
热门标签
热门文章
- 110个Python爬虫入门实例,建议收藏!!_python爬虫简单例子
- 2车载芯片分类、用途、供应商_汽车芯片的种类与功能
- 3big data
- 4大数据行业包含的岗位有哪些_大数据从业人员
- 5chatgpt赋能python:Python中的模块导入:如何导入自己写的文件_怎么导入自己写的py文件
- 6Python GUI界面界面—tkinter,学习、复习、查阅,这一篇就够了_pythongui界面
- 7软件供应链安全治理探索与实践
- 8Roboguide软件:机器人工件数模、焊点数据数模导入与安装_roboguide导入三维模型
- 9六个优质开源项目,让你更了解Django框架开发_django项目
- 10UE5学习笔记|增强输入系统EnhancedInput_enhanced input
当前位置: article > 正文
Hadoop平台搭建(hive前的步骤)_hoodop环境搭建
作者:空白诗007 | 2024-07-05 18:50:44
赞
踩
hoodop环境搭建
一、Hadoop平台安装
(一)配置 Linux 系统基础环境
1.查看服务器的 IP 地址
[root@localhost ~]#
ip a
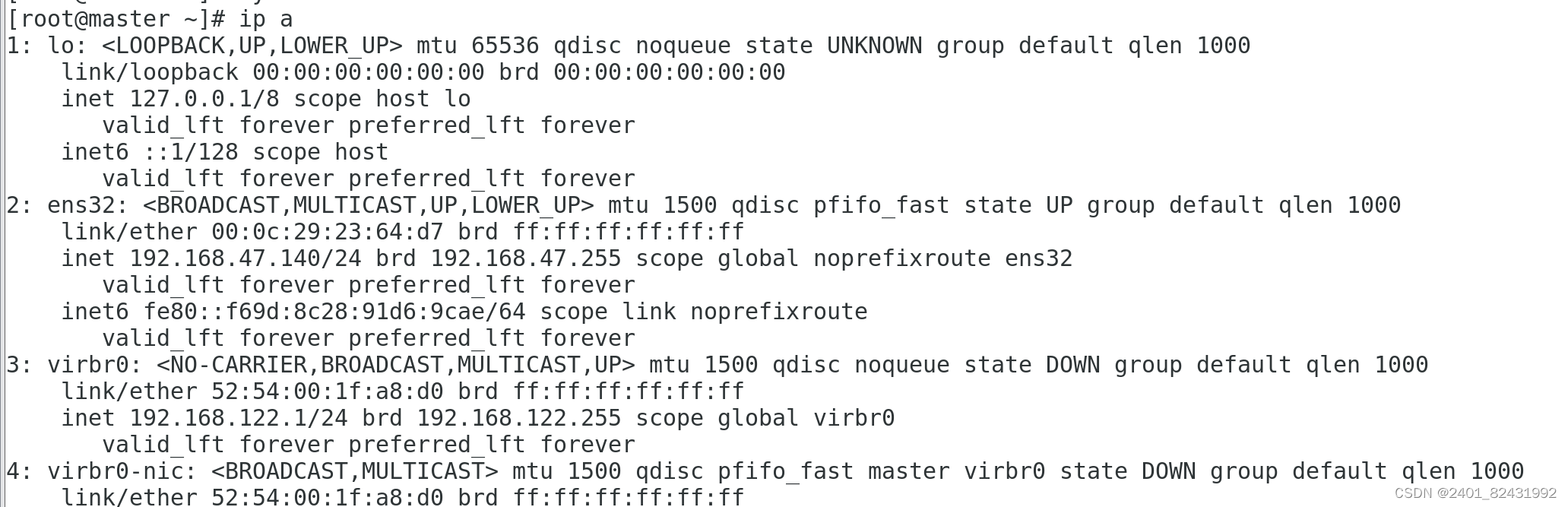
2.设置服务器的主机名称
[root@localhost ~]#
hostnamectl set-hostname master
[root@localhost ~]#
bash
[root@master ~]# hostname

3.绑定主机名与 IP 地址
[root@master ~]#
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4
localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master

4.查看 SSH 服务状态
[root@master ~]#
systemctl status sshd
● sshd.service - OpenSSH server daemon
Loaded: loaded (/usr/lib/systemd/system/sshd.service; enabled; vendor
preset: enabled)
Active:
active
(running) since
一
2021-12-20 08:22:16 CST; 10 months 21
days ago
Docs: man:sshd(8)
man:sshd_config(5)
Main PID: 1048 (sshd)
CGroup: /system.slice/sshd.service
└─1048 /usr/sbin/sshd -D
12
月
20 08:22:16 localhost.localdomain systemd[1]: Starting OpenSSH server
daemon...
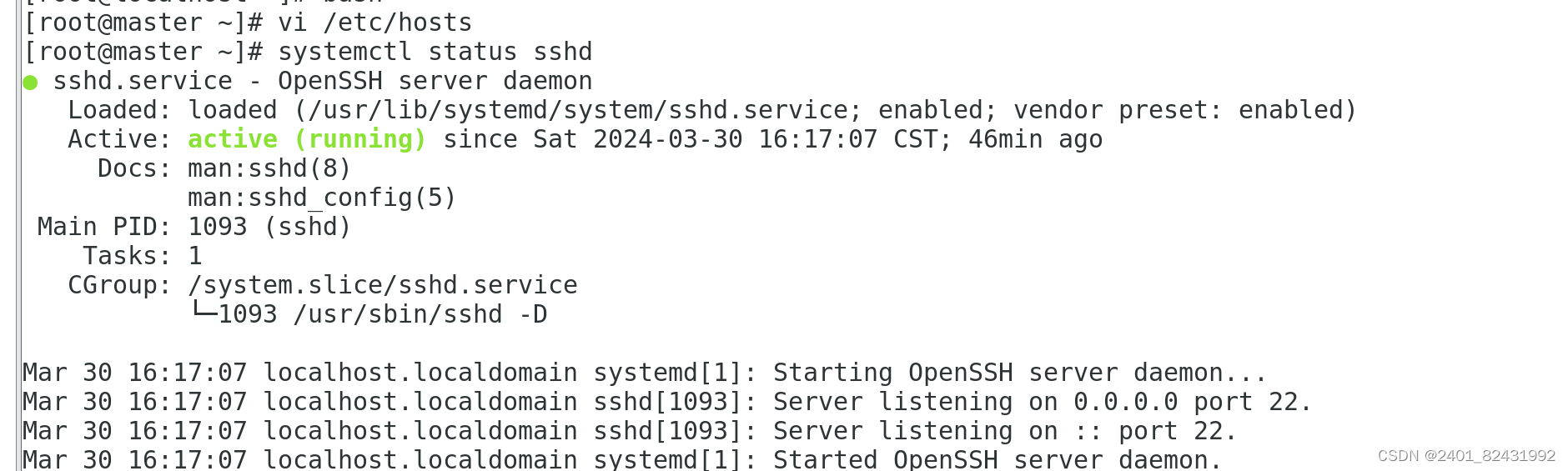
5.关闭防火墙
[root@master ~]#
systemctl stop firewalld #关闭防火墙
[root@master ~]#
systemctl status firewalld #查看防火墙的状态
[root@master ~]# systemctl disable firewalld #永久关闭防火墙
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.

6.创建 hadoop 用户
[root@master ~]#
useradd hadoop
[root@master ~]#
echo "1" |passwd --stdin hadoop
更改用户
hadoop
的密码 。
passwd
:所有的身份验证令牌已经成功更新。
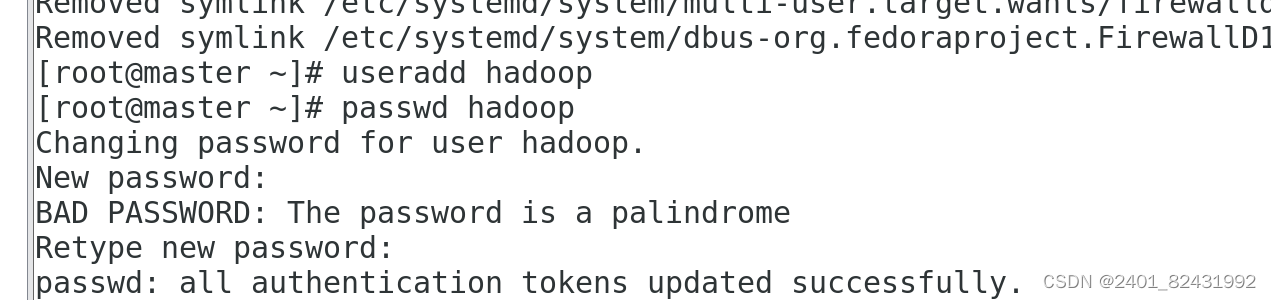
(二)安装 JAVA 环境
1.安装 JDK
将安装包解压到
/usr/local/src
目录下 ,注意
/opt/software
目录下的软件包事先准备好。
[root@master ~]#
tar -zxvf /opt/software/jdk-8u152-linux-x64.tar.gz -C
/usr/local/src/
[root@master ~]#
ls /usr/local/src/
jdk1.8.0_152
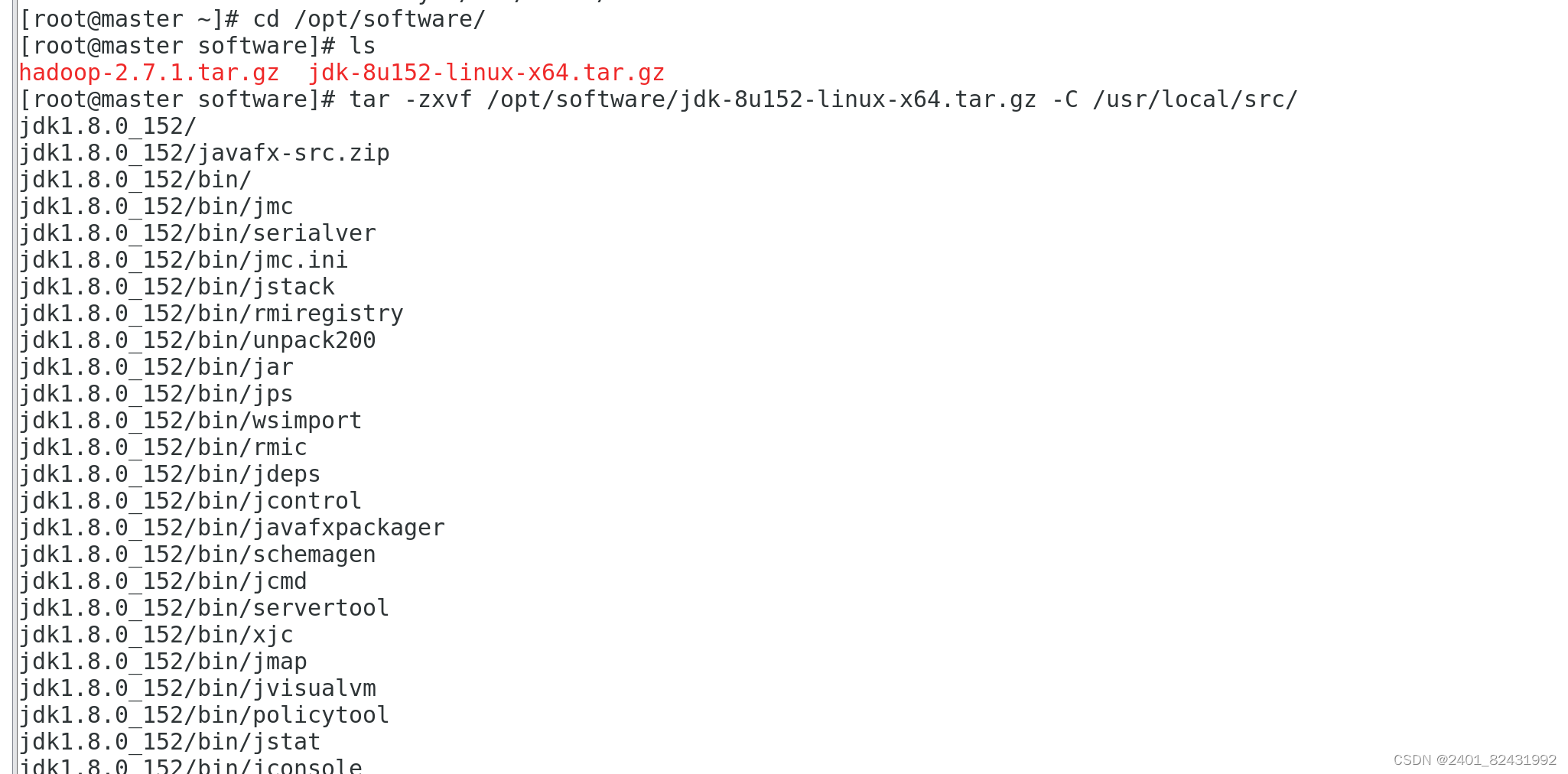
2.设置 JAVA 环境变量
[root@master ~]#
vi /etc/profile
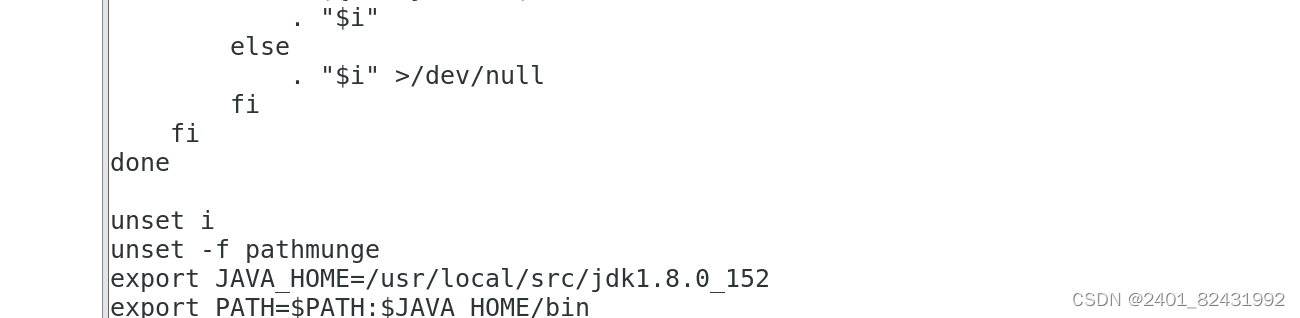
在文件的最后增加如下两行:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
执行
source
使设置生效:
[root@master ~]#
source /etc/profile
检查
JAVA
是否可用。
[root@master ~]#
echo $JAVA_HOME
/usr/local/src/jdk1.8.0_152
[root@master ~]#
java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
能够正常显示
Java
版本则说明
JDK
安装并配置成功

(三)安装 Hadoop 软件
1.安装 Hadoop 软件
将安装包解压到
/usr/local/src/
目录下
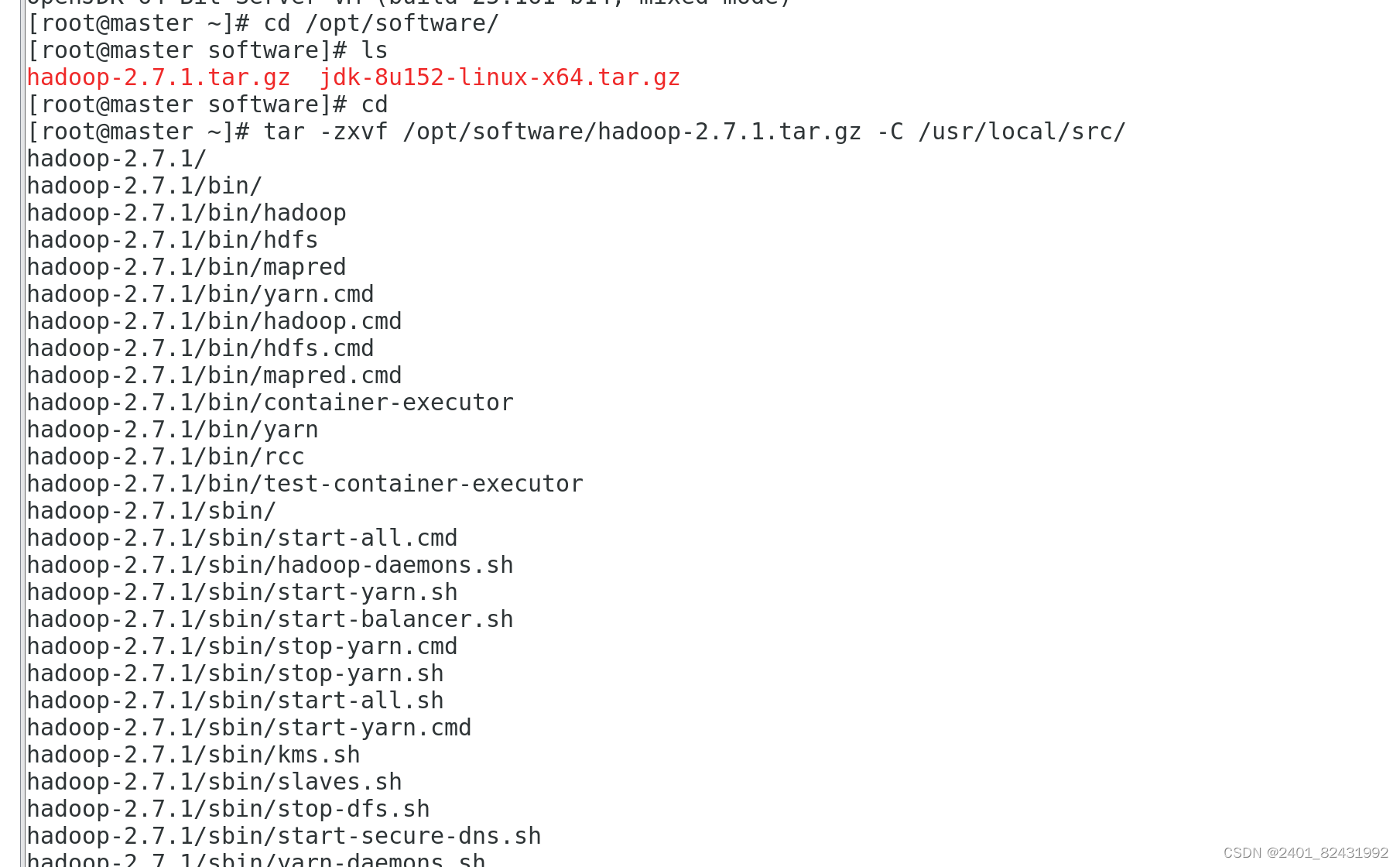
[root@master ~]#
tar -zxvf /opt/software/hadoop-2.7.1.tar.gz -C
/usr/local/src/
[root@master ~]#
ll /usr/local/src/
总用量
0
drwxr-xr-x. 9 10021 10021 149 6
月
29 2015 hadoop-2.7.1
drwxr-xr-x. 8 10 143 255 9
月
14 2017 jdk1.8.0_152
[root@master ~]# ll /usr/local/src/hadoop-2.7.1/ #查看
Hadoop
目录
总
用量
28
drwxr-xr-x. 2 10021 10021 194 6
月
29 2015 bin
drwxr-xr-x. 3 10021 10021 20 6
月
29 2015 etc
drwxr-xr-x. 2 10021 10021 106 6
月
29 2015 include
drwxr-xr-x. 3 10021 10021 20 6
月
29 2015 lib
drwxr-xr-x. 2 10021 10021 239 6
月
29 2015 libexec
-rw-r--r--. 1 10021 10021 15429 6
月
29 2015 LICENSE.txt
-rw-r--r--. 1 10021 10021 101 6
月
29 2015 NOTICE.txt
-rw-r--r--. 1 10021 10021 1366 6
月
29 2015 README.txt
drwxr-xr-x. 2 10021 10021 4096 6
月
29 2015 sbin
drwxr-xr-x. 4 10021 10021 31 6
月
29 2015 share
2.配置 Hadoop 环境变量
修改
/etc/profile
文件
[root@master ~]#
vi /etc/profile
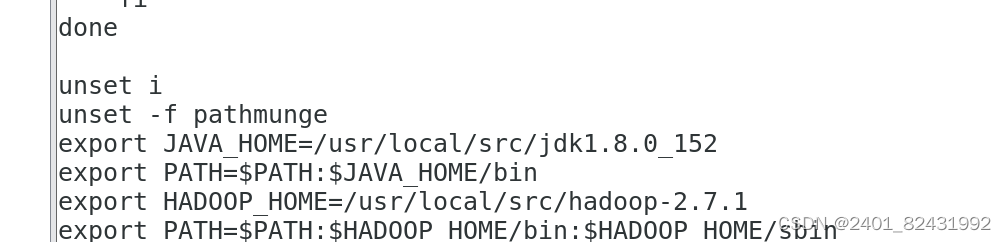
在文件的最后增加如下两行:
export HADOOP_HOME=/usr/local/src/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行
source
使用设置生效:
[root@master ~]#
source /etc/profile
检查设置是否生效:
[root@master ~]#
hadoop
3.修改目录所有者和所有者组
[root@master ~]#
chown -R hadoop:hadoop /usr/local/src/
[root@master ~]#
ll /usr/local/src/
总用量
0
drwxr-xr-x. 9 hadoop hadoop 149 6
月
29 2015 hadoop-2.7.1
drwxr-xr-x. 8 hadoop hadoop 255 9
月
14 2017 jdk1.8.0_152
/usr/local/src
目录的所有者已经改为
hadoop
了

4.配置 Hadoop 配置文件
[root@master ~]#
cd /usr/local/src/hadoop-2.7.1/
[root@master hadoop-2.7.1]#
ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@master hadoop-2.7.1]#
vi etc/hadoop/hadoop-env.sh
在文件中查找
export JAVA_HOME
这行,将其改为如下所示内容
:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152

5.测试 Hadoop 本地模式的运行
5.1切换到 hadoop 用户
使用
hadoop
这个用户来运行
Hadoop
软件。
[root@master hadoop-2.7.1]#
su - hadoop
[hadoop@master ~]$
id
uid=1001(hadoop) gid=1001(hadoop)
组
=1001(hadoop)
=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
5.2创建输入数据存放目录
将输入数据存放在
~/input
目录(
hadoop
用户主目录下的
input
目录中)。
[hadoop@master ~]$
mkdir ~/input
[hadoop@master ~]$
ls
Input

5.3创建数据输入文件
创建数据文件
data.txt
,将要测试的数据内容输入到
data.txt
文件中。
[hadoop@master ~]$
vi input/data.txt
输入如下内容,保存退出。
Hello World
Hello Hadoop
Hello Husan

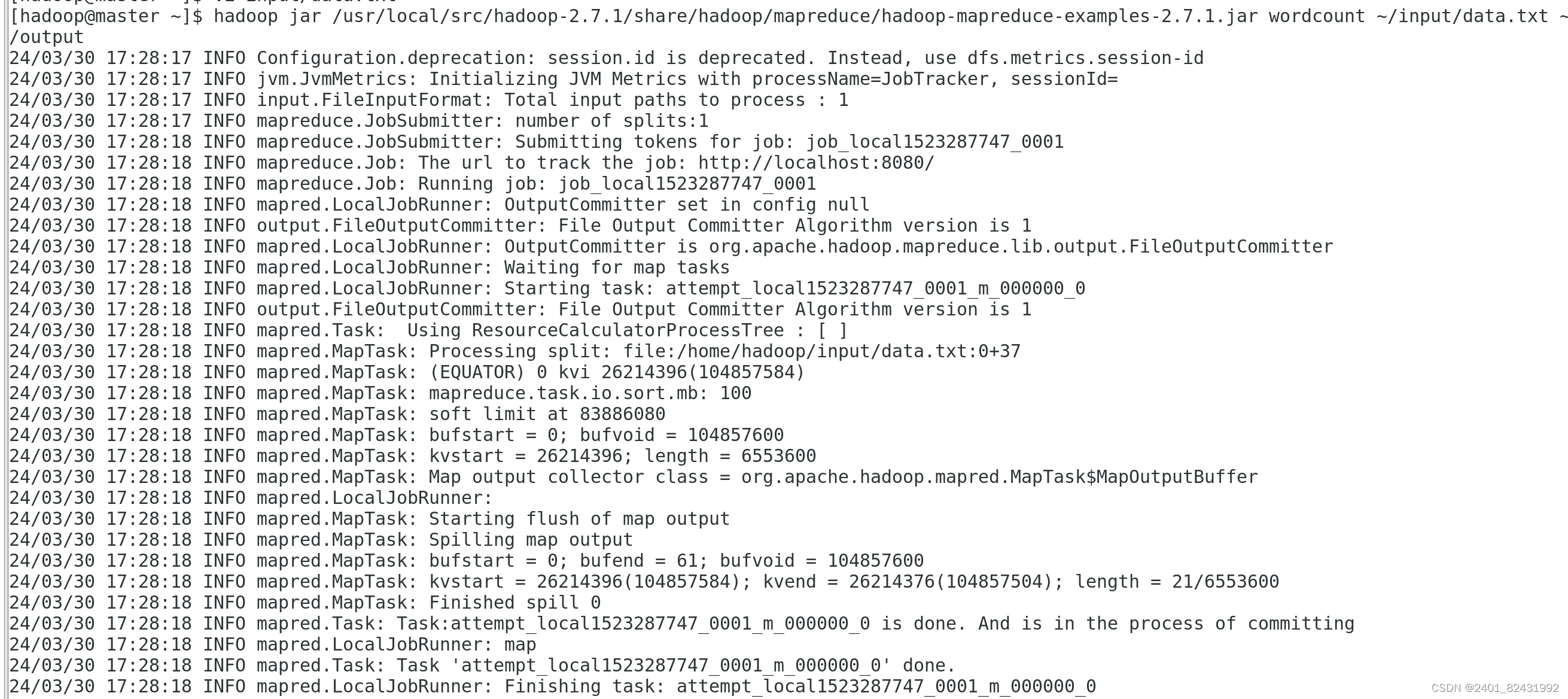
5.4测试 MapReduce 运行
[hadoop@master ~]$
hadoop jar /usr/local/src/hadoop-
2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar
wordcount ~/input/data.txt ~/output
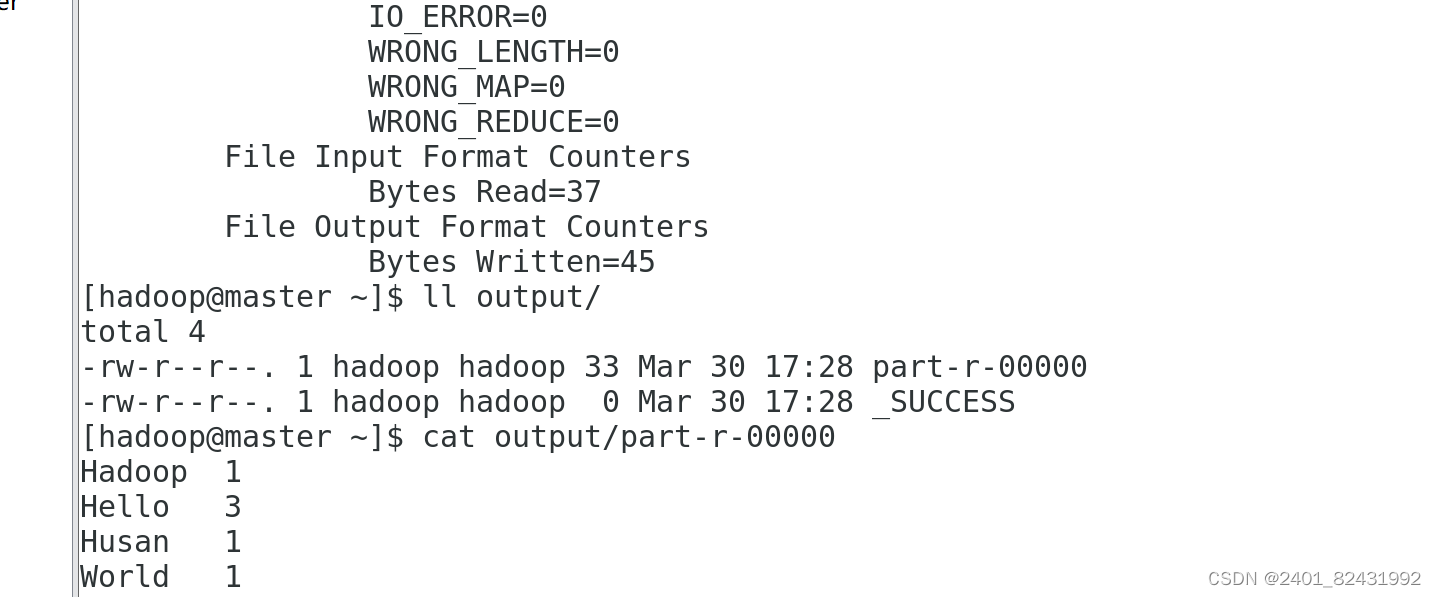
[hadoop@master ~]$
ll output/
总用量
4
-rw-r--r--. 1 hadoop hadoop 33 11
月
10 23:50 part-r-00000
-rw-r--r--. 1 hadoop hadoop 0 11
月
10 23:50 _SUCCESS
文件
_SUCCESS
表示处理成功,处理的结果存放在
part-r-00000
文件中,查看该文件。
[hadoop@master ~]$
cat output/part-r-00000
Hadoop1
Hello 3
Husan 1
World 1
可以看出统计结果正确,说明
Hadoop
本地模式运行正常。
二、Hadoop平台环境配置
(一)实验环境下集群网络配置
修改
slave1
机器主机名
[root@localhost ~]#
hostnamectl set-hostname slave1
[root@localhost ~]#
bash
[root@slave1 ~]#

修改
slave2
机器主机名
[root@localhost ~]#
hostnamectl set-hostname slave2
[root@localhost ~]#
bash

[root@slave2 ~]#
根据我们为
Hadoop
设置的主机名为
“master
、
slave1
、
slave2”
,
映
地
址
是
“192.168.
47
.
140
、
192.168.
47
.
141
、
192.168.
47
.
142
”
,分别修改主机配置文件“/etc/hosts”
[root@master ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master
192.168.47.141 slave1
192.168.47.142 slave2

[root@slave1 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master
192.168.47.141 slave1
192.168.47.142 slave2

[root@slave2 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master
192.168.47.141 slave1
192.168.47.142 slave2

(二)生成 SSH 密钥
1.每个节点安装和启动 SSH 协议
实现
SSH
登录需要
openssh
和
rsync
两个服务
[root@master ~]#
rpm -qa | grep openssh
openssh-server-7.4p1-11.el7.x86_64
openssh-7.4p1-11.el7.x86_64
openssh-clients-7.4p1-11.el7.x86_64
[root@master ~]#
rpm -qa | grep rsync
rsync-3.1.2-11.el7_9.x86_64

2.切换到 hadoop 用户
[root@master ~]#
su - hadoop
[hadoop@master ~]$

[root@slave1 ~]#
useradd hadoop
[root@slave1 ~]#
su - hadoop
[hadoop@slave1 ~]$

[root@slave2 ~]#
useradd hadoop
[root@slave2 ~]#
su - hadoop
[hadoop@slave2 ~]$

3.每个节点生成秘钥对
#
在
master
上生成密钥
[hadoop@master ~]$
ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:LOwqw+EjBHJRh9U1GdRHfbhV5+5BX+/hOHTEatwIKdU hadoop@master
The key's randomart image is:
+---[RSA 2048]----+
| ..oo. o==...o+|
| . .. . o.oE+.=|
| . . o . *+|
|o . . . . o B.+|
|o. o S * =+|
| .. . . o +oo|
|.o . . o .o|
|. * . . |
| . +. |
+----[SHA256]-----+
#slave1
生成密钥
[hadoop@slave1 ~]$
ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:RhgNGuoa3uSrRMjhPtWA5NucyhbLr9NsEZ13i01LBaA
hadoop@slave1
The key's randomart image is:
+---[RSA 2048]----+
| . . o+... |
|o .. o.o. . |
| +..oEo . . |
|+.=.+o o + |
|o*.*... S o |
|*oO. o + |
|.@oo. |
|o.o+. |
| o=o |
+----[SHA256]-----+

#slave2
生成密钥
[hadoop@slave2 ~]$
ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:yjp6AQEu2RN81Uv6y40MI/1p5WKWbVeGfB8/KK6iPUA
hadoop@slave2
The key's randomart image is:
+---[RSA 2048]----+
|.o. ... |
|.oo.. o |
|o.oo o . |
|. .. E. . |
| ... .S . . |
| oo+.. . o +. |
| o+* X +..o|
| o..o& =... .o|
| .o.o.=o+oo. .|
+----[SHA256]-----+
4.查看"/home/hadoop/"下是否有".ssh"文件夹,且".ssh"文件下是否有两个刚生产的无密码密钥对。
[hadoop@master ~]$
ls ~/.ssh/
id_rsa id_rsa.pub

5.将 id_rsa.pub 追加到授权 key 文件中
#master
[hadoop@master ~]$
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@master ~]$
ls ~/.ssh/
authorized_keys id_rsa id_rsa.pub

#slave1
[hadoop@slave1 ~]$
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@slave1 ~]$
ls ~/.ssh/
authorized_keys id_rsa id_rsa.pub

#slave2
[hadoop@slave2 ~]$
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@slave2 ~]$
ls ~/.ssh/
authorized_keys id_rsa id_rsa.pub

6.修改文件"authorized_keys"权限
#master
[hadoop@master ~]$
chmod 600 ~/.ssh/authorized_keys
[hadoop@master ~]$
ll ~/.ssh/
总用量
12
-rw-------. 1 hadoop hadoop 395 11
月
14 16:18 authorized_keys
-rw-------. 1 hadoop hadoop 1679 11
月
14 16:14 id_rsa
-rw-r--r--. 1 hadoop hadoop 395 11
月
14 16:14 id_rsa.pub

#slave1
[hadoop@slave1 ~]$
chmod 600 ~/.ssh/authorized_keys
[hadoop@slave1 ~]$
ll ~/.ssh/
总用量
12
-rw-------. 1 hadoop hadoop 395 11
月
14 16:18 authorized_keys
-rw-------. 1 hadoop hadoop 1675 11
月
14 16:14 id_rsa
-rw-r--r--. 1 hadoop hadoop 395 11
月
14 16:14 id_rsa.pub
#slave2
[hadoop@slave2 ~]$
chmod 600 ~/.ssh/authorized_keys
[hadoop@slave2 ~]$
ll ~/.ssh/
总用量
12
-rw-------. 1 hadoop hadoop 395 11
月
14 16:19 authorized_keys
-rw-------. 1 hadoop hadoop 1679 11
月
14 16:15 id_rsa
-rw-r--r--. 1 hadoop hadoop 395 11
月
14 16:15 id_rsa.pub
7.配置 SSH 服务
#master
[hadoop@master ~]$
su - root
密码:
上一次登录:一
11
月
14 15:48:10 CST 2022
从
192.168.47.1pts/1
上

[root@master ~]#
vi /etc/ssh/sshd_config
PubkeyAuthentication yes #
找到此行,并把
#
号注释删除。

#slave1
[hadoop@ slave1 ~]$
su - root
密码:
上一次登录:一
11
月
14 15:48:10 CST 2022
从
192.168.47.1pts/1
上
[root@ slave1 ~]#
vi /etc/ssh/sshd_config
PubkeyAuthentication yes #
找到此行,并把
#
号注释删除。

#slave2
[hadoop@ slave2 ~]$
su - root
密码:
上一次登录:一
11
月
14 15:48:10 CST 2022
从
192.168.47.1pts/1
上
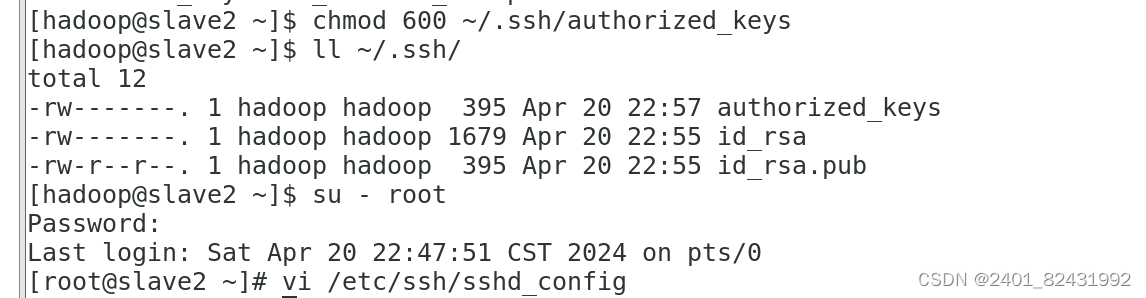
[root@ slave2 ~]#
vi /etc/ssh/sshd_config
PubkeyAuthentication yes #
找到此行,并把
#
号注释删除。

8.重启 SSH 服务
设置完后需要重启
SSH
服务,才能使配置生效。
[root@master ~]#
systemctl restart sshd

9.切换到 hadoop 用户
[root@master ~]#
su - hadoop
上一次登录:一
11
月
14 16:11:14 CST 2022pts/1
上
[hadoop@master ~]$
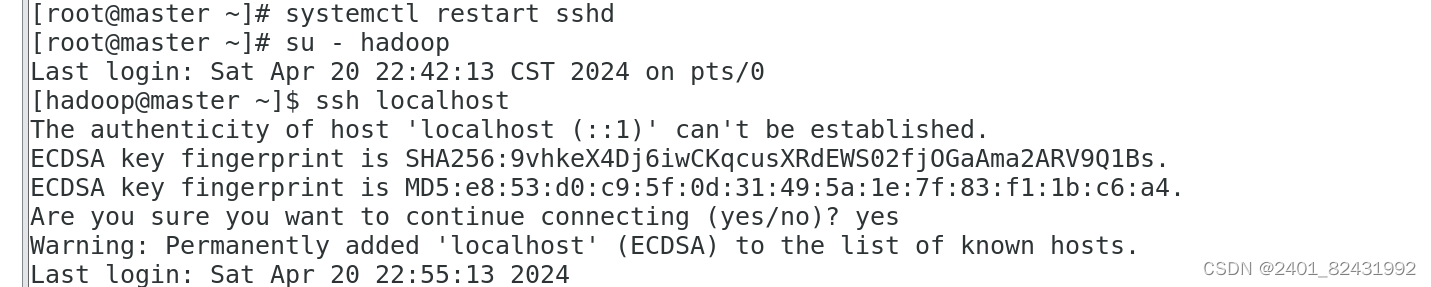
10.验证 SSH 登录本机
[hadoop@master ~]$
ssh localhost
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is
SHA256:KvO9HlwdCTJLStOxZWN7qrfRr8FJvcEw2hzWAF9b3bQ.
ECDSA key fingerprint is MD5:07:91:56:9e:0b:55:05:05:58:02:15:5e:68:db:be:73.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Last login: Mon Nov 14 16:28:30 2022
[hadoop@master ~]$
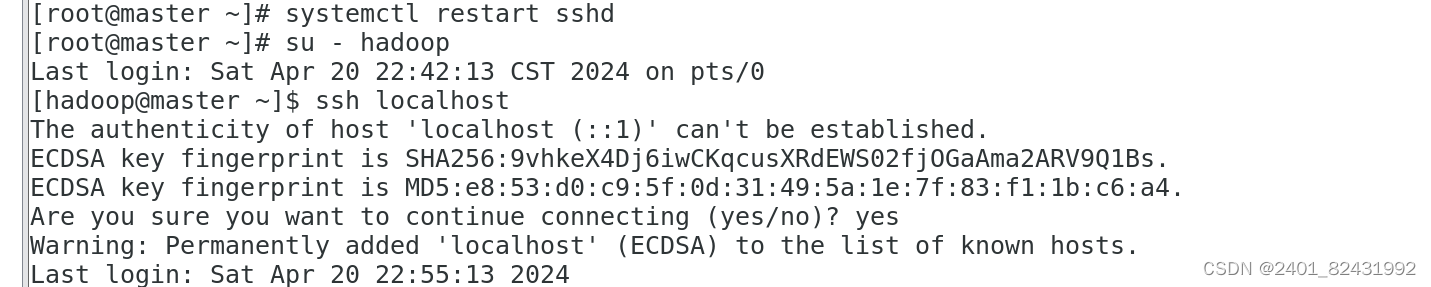
(三)交换 SSH 密钥
1.将 Master 节点的公钥 id_rsa.pub 复制到每个 Slave 点
hadoop
用户登录,通过
scp
命令实现密钥拷贝。
[hadoop@master ~]$
scp ~/.ssh/id_rsa.pub hadoop@slave1:~/
hadoop@slave1's password:
id_rsa.pub 100% 395 303.6KB/s 00:00
[hadoop@master ~]$
scp ~/.ssh/id_rsa.pub hadoop@slave2:~/
The authenticity of host 'slave2 (192.168.47.142)' can't be established.
ECDSA key fingerprint is
SHA256:KvO9HlwdCTJLStOxZWN7qrfRr8FJvcEw2hzWAF9b3bQ.
ECDSA key fingerprint is MD5:07:91:56:9e:0b:55:05:05:58:02:15:5e:68:db:be:73.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave2,192.168.47.142' (ECDSA) to the list of known
hosts.
hadoop@slave2's password:
id_rsa.pub 100% 395 131.6KB/s 00:00
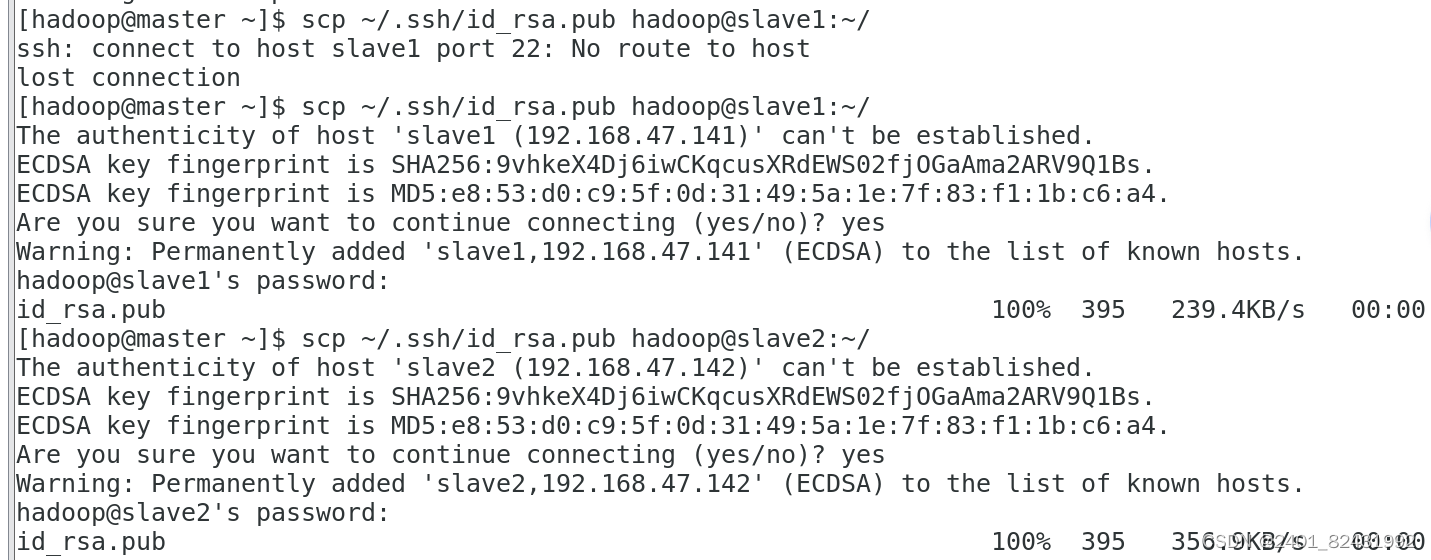
2.在每个 Slave 节点把 Master 节点复制的公钥复制到authorized_keys 文件
hadoop
用户登录
slave1
和
slave2
节点,执行命令。
[hadoop@slave1 ~]$
cat ~/id_rsa.pub >>~/.ssh/authorized_keys

[hadoop@slave2 ~]$
cat ~/id_rsa.pub >>~/.ssh/authorized_keys

3.在每个 Slave 节点删除 id_rsa.pub 文件
[hadoop@slave1 ~]$
rm -rf ~/id_rsa.pub
[hadoop@slave2 ~]$
rm -rf ~/id_rsa.pub
4.将每个 Slave 节点的公钥保存到 Master
(1)将 Slave1 节点的公钥复制到 Master
[hadoop@slave1 ~]$
scp ~/.ssh/id_rsa.pub hadoop@master:~/
The authenticity of host 'master (192.168.47.140)' can't be established.
ECDSA key fingerprint is
SHA256:KvO9HlwdCTJLStOxZWN7qrfRr8FJvcEw2hzWAF9b3bQ.
ECDSA key fingerprint is
MD5:07:91:56:9e:0b:55:05:05:58:02:15:5e:68:db:be:73.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master,192.168.47.140' (ECDSA) to the list of
known hosts.
hadoop@master's password:
id_rsa.pub 100% 395 317.8KB/s 00:00
[hadoop@slave1 ~]$

(2)将 Slave2 节点的公钥复制到 Master
[hadoop@slave2 ~]$
scp ~/.ssh/id_rsa.pub hadoop@master:~/
The authenticity of host 'master (192.168.47.140)' can't be established.
ECDSA key fingerprint is
SHA256:KvO9HlwdCTJLStOxZWN7qrfRr8FJvcEw2hzWAF9b3bQ.
ECDSA key fingerprint is MD5:07:91:56:9e:0b:55:05:05:58:02:15:5e:68:db:be:73.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master,192.168.47.140' (ECDSA) to the list of known
hosts.
hadoop@master's password:
id_rsa.pub 100% 395 326.6KB/s 00:00
[hadoop@slave2 ~]$

5.在 Master 节点把从 Slave 节点复制的公钥复制到 authorized_keys 文件
[hadoop@master ~]$
cat ~/id_rsa.pub >>~/.ssh/authorized_keys
6.在 Master 节点删除 id_rsa.pub 文件
[hadoop@master ~]$
rm -rf ~/id_rsa.pub
(四)验证 SSH 无密码登录
1.查看 Master 节点 authorized_keys 文件
[hadoop@master ~]$
cat ~/.ssh/authorized_keys
ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQDzHmpOfy7nwV1X453YY0UOZNTppiPA
9DI/vZWgWsK6hhw0pupzyxmG5LnNh7IhBlDCAKKmohOMUq9cKM3XMBq8R1f8
ys8VOPlWSKYndGxu6mbTY8wdcPWvINlAvCf2GN6rE1QJXwBAYdvZ8n5UGWqbQ
0zdqQG1uhix9FN327dCmUGozmCuCR/lY4utU3ltS3faAz7GHUCchpPTE6OopaAk9
yH5ynl+Y7BCwAWblcwf4pYoGWvQ8kMJIIr+k6cZXabsdwa3Y29OODsOsh4EfTmQ
iQbjMKpLahVrJIiL8C/6vuDX8Fh3wvgkvFgrppfzsAYNpKro27JvVgRzdKg7+/BD
hadoop@master
ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQDKUKduFzGYN41c0gFXdt3nALXhSqfgH
gmZuSjJnIlpvtQQH1IYm2S50ticwk8fr2TL/lMC/THJbuP6xoT0ZlJBPkbcEBZwkTEd
eb+0uvzUItx7viWb3oDs5s0UGtrQnrP70GszuNnitb+L+f6PRtUVVEYMKagyIpntfIC
AIP8kMRKL3qrwOJ1smtEjwURKbOMDOJHV/EiHP4l+VeVtrPnH6MG3tZbrTTCgFQ
ijSo8Hb4RGFO4NxtSHPH74YMwZBREZ7DPeZMNjqpAttQUH0leM4Ji93RQkcFoy2n
lZljhmKVKzdqazhjJ4DAgT3/FcRvF7YrULKxOHHYj/Jk0rrWwB hadoop@slave1
ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQDjlopSpw5GUvoOSiEMQG15MRUrNqsAf
NlnB/TcwDh7Xu7R1qND+StCb7rFScYI+NcDD0JkMBeXZVbQA5T21LSZlmet/38xeJ
Jy53Jx6X1bmf/XnYYf2nnUPRkAUtJeKNPDDA4TN1qnhvAdoSUZgr3uW0oV01jW5
Ai7YFYu1aSHsocmDRKFW2P8kpJZ3ASC7r7+dWFzMjT5Lu3/bjhluAPJESwV48aU2
+wftlT4oJSGTc9vb0HnBpLoZ/yfuAC1TKsccI9p2MnItUUbqI1/uVH2dgmeHwRVpq
qc1Em9hcVh0Gs0vebIGPRNx5eHTf3aIrxR4eRFSwMgF0QkcFr/+yzp
hadoop@slave2
[hadoop@master ~]$

2.查看 Slave 节点 authorized_keys 文件
[hadoop@slave1 ~]$
cat ~/.ssh/authorized_keys
ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQDKUKduFzGYN41c0gFXdt3nALXhS
qfgHgmZuSjJnIlpvtQQH1IYm2S50ticwk8fr2TL/lMC/THJbuP6xoT0ZlJBPkbcE
BZwkTEdeb+0uvzUItx7viWb3oDs5s0UGtrQnrP70GszuNnitb+L+f6PRtUVVEY
MKagyIpntfICAIP8kMRKL3qrwOJ1smtEjwURKbOMDOJHV/EiHP4l+VeVtrPnH
6MG3tZbrTTCgFQijSo8Hb4RGFO4NxtSHPH74YMwZBREZ7DPeZMNjqpAttQU
H0leM4Ji93RQkcFoy2nlZljhmKVKzdqazhjJ4DAgT3/FcRvF7YrULKxOHHYj/Jk
0rrWwB hadoop@slave1
ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQDzHmpOfy7nwV1X453YY0UOZNTp
piPA9DI/vZWgWsK6hhw0pupzyxmG5LnNh7IhBlDCAKKmohOMUq9cKM3XM
Bq8R1f8ys8VOPlWSKYndGxu6mbTY8wdcPWvINlAvCf2GN6rE1QJXwBAYdvZ
8n5UGWqbQ0zdqQG1uhix9FN327dCmUGozmCuCR/lY4utU3ltS3faAz7GHUCc
hpPTE6OopaAk9yH5ynl+Y7BCwAWblcwf4pYoGWvQ8kMJIIr+k6cZXabsdwa3
Y29OODsOsh4EfTmQiQbjMKpLahVrJIiL8C/6vuDX8Fh3wvgkvFgrppfzsAYNpK
ro27JvVgRzdKg7+/BD hadoop@master

[hadoop@slave2 ~]$
cat ~/.ssh/authorized_keys
ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQDjlopSpw5GUvoOSiEMQG15MRUrN
qsAfNlnB/TcwDh7Xu7R1qND+StCb7rFScYI+NcDD0JkMBeXZVbQA5T21LSZl
met/38xeJJy53Jx6X1bmf/XnYYf2nnUPRkAUtJeKNPDDA4TN1qnhvAdoSUZgr3
uW0oV01jW5Ai7YFYu1aSHsocmDRKFW2P8kpJZ3ASC7r7+dWFzMjT5Lu3/bj
hluAPJESwV48aU2+wftlT4oJSGTc9vb0HnBpLoZ/yfuAC1TKsccI9p2MnItUUbq
I1/uVH2dgmeHwRVpqqc1Em9hcVh0Gs0vebIGPRNx5eHTf3aIrxR4eRFSwMg
F0QkcFr/+yzp hadoop@slave2
ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQDzHmpOfy7nwV1X453YY0UOZNTp
piPA9DI/vZWgWsK6hhw0pupzyxmG5LnNh7IhBlDCAKKmohOMUq9cKM3XM
Bq8R1f8ys8VOPlWSKYndGxu6mbTY8wdcPWvINlAvCf2GN6rE1QJXwBAYdvZ
8n5UGWqbQ0zdqQG1uhix9FN327dCmUGozmCuCR/lY4utU3ltS3faAz7GHUCc
hpPTE6OopaAk9yH5ynl+Y7BCwAWblcwf4pYoGWvQ8kMJIIr+k6cZXabsdwa3
Y29OODsOsh4EfTmQiQbjMKpLahVrJIiL8C/6vuDX8Fh3wvgkvFgrppfzsAYNpK
ro27JvVgRzdKg7+/BD hadoop@master

3.验证 Master 到每个 Slave 节点无密码登录
[hadoop@master ~]$
ssh slave1
Last login: Mon Nov 14 16:34:56 2022
[hadoop@slave1 ~]$

[hadoop@master ~]$
ssh slave2
Last login: Mon Nov 14 16:49:34 2022 from 192.168.47.140
[hadoop@slave2 ~]$

4.验证两个 Slave 节点到 Master 节点无密码登录
[hadoop@slave1 ~]$
ssh master
Last login: Mon Nov 14 16:30:45 2022 from ::1
[hadoop@master ~]$
[hadoop@slave2 ~]$
ssh master
Last login: Mon Nov 14 16:50:49 2022 from 192.168.47.141
[hadoop@master ~]$

5.配置两个子节点slave1、slave2的JDK环境
[root@master ~]#
cd /usr/local/src/
[root@master src]# ls
hadoop-2.7.1 jdk1.8.0_152
[root@master src]#
scp -r jdk1.8.0_152 root@slave1:/usr/local/src/
[root@master src]#
scp -r jdk1.8.0_152 root@slave2:/usr/local/src/


