
- 1使用python连接neo4j时报错:IndexError: pop from an empty deque的解决办法
- 2手机恢复文件的3个宝典,一文轻松找回数据(安卓手机通用)
- 3【巴比特:区块链是什么】笔记_巴比特区块链大会是什么
- 4常见网络安全设备_与web和ctl有关的网络设备
- 5来自阿里测试工程师的忠告,测试到底都要学些什么?_专业的测试需要学习算法吗
- 6MVCC和多版本并发控制策略
- 7【ESP32】实用的反汇编命令_xtensa-esp32-elf-addr2line
- 8hiveserver负载均衡配置_hiveserver2 nginx负载均衡
- 9LLM大模型服务器端部署_(choose from 'clean', 'compare', 'config', 'create
- 10【写时复制(精华,从源码分析总结)】
【视频讲解】Python、R时间卷积神经网络TCN与CNN、RNN预测时间序列3实例附代码数据...
赞
踩
全文链接:https://tecdat.cn/?p=36944
本文旨在探讨时间卷积网络(Temporal Convolutional Network, TCN)与CNN、RNN在预测任务中的应用(点击文末“阅读原文”获取完整代码数据)。
视频
通过引入TCN模型,我们尝试帮助客户解决时间序列数据中的复杂依赖关系,以提高预测的准确性。本文首先介绍了TCN的基本原理,随后详细描述了数据预处理、模型构建、训练及评估的整个过程。实验结果表明,TCN模型在处理时间序列数据时表现出色,为相关领域的研究提供了一种新的有效方法。
时间卷积网络(TCN)概述
时间卷积网络(TCN)是一种专为序列建模设计的卷积神经网络架构。它通过引入因果卷积和膨胀卷积,实现了对序列数据的长期依赖关系的有效捕捉。因果卷积确保了模型输出的每个时间步仅依赖于过去的输入,而膨胀卷积则通过增加感受野的大小,使得模型能够捕捉到更远距离的信息。
数据预处理
在模型训练之前,对数据进行适当的预处理是至关重要的。本文采用以下步骤进行数据预处理:
数据加载:从指定路径加载时间序列数据。
归一化:使用MinMaxScaler对数据进行归一化处理,以消除不同量纲对模型训练的影响。
划分数据集:将数据集划分为训练集、验证集和测试集,用于模型的训练、验证和测试。
- from sklearn.metrics import mean_squared_error
- from sklearn.preprocessing import MinMaxScaler
下面的代码将帮助定义一些需要运行程序的变量。它还将创建用于测试和预测的训练样本、验证样本和附加样本。
- df = pd.read_csv(f_path)
-
- # 计算训练样本的大小,这里取数据总量的60%
- training_sample_size = math.ceil(df.shape[0] * .6)
- # 计算验证样本的大小,这里取数据总量的15%
- validation_sample_size = math.ceil(df.shape[0] * .15)
- # 设置采样方式为'sliding_window',即滑动窗口方式,也可以设置为'jump'(跳步方式)

在此,数据已经成型,可以输入到模型中,但我们需要先定义模型 要定义模型,我们应该知道内核的大小、TCN 需要多少个滤波器和多少个层
- if len(channels) != num_layers:
- print('You should not have more than {} residual layers or else model will be equivalent to RNN'.format(num_layers))
模型定义
TCN作为一种专为序列数据设计的深度学习架构,通过其独特的卷积结构和时间因果性,能够有效捕捉数据中的长期依赖关系,从而提高预测的准确性。
模型架构设计
模型的定义是预测任务中的关键环节。在本研究中,我们采用了TemporalConvolutionalNet类来实例化TCN模型。该类通过接收一系列参数来定义模型的具体结构,包括输入通道数(in_channels)、输出通道数(channels)、卷积核大小(kernel_size)、dropout比率以及是否应用权重归一化等。

- y_pred = model(X_train) # 让模型对训练集X_train进行预测
- loss_value = loss(y_pred, y_train) # 计算预测值与真实值之间的损失
- #print(y_pred) # 注释掉的代码,原本可能用于打印预测值

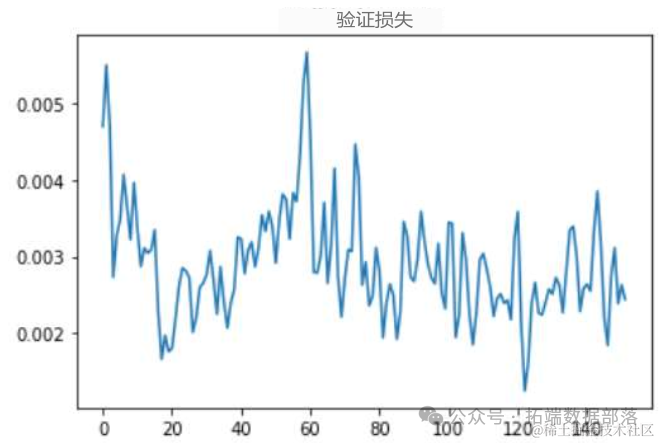
在这里,我们测试了训练数据,看看平均验证损失是否足够低。之所以要看平均值,是因为数据的性质决定了它的波动性。一个好的模型应该能够应对这种波动性。
- # 验证模型
- validation_loss = []
- with torch.no_grad(): # 禁用梯度计算,以节省内存和加速计算
- model.eval() # 将模型设置为评估模式,停止dropout等操作

