
- 1RabbitMQ(五)死信队列、延迟队列_死信队列和延时队列的区别
- 2使用GPU跑包工具
- 330岁程序员的转型思考_算法工程师30岁以后
- 4Android 面试问题 2024 版(其一)_安卓开发面试
- 5【学习笔记】爬虫(Ⅰ)—— Selenium和Pytest_pytest框架和selenium一样吗
- 6灰狼优化算法(GWO)与长短期记忆网络(LSTM)结合的预测模型(GWO-LSTM)及其Python和MATLAB实现
- 7十大经典排序算法-计数排序算法详解
- 8java实现lda模型_lda模型 java
- 9Python 微信自动化工具开发系列03_自动向微信好友发送信息和文件(2024年2月可用 支持3.9最新微信)_python使用wxauto实现多人微信自动发消息或文件
- 10Spring Boot 3 整合 Hutool 验证码实战_springboot3 整合hutool
【学习笔记】Selenium 定位方式详解_selenium定位
赞
踩
学习说明
本贴的学习目的为详细了解selenium定位方式的用法与优缺点。
第一部分:单元素定位与多元素定位
单元素定位语法
# 单元素定位语法
element = driver.find_element(By.XX, "value")
- 1
- 2
单元素定位会直接选择页面中第一个符合条件的元素。
多元素定位语法
# 多元素定位语法
element = driver.find_elements(By.XX, "value")
- 1
- 2
多元素定位会返回所有匹配到的元素列表(数组)。
我们可以根据列表的下标来定位具体的某个元素:
element = driver.find_elements(By.XX, "value")[index]
- 1
或者:
element = driver.find_elements(By.XX, "value")
element = elements[0]
- 1
- 2
也可以使用for遍历元素列表,来找到符合条件(属性、文本内容等)的元素。
# 定位多个元素
elements = driver.find_elements(By.TAG_NAME, "div")
# 假设我们想要选择包含特定文本的元素
target_text = "my_target_text"
target_element = None
for element in elements:
if target_text in element.text:
target_element = element
break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
第二部分:元素选择定位
1、通过ID定位
# 通过 ID 定位
element = driver.find_element(By.ID, "element_id")
- 1
- 2
在Html中,#用来标识id。
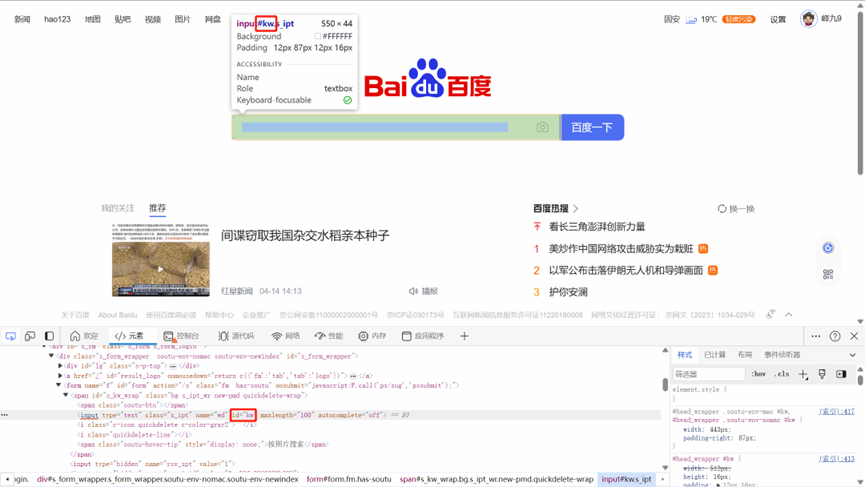
Html Tag的id属性值是唯一的,故不存在根据id定位多个元素的情况。HTML Tag的id属性可以省略,不是一定能定位到的,有时候页面元素中随着刷新网页id的值是会变化的,说明是js动态生成的id属性值,这时候用来定位就会产生问题。
注意:id属性是唯一的,所以多元素定位没有id。
2、通过NAME定位
# 通过 Name 定位单元素
element = driver.find_element(By.NAME, "element_name")
# 通过 Name 定位多元素
elements = driver.find_elements(By.NAME, "element_name")
- 1
- 2
- 3
- 4
- 5
name不具有唯一性,可以多次出现,用name定位单元素需要保证name值唯一,否则定位失败。
3、通过Class Name定位
# 通过 Class Name 定位单元素
element = driver.find_element(By.CLASS_NAME, "class_name")
# 通过 Class Name 定位多元素
elements = driver.find_elements(By.CLASS_NAME, "class_name")
- 1
- 2
- 3
- 4
- 5
在HTML中,.用来标识class。
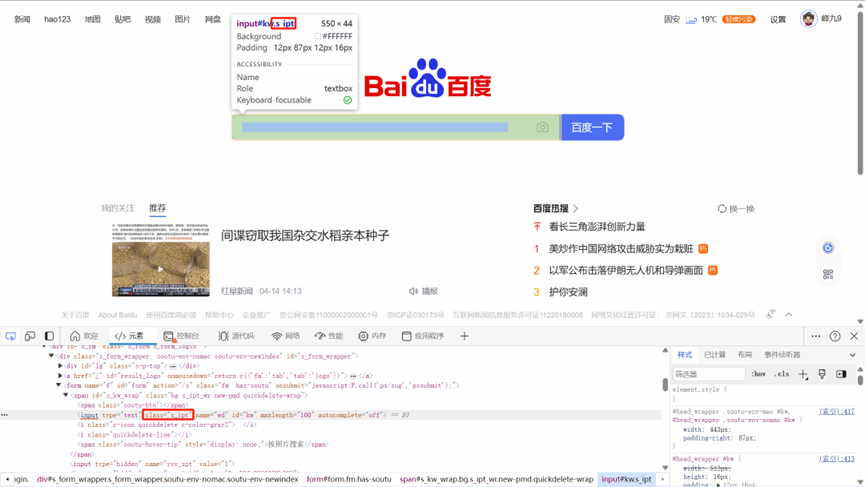
class是元素的类名,也不具有唯一性。
注意:根据class_name 进行定位的时候,有时候会遇到复合类,也就是class属性中间有空格,空格为间隔符号,表示的是一个元素有多个lass的属性名称,此时元素定位的时候任取一个即可。
4、通过Tag Name定位
# 通过 Tag Name 定位单元素
element = driver.find_element(By.TAG_NAME, "Tag Name")
# 通过 Tag Name 定位多元素
elements = driver.find_elements(By.TAG_NAME, "Tag Name")
- 1
- 2
- 3
- 4
- 5
tag_name 定位即通过标签名称(Html Tag)定位,不推荐使用此方式去定位,存在极大的不稳定性。
5、通过Link Taxt定位
# 通过 Link Text 定位单元素
element = driver.find_element(By.LINK_TEXT, "Link Text")
# 通过 Link Text 定位多元素
elements = driver.find_elements(By.LINK_TEXT, "Link Text")
- 1
- 2
- 3
- 4
- 5
Link Taxt 定位即通过超链接文字来定位,只使用在链接位置处,比如a标签。
注意: link_text只能使用精准的匹配,必须根据链接上完整的文本内容去进行定位 。
6、通过Partial Link Taxt定位
# 通过 Partial Link Text 定位单元素
element = driver.find_element(By.PARTIAL_LINK_TEXT, "Partial Link Text")
# 通过 Partial Link Text 定位多元素
elements = driver.find_elements(By.PARTIAL_LINK_TEXT,"Partial Link Text")
- 1
- 2
- 3
- 4
- 5
Partial_Link_Text定位是使用超链接的部分文字来定位,同样也只使用在链接位置处,且可以使用精准或模糊匹配,一般用于定位长文本内容。
7、通过CSS Selector定位
# 通过 CSS Selector 定位单元素
element = driver.find_element(By.CSS_SELECTOR, "css_selector")
# 通过 CSS Selector 定位多元素
element = driver.find_element(By.CSS_SELECTOR, "css_selector")
- 1
- 2
- 3
- 4
- 5
CSS定位是通过元素的CSS属性进行定位,兼容Tag、Class、Id等等定位方式。CSS定位非常灵活,它允许你在不更改定位方式的情况下更改定位策略,也使得脚本更加清晰和易于维护。
标签选择器:
通过HTML元素的标签名进行定位。
# 定位所有的<p>标签
element = driver.find_element(By.CSS_SELECTOR, "P")
- 1
- 2
类选择器:
通过元素的class属性进行定位。
# 定位Class为"myClass"的元素
element = driver.find_element(By.CSS_SELECTOR, ". myClass")
- 1
- 2
使用.来标志Class
ID选择器:
通过元素的ID进行定位。
# 定位ID为"myId"的元素
element = driver.find_element(By.CSS_SELECTOR, "#myID")
- 1
- 2
使用#来标志ID
组合选择器:
可以使用空格、子代选择器(>)、相邻兄弟选择器(+)和一般兄弟选择器(~)等来组合选择器。
# 定位div.container的直接子代<p>元素
element = driver.find_element(By.CSS_SELECTOR, "div.container>p")
- 1
- 2
属性选择器:
可以根据元素的属性及其值进行定位。
选择具有特定属性的元素:[attr]
选择具有特定属性和值的元素:[attr=value],例如:
# 定位所有href属性值为example.com的a标签:
element = driver.find_element(By.CSS_SELECTOR, " a[href='example.com']")
- 1
- 2
通配符和伪类选择器:
CSS选择器还支持使用通配符(*)和伪类(如:hover, :first-child等)来增加选择的灵活性。
8、通过Xpath定位
# 通过 XPath 定位单元素
element = driver.find_element(By.XPATH, "xpath")
# 通过 XPath 定位多元素
elements = driver.find_elements(By.XPATH, "xpath")
- 1
- 2
- 3
- 4
- 5
XPath 表达式用于定位 XML 文档中的节点。在 web 开发中,HTML 可以看作是特殊的 XML,所以 XPath 也可以用来定位 HTML 元素。
Xpath语法:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@属性] | 选取具有给定属性的所有元素 |
| [@属性=‘value’] | 选取给定属性具有给定值的所有元素 |
XPath 定位:
- 通过标签名定位:
//tagname,比如//div会选择所有的 div 标签。 - 通过 ID 定位:
//[@id='someId'],比如//[@id='myElementId']。 - 通过类名定位:
//[@class='someClass']或//tagname[@class='someClass']。 - 通过属性定位:如
//a[@href='https://www.baidu.com']会选择所有 href 属性值为指定 URL 的 a 标签。 - 组合定位:可以使用逻辑运算符如
and、or和not来组合多个条件。
注意 :
- XPath大小写敏感,确保你的标签名和属性值的大小写正确。
- 当页面结构复杂或动态加载内容时,XPath可能需要相应地调整。
- 使用简单的XPath表达式可以提高性能。避免使用过于复杂的表达式。
Xpath调试:
在浏览器的开发者模式调试界面,ctrl+f调出搜索框,将xpath的定位语句复制到搜索框,会以黄色高亮的方式指出你定位到的是哪个元素:
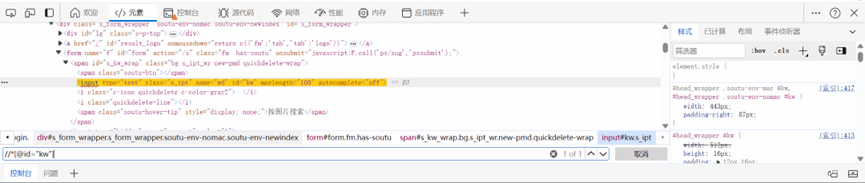
第三部分:相对定位器
说明:
| 方法 | 作用 |
|---|---|
| above() | 定位到现元素上面的元素 |
| below() | 定位到现元素下面的元素 |
| toLeftOf() | 定位到现元素左面的元素 |
| tpRightOf() | 定位到现元素右面的元素 |
| near() | 定位到最多距现元素50个像素远的元素 |
语法:
email_locator = locate_with(By.TAG_NAME,"input").above({By.ID: "password"})
- 1

