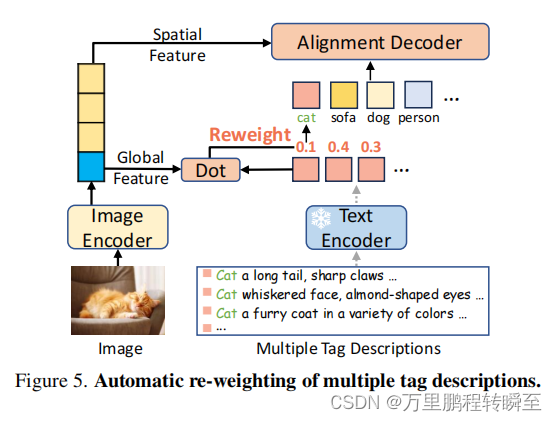
Automatic Re-weighting of Multiple Tag Descriptions. 每个类别的多重描述需要集成到一个标签嵌入中,以进行图像标记。一个简单的策略是即时集成,它在文本表示空间中平均多个标签描述。该策略与对开放集标记模型[41,43]的普遍评估工作相一致。然而,由于不知道图像和多个候选标签描述之间的不同相似性,平均嵌入对于训练过程可能是次优的。
为了实现从多个候选标签描述中进行的选择性学习,我们设计了一个自动重新加权模块,用于处理多个标签描述,如图5所示。
第i个标签类别的概率分数计算如下:
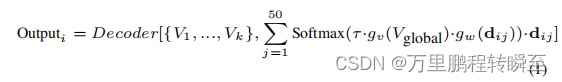
其中解码器表示对齐解码器,
V
g
l
o
g
a
l
V_{glogal}
Vglogal表示图像的全局特征,{V1,…,Vk}表示图像的空间特征。术语dij表示第j个标签描述的嵌入。函数
g
v
g_v
gv和
g
w
g_w
gw是将输入映射到相同维度的投影仪头,而τ是一个可学习的温度参数。
RAM++基于LLM对标签进行描述,补充了tag的额外知识,增强了模型对未知标签的泛化能力
3.4. Online/Offline Design
我们的方法还结合了针对不同步骤的在线/离线设计,确保了图像文本对齐和图像标签过程的无缝集成。在图像标记的上下文中,标签描述的数量是固定的,但是体积很大(例如,4,500个标签×50 des)。尽管为所有标签描述提取嵌入是很耗时的,但是描述嵌入可以使用现成的文本编码器[43]离线进行预处理。相比之下,图像-文本对齐处理可变的文本输入,其中由批处理大小决定的卷相对适中。因此,文本嵌入是可以在各个batch中在线提取特征的,规避了大量的计算成本开销。
4. Experiment
4.1. Experimental Settings