给定一组新数据,我们将其输入模型,以确定其预测结果
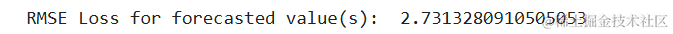
点击标题查阅往期内容

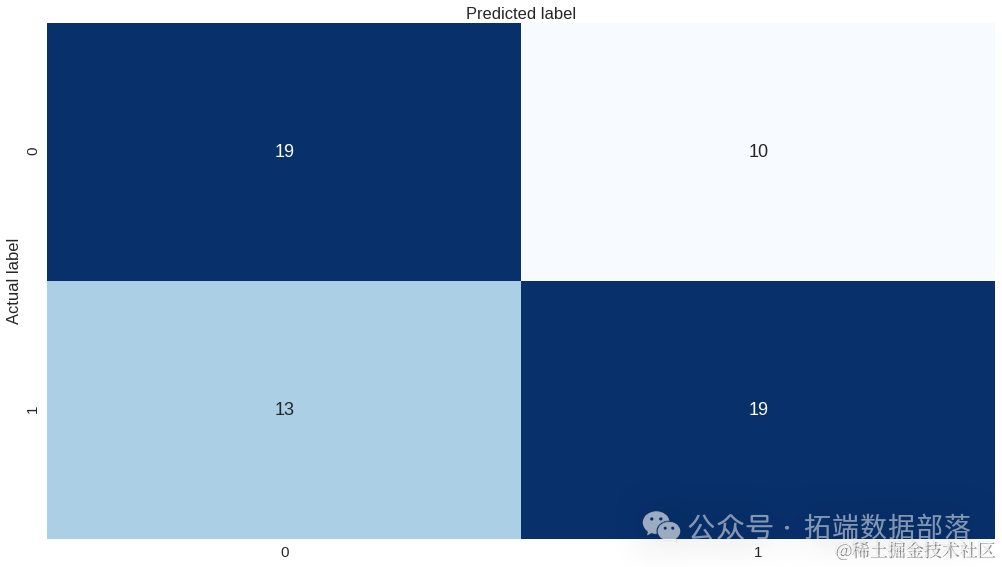
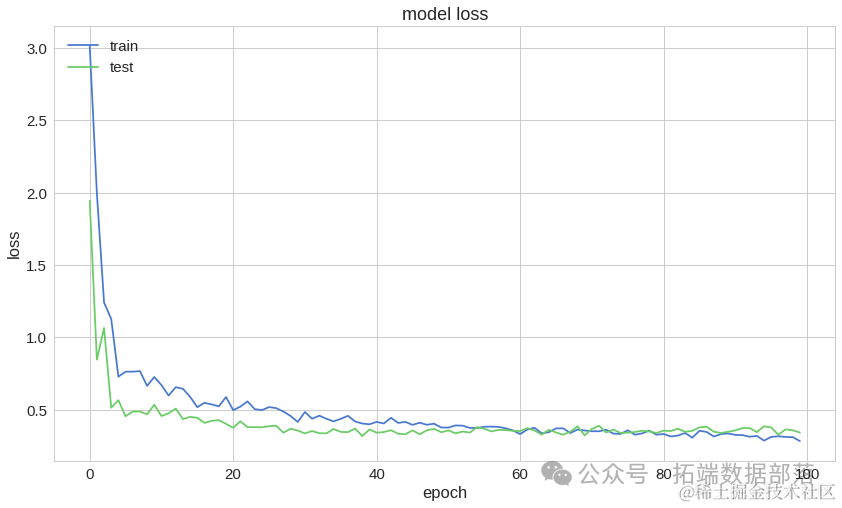
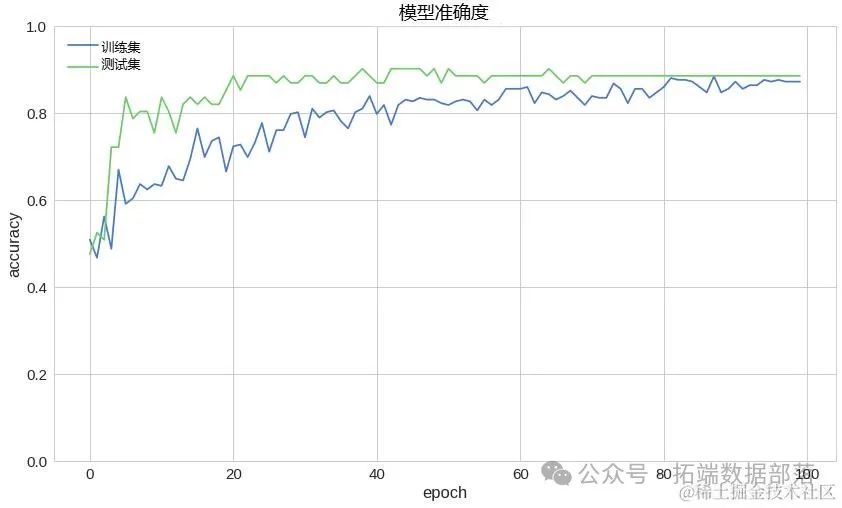
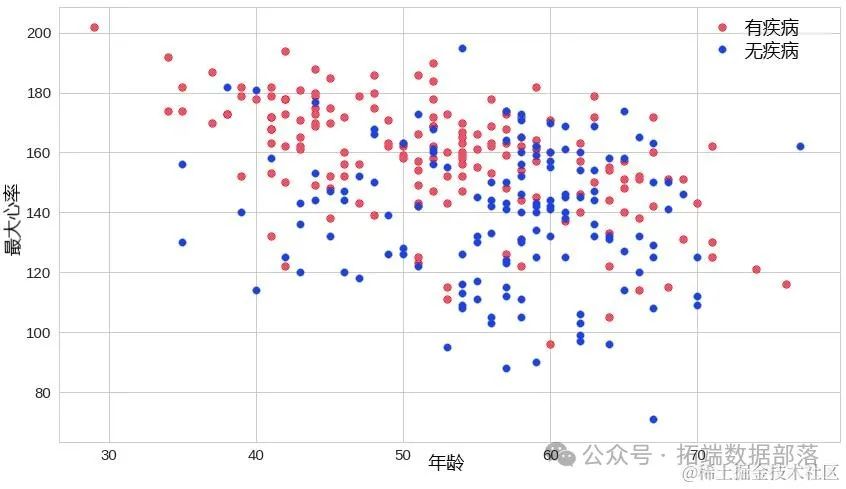
Python深度学习TensorFlow Keras心脏病预测神经网络模型评估损失曲线、混淆矩阵可视化