#slave1
[root@slave1 ~]#
ls /usr/local/src/
jdk1.8.0_152
[root@slave1 ~]#
vi /etc/profile
#
此文件最后添加下面两行
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin

[root@slave1 ~]#
source /etc/profile
[root@slave1 ~]#
java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)

#slave2
[root@slave2 ~]#
ls /usr/local/src/
jdk1.8.0_152
[root@slave2 ~]#
vi /etc/profile
#
此文件最后添加下面两行
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
[root@slave2 ~]#
source /etc/profile
、
[root@slave2 ~]#
java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)

二、Hadoop集群运行
(一)Hadoop文件参数配置
1.在 Master 节点上安装 Hadoop
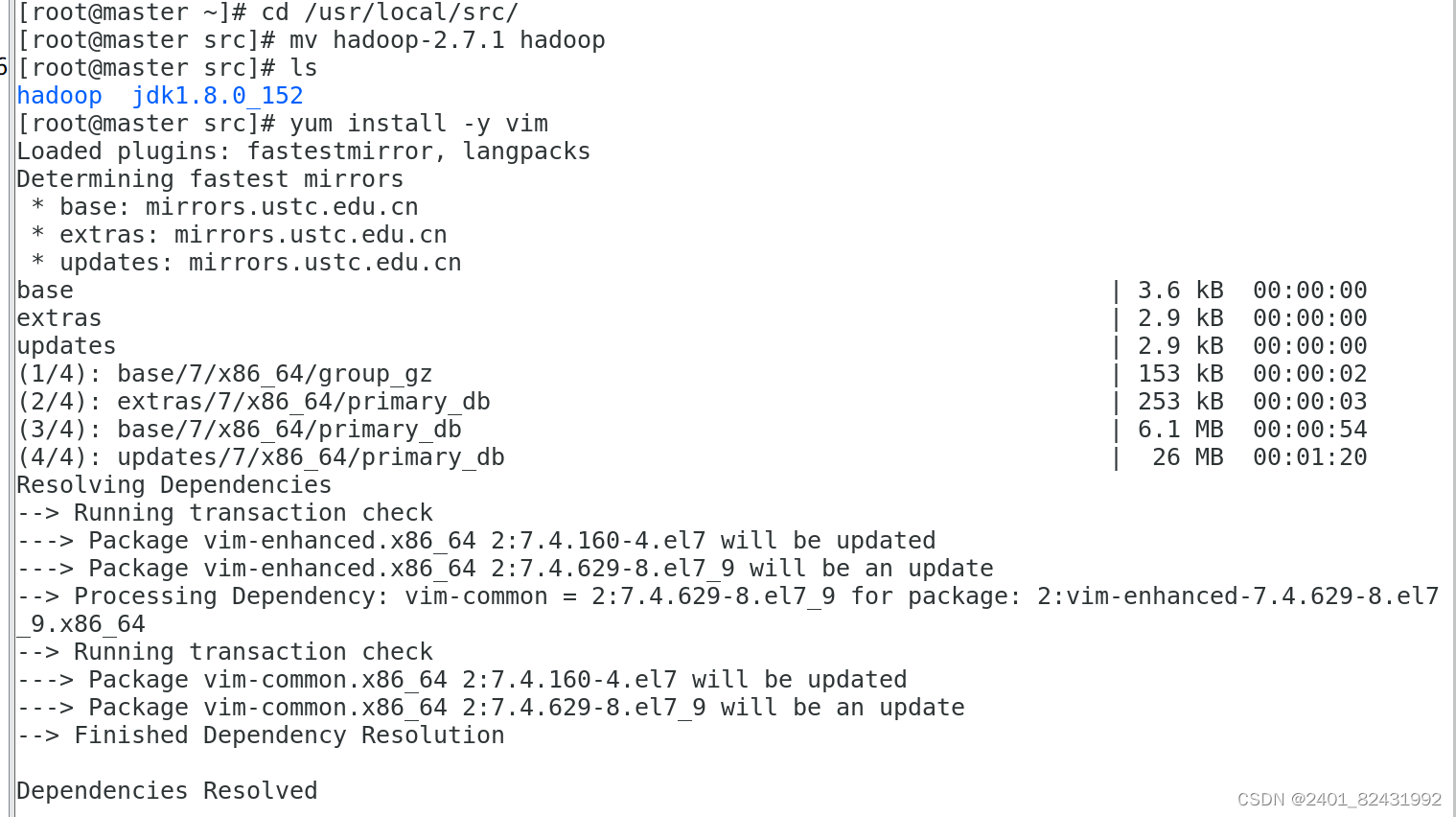
1.1. 将 hadoop-2.7.1 文件夹重命名为 Hadoop
[root@master ~]#
cd /usr/local/src/
[root@master src]#
mv hadoop-2.7.1 hadoop
[root@master src]#
ls
hadoop jdk1.8.0_152
1.2. 配置 Hadoop 环境变量
[root@master src]#
yum install -y vim
[root@master src]#
vim /etc/profile
[root@master src]#
tail -n 4 /etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

1.3. 使配置的 Hadoop 的环境变量生效
[root@master src]#
su - hadoop
上一次登录:一
2
月
28 15:55:37 CST 2022
从
192.168.41.143pts/1
上
[hadoop@master ~]$
source /etc/profile
[hadoop@master ~]$
exit

1.4. 执行以下命令修改 hadoop-env.sh 配置文件
[root@master src]#
cd /usr/local/src/hadoop/etc/hadoop/
[root@master hadoop]#
vim hadoop-env.sh #
修改以下配置
export JAVA_HOME=/usr/local/src/jdk1.8.0_152

2.配置 hdfs-site.xml 文件参数
[root@master hadoop]#
vim hdfs-site.xml #
编辑以下内容
[root@master hadoop]#
tail -n 14 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>

3.配置 core-site.xml 文件参数
[root@master hadoop]#
vim core-site.xml
#
编辑以下内容
[root@master hadoop]#
tail -n 14 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.47.140:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
</property>
</configuration>

4.配置 mapred-site.xml
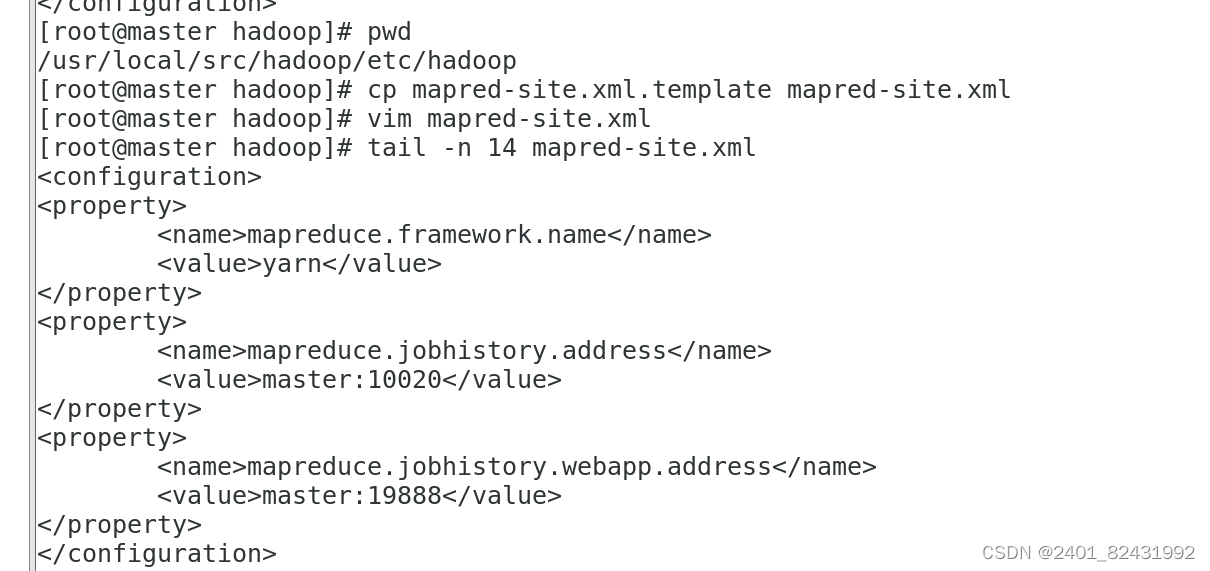
[root@master hadoop]#
pwd
/usr/local/src/hadoop/etc/hadoop
[root@master hadoop]#
cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]#
vim mapred-site.xml #
添加以下配置
[root@master hadoop]#
tail -n 14 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
5.配置 yarn-site.xml
[root@master hadoop]#
vim yarn-site.xml #
添加以下配置
[root@master hadoop]#
tail -n 32 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>

6.Hadoop 其他相关配置
6.1. 配置 masters 文件
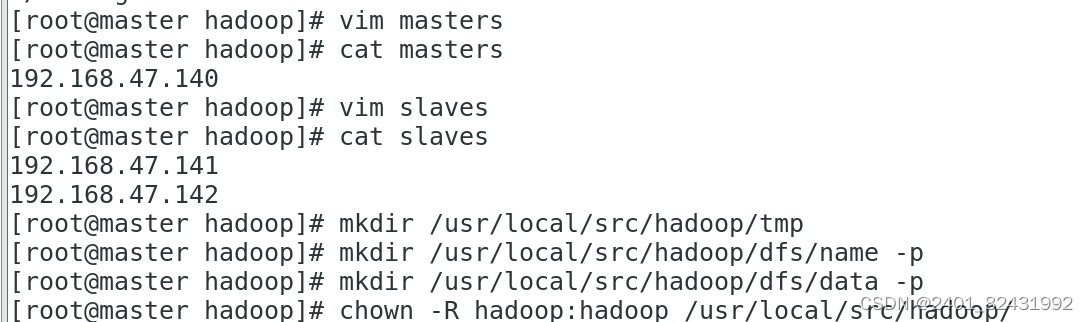
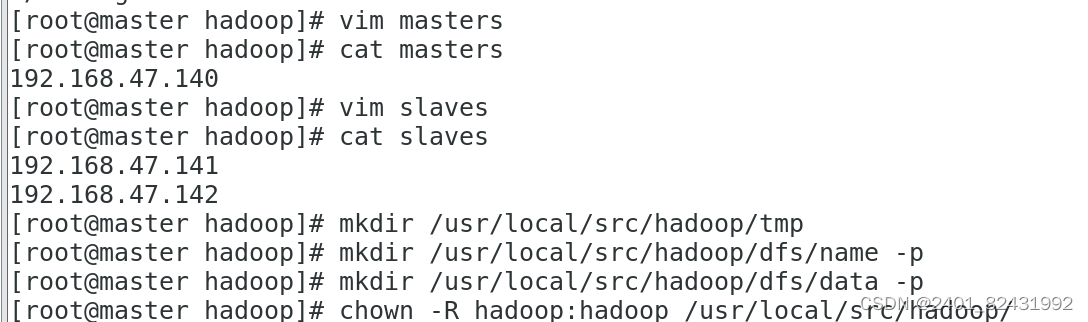
[root@master hadoop]#
vim masters
[root@master hadoop]#
cat masters
192.168.47.140
6.2. 配置 slaves 文件
[root@master hadoop]#
vim slaves
[root@master hadoop]#
cat slaves
192.168.47.141
192.168.47.142
6.3. 新建目录
[root@master hadoop]#
mkdir /usr/local/src/hadoop/tmp
[root@master hadoop]#
mkdir /usr/local/src/hadoop/dfs/name -p
[root@master hadoop]#
mkdir /usr/local/src/hadoop/dfs/data -p

