- 1Android第三方库收藏汇总,驱动核心源码详解和Binder超系统学习资源_android 第三方控件库
- 2鸿蒙开发:Universal Keystore Kit(密钥管理服务)【明文导入密钥(C/C++)】
- 3ROS-Moveit和Gazebo联合仿真(二)_gazebo联合moveit运动仿真
- 4Django学习笔记1day59_django preventdefault() 的用法
- 5亚马逊aws深度学习_在线学习的前5大Amazon Web Services或AWS课程-免费和最佳
- 6消息队列常见问题(1)-如何保障不丢消息_消息业务层保证不丢消息方案
- 7Javascript学习笔记(自用)_芙兰朵字符串匹配
- 830个接口自动化测试面试题,看过的已经在上班了_接口自动化常见面试题
- 9昇思25天学习打卡营第19天|ShuffleNet图像分类
- 10使用SM4国密加密算法对Spring Boot项目数据库连接信息以及yaml文件配置属性进行加密配置(读取时自动解密)_sm4 requires a 128 bit key
编译原理期末复习
赞
踩
目录
第一章
1. 编译程序与解释程序的异同
相同点:都是进行翻译,将源程序翻译成目标程序
不同:编译程序是整体翻译,解释程序是逐条翻译
2.编译过程概述
编译的各个阶段:
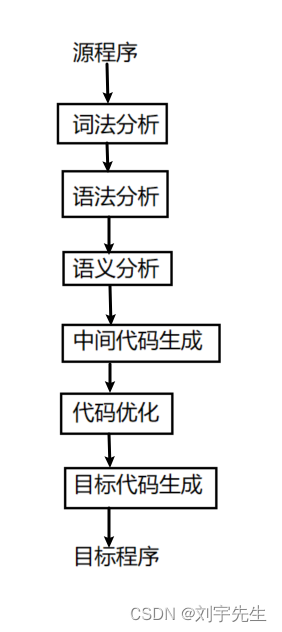
词法分析:从左到右一个字符一个字符的读入源程序,识别出一个个单词
语法分析:在词法分析的基础上将单词序列分解成各类语法短语
3. 编译阶段的组合
表格管理程序:
负责收集记录查询编译当中所缺的信息,像常量表,符号表,数组信息表
出错处理程序:
语法错误,词法错误,语义错误
有时候把编译过程分为前端和后端
| 阶段 | |
| 前端 | 词法分析,语法,语义,中间代码生成 |
| 后端 | 目标代码生成,相关出错处理,符号表操作 |
第二章:词法分析
1.记号的识别:有限自动机
不确定的有限自动机:NFA
是一个五元组 M=(S,+,move,S0,F)
参数:
1. 有限个状态集合
2. 有限个输入字符的集合
3. 状态转移函数
4. 唯一的初态
5. 终态集
DFA确定的有限自动机,是NFA 的一个特例
1. 没有e 状态转移
2. 对于每一个状态和每一次字符,最多只有一个下一状态
练习:求e_闭包
第三章:语法分析(文法和语言)
1. 符号和字符串
符号串的头尾,固有头和固有尾
符号串的连接
2. 文法和语言的形式定义:
文法的概念:
文法G定义为一个四元组 G = ( N, T, P, S )
参数:
1. 非终结符有限集合,2. 终结符有限集合,3. 产生式的有限集合,4. 非终结符,称为开始符号
直接推导,推导的定义
直接推导:一步推导
推导:存在一个推导序列,对于任意文法序列,过程为零步或者多步推导
句型,句子的定义
句型是句子的前身
文法描述的语言是该文法一切句子的集合
3.文法的类型
乔姆斯基把文法分为四种类型:0型(短语文法),1型(CSG上下文有关文法),2型(CFG上下文无关文法),3型(正规式)
| 文法 | 产生式 | 语言 | 自动机 |
| 0型 | a-> B | 短语结构语言,递归可枚举集 | 图灵机 |
| 1型 | 限制1 | CSL | 线性界限自动机 |
| 2型 | 限制2 | CFL | 下推自动机 |
| 3型 | 限制3 | 正规语言,正规集 | 有限自动机 |
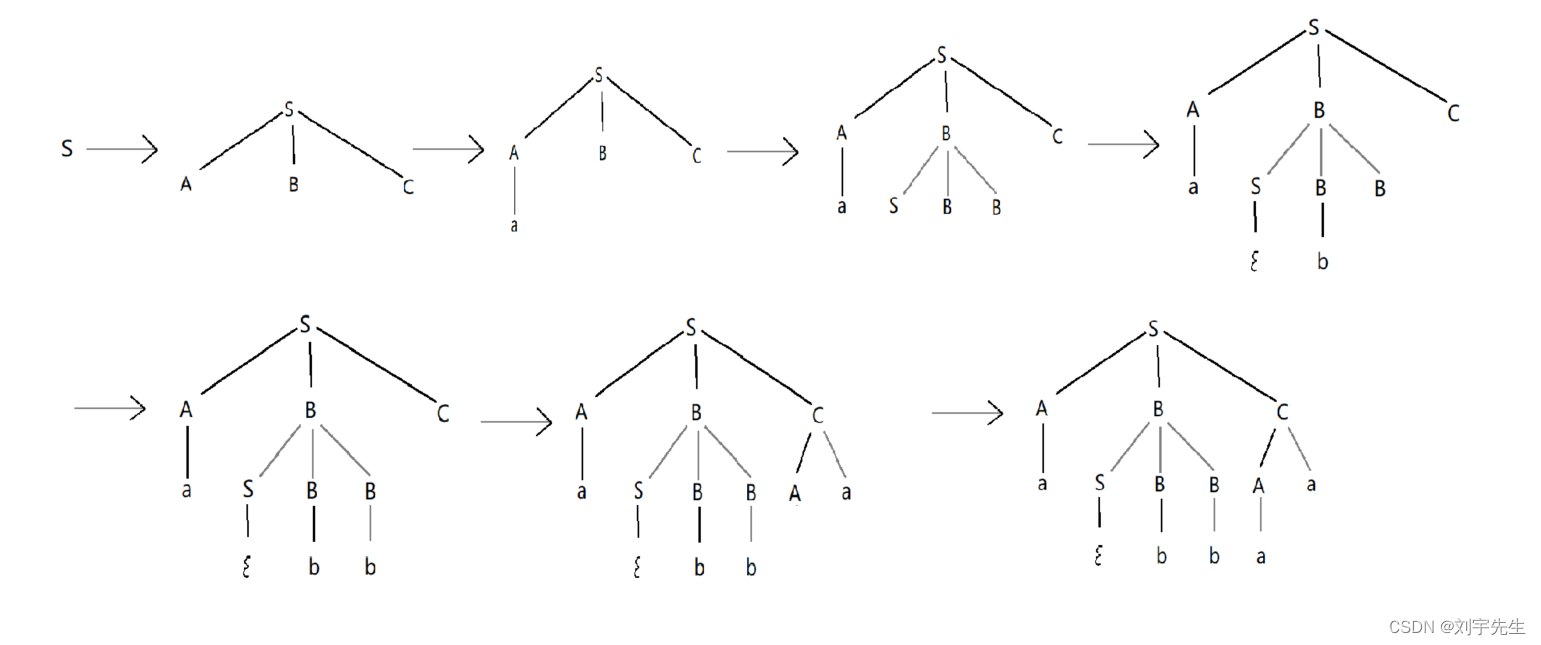
4. 推导,分析树,语法树
推导的过程可以用一颗分析数来表示,称为分析树
语法树:描述上下文无关文法(2型文法)的句型推导,也叫推导树
最右推导:在推导的任何一步,都是最右非终结符进行替换,反之最左推导就是左非终结符的替换
最右推导称为规范推导
规范推导的逆过程,称为最左归约,也称规范归约
二义性:一个文法存在某个句子对应两颗不同的语法树
5. 句型的分析
推导过程:自顶向下的分析方法
归约过程:自底向上的分析法
6. 短语,直接短语,句柄
案例:
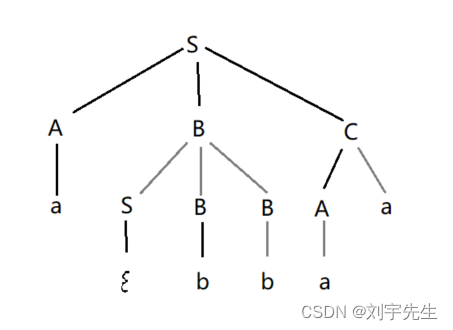
1. 给出最左推导,最右推导
2. 该文法产生式的集合,可能有哪些元素
3. 给出所有的短语,简单短语,句柄
答:1.最左推导:,最右推导略
2. 产生式集合:
S-> ABC| e
A-> a
B-> SBB|b
C-> Aa
可能的元素:ab,aabb ,ebb
3. 短语:
a 是A 的短语: a-> A;