左右滑动查看更多
01
02
03
04
多元TCN
接下来旨在介绍基于时间卷积网络(Temporal Convolutional Network, TCN)的多元时间序列预测模型的构建过程,并详细阐述数据预处理及特征工程的实施步骤。通过整合多变量预处理技术、特征提取方法和模型构建策略,本文提出了一种有效的预测框架,旨在提高时间序列数据预测的准确性。
模型定义
时间卷积网络(TCN)是一种专为序列建模设计的深度学习架构,它通过引入因果卷积和膨胀卷积来捕获序列中的长期依赖关系。在本研究中,我们使用TemporalConvolutionalNet类来定义TCN模型,具体参数包括输入通道数(in_channels)、输出通道数(channels)、卷积核大小(kernel_size)、丢弃率(dropout)以及权重归一化选项(weight_normal)。
下面的代码将帮助定义一些需要运行程序的变量。它还将创建用于测试和预测的训练样本、验证样本和附加样本
- window_size = 14
-
- # ticer_options = ['APPLE', 'TESLA', 'AT&T', 'S&P500']
- ticker = 'APPLE'
- cur_dir = Path(os.getcwd())
- parent_path = cur_dir.parent
- f_path = parent_path / 'data/{}.csv'.format(ticker)
- df=pd.read_csv(f_path)

在这里,数据已经成型,可以输入到模型中,但我们需要先定义模型。要定义模型,我们应该知道内核的大小、TCN 需要多少个过滤器和层
- in_channels = num_features
- out_channel = 1
- filter_size = 3
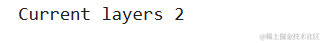
模型定义与训练
模型定义
在本文中,我们采用了一个时间卷积网络(Temporal Convolutional Network, TCN)作为我们的主要模型架构,用于处理时间序列数据。

此模型配置旨在通过调整输入通道数、卷积核的通道数、卷积核大小以及引入适当的Dropout来优化模型的性能。
训练模型
训练参数设置
为了训练该模型,我们设置了以下训练参数:
训练周期数 (
num_epoch): 500,即整个训练数据集将被遍历500次。损失函数 (
loss): 采用均方误差损失(MSE Loss),适用于回归任务。优化器 (
optimizer): 使用Adam优化器,其学习率设置为0.015,betas参数为(0.45, 0.35),以及权重衰减为0.4。这些参数经调优后旨在提高模型的收敛速度和泛化能力。此外,还提供了另一组备选超参数以供比较。

在这里,我们测试了训练数据,看看平均验证损失是否足够低。之所以要看平均值,是因为数据的性质决定了它的波动性。一个好的模型应该能够应对这种波动性。
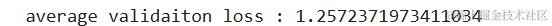
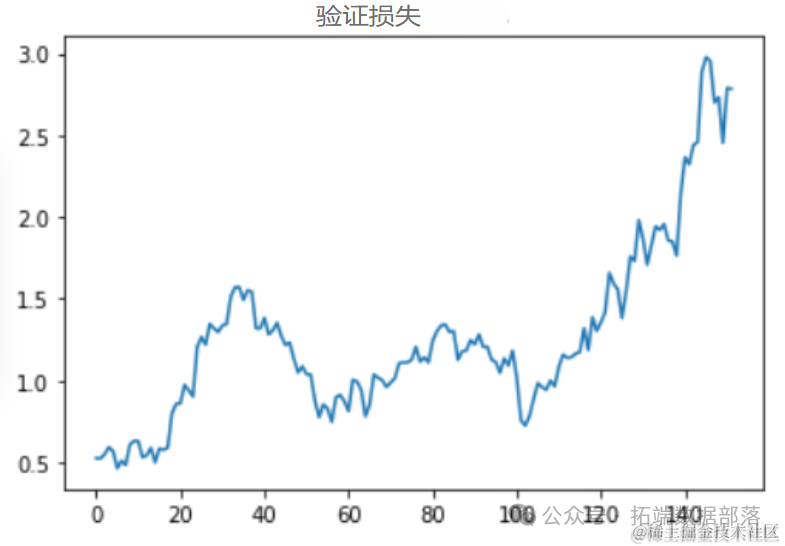
准确预测未来趋势对于决策制定至关重要。本文探讨了一种利用滑动窗口法(Sliding Window Method)进行时间序列预测的方法,该方法通过动态调整输入数据的窗口大小,有效捕捉时间序列中的历史信息,并据此预测未来的数据点。
方法
1. 滑动窗口法概述
滑动窗口法是一种处理时间序列数据的常用技术,它通过设定一个固定大小的窗口在数据序列上滑动,每次滑动都选取窗口内的数据作为模型的输入。在本研究中,我们特别关注于输入和输出长度相等的配置,即窗口大小与预测目标序列的长度相匹配。
预测流程
给定一组新的时间序列数据,我们按照以下步骤进行预测:
步骤一:数据准备:首先,确定预测所需的窗口大小(即输入长度)和预测长度(
num_predictions)。例如,若num_predictions为2,则意味着我们希望模型能够基于当前及之前的数据点预测未来两个时间步的值。步骤二:构建输入和目标序列:通过滑动窗口法构建输入和目标序列。具体而言,将目标序列相对于输入序列向后移动
num_predictions个时间步,以确保输入序列包含了用于预测未来num_predictions个时间步所需的所有历史信息。例如,对于输入序列t1,t2,t3,t4,t5,对应的目标序列将是t3,t4,t5,t6,t7,其中t6,t7即为预测目标。步骤三:模型预测:将构建好的输入序列输入到已训练的时间序列预测模型中,模型将输出与输入序列长度相等的预测序列。由于模型已知输入序列中前
len(input)-num_predictions个时间步的真实值,它利用这些信息来预测接下来的num_predictions个时间步的值。步骤四:验证与评估:为了验证模型的预测性能,我们将预测结果与真实值(即总数据集中位于输入序列之后的
num_predictions个时间步的值)进行比较。例如,如果总数据集为t1,t2,t3,t4,t5,t6,t7,则通过比较模型预测的t6,t7与实际的t6,t7来评估预测准确性。
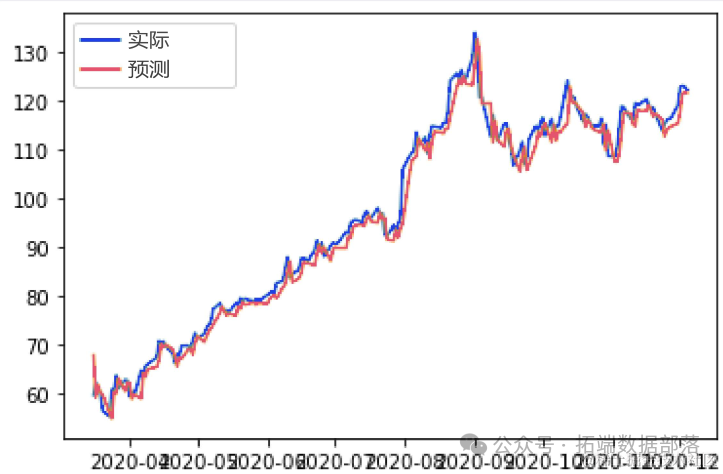

CNN(卷积神经网络)模型以及R语言实现
当我们将CNN(卷积神经网络)模型用于训练多维类型的数据(例如图像)时,它们非常有用。我们还可以实现CNN模型进行回归数据分析。我们之前使用Python进行CNN模型回归 ,在本视频中,我们在R中实现相同的方法。
视频
我们使用一维卷积函数来应用CNN模型。我们需要Keras R接口才能在R中使用Keras神经网络API。如果开发环境中不可用,则需要先安装。本教程涵盖:
准备数据
定义和拟合模型
预测和可视化结果
源代码
我们从加载本教程所需的库开始。
- html
- library(keras)
- library(caret)
准备
数据在本教程中,我们将波士顿住房数据集用作目标回归数据。首先,我们将加载数据集并将其分为训练和测试集。
- html
- set.seed(123)
- boston = MASS::Boston
- indexes = createDataPartition(boston$medv, p = .85, list = F)
- html
- train = boston[indexes,]
- test = boston[-indexes,]
接下来,我们将训练数据和测试数据的x输入和y输出部分分开,并将它们转换为矩阵类型。您可能知道,“ medv”是波士顿住房数据集中的y数据输出,它是其中的最后一列。其余列是x输入数据。
检查维度。
- html
- dim(xtrain)
- [1] 432 13
- html
- dim(ytrain)
- [1] 432 1
接下来,我们将通过添加另一维度来重新定义x输入数据的形状。
- html
- dim(xtrain)
- [1] 432 13 1
- html
- dim(xtest)
- [1] 74 13 1
在这里,我们可以提取keras模型的输入维。
- html
- print(in_dim)
- [1] 13 1
定义和拟合模型
我们定义Keras模型,添加一维卷积层。输入形状变为上面定义的(13,1)。我们添加Flatten和Dense层,并使用“ Adam”优化器对其进行编译。
- model %>% summary()
- ________________________________________________________________________
- Layer (type) Output Shape Param #
- ========================================================================
- conv1d_2 (Conv1D) (None, 12, 64) 192
- ________________________________________________________________________
- flatten_2 (Flatten) (None, 768) 0
- ________________________________________________________________________
- dense_3 (Dense) (None, 32) 24608
- ________________________________________________________________________
- dense_4 (Dense) (None, 1) 33
- ========================================================================
- Total params: 24,833
- Trainable params: 24,833
- Non-trainable params: 0
- ________________________________________________________________________

接下来,我们将使用训练数据对模型进行拟合。
- html
-
- print(scores)
- loss
- 24.20518
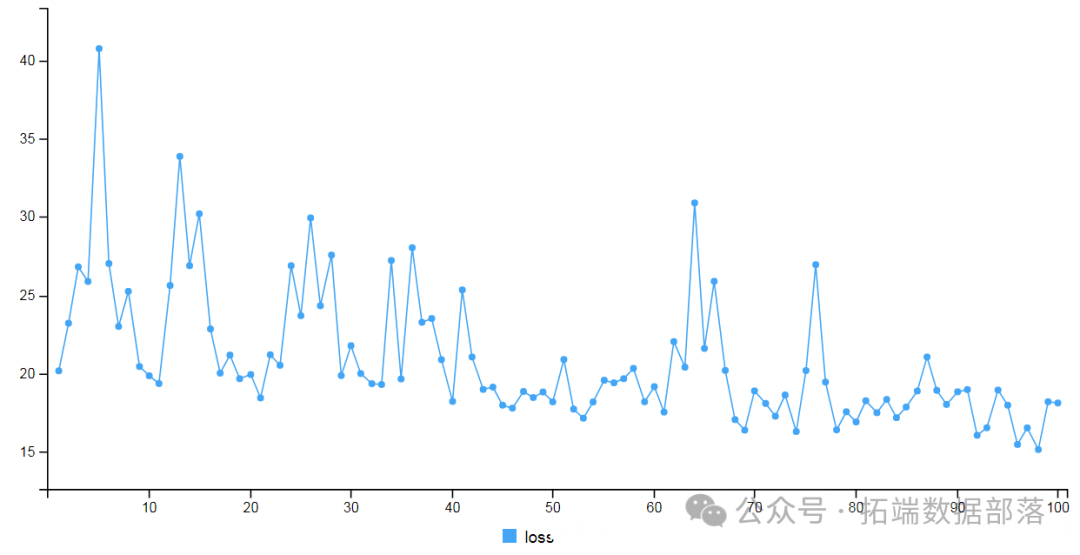 预测和可视化结果
预测和可视化结果
现在,我们可以使用训练的模型来预测测试数据。
- html
- predict(xtest)
我们将通过RMSE指标检查预测的准确性。
- html
- cat("RMSE:", RMSE(ytest, ypred))
- RMSE: 4.935908
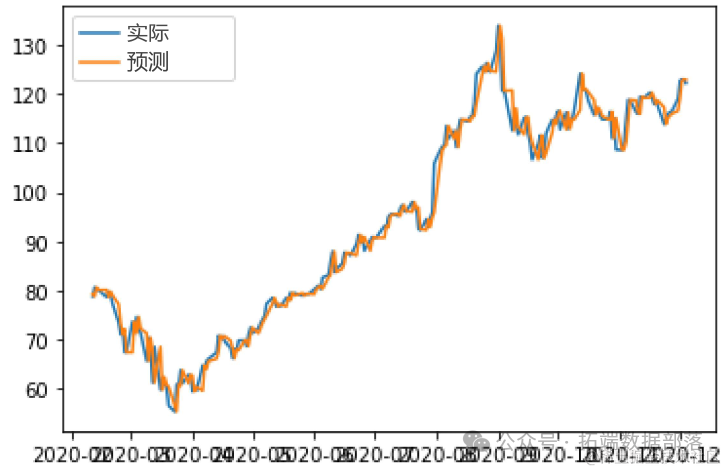
最后,我们将在图表中可视化结果检查误差。
- html
- x_axes = seq(1:length(ypred))
-
- lines(x_axes, ypred, col = "red", type = "l", lwd = 2)
- legend("topl
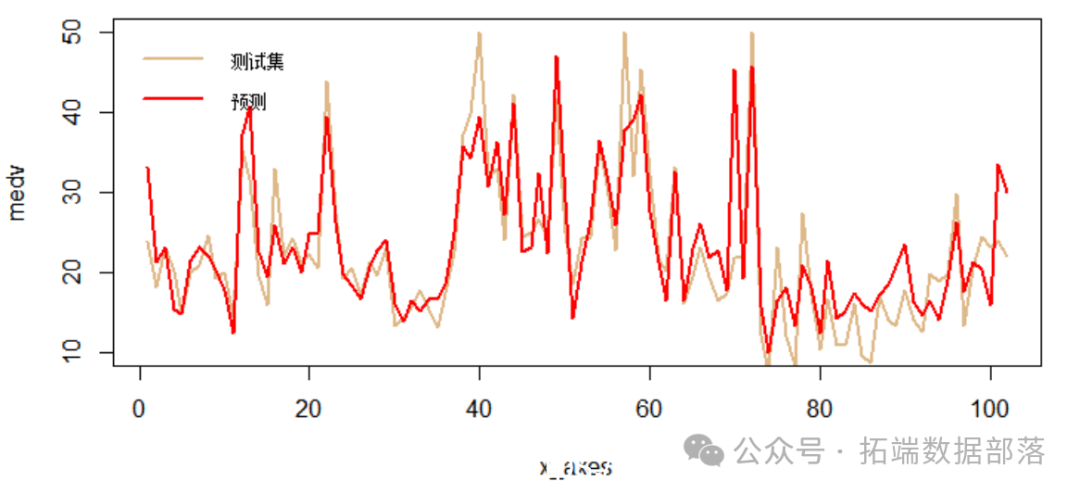
在本教程中,我们简要学习了如何使用R中的keras CNN模型拟合和预测回归数据。
Python用RNN循环神经网络:LSTM长期记忆、GRU门循环单元、回归和ARIMA对COVID
该数据根据世界各国提供的新病例数据提供。
获取时间序列数据
df=pd.read_csv("C://global.csv")探索数据
此表中的数据以累积的形式呈现,为了找出每天的新病例,我们需要减去这些值
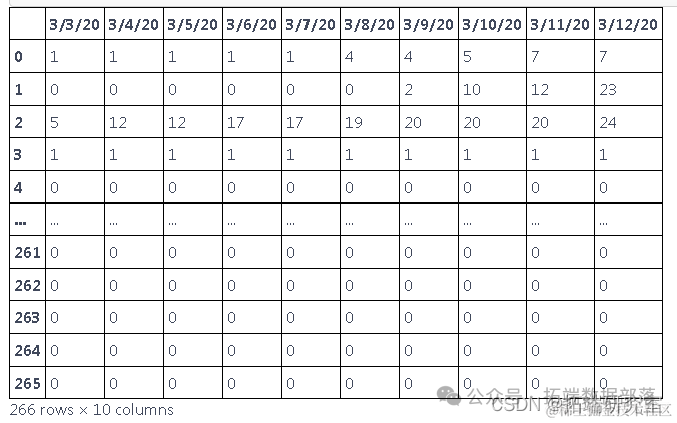
df.head(10)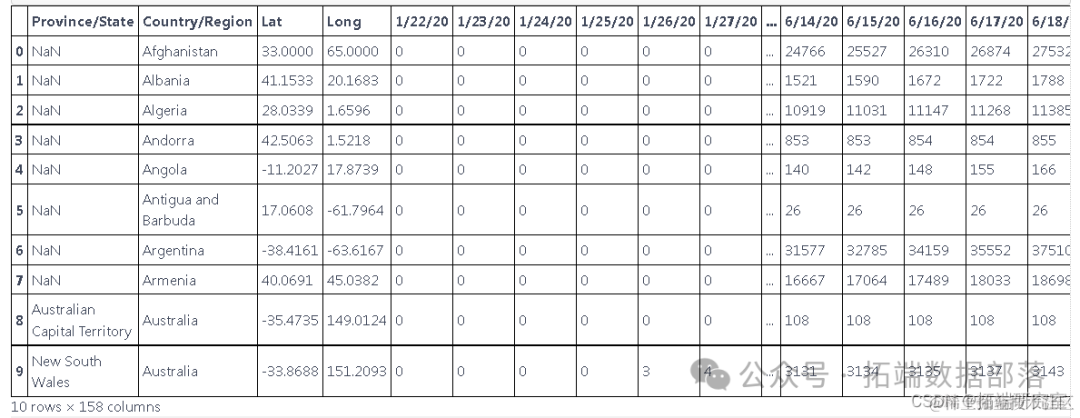
这些数据是根据国家和地区报告新病例的数据,但我们只想预测国家的新病例,因此我们使用 groupby 根据国家对它们进行分组
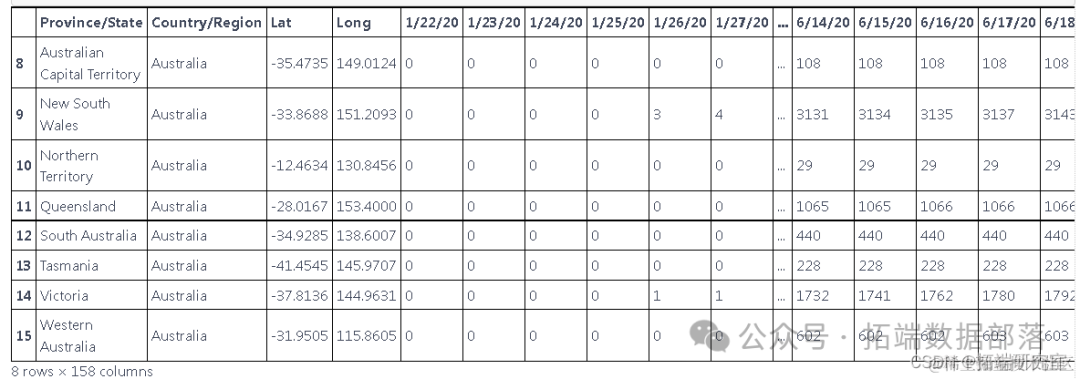
总结数据
执行 groupby 以根据一个国家的新病例来汇总数据,而不是根据地区
d1=df.groupby(['Country/Region']).sum()

