
- 1安卓Shell脚本_android shell 脚本binary
- 2(一)js前端开发中设计模式前篇之对象
- 3深入解析MJ图像生成中的指令功能_mj指令
- 4U盘或者移动硬盘弹出时出现弹窗的解决方法_移动硬盘怎么解除占用并安全弹出
- 5Python进阶语法:列表推导式
- 6网络安全数据集_工业网络安全大模型测试数据集
- 7基于 huggingface diffuser 库云服务器实现 stable diffusion inpaint样例代码
- 8昇思MindSpore 25天学习打卡营|day5
- 9如何在Linux将Spring Boot项目的Jar包注册为开机自启动系统服务_linux 启动springboot jar
- 10hadoop:未找到命令----解决办法_start-dfs.sh为什么找不到命令
昇思25天学习打卡营第19天|ShuffleNet图像分类
赞
踩
今天是参加昇思25天学习打卡营的第19天,今天打卡的课程是“ShuffleNet图像分类”,这里做一个简单的分享。
1.简介
在第15-18日的学习内容中,我们陆陆续续学习了计算机视觉相关的模型包括图像语义分割、图像分类、目标检测等内容,这些模型的运算往往都是在大算力设备上运行的,今天学习一种可以在移动设备上运行的图像分类模型-“ShuffleNet”。
ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到最好的模型精度。ShuffleNetV1的设计核心是引入了两种操作:Pointwise Group Convolution和Channel Shuffle,这在保持精度的同时大大降低了模型的计算量。因此,ShuffleNetV1和MobileNet类似,都是通过设计更高效的网络结构来实现模型的压缩和加速。
了解ShuffleNet更多详细内容,详见论文ShuffleNet。
2.模型架构
ShuffleNet最显著的特点在于对不同通道进行重排来解决Group Convolution带来的弊端。通过对ResNet的Bottleneck单元进行改进,在较小的计算量的情况下达到了较高的准确率。这里主要是要学习两个概念一是Pointwise Group Convolution(逐点分组卷积),二是Channel Shuffle(通道重排)。
2.1Pointwise Group Convolution
Group Convolution(分组卷积)原理如下图所示,相比于普通的卷积操作,分组卷积的情况下,每一组的卷积核大小为in_channels/gkk,一共有g组,所有组共有(in_channels/gkk)*out_channels个参数,是正常卷积参数的1/g。分组卷积中,每个卷积核只处理输入特征图的一部分通道,其优点在于参数量会有所降低,但输出通道数仍等于卷积核的数量。
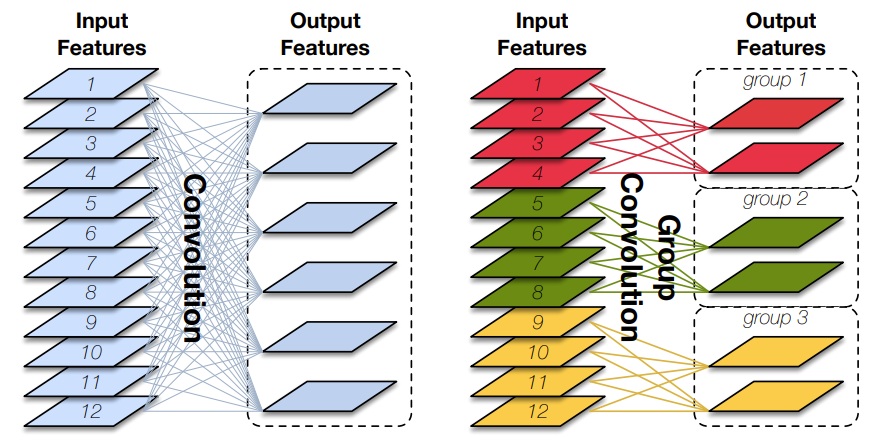
图片来源:Huang G, Liu S, Van der Maaten L, et al. Condensenet: An efficient densenet using learned group convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 2752-2761.