Training Datasets 我们使用了与Tag2Text [21]和RAM [59]相同的训练数据集。这些数据集基于开源的图像-文本对数据集,包括两个设置:400万(4M)图像数据集和1400万(14M)图像数据集。4M设置包括两个人类注释的数据集(COCO [28]和VG [24]),以及两个web数据集(SBU标题[38]和CC-3M [48])。14M设置通过合并CC-12M [5]扩展了4M。我们的标签系统包括4,585个在文本中常用的类别。对于标签2文本,图像标签是使用解析器[52]自动从配对文本中提取的。对于RAM,标签和文本都通过自动数据引擎[59]进一步增强。我们使用RAM数据集训练RAM++,并在Tag2文本数据集上执行额外的验证。
Implementation Details 我们使用在ImageNet [10]上预先训练过的SwinBase [32]作为图像编码器,并在其他比较方法中选择基尺度模型进行公平比较。我们利用来自CLIP [43]的现成文本编码器来提取文本和标签描述嵌入。我们采用了ASL [46]的鲁棒对齐损失函数,同时用于图像-文本对齐和图像标记。不同对齐损失函数的比较可在附录g中找到。在[21,26,27,59]之后,我们的模型在经过预训练后对COCO数据集进行了进一步的微调,以提高其性能。得益于快速收敛的特性,4M和14M版本的RAM++分别只需要1天和3天的训练,使用8个A100gpu。
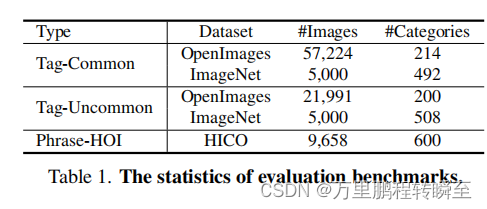
Evaluation Benchmarks 我们采用平均平均精度(mAP)作为评价度量,这是一种用于评价多标签识别性能[30,46,47,59]的良好指标。其他指标,包括F1分数、精确度和召回率。我们在各种域外评估基准上评估图像标记能力。具体来说,我们利用了广泛使用的基准测试 OpenImages[25]和ImageNet。考虑到ImageNet是单标记的,并且在其测试集中缺少标签,我们使用ImageNetMulti [2],其中测试集中的每幅图像都拥有多个标签,以进行更全面的注释。根据RAM++标签系统中的包含情况,这些基准测试的类别被分为“常见”和“不常见”类别。为了对短语类别进行更多的评估,我们求助于HICO [6]基准测试,这是一个关于人体对象交互的标准(HOI)的流行标准。HICO包含了80个对象类别,177个动作类别,总共产生了600个“人-行为-对象”的短语组合。评价基准的统计数据见表1。值得注意的是,对于RAM和RAM++,除了被认为是预定义类别的Tag-Common外,所有其他基准测试都是指在开放集配置中看不到的类别。
4.2. Comparison with State-of-the-Arts
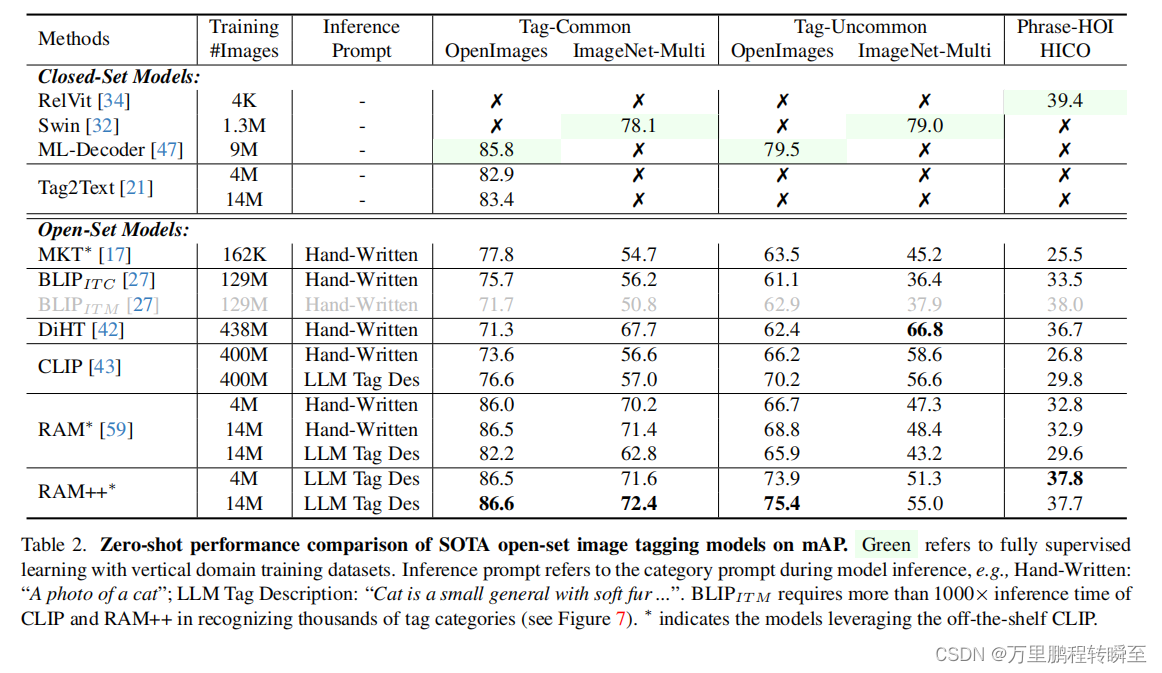
Quantitative Results 表2给出了RAM++和SOTA开放集图像标记模型之间的零镜头性能比较。一方面,文本监督模型,如BLIP和CLIP,在多标签识别上,在常见的和不常见的类别中都表现出次优的性能。另一方面,标签监督模型RAM在常见类别上的性能显著提高,但在不常见类别上不如CLIP。此外,当使用LLM标签描述进行推理时,CLIP的性能可以显著提高,这与[41]的研究结果一致。相反,RAM并不能从LLM标签描述中获益,这表明由于标签监督的语义受限,其具有的开放集泛化潜力有限。
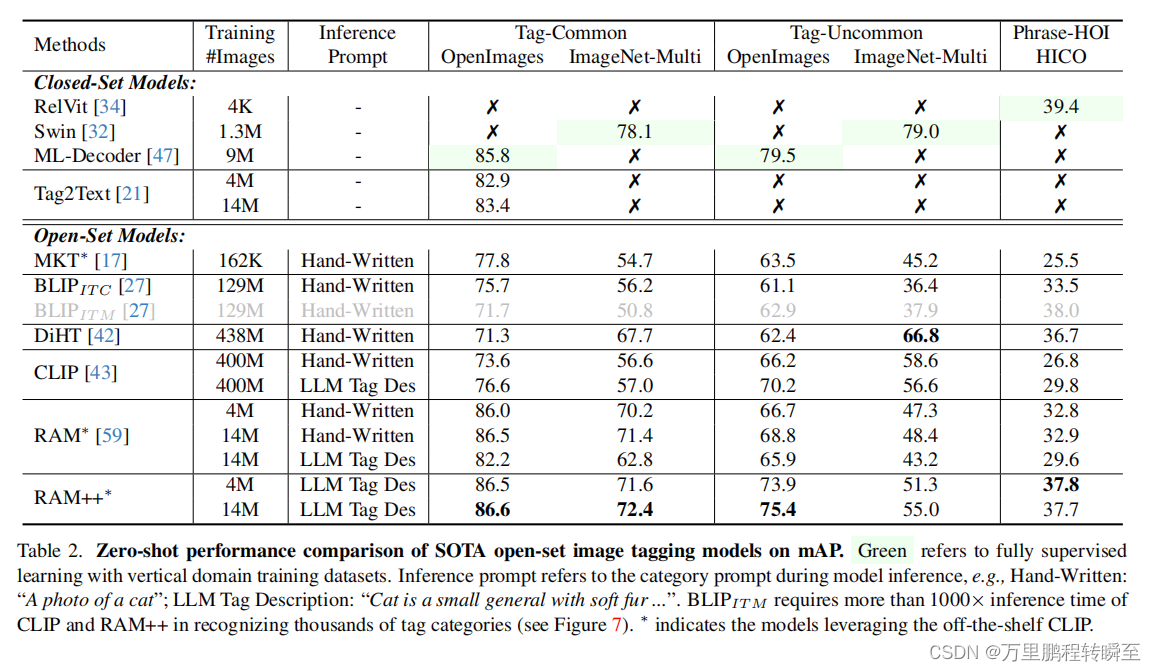
RAM++模型,它利用了文本监督和标签描述监督,在各种基准测试中建立了一个新的SOTA zero-shit性能。具体来说,RAM++在开放图像和ImageNet的常见类别上分别比CLIP强10.0 mAP和15.4 mAP。在开放集类别方面,RAM++在标签-不常见和短语-hoi上都显著优于RAM,这强调了我们的方法的有效性。值得注意的是,RAM++在HICO上比RAM和CLIP提高了6.6 mAP和5.2 mAP,在HICO上分别比RAM和CLIP提高了8.0 mAP和4.9 mAP。
尽管RAM++在ImageNet-Multi的罕见类别上略落后于CLIP,但我们认为,RAM++的1400万数据集规模不足以覆盖这些罕见类别。值得注意的是,将RAM++的数据从4M扩展到14M,导致了在ImageNet-Multi不常见类别上的3.7 mAP性能改进。我们认为,进一步扩大训练数据集可以增强RAM++的开放集识别能力。
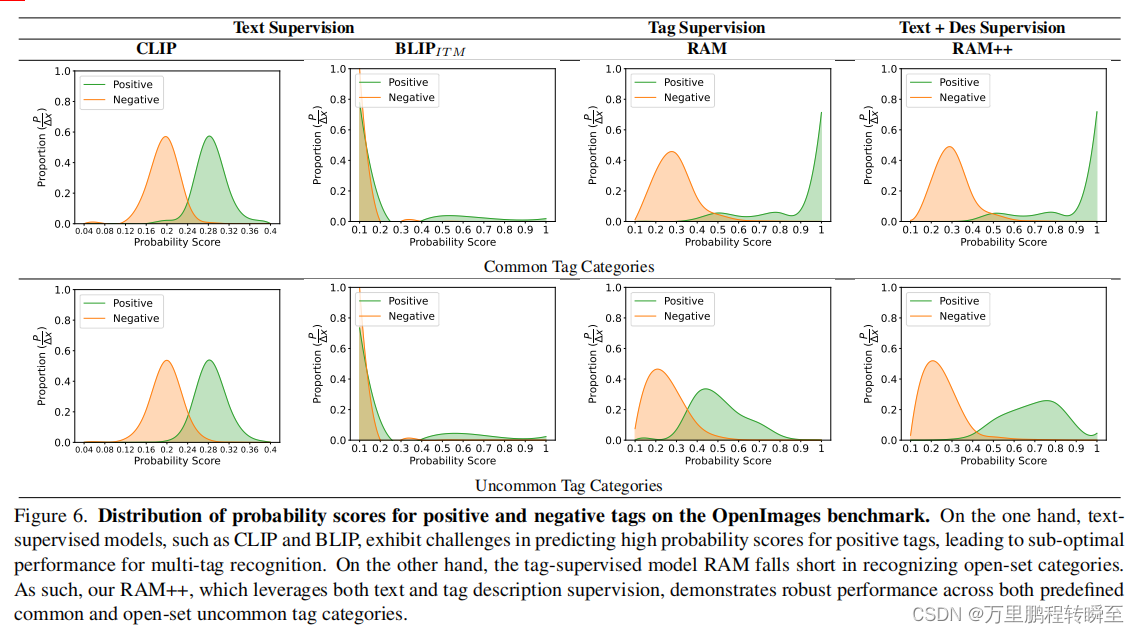
Distribution of Probability Scores. 在图6中,我们分析了正数的概率分数的分布和在OpenImages基准测试上,跨不同模型的负标签。一个有效的模型应该清楚地区分积极的标签和消极的标签。值得注意的是,RAM++,即来自文本和标签描述的双重监督,在预定义和开放集标签类别上都显示了健壮的性能。
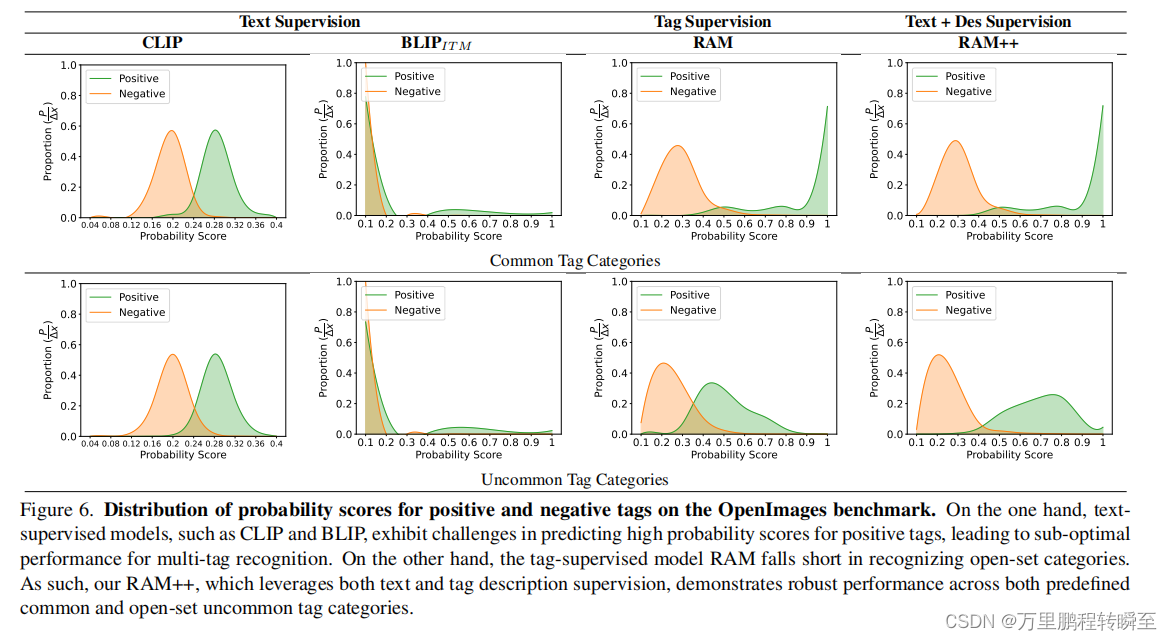
此外,我们承认调查不同对齐范式的分数分布背后的原因的价值,我们将其作为未来的工作。作为一个说明,我们认为CLIP中的对比损失可能导致其得分在0.2左右。而ITM模型的次优分布可以归因于在训练过程中对负样本的利用不足。
RAM和RAM++之间的预测概率比较的定量结果如图8所示。图中描述的是在自动重新加权中权重较高的描述。RAM++对开放集类别的预测概率有了显著的改进。

4.3. Analysis of Multi-Grained Supervision
Evaluation on Multi-Grained Text Supervision. 我们在表3中进行了一项全面的消融研究,以评估多粒度文本监督的影响。Case (a)和(b)参考了图3中的两个部分,它们通过对齐解码器仅利用文本监督和标签监督。文本监督在不同的基准测试中保持一致的性能,而标签监督增强了常见类别中的结果。
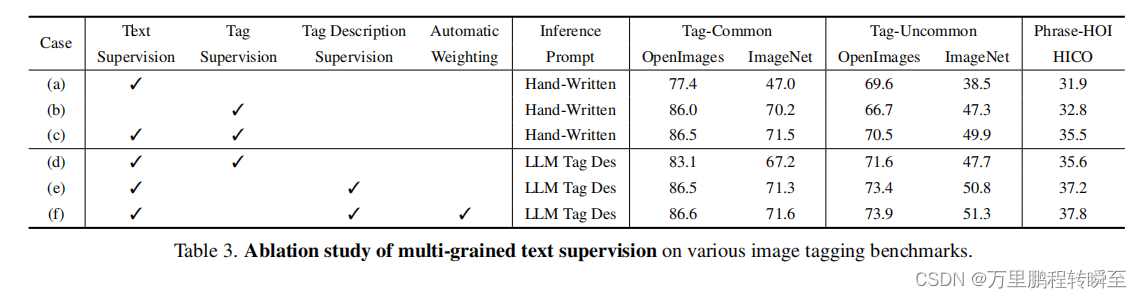
案例 © 展示了将图像-文本对齐与图像标记集成的优越性,显著提高了模型识别开放集类别的能力,对开放图像-不常见和HICO的3.8 mAP和2.7 mAP改进证明了这一点。与表2中引用的标签监督RAM模型相比,这种方法避免了在使用LLM标签描述作为推理提示时性能的急剧下降,这表明通过文本监督增强了语义概念。
案例(e)强调了在训练阶段合并LLM标签描述的有效性。当还使用标签描述进行开放集类别评估时,我们的模型记录了在OpenImage-不常见和HICO上的2.9和1.7 mAP改进。这些结果表明,在训练和推理阶段,将语义限制的标签监督扩展到广泛的描述性概念,可以对开放集标签识别产生实质性的好处。
在此基础上,case (f)揭示了对多个标签描述的自动重新加权,进一步增强了模型的能力。在第4.3节中,我们展示了我们的重新加权模块通过更具体和多样化的标签描述实现了更显著的改进。
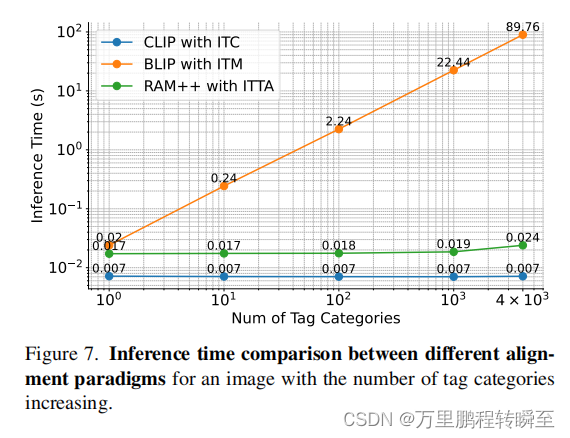
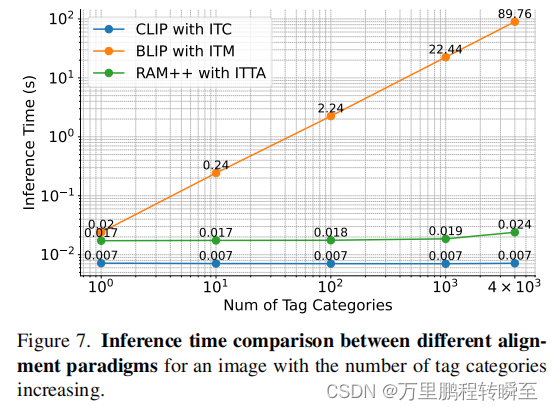
Inference Time Comparison. 图7显示了三种对齐范式的推理时间消耗的比较。这种比较利用了在A100 GPU上进行的超过1000次迭代计算的平均推理时间。从图中可以明显地看出,与单个图像-文本对对齐的ITM模型的推理时间随着类别的增加而呈指数级增长。当处理大量的标签类别时,这一趋势给模型带来了挑战。相比之下,ITC和ITTA模型保持了很高的推理效率,即使对标签类别有了大幅度的增加。例如,在识别4,000个类别的场景下,ITM模型需要86.76秒,而ITC和ITTA模型只需要0.024秒和0.007秒。
Comparison of Image Features with different granularities. 表2显示,在各种基准测试中,使用ITTA的RAM++始终优于使用ITC的CLIP。为了进一步比较不同粒度的图像特征,我们在由图像-标签-文本三联体组成的相同训练数据集下,使用对齐解码器对图像空间特征进行评估,并使用点积对图像全局特征进行评估。如表4所示,图像空间特征始终优于全局特征,特别是在开放集类别的开放图像异常图像和HICO基准测试上。这些结果突出了我们的ITTA的重要性,在细粒度对齐解码器框架中无缝地集成了图像-文本对齐和图像标记。
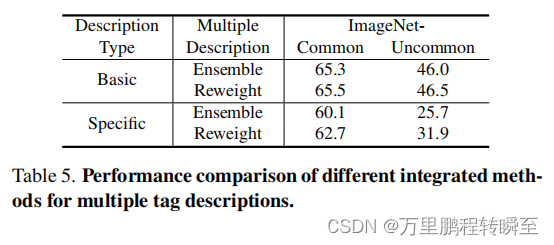
More Specific and Diverse Descriptions. 我们观察到,由温度控制的LLM描述的多样性主要局限于重新措辞,而不是提供真正的语义多样性。为了进一步验证我们提出的多重标签描述自动重新加权的有效性,我们尝试采用更具体和多样化的标签描述。具体来说,我们设计了LLM提示“描述(n) {}的50种不同的外观”来生成描述。表5说明了,我们的自动重新加权模块通过更具体和更多样化的标签描述实现了更显著的改进,因为我们提出了选择性地从相互不同的文本中学习的自由度。 不过,这些描述的质量也会明显下降,导致整体性能大大低于基本版本。
5. Conclusion
本文介绍了一种具有鲁棒泛化能力的开放集图像标记模型RAM++。通过利用多粒度的文本监督,RAM++在各种开放集类别中实现了卓越的性能。综合评估表明,RAM++在大多数方面都超过了现有的SOTA模型。鉴于llm在自然语言过程中的革命,RAM++强调,整合自然语言知识可以显著增强视觉模型。我们希望我们的努力能为其他作品提供一些灵感。