描述随机选择的国家的累计新病例增长
from numpy.random import seed plt.plot(F[i], label = RD[i]) plt.show()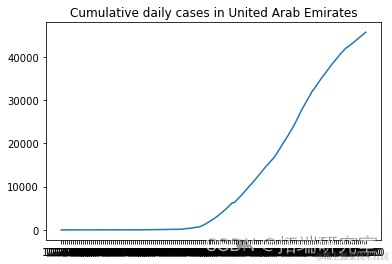
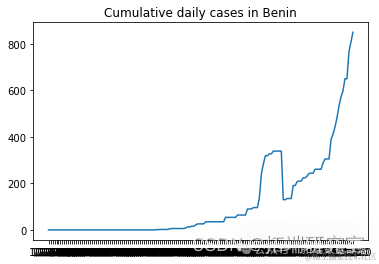
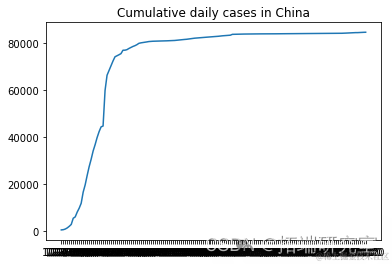
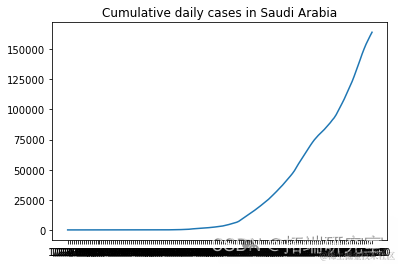
# 我们不需要前两列d1=d1.iloc[:,2:]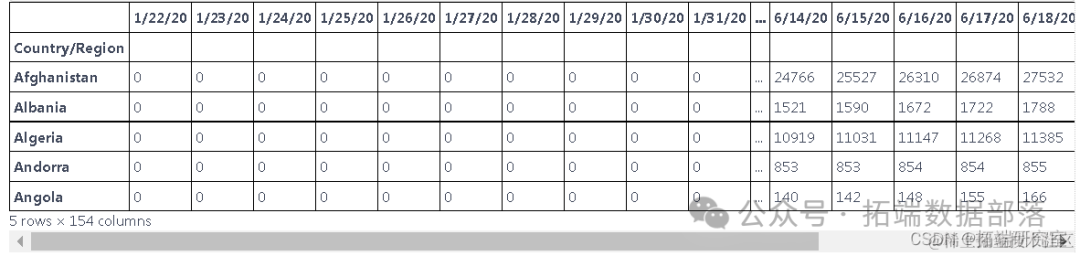
# # 检查是否有空值d1.isnull().sum().any()
我们可以对每个国家进行预测,也可以对所有国家进行预测,这次我们对所有国家进行预测
dlycnmdcas.head()
dalycnfreces.indexdal_cnre_ces.index = pd.to_datetime(dailyonfrmd_as.index)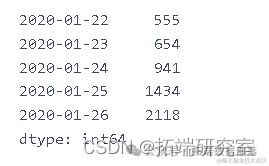
plt.plot(dalnimedases)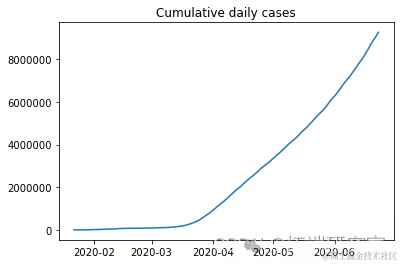
ne_ces = daiy_onme_as.diff().dropna().astype(np.int64)newcaes

