
- 1那些年逃离北京的软件测试员,现在都怎么样了?
- 2git 笔记/常见命令/as的fetch,pull ,update project的区别/标签管理
- 3学完了python能做什么-学完Python能做什么
- 4使用scikit-learn计算文本TF-IDF值_对txt文件进行tfidf分析
- 5华为HuaweiCloudStack介绍与架构_fusionsphere openstack
- 6探索Spring Boot的自动配置机制
- 7非关系型数据库——Mongodb笔记_mongodb aggregate 突破 16m限制
- 8采用蒙特卡罗方法求解π值_用蒙特卡罗方法求解pi的值
- 9vscode 将本地项目推送到git_vscode 代码推送到git
- 10用华为模拟器ENSP编写一个电子信息学院数据中心网络及机房规划设计(路由毕业设计)(思科配置电子信息学院数据中心网络及机房规划设计也有)_用ensp做毕业设计可以拟什么题目
Linux安装、运行单机版Spark_linux运行spark3单机程序教程
赞
踩
一. 安装JDK,可参考:Linux(CentOs7)安装OpenJDK1.8。
二. 安装spark。
说明:安装单机版spark只需要安装jdk和spark就可以了,因为spark内置的有scala,可不单独安装spark依赖的scala。网上说法。
2.1 到spark官网下载Spark压缩包及解压:
官网下载地址:http://spark.apache.org/downloads.html
我下载的是最新的2.3.1版本的。
下载完成后使用工具上传到Linux服务器下,然后解压压缩包、为了操作方便改名:
- tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz
- mv spark-2.3.1-bin-hadoop2.7 spark-2.3.1
2.2 配置环境变量:
2.2.1 配置系统的环境变量:
进入/etc/profile目录下:vim /etc/profile,会提示文件已存在,输入“e”进入编辑模式即可,

然后在文件的最后加上如下配置:
- #Spark
- export SPARK_HOME=/opt/spark-2.3.1
- export PATH=$PATH:$SPARK_HOME/bin
然后键盘按下“Esc”,输入“:wq”保存退出vim编辑模式,最后:source /etc/profile 使文件修改生效。
2.2.2 配置spark的配置文件:
2.2.2.1 新建spark-env.sh配置文件(spark环境配置文件):
进入spark的conf目录下:cd /opt/spark-2.3.1/conf/,
copy一份spark-env.sh:cp spark-env.sh.template spark-env.sh
然后进入vim编辑模式:vim spark-env.sh,会提示文件已存在,输入“e”进入编辑模式即可。
在文件的最后加上如下配置:
- #export SCALA_HOME=/opt/scala-2.13.0
- export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64 #这里是你jdk的安装路径
- export SPARK_HOME=/opt/spark-2.3.1
- export SPARK_MASTER_IP=XXX.XX.XX.XXX #将这里的xxx改为自己的Linux的ip地址
- #export SPARK_EXECUTOR_MEMORY=512M
- #export SPARK_WORKER_MEMORY=1G
- #export master=spark://XXX.XX.XX.XXX:7070
最后“Esc”,输入“:wq”保存退出vim编辑模式,最后source spark-env.sh使修改生效。
2.2.2.2 新建slaves配置文件(子节点配置文件):
进入spark的conf目录下:cd /opt/spark-2.3.1/conf/,
copy一份slaves:cp slaves.template slaves
然后进入vim编辑模式:vim slaves,会提示文件已存在,输入“e”进入编辑模式即可。
在文件的最后加上如下配置:
localhost最后“Esc”,输入“:wq”保存退出vim编辑模式,最后source slaves使修改生效。
三. 启动spark。
进入spark的sbin目录:cd sbin/
启动spark集群(单机版): ./start-all.sh
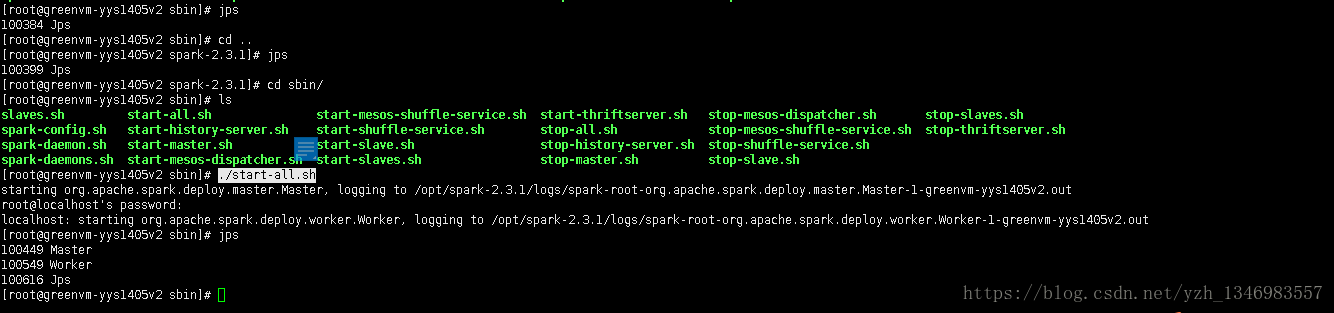
会要求你输入linux的登录密码,使用jps命令可看到运行的master和worker进程,至此,单机版spark的搭建完成。
start-all.sh命令的作用可查看文件的内容:cat start-all.sh
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
# Load the Spark configuration
. "${SPARK_HOME}/sbin/spark-config.sh"
# Start Master
"${SPARK_HOME}/sbin"/start-master.sh
# Start Workers
"${SPARK_HOME}/sbin"/start-slaves.sh
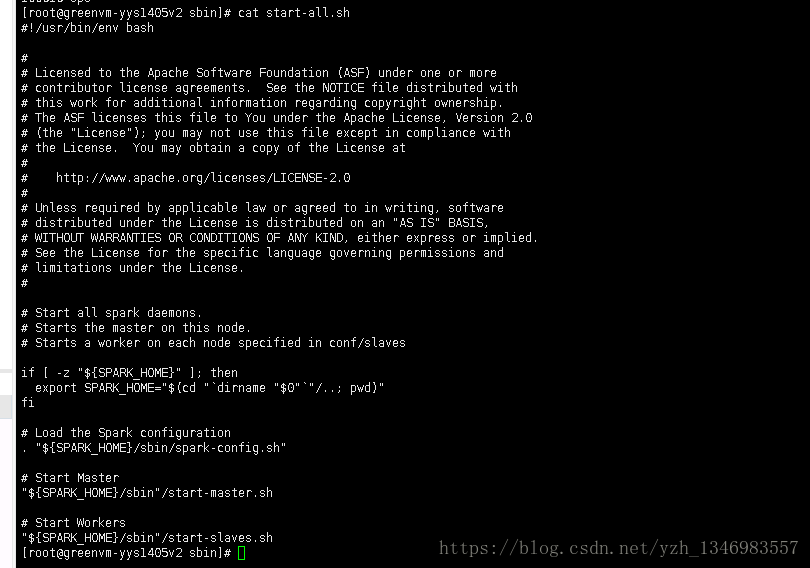
可以发现它加载了spark-config.sh配置文件,启动了集群master主节点和slaves子节点。
参考博客:https://blog.csdn.net/pucao_cug/article/details/72377219
2.3.1的官方文档:http://spark.apache.org/docs/latest/spark-standalone.html