6.4. 修改目录权限
[root@master hadoop]#
chown -R hadoop:hadoop /usr/local/src/hadoop/

6.5. 同步配置文件到 Slave 节点
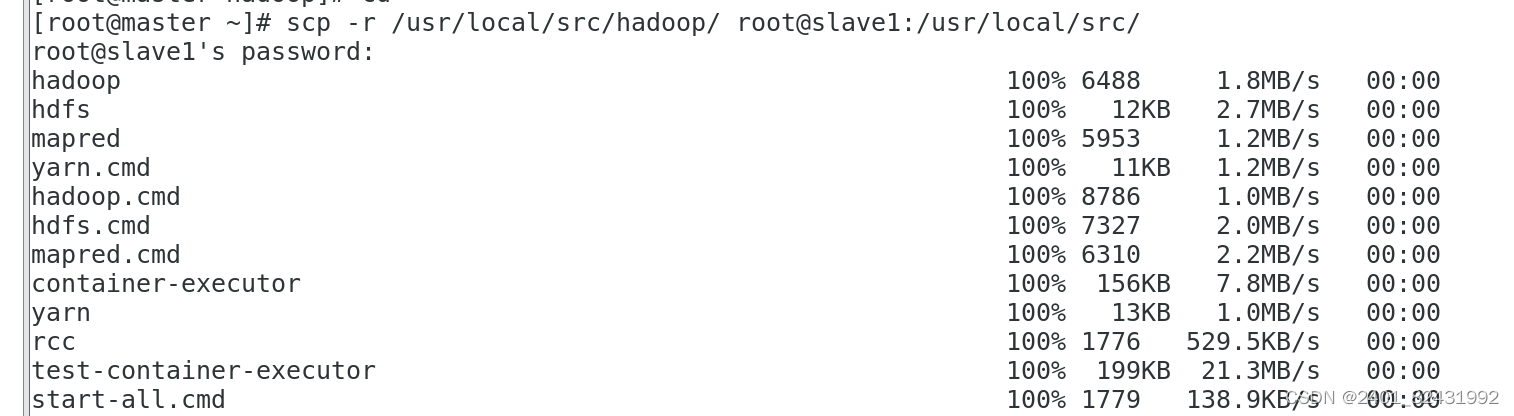
[root@master ~]#
scp -r /usr/local/src/hadoop/ root@slave1:/usr/local/src/
The authenticity of host 'slave1 (192.168.47.141)' can't be established.
ECDSA key fingerprint is SHA256:vnHclJTJVtDbeULN8jdOLhTCmqxJNqUQshH9g9LfJ3k.
ECDSA key fingerprint is MD5:31:03:3d:83:46:aa:c4:d0:c9:fc:5f:f1:cf:2d:fd:e2.
Are you sure you want to continue connecting (yes/no)? yes
* * * * * * *
[root@master ~]#
scp -r /usr/local/src/hadoop/ root@slave2:/usr/local/src/
The authenticity of host 'slave1 (192.168.47.142)' can't be established.
ECDSA key fingerprint is SHA256:vnHclJTJVtDbeULN8jdOLhTCmqxJNqUQshH9g9LfJ3k.
ECDSA key fingerprint is MD5:31:03:3d:83:46:aa:c4:d0:c9:fc:5f:f1:cf:2d:fd:e2.
Are you sure you want to continue connecting (yes/no)? yes
* * * *




#slave1
配置
[root@slave1 ~]#
yum install -y vim
[root@slave1 ~]#
vim /etc/profile
[root@slave1 ~]#
tail -n 4 /etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@slave1 ~]#
chown -R hadoop:hadoop /usr/local/src/hadoop/
[root@slave1 ~]#
su - hadoop
上一次登录:四
2
月
24 11:29:00 CST 2022
从
192.168.41.148pts/1
上
[hadoop@slave1 ~]$
source /etc/profile
#slave2
配置
[root@slave2 ~]#
yum install -y vim
[root@slave2 ~]#
vim /etc/profile
[root@slave2 ~]#
tail -n 4 /etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@slave2 ~]#
chown -R hadoop:hadoop /usr/local/src/hadoop/
[root@slave2 ~]#
su - hadoop
上一次登录:四
2
月
24 11:29:19 CST 2022
从
192.168.41.148pts/1
上
[hadoop@slave2 ~]$
source /etc/profile
(二)大数据平台集群运行
1.配置 Hadoop 格式化
1.1.NameNode 格式化
[root@master ~]#
su - hadoop
[hadoop@master ~]#
cd /usr/local/src/hadoop/
[hadoop@master hadoop]$
bin/hdfs namenode -format
1.2.启动 NameNode
[hadoop@master hadoop]$
hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop- 2.7.1/logs/hadoop-hadoop-namenode-master.out

2.查看 Java 进程
[hadoop@master hadoop]$
jps
3557 NameNode
3624 Jps

2.1.slave节点 启动 DataNode
[hadoop@slave1 hadoop]$
hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop- 2.7.1/logs/hadoop-hadoop-datanode-master.out
[hadoop@slave2 hadoop]$
hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop- 2.7.1/logs/hadoop-hadoop-datanode-master.out
[hadoop@slave1 hadoop]$
jps
3557 DataNode
3725 Jps
[hadoop@slave2 hadoop]$
jps
3557 DataNode
3725 Jps


2.2.启动 SecondaryNameNod
[hadoop@master hadoop]$
hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to /opt/module/hadoop- 2.7.1/logs/hadoop-hadoop-secondarynamenode-master.out
[hadoop@master hadoop]$
jps
34257 NameNode
34449 SecondaryNameNode
34494 Jps

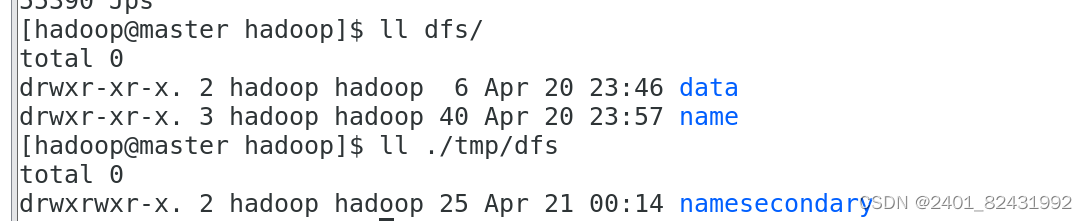
2.3.查看 HDFS 数据存放位置
[hadoop@master hadoop]$
ll dfs/
总用量
0
drwx------ 3 hadoop hadoop 21 8
月
14 15:26 data
drwxr-xr-x 3 hadoop hadoop 40 8
月
14 14:57 name
[hadoop@master hadoop]$
ll ./tmp/dfs
总用量
0
drwxrwxr-x. 3 hadoop hadoop 21 5
月
2 16:34 namesecondary
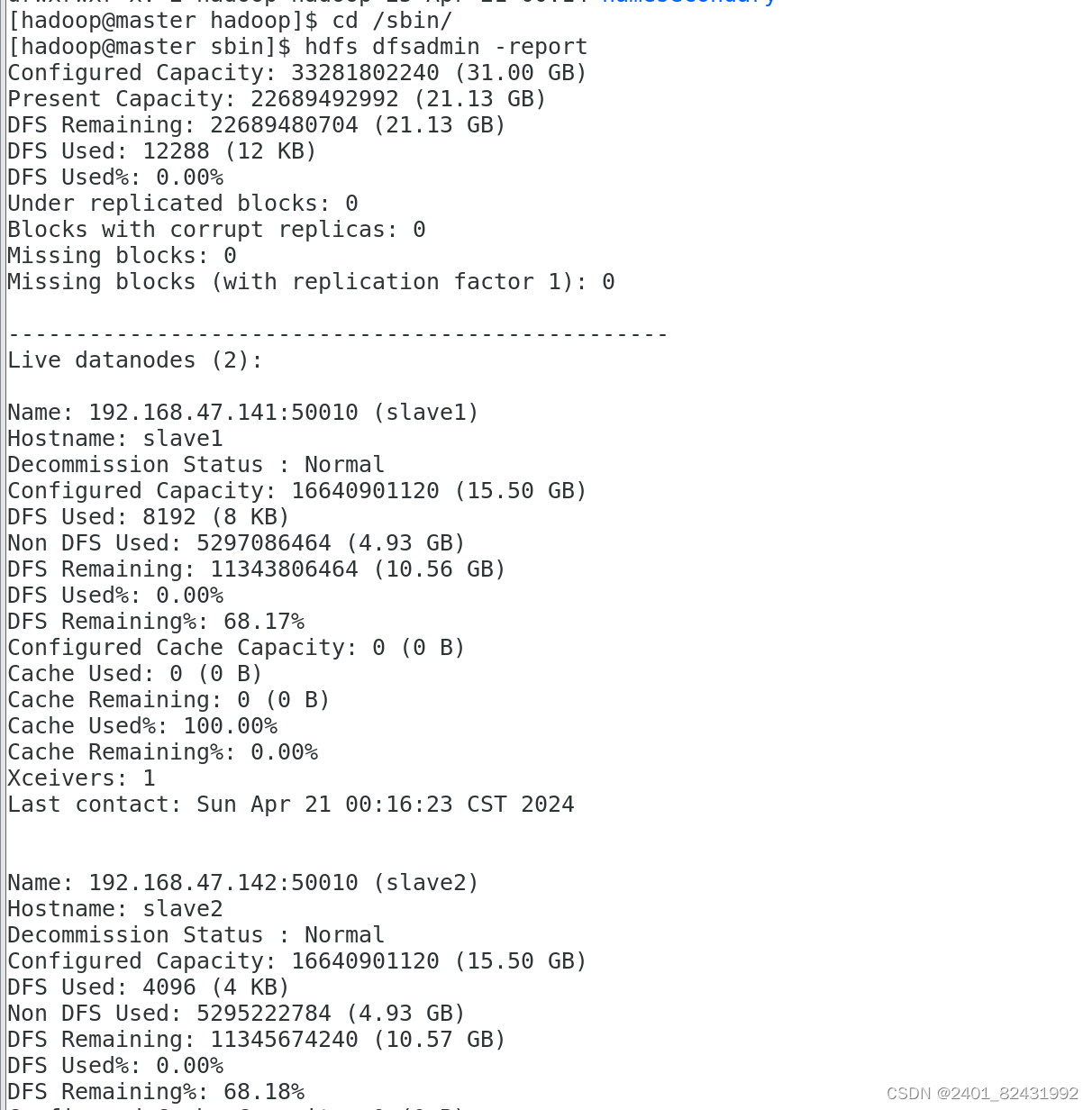
3.查看 HDFS 的报告
[hadoop@master sbin]$
hdfs dfsadmin -report
4.使用浏览器查看节点状态
在浏览器的地址栏输入
http://master:50070
,进入页面可以查看
NameNode
和
DataNode信息

在浏览器的地址栏输入
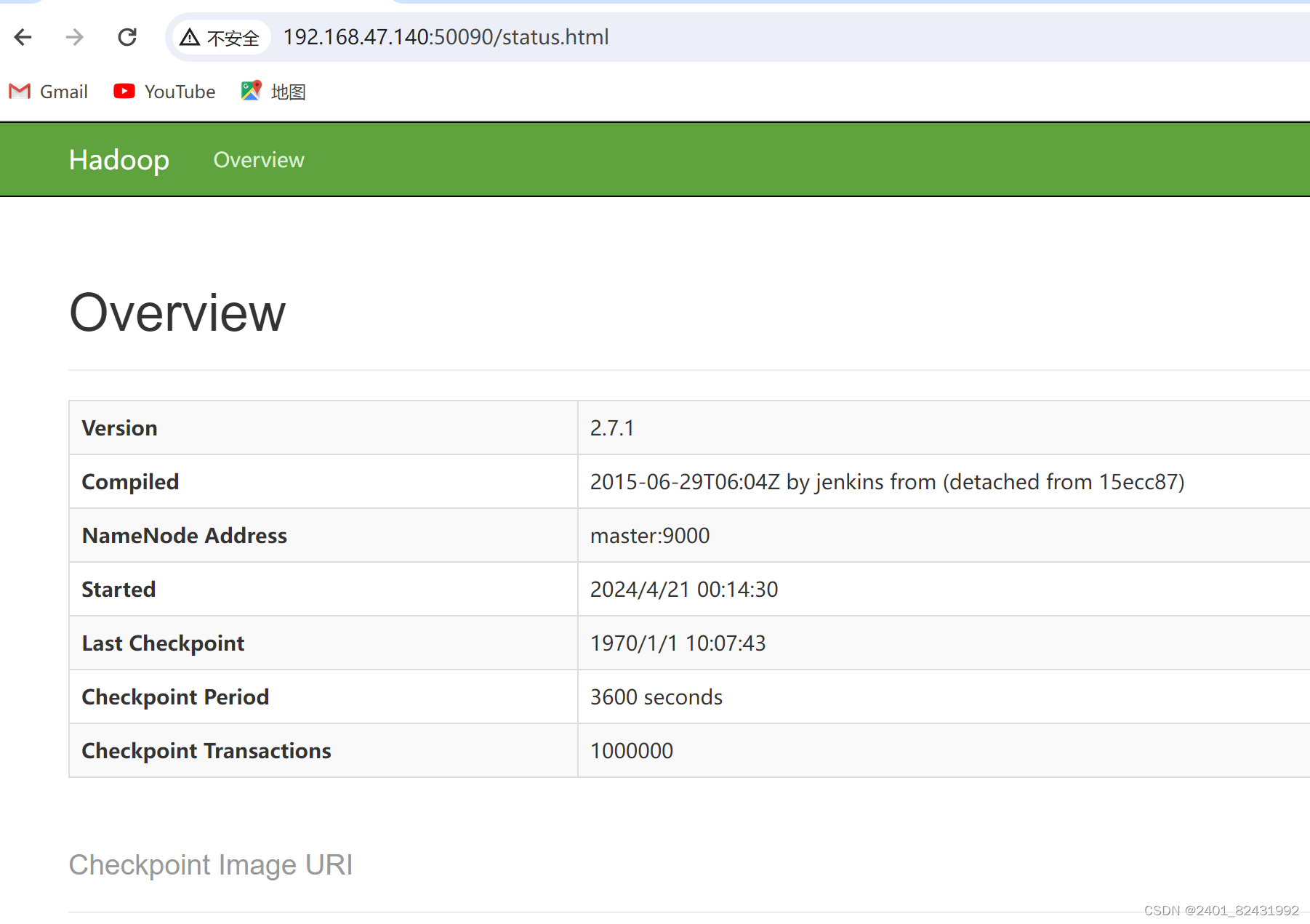
http://master:50090
,进入页面可以查看 SecondaryNameNode信息
[hadoop@master hadoop]$
stop-dfs.sh
[hadoop@master hadoop]$
start-dfs.sh
4.1.在 HDFS 文件系统中创建数据输入目录
确保
dfs
和
yarn
都启动成功
[hadoop@master hadoop]$
start-yarn.sh
[hadoop@master hadoop]$
jps
34257 NameNode
34449 SecondaryNameNode
34494 Jps
32847 ResourceManager
[hadoop@master hadoop]$
hdfs dfs -mkdir /input
[hadoop@master hadoop]$
hdfs dfs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2020-05-02 22:26 /input

此处创建的
/input
目录是在
HDFS
文件系统中,只能用
HDFS
命令查看和操作。
4.2.将输入数据文件复制到 HDFS 的/input 目录中
[hadoop@master hadoop]$
cat ~/input/data.txt
Hello World
Hello Hadoop
Hello Huasan
将输入数据文件复制到
HDFS
的
/input
目录中:
[hadoop@master hadoop]$
hdfs dfs -put ~/input/data.txt /input
确认文件已复制到
HDFS
的
/input
目录:
[hadoop@master hadoop]$
hdfs dfs -ls /input
Found 1 items
-rw-r--r-- 1 hadoop supergroup 38 2020-05-02 22:32 /input/data.txt

4.3.运行WordCount 案例,计算数据文件中各单词的频度
[hadoop@master hadoop]$
hdfs dfs -mkdir /output
先执行如下命令查看
HDFS
中的文件:
[hadoop@master hadoop]$
hdfs dfs -ls /
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2020-05-02 22:32 /input
drwxr-xr-x - hadoop supergroup 0 2020-05-02 22:49 /out

[hadoop@master hadoop]$ hadoop jar share/hadoop/mapreduce/hado
op
-
mapreduce-examples-2.7.1.jar wordcount /input/data.txt /output
在浏览器的地址栏输入:http://master:8088

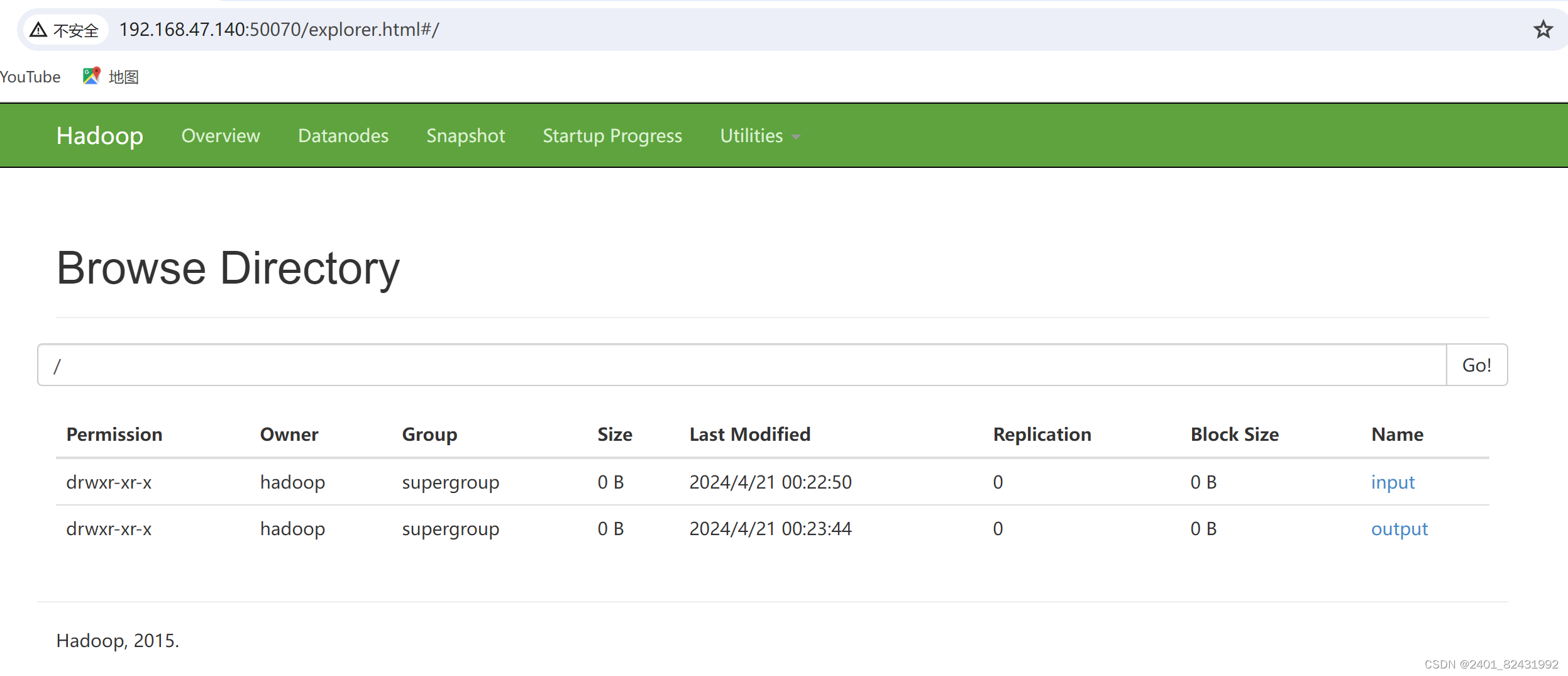
在浏览器的地址栏输入
http://master:50070
,进入页面,在
Utilities
菜单中 选择 Browse the file system
,可以查看
HDFS 文件系统内容。
5.停止 Hadoop
5.1.停止 yarn
[hadoop@master hadoop]$
stop-yarn.sh

5.2.停止 DataNode
[hadoop@slave1 hadoop]$
hadoop-daemon.sh stop datanode
stopping namenode
[hadoop@slave2 hadoop]$
hadoop-daemon.sh stop datanode
stopping namenode


5.3. 停止 NameNode
[hadoop@master hadoop]$
hadoop-daemon.sh stop namenode
stopping namenode

5.4. 停止 SecondaryNameNode
[hadoop@master hadoop]$
hadoop-daemon.sh stop secondarynamenode
stopping secondarynamenode

5.5. 查看 JAVA 进程,确认 HDFS 进程已全部关闭
[hadoop@master hadoop]$
jps
3528 Jps

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/空白诗007/article/detail/790741
推荐阅读
相关标签