plt.plot(ne_s[1:])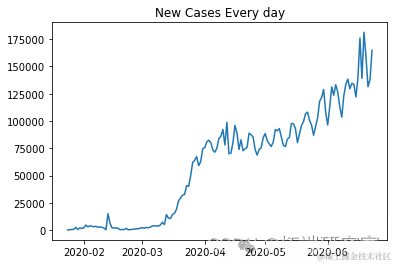
nw_s.shape(153,)将数据拆分为训练和测试数据
ct=0.75trin_aa,tet_aa = train_test_split(ne_ces, pct)(116,)plt.plot(tainta)plt.plot(tesata)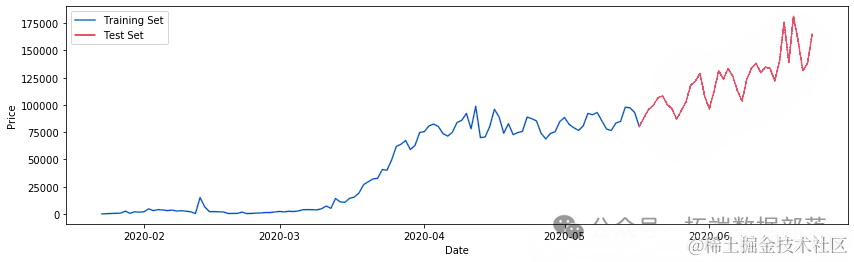
数据标准化
scaler = MinMaxScaler()testa.shape(38, 1)创建序列
lentTe = len(ts_data)for i in range(timmp, lenhTe): X_st.append(tst_aa[i-tmStap:i]) y_tt.append(tesata[i])X_tet=np.array(X_ts)ytes=np.array(y_tt)X_st.shape


Xtrn.shape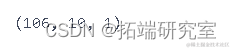
# 序列的样本 X_trn[0], yran[0]
为股票价格预测设计 RNN 模型
模型:
LSTM
GRU
model.summary()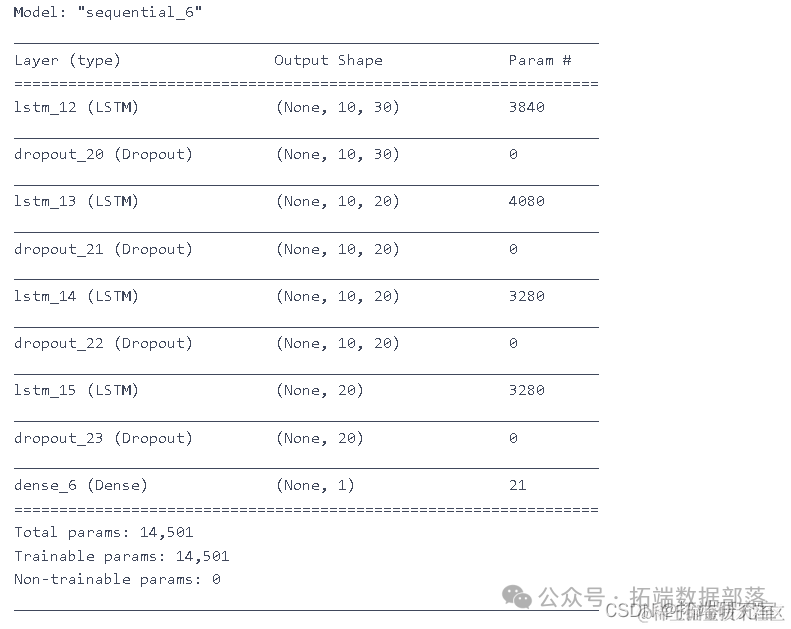
model.fit(X_trn y_rin, epochs=50, batch_size=200)


yprd = (mod.predict(X_test))MSE = mean_squared_error(ytue, y_rd)plt.figure(figsize=(14,6))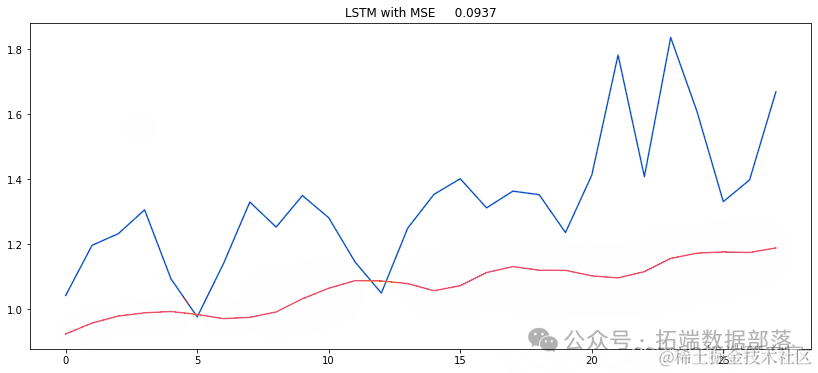
meRU= Sqtal([ keras.layers.GRU(model_GRU.fit(Xtrn, ytin,epochs=50,batch_size=150)