b -> B;
bb -> B;
aa -> C
abbaa -> S;
直接短语: a,b;
句柄:a
有关文法的实用限制:
有害规则:是指像U->U这种没有必要的产生式,因为这会引起文法的二义性所以有害
多余规则:指文法中那些连一个句子的推导都用不到的规则,以两种形式出现:不可到达的、不可终止的
自上而下的语法分析
思想:
first集:第一个终结符号
follow集:后面紧跟着的终结符号
LL(1)文法:
1. 从左向右扫描输入字符串
2. 最左推导
3. 只需要向后看一个符号便可以决定如何推导
消除左递归:
例题: E-> E + T | T
消除左递归后:
first和follow 集合:
根据消除左递归后的文法,写出各非终结符的first和follow 集合:
文法:
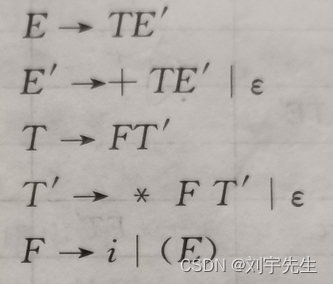
first集合:
first(E) = { i,( }
first(E1) = { +,e }
first(T) = { i,( }
first(T1) = { *,e }
first(F) ={ i,( }
follow集合:1. 写入# 2. TE 则E的first(除过e)是T的follow 3. T->aEb (b->空)则follow(T)写入follow(E)
follow(E) =follow(E1) = { ), # }
follow(T) =follow(T1) = { +, ), # }
follow(F) = { * ,+ ,) , # }
构造预测分析表:
| i | + | * | ( | ) | # | |
| E | TE1 | TE1 | ||||
| E1 | +TE1 | |||||
| T | FT1 | FT1 | ||||
| T1 | *FT1 | |||||
| F | i | (E) |
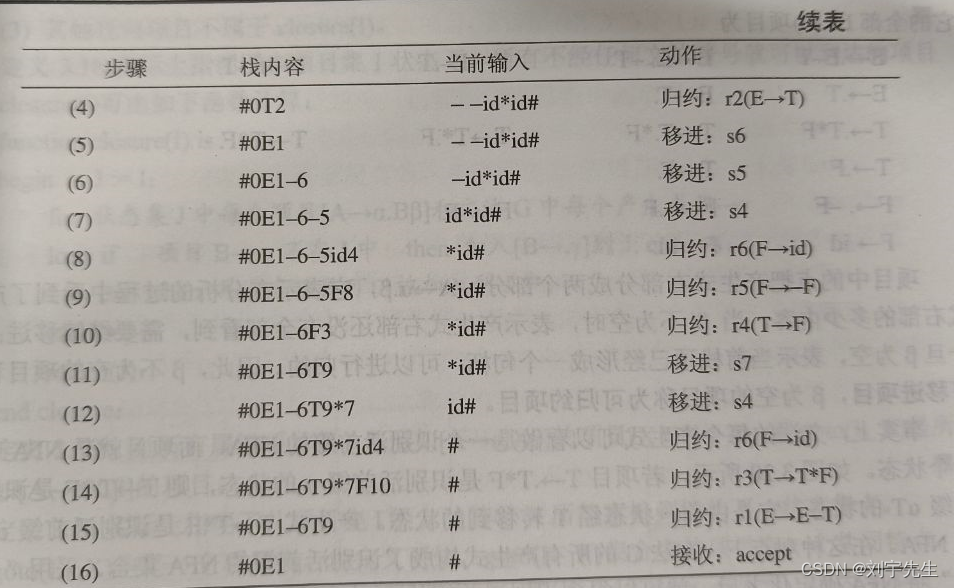
自下而上语法分析(LR文法)
1. 构造移进-归约SLR分析表
s 表示 shift 移入动作;r 表示 reduced 归约
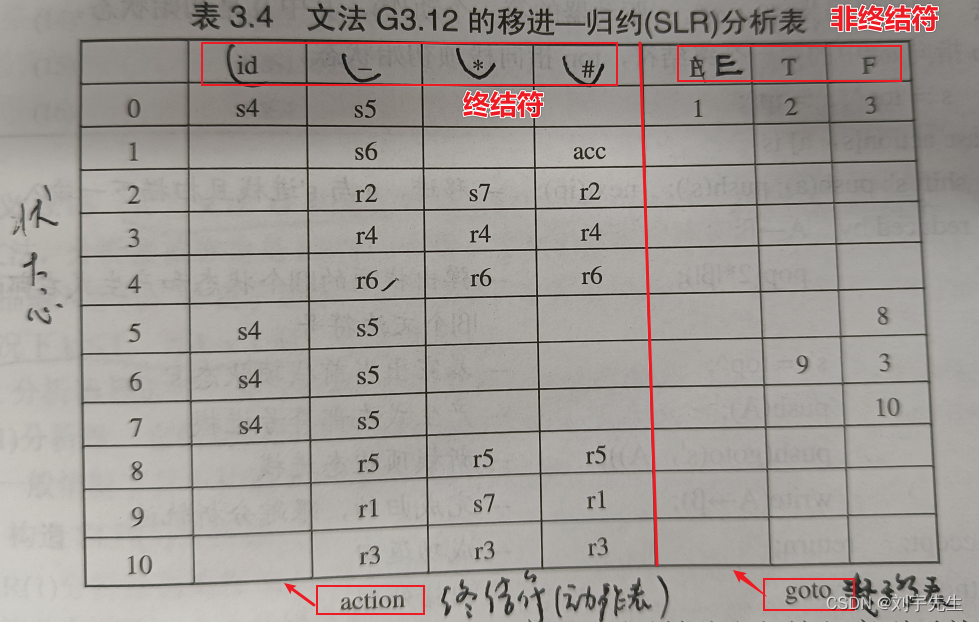
2. 用于归约处理的产生式文法:

3.分析输入序列的过程: