
- 1从“微软蓝屏”事件看网络安全与系统稳定性的挑战与应对
- 2git add和git commit之后,想撤销commit,修改注释_git commit后取消add
- 3【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)_wav2vec2.0语音识别
- 4MySQL数据分析进阶(十一)数据类型
- 5python中的异常(try...except...else...finally)_python try else
- 6Linux 权限_linux中超级用户是什么
- 7什么是低代码开发
- 8springboot对接kafka_springboot接入kafka
- 9微信小程序-Vant组件库的使用
- 10微信小程序_对接腾讯实时音视频_多人会议_微信小程序多人音视频会议录屏
Stable Diffusion中的embedding_stable diffusion embedding
赞
踩
Stable Diffusion中的embedding
嵌入,也称为文本反转,是在 Stable Diffusion 中控制图像样式的另一种方法。在这篇文章中,我们将学习什么是嵌入,在哪里可以找到它们,以及如何使用它们。
什么是嵌入embedding?
嵌入(Embedding)是一种在机器学习和人工智能领域中常用的技术,特别是在图像生成和风格迁移等任务中。文本反转(Textual Inversion)则是一种特定于图像生成领域的方法,它允许用户在不直接修改预训练模型的情况下,通过定义新的关键字来引入新的样式或对象。
这种方法之所以受到关注,主要是因为它提供了一种高效且灵活的方式来扩展和定制AI模型的能力。尤其是在样本图像数量有限的情况下(例如只有3到5个样本),文本反转能够显著提高模型的适应性和创造力。通过这种方式,模型能够学习并模仿特定的风格或特征,并将其应用到新的图像生成过程中。
文本反转是如何工作的?
文本反转的核心思想是将特定的文本描述与图像特征相关联。这个过程通常包括以下几个步骤:
- 样本收集:首先,收集一组具有相似风格或包含特定对象的样本图像。
- 文本描述:为每个样本图像创建一个文本描述,这个描述应该捕捉到图像的关键特征或风格。
- 嵌入训练:使用这些文本描述和对应的样本图像来训练一个嵌入模型。这个模型将学习如何将文本描述映射到图像特征上。
- 应用嵌入:一旦嵌入模型训练完成,就可以将其应用于新的图像生成任务中。当模型接收到一个与训练时相似的文本描述时,它能够生成具有相应特征或风格的图像。
嵌入的优势
嵌入技术的优势在于其灵活性和高效性。通过文本反转,用户可以在不改变原有模型结构的前提下,快速地引入新的风格或对象。这种方法特别适用于以下场景:
- 快速原型设计:设计师和艺术家可以迅速尝试不同的风格和概念,而无需从头开始训练复杂的模型。
- 个性化定制:用户可以根据自己的喜好和需求,定制独特的图像风格或对象。
- 数据稀缺情况:即使在样本数量有限的情况下,也能够有效地训练模型,使其学习到新的样式或特征。
总的来说,嵌入和文本反转为图像生成领域提供了一种创新的方法,使得AI模型更加灵活和易于使用。通过这种方式,我们可以更好地利用现有的AI资源,创造出更加多样化和个性化的视觉内容。
下面转载的原始研究文章中的图表说明了它是如何工作的。
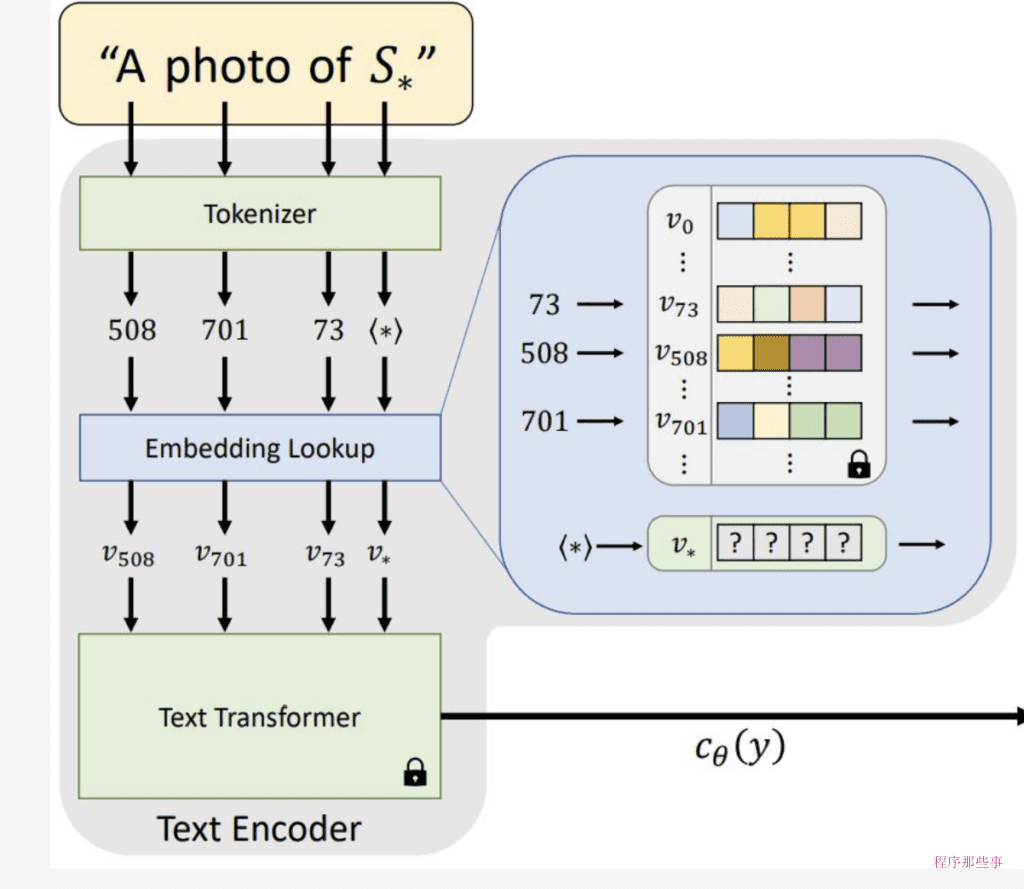
在使用稳定扩散AI模型进行图像生成时,引入新的对象或样式是一个常见的需求。为了实现这一点,文本反转(Textual Inversion)提供了一种有效的方法,允许我们在不修改模型本身的情况下,通过定义新的关键字来实现这一目标。下面是详细的步骤说明:
定义新的关键字
- 选择或创建新关键字:首先,你需要为想要添加到模型中的新对象或样式选择或创造一个独特的关键字。这个关键字应该是描述性的,能够清晰地表达你想要引入的新元素。
- 标记化:在模型中,所有的文本提示都是通过标记化(Tokenization)过程被转换成数字形式的。这个过程将文本中的每个单词或符号转换成对应的数字标记。对于你定义的新关键字,它也会被转换成一个唯一的数字标记。
生成嵌入向量
- 嵌入向量生成:每个标记(包括新关键字的标记)都会被进一步转换为嵌入向量。嵌入向量是高维空间中的点,它能够捕捉和表示文本的语义信息。在这个过程中,新关键字会被赋予一个独特的嵌入向量。
- 文本反转过程:文本反转技术的核心在于,它允许我们通过嵌入向量来查找和表示新关键字,而无需更改模型的任何其他部分。这意味着,即使模型在训练时没有直接接触过新关键字,它也能够通过嵌入向量来理解和生成与新关键字相关的图像内容。
应用新关键字
- 在提示中使用新关键字:在生成图像时,你可以在文本提示中包含新关键字。由于新关键字已经被标记化并转换成了嵌入向量,模型能够识别并将其作为生成图像的依据。
- 生成图像:当模型接收到包含新关键字的提示时,它会查找与该关键字对应的嵌入向量,并使用这个向量来生成图像。这个过程就像是在语言模型中引入了一种新的语言元素,使得模型能够理解和创造出新的概念。
通过这种方式,文本反转为我们提供了一种强大的工具,使得我们能够在不改变模型结构的前提下,灵活地引入新的对象或样式,极大地扩展了图像生成的可能性。这种方法不仅提高了模型的适应性和灵活性,也为艺术家和设计师提供了更多的创作自由。
在哪里可以找到embedding
下载embedding的首选位置是 Civitai。
我们在C站的右上角可以有一个filter选项:
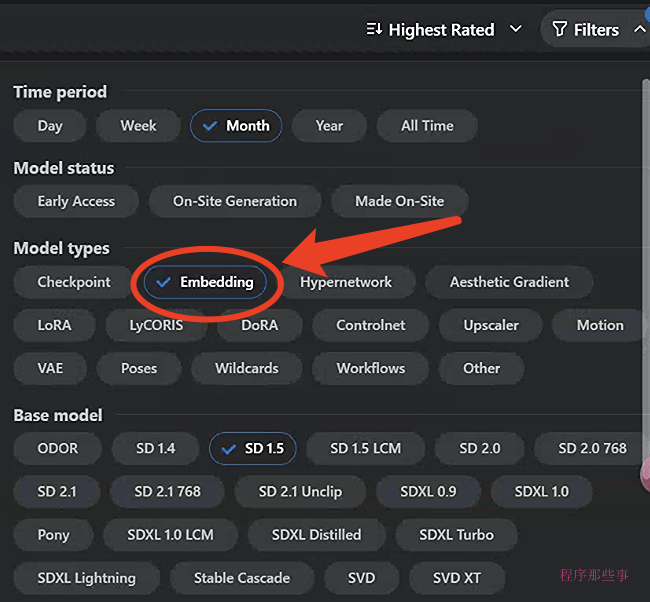
在filter中选择model types= embedding就可以找到对应的embedding了。
如何使用embedding
在 AUTOMATIC1111 中使用embedding很容易。
首先,从 Civitai 网站下载好embedding文件。下载下来的embedding文件通常是bin或者pt结尾的。
你需要把这些embedding文件放到Stable diffusion webUI根目录下面的embeddings文件夹,然后重启Stable diffusion webUI即可。

在webUI界面,你可以在Textual Inversion中找到你安装好的embedding。
要使用他,只需要点击对应的embedding, webUI会自动把对应的embedding添加到提示词中去。比如:
a girl,0lg4kury,
这里0lg4kury就是我安装的第一个embedding的名字。点击生成,看看效果:

可以看到人物还是很相似的。
这里我用了多种采样方法来进行最终图片的对比。
调整embedding的强度
之前听过我的prompt文章的朋友应该知道我们可以调整提示词强度的。
因为embedding同样也是提示词的一部分,所以我们也可以用同样的方式来调整embedding的强度。

neg embedding
有了正面的embedding,同样也有负面的embedding,下面是几个常用的负面embedding:



embedding、dreambooth 和hypernetwork的区别
文本反转(Textual Inversion)、Dreambooth 和超网络 是三种不同的技术,它们都可以用于微调Stable Diffusion模型,但各自有不同的特点和应用场景。
- 文本反转(Textual Inversion):
- 文本反转是一种通过少量样本图像来训练模型的方法,它允许用户定义新的关键字来描述特定的对象或风格。
- 这种方法不需要更改模型的结构,而是通过嵌入向量来实现新关键字的添加。
- 嵌入向量存储在相对较小的文件中(通常小于100 kB),这使得它们易于存储和传输。
- 文本反转适合于快速添加新概念到模型中,但可能不如其他方法那样灵活或强大。
- Dreambooth:
- Dreambooth是一种基于深度学习的图像风格转换技术,它使用少量图像来训练模型。
- 它特别适合于生成高质量艺术作品,而无需用户具备专业艺术技能。
- Dreambooth通过微调模型的权重来实现特定主题的生成,这可能导致模型过度拟合训练数据。
- 它生成的模型文件相对较大(2-4GB),并且在使用时需要加载模型。
- 超网络(Hypernetwork):
- 超网络是一种使用神经网络来生成模型参数的方法。
- 它通过在原有模型的基础上添加一个附加网络来实现微调,这个附加网络可以学习新的生成特征。
- 超网络生成的模型文件大小介于文本反转和Dreambooth之间(大约几十MB),这使得它在存储和传输方面比较平衡。
- 超网络适合于生成近似内容图像,如果训练数据与目标风格高度相关,那么超网络是一个不错的选择。
总的来说,文本反转、Dreambooth和超网络各有优势和适用场景。文本反转适合快速添加新概念,Dreambooth适合个性化的高质量图像生成,而超网络则提供了一种在保留原有模型结构的同时进行微调的中间方案。用户可以根据自己的需求和资源限制来选择最合适的方法。