pe_rut = {}y_ue = (y_et.reshape(-1,1))y_prd = (modlGU.predict(X_test))MSE = mean_squared_error(y_ue, ed)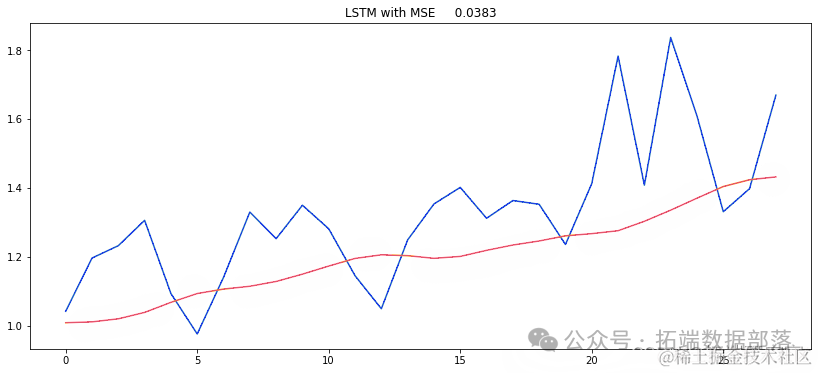
用于预测新病例的机器学习算法
准备数据
d__in.shape
moel=LinearRegression(nos=-2)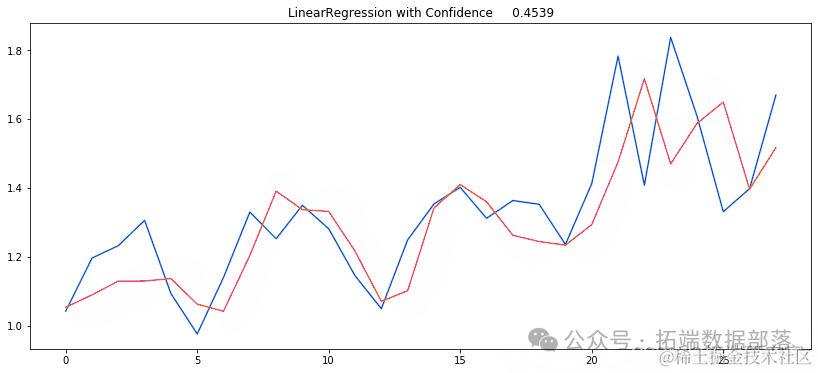
ARIMA
COVID-19 新病例预测的自回归综合移动平均线
#我们不需要前两列df1.head()daly_nfrd_cses = df1.sum(axis=0)day_cnir_ase.index = pd.to_datetime(da_onieses.index)new_cs = dacofmecss.diff().dropna().astype(np.int64)tri_ta,tet_ata = trintt_it(nw_es, pct)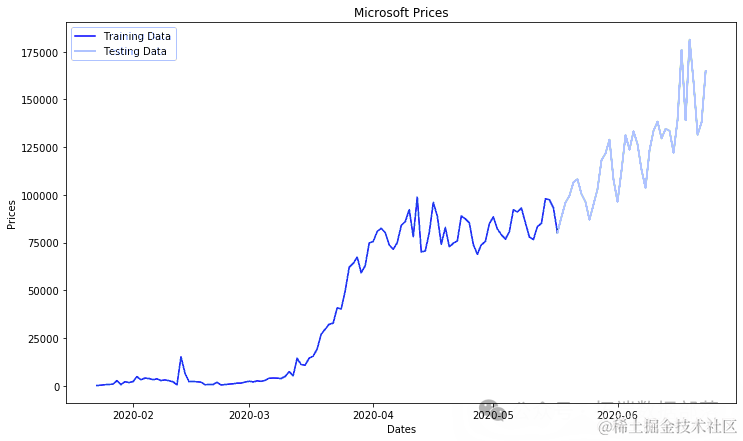
ero = men_squred_eror(ts_ar, pricos)


plt.figure(figsize=(12,7))plt.plot(tanat)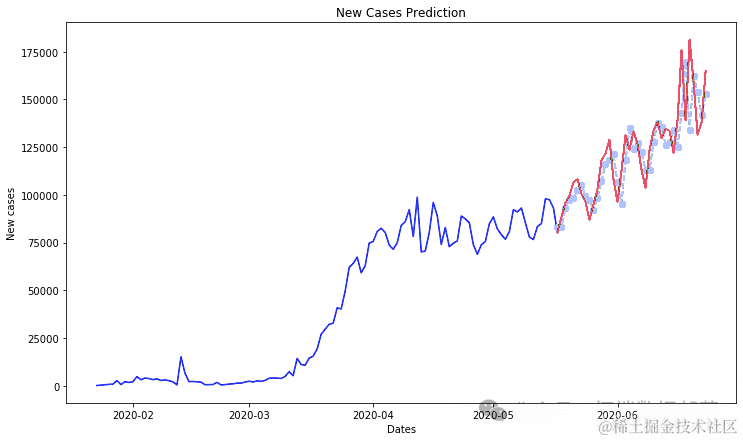
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《【视频讲解】Python、R时间卷积神经网络TCN与CNN、RNN预测时间序列3实例》。
点击标题查阅往期内容
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类



![]()