2.2Channel Shuffle
Group Convolution的弊端在于不同组别的通道无法进行信息交流,堆积GConv层后一个问题是不同组之间的特征图是不通信的,这就好像分成了g个互不相干的道路,每一个人各走各的,这可能会降低网络的特征提取能力。这也是Xception,MobileNet等网络采用密集的1x1卷积(Dense Pointwise Convolution)的原因。
为了解决不同组别通道“近亲繁殖”的问题,ShuffleNet优化了大量密集的1x1卷积(在使用的情况下计算量占用率达到了惊人的93.4%),引入Channel Shuffle机制(通道重排)。这项操作直观上表现为将不同分组通道均匀分散重组,使网络在下一层能处理不同组别通道的信息。
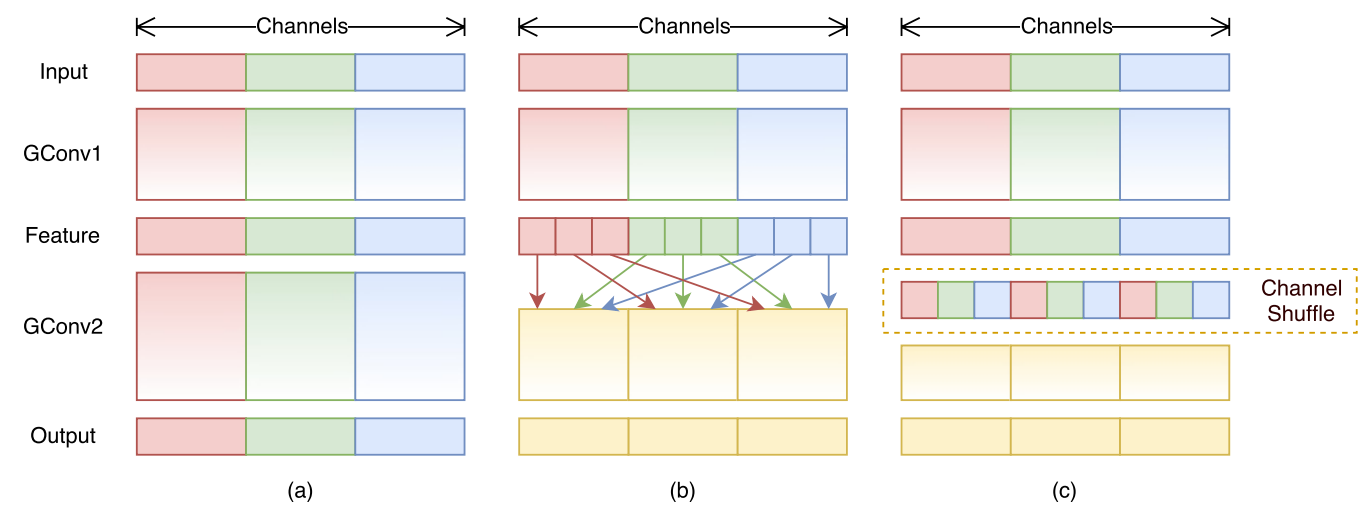
2.3 ShuffleNet模块
如下图所示,ShuffleNet对ResNet中的Bottleneck结构进行由(a)到(b), ©的更改:
- 将开始和最后的1×11×1卷积模块(降维、升维)改成Point Wise Group Convolution;
- 为了进行不同通道的信息交流,再降维之后进行Channel Shuffle;
- 降采样模块中,3×33×3 Depth Wise Convolution的步长设置为2,长宽降为原来的一般,因此shortcut中采用步长为2的3×33×3平均池化,并把相加改成拼接。
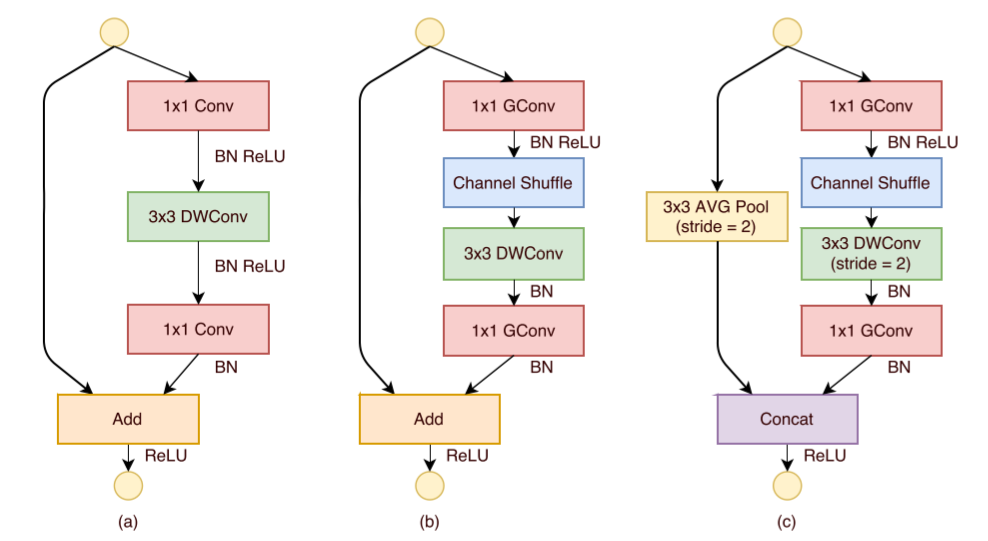
2.4 ShuffleNet网络
ShuffleNet网络结构如下图所示,以输入图像224×224224×224,组数3(g = 3)为例,首先通过数量24,卷积核大小为3×33×3,stride为2的卷积层,输出特征图大小为112×112112×112,channel为24;然后通过stride为2的最大池化层,输出特征图大小为56×5656×56,channel数不变;再堆叠3个ShuffleNet模块(Stage2, Stage3, Stage4),三个模块分别重复4次、8次、4次,其中每个模块开始先经过一次下采样模块(上图©),使特征图长宽减半,channel翻倍(Stage2的下采样模块除外,将channel数从24变为240);随后经过全局平均池化,输出大小为1×1×9601×1×960,再经过全连接层和softmax,得到分类概率。
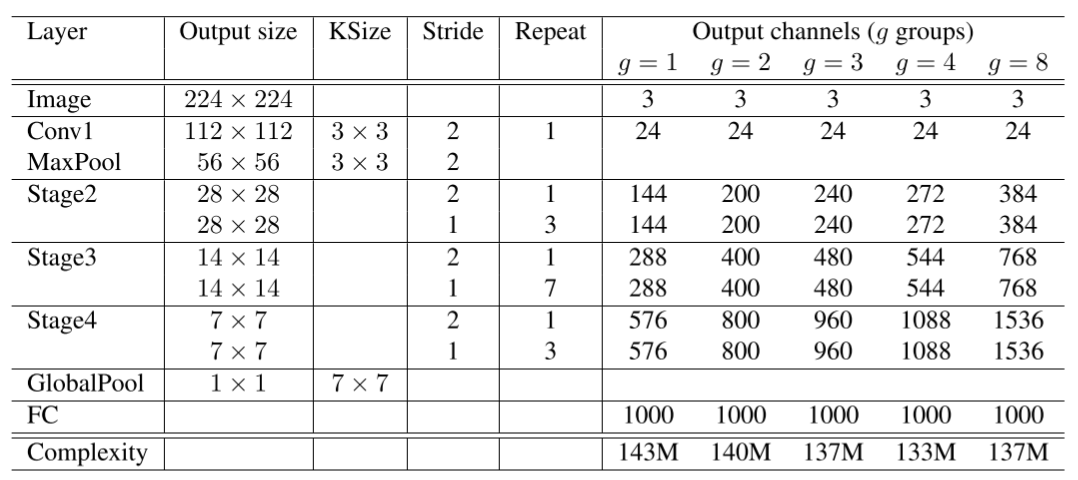
3.小结
人工智能模型的小型化对于移动设备上部署和应用来说具有重要的意义,牺牲一定程度的准确性来换取模型在移动设备可用对于用户来说是可接受的,这也是研究学习ShuffleNet的一个重要意义。ShuffleNet通过分组卷积、通道重排等技术大幅度降低了所需计算的参数,同时能够获得不错的准确率,使得模型在能够在算力不足的移动设备可用,是这个领域的重大贡献。
当然,对于移动设备上的人工智能模型,除了模型小型化以外,借助高速发展的5G等移动网络也可以使用基于云端的应用部署方式来获取更高性能、更高准确度的模型,这两种方案应该说是互补的,而不是对立。移动设备在离线环境下的可用性对于很多业务场景都有很高的价值,对在线和离线环境模型都可用有需求的场景,模型小型化的研究是非常有必要的。
以上是第19天的学习内容,附上今日打卡记录:



