本专题的内容结构:
第一部分主要是:如何编写Python第三方库(包和模块)
第二部分主要是:如何编写带有c语言扩展的Python第三方库(包和模块)
第一部分的结构:
unit1:深入理解Python库:
(1),库,模块和包
(2),模块的命名空间
(3),包的命名空间
(4),模块的名称属性
unit2:模块和包的构建:
(1),模块的构建
(2),常规包的构建
(3),命名空间包的构建
unit3:实例1:矩阵乘法模块的构建
(1),矩阵乘法运算
(2),模块构造方法实践
unit4:深入立即import系统
(1),import系统
(2),模块对象
(3),模块的查找和加载
unit5:Python第三方库的发布:
(1),发布前的准备和发布概念
(2),第三方库的发布流程
第二部分的结构:
unit1:c语言精简概述:
(1),c语言概述,语法及实例
(2),c编辑环境配置
unit2:Python与C的交互方法:
(1),Python的扩展方法
(2),Python的嵌入方法
(3),Python的调用方法
unit3:Python扩展的CFFI 方法
(1),CFFI的功能接口
(2),CFFI 库的应用
unit4:实例2:矩阵乘法的c语言加速
(1),c语言加速文件组织结构及示例
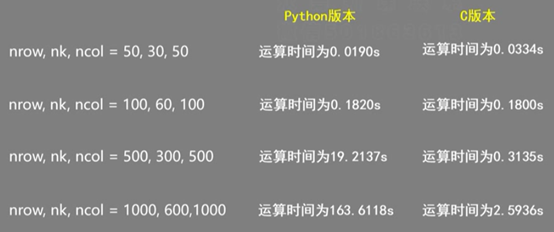
(2),Python和c性能比较
第一部分的内容:
unit1:深入理解Python库:
(1),库,模块和包:
库: Library :一种对特定功能集合的通俗“说法”
它只是通俗说法,不是语法元素
>包含一些程序功能,通过import 引入使用,对应模块和包
>标准库:Standard Library ,与Python解释器一同安装的库
>第三方库:Third-Party Library ,需要额外安装的库
模块:Module: 以单个文件为命名空间的代码片段
简单说模块也是语法元素
>模块是一个单独的.py 文件,模块名就是文件名
>模块本质上是一个独立的,由模块名组织的命名空间
>模块中可以引入其他模块,并由一些Python语法来约束和管理
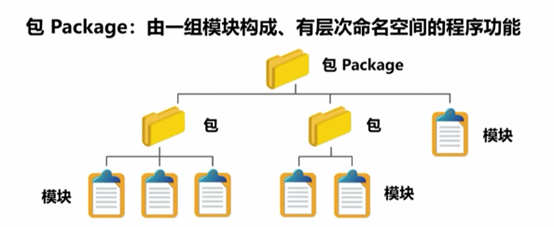
包:Package :由一组模块构成,有层次命名空间的程序功能
>包由多个模块(多个.py 文件)有组织的构成
>模块的组织方式构成了命名空间的层次结构
>包是模块的上一级组织概念,其中可以包括子包
模块是一切库的基础单元:
>包由模块构成,可以理解为:包是目录,模块是.py文件
>库是通俗的说法,具体指Python的模块和包
>Python库的核心是 模块 及 模块的组织方式 (体现为命名空间)
(2),模块的命名空间:
模块是一个命名空间
>模块对应单独的.py 文件,它是一个独立的命名空间
>模块内可能包含:类,函数,语句(直接可执行),变量等元素
>模块内还包括一些其他对模块进行约束和管理的语法元素
例子:
在m.py 文件中:
module_var = 1 #全局变量
class module_class: #全局类
mc_classattr = 1
def __init__(self,mc_instattr = 1):
self.mc_instattr = mc_instattr
def mc_func(self):
return "Method with a count of {}".format(self.mc_classattr)
def module_func(): #全局函数
print("Module Function")
print("Moudle Statement") #全局语句
那么m.py 就是模块
那么在使用m模块的时候:
1, <模块名>.<名称> :访问模块内顶层命名空间的变量,类和函数
import m # 这时会执行一遍m.py ,所以会打印 Module Statement
print(m.module_var)
mc = m.module_calss(99)
print(mc.mc_func())
m.module_func()
2,from m import * 将所有的顶层的东西加载到当前模块中
from m import * #仍然打印Moudule Statement
print(module_var)
mc= module_class(99)
print(mc.mc_func())
module_func()
扩展: m.py 文件如下:
_module_var = 1 #前加_
class _module_class: #前加_
mc_classattr = 1
def __init__(self,mc_instattr = 1):
self.mc_instattr = mc_instattr
def mc_func(self):
return "Method with a count of {}".format(self.mc_classattr)
def _module_func(): #前加_
print("Module Function")
print("Moudle Statement")
如果用上面第一种,import m
import m
print(m._module_var)
mc = m._module_calss(99)
print(mc.mc_func())
m._module_func()
依然是可以的
但是如果用第二种:
from m import *
print(_module_var)
mc= _module_class(99)
print(mc.mc_func())
_module_func()
这时会出错,也就是说使用单下划线开头时,如果使用from m import * 时,加载不进来
总结:
>模块中的顶层语句:在import 时一次性执行
>模块内的变量,类和函数:在import时采用<模块名>方式访问
>单下划线的顶层命名元素:不会在from ...import *时被导入
(3),包的命名空间:
与模块不同,包是一个有层次的命名空间
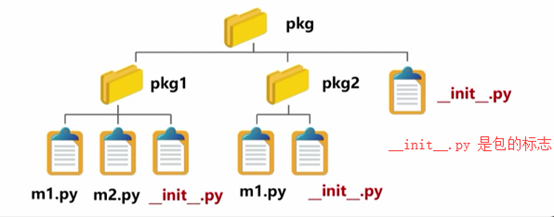
Python包区别于普通目录的关键:
Python包里有__init__.py 文件
包: Package:由一组模块构成,有层次命名空间的程序功能
>每个包需要包含一个__init__.py 文件表达包的组织
>__init__.py 可以是空文件,即,文件存在即可
>每个包可以嵌套包含更多子包
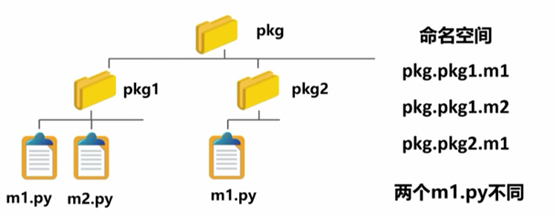
例子:
所对应的命名空间:
小结:
包是一个有层次的命名空间:
>通过包的组织可以形成由英文句号(点). 分隔的层次化命名空间
>__init__.py 用来构成包的定义,区分于包含.py 文件的普通目录
>包,子包和模块可以用import进行导入或单独导入
(4),模块的名称属性:
名称属性是表达模块名称的预定义变量
属性 描述
__name__ 模块或包的名字,例:m.__name__
你可能会问:模块的名字不就是文件的名字吗,为何还定义个__name__?
不完全是
看例子:
m.py 中:
def _module_func():
print("Module Fucntion")
module_var = 1
print("Module Statement")
print(__name__)
输出是:
Module Statement
__main__ (自己内部使用)
a.py 中:
import m
输出是:
Module Statement
m (外面的文件引用)
总结:
>当程序以脚本方式直接执行时,__name__的值为'__main__'
>当程序以模块方式被引用执行时,__name__的值为模块名称
>作用: 区分程序以何种方式执行
一句话:自己用,__name__是__main__ ,别人用是模块名
我们经常看到在一些程序中用if __name__ == "__main__": 来表达,
它其实就是为了方便在自己本身内部调试,外部调时不会被执行
总之:
作用1:作为模块主体功能的单元测试部分
作用2:作为模块内部保留的额外功能部分(暂时没有完成的项目代码)
Make a script both importable and executable!
unit2:模块和包的构建:
(1),模块的构建 :
模块的构建原则:如何编写好一个.py 文件呢?
>功能闭包:单一.py 文件实现单一且完整的功能
>抽象适度:用函数或类进行抽象,结合功能选择合适抽象
具体抽象级别,要看需求,简单的抽象用函数,复杂的抽象用类
>操作闭包:模块无顶层可执行语句,导入时无输出
不规范的模块:

规范之后:
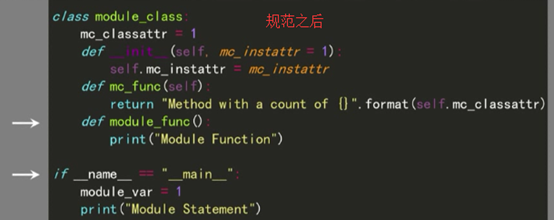
还有要注意的是:顶层尽可能都是函数或都是类,尽量不要顶层的类和函数的混合使用
>功能闭包:功能定义要清晰,设计要合理(紧耦合,松耦合)
在模块内部,功能之间是紧耦合的,
模块之间,尽量使松耦合
>抽象湿度:采用类或函数,尽量选择一种;多种也无妨
>操作闭包:采用__name__,无全局可执行语句,尽量无顶层全局变量
实例:
"这是模块的秒数"
class module_class:
mc_classattr = 1
def __init__(self,mc_instattr = 1):
self.mc_instattr = mc_instattr
def mc_func(self):
return "Method with a count of {}".format(self.mc_classattr)
def module_func():
print("Module Function")
if __name__ == "__main__":
import sys #如果引入是为了测试用,最好放在这
module_var = 1
print("Moudle Statement")
还要: dir() 函数:以列表形式返回模块所使用的命名
a.py :
import m
print(dir(m))
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'module_class']
用dir() 查看,我们能使用的命名,这样对于我们使用模块更加简单,
====Python包分为常规包和命名空间包====
>常规包:Regular Packages ,通过__init__.py 对文件和目录组织形参的包(在目录上连续的)
>命名空间包:Namespace Packages,由更分散子包组成的包
>子包的位置可以在文件系统中不连续
>子包也可以是压缩文件后网络连接或其他系统资源
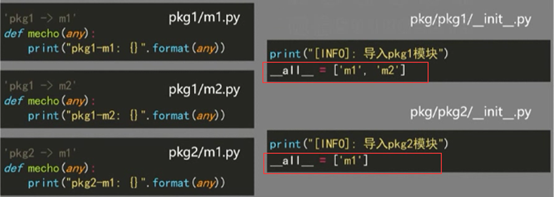
(2),常规包的构建:
常规包:Regular Packages
>连续目录空间表达的,有层次的命名空间
>每个目录中包含一个__init__.py 文件,可以是空文件
>当 包/子包 被导入时,对应目录的__init__.py 文件将被执行
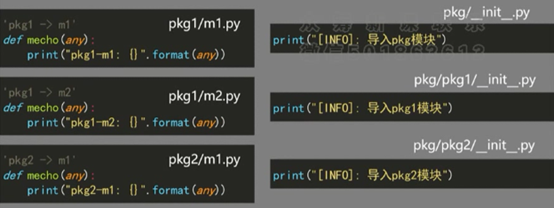

我们发现,三行import 语句分别引入m1,m2,m1
我们头两行都导入了pck包,但是包只运行了一次
即是每个包仅被导入一次,且包导入按照层次结构进行

导入的时候,只能导入模块,不能导入包
这时可以用from pkg.pkg1 import m1,m2

通过from ..import 直接导入具体模块,可以简化调用时命名空间的表达
再看用from ..import * :
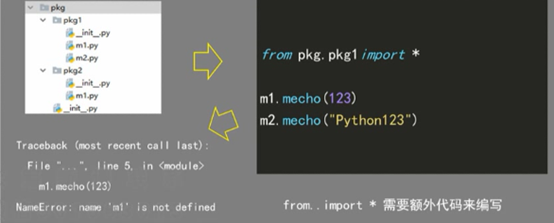
结果是错的 ,使用它是需要额外写代码的,
这就要用到__all__属性,
>from ..import *形式需要在__init__.py 文件中增加__all__属性赋值
>__all__需要被赋值为列表对象,包含当前包下所有希望被导入的模块名称
>__all__ 用来辅助导入模块,但不能辅助导入列表

常规包的构建流程:
>设计好包层次结构(命名空间),每个目录配置一个__init__.Python文件
>完善__init__.py 文件,并酌情赋值__all__属性
>再次理解包和模块的不同,模块提供功能,包提供命名空间
小结:
>每个包仅被导入一次,且包导入按照层次结构进行
>直接导入包不能调用功能,需要导入到模块层次
>from ..import 直接导入具体模块,可以简化调用时命名空间的表达
>__init__.py 文件中通过__all__ 属性支持 from..import *功能
(3),命名空间包的构建:
常规包需要用__init__.py 辅助构建,命名空间包是不需要的,
命名空间包:表达命名空间层次结构的一种逻辑包形式
>命名空间中各部分可以在不同的文件系统位置
>命名空间中各子包并不包含__init__.py (是个普通目录)
要把目录加到sys.path 中,
>Python 解释器通过sys.path 变量来 隐式 维护命名空间包
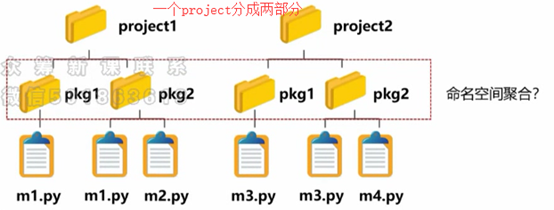
现在的问题是如何将这样的命名空间聚合?

注:project1 和project2 可以在不同的路径中(只不过它们中的pkg1和pkg2要相同)


import sys
sys.path += ['project1','project2'] #首先是将最顶层目录加入到sys.path变量中,
import pkg1.m1
import pkg1.m3 #两个不同 的pak1 成为一个命名空间
pkg1.m1.mecho(123)
pkg1.m3.mecho("Python")
print(pkg1.__path__) # 输出是:_NamesapcePath(['project1\\pkg1','project2\\pkg1'])
sys.path :指定搜索路径的字符串列表:
>指定import 时搜索模块或包的路径列表,路径是相对或绝对路径
>sys.path 是个列表类型,可以用sys.path.append(p)增加新路径p
>载入后,根据其中包的名称和层次结构自然组成了命名空间包
__path__属性:
>记录了某个包(命名空间) 的绝对/相对路径,列表类型
>常规包:路径是单一的,列表中只有一个元素
>命名空间包:路径是多元的,列表中可能有多个元素
unit3:实例1:矩阵乘法模块的构建
矩阵乘法:
>人工智能算法的核心运算之一
>数据分析的数据表达及运算之一
>大规模科学计算的核心操作之一
需求分析:
矩阵乘法模块:
>输入:两个矩阵及行列值
>处理:矩阵乘法运算,矩阵各元素求和运算
>输出:一个采用Python语言开发的Python模块
例子:


1 mxmul.py 模块 2 "mx 为matrix 矩阵" 3 def mxmul(mx1,mx2,mx1_row,mx1_col,mx2_col): 4 rst = [[0 for y in range(mx2_col)] for x in range(mx1_row)] 5 for i in range(mx1_row): #mx1行 6 for j in range(mx1_col): # mx1列 mx2行 7 for k in range(mx2_col): #mx2列 8 rst[i][k] += mx1[i][j] *mx2[j][k] 9 return rst 10 11 def mxsum(mx,mx_row,mx_col): 12 s = 0 13 for i in range(mx_row): 14 for j in range(mx_col): 15 s += mx[i][j] 16 return s 17 18 if __name__ =="__main__": 19 mx1 = [[1,2,3],[7,8,2],[4,2,5]] 20 mx2 = [[1,2],[9,8],[11,7]] 21 mx1_row = len(mx1) 22 mx1_col = len(mx1[0]) 23 mx2_row = len(mx2) 24 mx2_col = len(mx2[0]) 25 26 rst = mxmul(mx1,mx2,mx1_row,mx1_col,mx2_col) 27 sum1 = mxsum(mx1,mx1_row,mx1_col) 28 sum2 = mxsum(mx2,mx2_row,mx2_col) 29 print(rst) 30 print(sum1,sum2)
输出:
[[52, 39], [101, 92], [77, 59]]
34 38
后面会用c语言来改写它,对于成千上万,几十万的矩阵,用c语言才是最佳的
上面模块的使用:
1 import mxmul 2 3 mx1 = [[1,2,3,4],[1,2,3,4],[1,2,3,4],[1,5,9,7]] 4 mx2 = [[1,5],[2,6],[7,8],[9,5]] 5 6 mx1_row = len(mx1) 7 mx1_col = len(mx1[0]) 8 mx2_row = len(mx2) 9 mx2_col = len(mx2[0]) 10 11 rst = mxmul.mxmul(mx1,mx2,mx1_row,mx1_col,mx2_col) 12 13 print(rst)
输出:
[[62, 61], [62, 61], [62, 61], [137, 142]]
unit4:深入理解import系统(理解)
(1),import系统:
import系统:扩展命名空间及功能的方法
>构成(3部分):import保留字,__import__()函数 和 importlib 标准库
这三者都可启动import系统
>步骤:模块的查找,模块的加载
>价值:import系统是Python代码复用和命名空间管理的精髓
>import保留字:调用__import__() 进行模块查找,以及模块的加载
它同时完成了查找和加载两个功能
>__import__() 函数:模块的查找,建立模块对象
>importlib标准库:与import 系统相关的丰富API
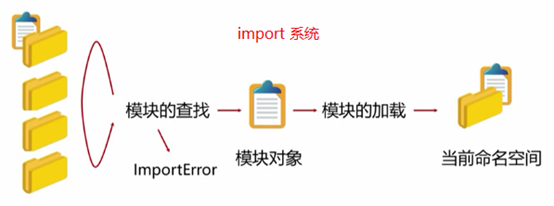
如果未查找到,会返回ImportError 的错误
万物皆对象:模块被导入后成为了对象
>模块的对象形式:模块在程序中使用都是以对象形式体现
>类似 类对象 ,模块对象只有一个
>模块对象生产时,模块中代码会被执行,因此会有类对象产生
(2),模块的查找:
模块的查找是import系统中第一部分,

查找的开始:
>输入参数:模块的名字,例如:pkg.pkg1.m1
>输入方式:import保留字,__import__(),importlib标准库
>基本行为:按层次结构逐层查找,例如:pkg -> pkg1-> m1
查找路径:
第一步:
>第一步查找sys.modules,之前 被引入的模块 会在缓存中(cache)
>sys.modules是个字典,<模块名/对象引用>:<加载路径>
>如果模块不在sys.modules中,则进入下一步
第二步:
查找策略
>用户通过 注册import 钩子扩展的查找模式
>内置模块的路径
>sys.path(列表变量)提供的加载路径,可以是zip或url
improt钩子:import hook
>扩展查找模块的方式:meta_path 方式和import路径方式
>meta_path:将查找方法增加到sys.meta_path列表变量中
>Import路径:将查找方法注册到sys.path_hooks 列表变量中

如果这四个步骤都没有找到就会返回ImportError
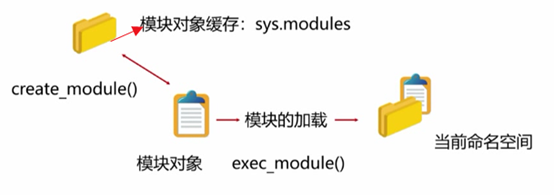
(3),模块的加载:
在模块查找到以后,
从模块对象的生成到命名空间的使用是模块的加载,
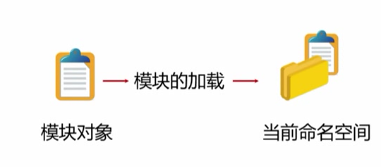
建立模块对象的过程:
>1,找到模块后,如果模块对象存在,则使用现有模块对象
>2,创建一个新的模块对象,将其加入到sys.modules
>3,在程序当前命名空间执行模块代码
简单说,建立模块对象的过程:不只是创建对象,还有执行对象
>创建对象:importlib.abc.Loader.create_module()
>执行对象:importlib.abc.Loader.exec_module()
模块对象的命名空间:
因为import是可以在任何命名空间使用的:
>模块的命名空间与import 的位置有直接关系
>如果import引用位置在文件顶层,则使用文件顶层命名空间访问模块
>如果import引用位置在非顶层,则使用局部命名空间访问模块
(4),import的使用方式:
import的三种使用方式:
>import <模块名>
>from <模块名> import <类/函数名/*>
>import <模块名> as <别名>
import <模块名>
>当前命名空间下的一个子命名空间
>成功加载后,产生一个与<模块名>同名的<模块对象名>
>实际上:<模块对象名>.<子命名空间内元素>方式访问
from <模块名> import <类/函数名/*>
>将导入元素加载到当前命名空间
>成功加载后,产生类对象或函数对象,覆盖同名对象
>实际上: <类对象名> 或 <函数对象名> 方式访问
import <模块名> as <别名>
>当前命名空间下的一个子命名空间
>成功加载后,产生一个与<别名>同名的<模块对象名>
>实际: <模块对象名>.<子命名空间内元素>方式访问
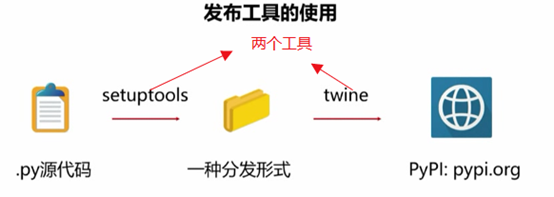
unit5:Python第三方库的发布:
(1),发布前的准备:
>PyPI : Python Package Index ,用来登记第三方库信息
>Github,bitbucket :存储第三方库源代码及文档
>目标:通过pip 进行安装和管理,源代码和文档网络可管理
一些基本概念:
>项目: project:PyPI 上一组发布和文件的统称
>发布:release :项目的一个特定版本,每个发布有一个确定的版本号
>文件file: 即package ,一次发布包含的具体文件
发布流程:
工具的更新:

注册账号:
(2),第三方库的发布流程:
1,整理目录结构
2,创建其他相关文件,主要是setup.py
3,执行打包命令 :python setup.py ...
4,执行发布命令 : twine upload dist/*
(3),第三方库的发布概念:
略
第二部分的内容:
unit1:c语言精简概述:
(1),c语言概述
c语言与Python语言:
>Python解释器采用c语言编写,被称为:cpython
>Python从未视图替换过c语言,而是通过扩展与c语言并存,各展所长
>c和python 都将是不可超越的经典
c语言的精髓:
>c语言精髓在于灵活语法下的内存有效管理
>无论何种语法形态,最终体现为数据在内存中栈和堆的存储和操作
>c语言可以直接精细到操作每一个比特和字节,充分发挥计算机效率
(2),c语言语法:
略
(3),c开发环境配置:
略
(4),c语言实例:
略
(5),编译与解释
略
unit2:Python与C的交互方法:
Python与c/c++及交互的三种方式:
>Python扩展:在Python程序中调用c/c++编写的库
>Python嵌入:在c/c++中调用python程序
>Python调用: Pythonhe c间以程序级别互相调用
Python和c/c++交互的价值
>整合Python高产和c/c++高效的优势
>利用c或python 已有功能服务彼此的程序
>Python作为粘性脚本语言整合或被整合到各类独立程序
第一:Python扩展:在Python程序中调用c/c++编写的库 :
>目的:提升关键代码性能,引入c语言成熟功能库
>方式:Cython,SWIG,ctypes,CFFI
>形式:Python为主程序,C通过.dll/.so 形式使用
第二:Python嵌入:在Python程序中调用c/c++编写的库 :
>目的:在c/c++中调用python程序
>方式:Python/C API
>形式:c/c++为主程序,Python通过源文件形式使用
第三:Python 和 c互相调用:在Pythonhe c间以程序级别互相调用
>目的:模块间功能互用,以功能使用为目标
>方式:子进程/线程方式,即subprocess
>形式:c/c++ 和python都是独立程序
总结:
>Python扩展: 十分重要,Python程序员必会 (提高计算性能)
>Python嵌入:一般重要,Python程序员可以掌握
>Python调用:比较重要,Python程序员应该掌握
(1),Python的扩展方法:
>目的:提升关键代码性能,引入c语言成熟功能库
>方式:Cython,SWIG,ctypes,CFFI
>形式:Python为主程序,C通过.dll/.so 形式使用
1,Cython:实现python扩展的一种语言,第三方库
>思路:通过一种简单的语言实现Python和c的接口
>方式:采用了Pyrex语法形式
>结果:采用c数据类型的python编程,实现混合编程
more:http://cython.org/
2,SWIG :一个将c/c++与脚本语言相整合的编译器,独立工具
>思路:通过一个编译器来实现Python和c的接口
>方式:纯c/c++编程,通过编写接口变成Python模块
>结果:独立c和python编程,重点在于编写接口(描述)
more:http://www.swig.org
3,ctypes:调用DLL 或共享的Python功能函数库,标准库API
>思路:通过一个python标准库实现python扩展
>方式:c语言功能编为.dll 或 .so ,加载库及调用函数,API
>结果:c语言独立编程,Python使用库调用接口函数
more:http://docs.python.org/3.7/library/ctypes.html
4,CFFI: 在python中直接使用c函数的方式,第三方库 (最有效)
>思路:类似于ctypes,使用API 扩展c程序,也可以直接混合编程
>方式:关注c函数的访问接口,而不是库函数,构建API
>结果:c语言独立编程,Python使用CFFI扩展,最小学习代价
more:http://cffi.readthedocs.io/
小结:
>Cython:采用c数据类型的Python编程
>SWIG:将c转变为Python模块的接口编译工具
>ctypes:调用.dll/.so 的标准库API
>CFFI:调用c函数及混合编程的第三方库API (推荐使用)
(2),Python的嵌入方法:
Python嵌入:在Python程序中调用c/c++编写的库 :
>目的:在c/c++中调用python程序
>方式:Python/C API
>形式:c/c++为主程序,Python通过源文件形式使用
Python/C API: python嵌入的主要接口
>嵌入Python语句:嵌入一个或多个Python语句
>嵌入Python脚本:嵌入一个或多个Python文件
Python/C API需要加载Python解释器及加载Python语句和脚本
Python/C API 是一组能够在c语言下执行的类型定义和函数
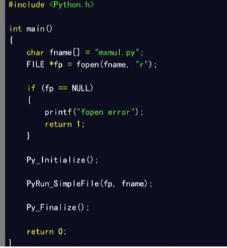
它需要头文件: Python.h
函数:加载Python解释器,嵌入python的语句/脚本/数据类型转换

加载Python解释器:
Py_Initialize() 初始化Python解释器,加载builtins,__main__,sys等
Py_Finalize() 终结化Python解释器,释放解释器占用内存
PyRun_SimpleString(const char *cmd) 在__main__模块中执行一条语句,如果__main__不存在则创建
PyRun_SimpleFile(FILE *fp ,const char *fname) 在c中调用一个Python文件
例子:
more function:https://docs.python.org/3/c-api/
(3),Python的调用方法:
Python 和 c互相调用:在Pythonhe c间以程序级别互相调用
>目的:模块间功能互用,以功能使用为目标
>方式:子进程/线程方式,即subprocess
>形式:c/c++ 和python都是独立程序
1,在python中调用c程序:



subprocess模块:
函数: 描述
subprocess.run(args) 执行args指定的一个程序,args可以是一个字符串/列表,
字符串:一个程序的名称,如a.exe
列表: 程序名称和参数的列表,如['a.exe','9']
2,在c中调用python程序:

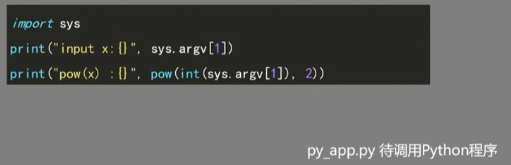

system(char* cmd) c/c++ 下的标准函数,c89定义,将指令和参数以字符串形式作为参数传递执行程序
python 调c : subprocess模块
c调Python: system() 函数
unit3:Python扩展的CFFI 方法
(0),CFFI概述:
CFFI: C Foreign Fucntion Interface for Python
>它是第三方库,需要安装:pip install cffi
>查阅文档:CFFI是一种流程或机制,只要按流程就能实现c语言的扩展
>平台相关:windows平台的.dll ,Linux平台的.so ,32位/64位
CFFI: 在python中直接使用c函数的方式,第三方库 (最有效)
>思路:类似于ctypes,使用API 扩展c程序,也可以直接混合编程
>方式:关注c函数的访问接口,而不是库函数,构建API
>结果:c语言独立编程,Python使用CFFI扩展,最小学习代价
more:http://cffi.readthedocs.io/
>库扩展:对已经编译的c语言.dll 或 .so 库调用并使用
>标准库:c语言标准库的调用及使用
>数据类型:c语言和python数据类型的转换
(1),CFFI的功能接口:
这些都是写在python文件中,
函数 描述
ffi.NULL 相当于常量值NULL
ffi.new(cdecl) 数组/指针的生成,new('x*')或 new ('x[n]')
ffi.cast(ctype,value) c数据类型声明,ctype是类型名,value是变量名 cast('int',x)
ffi.string(cdata) 从cdata类型中返回一个Python字符串
ffi.unpack(cdata,length)从cdata数组中获取特定长度,返回一个Python字符串或列表
与数据大小相关的接口:
ffi.typeof(ctype) 返回ctype的长度
ffi.sizeof(object) 返回object对象的长度
ffi.alignof(ctype) 返回ctype或对象的长度
与调用相关的接口:
ffi.dlopen(libpath) 打开动态链接库并建立一个句柄
ffi.dlclose(lib) 关闭动态链接库并释放句柄
ffi.cdef(str) str指明python中需要使用c类型,函数等声明
与内存操作相关的接口:
ffi.memmove(dst,src,n) 从src 向dst 拷贝n字节内容,注意src和dst都是python变量
(2),CFFI 库的应用:
Python计算生态:>15万个,每个都不一样
那么该怎么学?
>阅读 + 理解 + 实践
>阅读官方文档,理解设计及应用理念,实践典型及拓展案例
一起来学习CFFI库:
>阅读: https://cffi.readthedocs.io 文档不长
>理解:理解设计及应用理念
>实践:典型案例参考实例2,扩展案例请结合工作需求完成
unit4:实例2:矩阵乘法的c语言加速
需求分析:
关键计算部分使用c语言实现
文件结构:
>可编译为.dll的c语言代码: mxmul.h mxmul.c
>用来封装.dll的python模块:cmxmul.py
>用来测试效果的python程序 :test.py
mxmul.h :
#ifndef _DLL_H_
#define _DLL_H_
#if BUILDING_DLL
#define DLLIMPORT __declspec(dllexport)
#else
#define DLLIMPORT __declspec(dllimport)
#endif
DLLIMPORT int* mxmul(int mx1_row, int mx1_col, int mx2_col, int mx1[][mx1_col], int mx2[][mx2_col]);
#endif
mxmul.c :
#include "mxmul.h"
#include <windows.h>
#include <stdlib.h>
DLLIMPORT int* mxmul(int mx1_row, int mx1_col, int mx2_col, int mx1[][mx1_col], int mx2[][mx2_col])
{
int x,i,j;
int * rst;
rst = malloc(sizeof(int) * mx1_row * mx2_col);
for (int i = 0; i < mx1_row; i++){ //mx1行
for (int j = 0; j < mx2_col; j++){ //mx2列
rst[i * mx2_col + j] = 0;
for (int k = 0; k < mx1_col; k++){ //mx1列 mx2行
rst[i * mx2_col + j] += *((mx1 + i) + k) *
*(*(mx2 + k) + j);
}
}
}
return rst;
}
BOOL WINAPI DLLMain(HINSTANCE hinstDLL,DWORD fdwReason,LPVOID lpvReserved){
switch(fdwReason){
case DLL_PROCESS_ATTACH:{
break;
}
case DLL_PROCESS_DETACH:{
break;
}
case DLL_THREAD_ATTACH:{
break;
}
case DLL_THREAD_DETACH:{
break;
}
}
}
将mxmul.h 和mxmul.c 做成dll库
cmxmul.py
import array #引入array 标准库,形成数组的标准库
from cffi import FFI
def cmxmul(mx1_row,mx1_col,mx2_col,mx1,mx2):
ffi = FFI()
c_mx1_row = ffi.cast('int',mx1_row)
c_mx1_col = ffi.cast('int',mx1_col)
c_mx2_col = ffi.cast('int',mx2_col)
_mx1 = array.array('|')
_mx2 = array.array('|')
[_mx1.fromlist(x) for x in mx1]
[_mx2.fromlist(x) for x in mx2]
c_mx1 = ffi.new('int[]',len(_mx1))
c_mx2 = ffi.new('int[]',len(_mx2))
ffi.memmove(c_mx1,_mx1,ffi.sizeof(c_mx1))
ffi.memmove(c_mx2,_mx2,ffi.sizeof(c_mx2))
ffi.cdef('''
int * mxmul(int mx1_row,int mx1_col,int mx2_col,int *mx1,int *mx2);
''')
try:
C = ffi.dlopen('mxmul.dll')
except:
C = ffi.dlopen('mxmul32.dll')
c_res = C.mxmul(c_mx1_row,c_mx1_col,c_mx2_col,c_mx1,c_mx2)
return ffi.unpack(c_res,c_mx1_row*c_mx2_col)
test.py
略