
- 1VUE项目安全漏洞扫描和修复
- 2Oracle数据库中触发器包含dblink_blob dblink 触发
- 3博奥机械制造有限公司诚邀您参观2024第13届生物发酵展
- 4华为OD面试_华为od非目标院校多少分过笔试
- 5TMDB电影数据分析(下)_基于 tmdb 数据集的电影数据分析
- 6【2024最新华为OD-C卷试题汇总】传递悄悄话的最长时间(100分) - 三语言AC题解(Python/Java/Cpp)_传递悄悄话java
- 7java并查集找朋友圈_并查集、及并查集解决常见朋友圈等问题!
- 8Cent OS 7 安装 opencv-4.6.0_centos opencv
- 9kaggle和colab入门_kaggle联机跑代码需要联网吗
- 10若依vue 整合echart_ruoyi-vue echart map.vue
智谱AI GLM4开源!快速上手体验_glm4-9b
赞
踩
目录
前言
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出较高的性能。GLM-4-9B 模型具备了更强大的推理性能、更长的上下文处理能力、多语言、多模态和 All Tools 等突出能力。GLM-4-9B 系列模型包括:基础版本 GLM-4-9B(8K)、对话版本 GLM-4-9B-Chat(128K)、超长上下文版本 GLM-4-9B-Chat-1M(1M)和多模态版本 GLM-4V-9B-Chat(8K)。

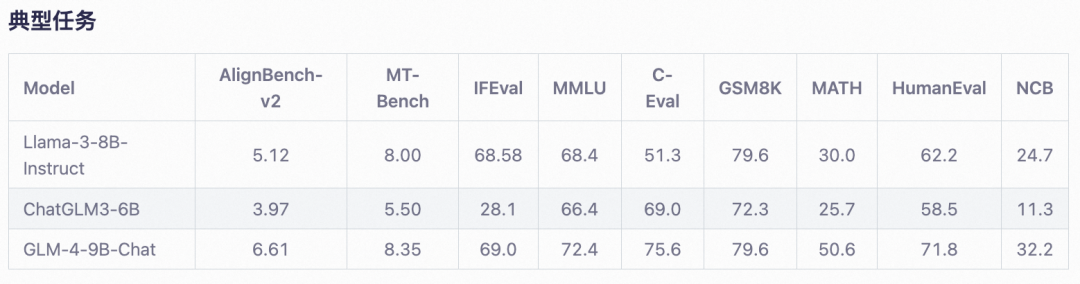
如下为GLM-4-9B-Chat模型的经典任务评测结果:
在线体验
魔搭社区使用自研开源的推理加速引擎dash-infer也转换了模型格式,支持在CPU上运行,并搭建了体验链接
魔搭社区汇聚各领域最先进的机器学习模型,提供模型探索体验、推理、训练、部署和应用的一站式服务。![]() https://modelscope.cn/studios/dash-infer/GLM-4-Chat-DashInfer-Demo同时创空间体验也支持vLLM推理,体验链接:
https://modelscope.cn/studios/dash-infer/GLM-4-Chat-DashInfer-Demo同时创空间体验也支持vLLM推理,体验链接:
效果体验
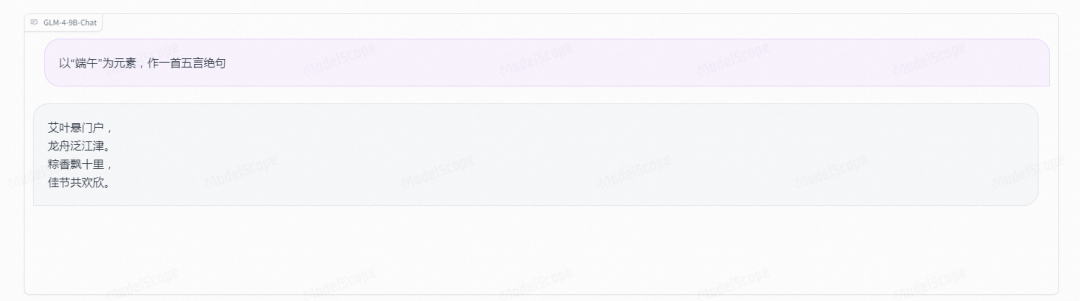
语义创作:
数学:
<计算题>

<应用题>

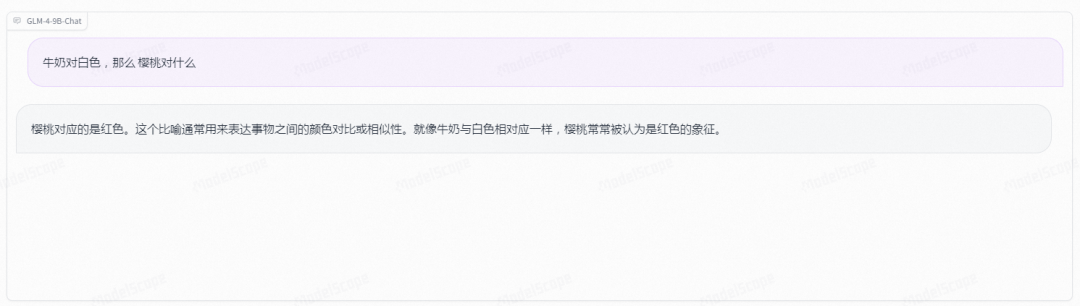
推理:
模型链接及下载
GLM-4-9B-Chat
模型链接:
https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat/summary
GLM-4-9B-Chat-1M
模型链接:
https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat-1m/summary
glm-4-9b
模型链接:
https://modelscope.cn/models/ZhipuAI/glm-4-9b/summary
glm-4v-9b
模型链接:
https://modelscope.cn/models/ZhipuAI/glm-4v-9b/summary
模型weights下载
-
- from modelscope import snapshot_download
- model_dir = snapshot_download("ZhipuAI/glm-4-9b-chat")
模型推理
使用Transformers 大语言模型推理代码
- import torch
- from modelscope import AutoModelForCausalLM, AutoTokenizer
-
- device = "cuda"
-
- tokenizer = AutoTokenizer.from_pretrained("ZhipuAI/glm-4-9b-chat",trust_remote_code=True)
-
- query = "你好"
-
- inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
- add_generation_prompt=True,
- tokenize=True,
- return_tensors="pt",
- return_dict=True
- )
-
- inputs = inputs.to(device)
- model = AutoModelForCausalLM.from_pretrained(
- "ZhipuAI/glm-4-9b-chat",
- torch_dtype=torch.bfloat16,
- low_cpu_mem_usage=True,
- trust_remote_code=True
- ).to(device).eval()
-
- gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
- with torch.no_grad():
- outputs = model.generate(**inputs, **gen_kwargs)
- outputs = outputs[:, inputs['input_ids'].shape[1]:]
- print(tokenizer.decode(outputs[0], skip_special_tokens=True))
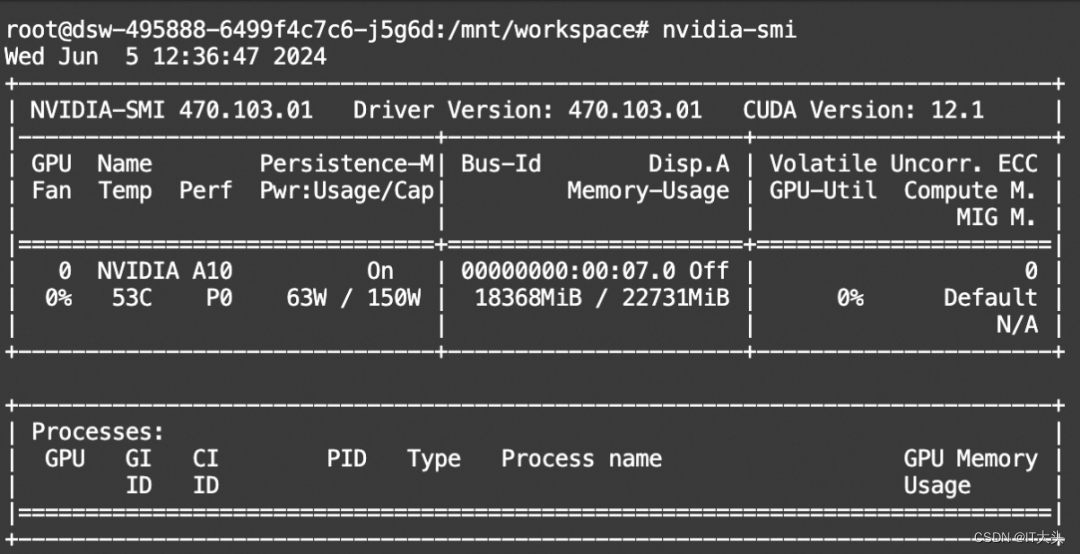
显存占用:
多模态模型推理代码
-
- import torch
- from PIL import Image
- from modelscope import AutoModelForCausalLM, AutoTokenizer
-
- device = "cuda"
-
- tokenizer = AutoTokenizer.from_pretrained("ZhipuAI/glm-4v-9b", trust_remote_code=True)
-
- query = '这样图片里面有几朵花?'
- image = Image.open("/mnt/workspace/玫瑰.jpeg").convert('RGB')
- inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": "这样图片里面有几朵花?"}],
- add_generation_prompt=True, tokenize=True, return_tensors="pt",
- return_dict=True) # chat mode
-
- inputs = inputs.to(device)
- model = AutoModelForCausalLM.from_pretrained(
- "ZhipuAI/glm-4v-9b",
- torch_dtype=torch.bfloat16,
- low_cpu_mem_usage=True,
- trust_remote_code=True
- ).to(device).eval()
-
- gen_kwargs = {"max_length": 500, "do_sample": True, "top_k": 1}
- with torch.no_grad():
- outputs = model.generate(**inputs, **gen_kwargs)
- outputs = outputs[:, inputs['input_ids'].shape[1]:]
- print(tokenizer.decode(outputs[0]))
使用vLLM推理
-
- from modelscope import AutoTokenizer
- from vllm import LLM, SamplingParams
- from modelscope import snapshot_download
- # GLM-4-9B-Chat
- max_model_len, tp_size = 131072, 1
- model_name = snapshot_download("ZhipuAI/glm-4-9b-chat")
- prompt = '你好'
-
- tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
- llm = LLM(
- model=model_name,
- tensor_parallel_size=tp_size,
- max_model_len=max_model_len,
- trust_remote_code=True,
- enforce_eager=True,
- )
- stop_token_ids = [151329, 151336, 151338]
- sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
-
- inputs = tokenizer.apply_chat_template([{'role': 'user', 'content': prompt}], add_generation_prompt=True)[0]
- outputs = llm.generate(prompt_token_ids=[inputs], sampling_params=sampling_params)
-
- generated_text = [output.outputs[0].text for output in outputs]
- print(generated_text)

